Planera migreringen från Azure Data Factory
Microsoft Fabric är Microsofts SaaS-produkt för dataanalys som sammanför alla Microsofts marknadsledande analysprodukter till en enda användarupplevelse. Fabric Data Factory tillhandahåller arbetsflödesorkestrering, dataflytt, datareplikering och datatransformering i stor skala med liknande funktioner som finns i Azure Data Factory (ADF). Om du har befintliga ADF-investeringar som du vill modernisera till Fabric Data Factory är det här dokumentet användbart för att hjälpa dig att förstå migreringsöverväganden, strategier och metoder.
Att migrera från Azure PaaS ETL/DI-tjänsterna ADF & Synapse-pipelines och dataflöden kan ge flera viktiga fördelar:
- Nya integrerade pipelinefunktioner, inklusive e-post- och Teams-aktiviteter, möjliggör enkel routning av meddelanden under pipelinekörning.
- Inbyggda funktioner för kontinuerlig integrering och leverans (CI/CD) (distributionspipelines) kräver inte extern integrering med Git-lagringsplatser.
- Integrering av arbetsytor med din OneLake-datasjö möjliggör enkel analyshantering med en enda fönsterruta.
- Det är enkelt att uppdatera dina semantiska datamodeller i Fabric med en helt integrerad pipelineaktivitet.
Microsoft Fabric är en integrerad plattform för både självbetjäning och IT-hanterade företagsdata. Med exponentiell tillväxt i datavolymer och komplexitet kräver Fabric-kunder företagslösningar som skalas, är säkra, enkla att hantera och tillgängliga för alla användare i de största organisationerna.
Under de senaste åren har Microsoft gjort stora ansträngningar för att leverera skalbara molnfunktioner till Premium. För detta ändamål möjliggör Data Factory i Fabric omedelbart ett stort ekosystem av dataintegreringsutvecklare och dataintegreringslösningar som har byggts upp över årtionden att tillämpa den fullständiga uppsättningen funktioner och kapabiliteter som går långt utöver den jämförbara funktionalitet som varit tillgänglig i tidigare generationer.
Naturligtvis frågar kunderna om det finns en möjlighet att konsolidera genom att vara värd för sina dataintegreringslösningar i Fabric. Vanliga frågor är:
- Fungerar all den funktionalitet vi är beroende av i Fabric-pipelines?
- Vilka funktioner är endast tillgängliga i Fabric-pipelines?
- Hur migrerar vi befintliga pipelines till Fabric pipelines?
- Vad är Microsofts översikt över datainmatning för företag?
Plattformsskillnader
När du migrerar en hel ADF-instans finns det många viktiga skillnader att tänka på mellan ADF och Data Factory i Fabric, vilket blir viktigt när du migrerar till Fabric. Vi utforskar flera av dessa viktiga skillnader i det här avsnittet.
Mer detaljerad information om funktionell mappning av funktionsskillnader mellan Azure Data Factory och Fabric Data Factory finns i Compare Data Factory in Fabric and Azure Data Factory.
Integrationskörtider
I ADF är integreringskörningar (IR) konfigurationsobjekt som representerar beräkning som används av ADF för att slutföra databearbetningen. De här konfigurationsegenskaperna omfattar Azure-regionen för molnberäkning och Spark-beräkningsstorlekar för dataflöde. Andra IR-typer är lokalt installerade IR:er (SHIR) för lokal dataanslutning, SSIS IR:er för att köra SQL Server Integration Services-paket och Vnet-aktiverade moln-IR:er.
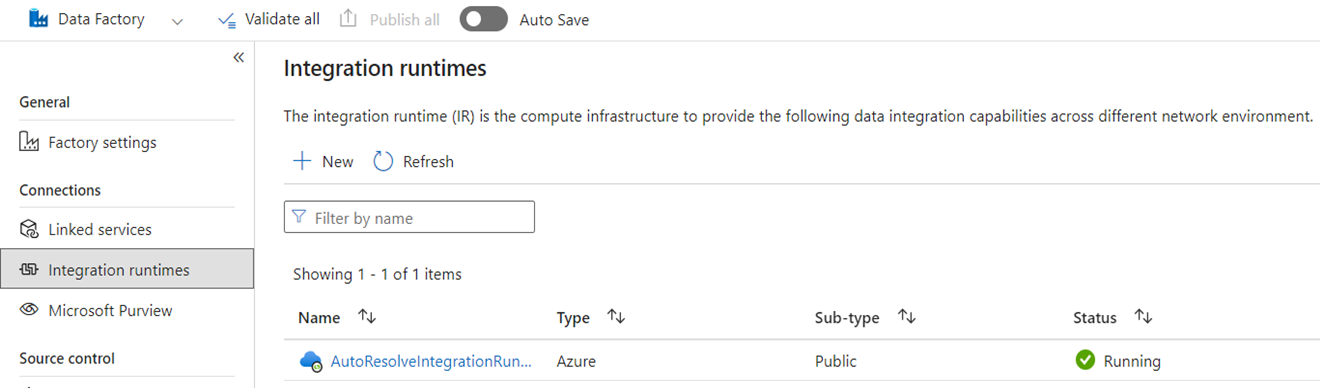
Microsoft Fabric är en SaaS-produkt (software-as-a-service) medan ADF är en PaaS-produkt (platform-as-a-service). Vad den här distinktionen innebär för integrationens körtider är att du inte behöver konfigurera något för att använda pipelines eller dataflöden i Fabric, eftersom standardinställningen är att använda molnbaserad datorkraft i den region där dina Fabric-kapaciteter är belägna. SSIS IR:er finns inte i Fabric och för lokal dataanslutning använder du en Fabric-specifik komponent som kallas lokal Data Gateway (OPDG). Och för anslutningar baserade på virtuella nätverk till skyddade nätverk använder du den virtuella nätverksdatagatewayen i Fabric.
När du migrerar från ADF till Infrastrukturresurser behöver du inte migrera offentliga Azure-IR:er (cloud). Du behöver återskapa dina SHIR:er som OPDG:er och Azure IR aktiverade för virtuella nätverk som Virtual Network Data Gateways.
Rörledningar
Pipelines är den grundläggande komponenten i ADF, som används för det primära arbetsflödet och orkestreringen av dina ADF-processer för dataflytt, datatransformering och processorkestrering. Pipelines i Fabric Data Factory är nästan identiska med ADF, men med extra komponenter som passar bra med SaaS-modellen baserat på Power BI. Den här likheten omfattar interna aktiviteter för uppdateringar av e-postmeddelanden, Teams och Semantic Model.
JSON-definitionen för pipelines i Fabric Data Factory skiljer sig något från ADF på grund av skillnader i programmodellen mellan de två produkterna. På grund av den här skillnaden går det inte att kopiera/klistra in pipeline-JSON, importera/exportera pipelines eller peka på en ADF Git-lagringsplats.
När du återskapar dina ADF-pipelines som Fabric-pipelines använder du i stort sett samma arbetsflödesmodeller och kunskaper som du använde i ADF. Det huvudsakliga övervägandet gäller länkade tjänster och datauppsättningar, som är begrepp i ADF men inte finns i Fabric.
Länkade tjänster
I ADF definierar länkade tjänster de anslutningsegenskaper som behövs för att ansluta till dina datalager för dataflytt, datatransformering och databearbetningsaktiviteter. I Fabric måste du återskapa dessa definitioner som Anslutningar, vilka är egenskaper för aktiviteter som kopiera och dataflöden.
Datamängder
Datauppsättningar definierar form, plats och innehåll för dina data i ADF men finns inte som entiteter i Fabric. Om du vill definiera dataegenskaper som datatyper, kolumner, mappar, tabeller osv. i Fabric Data Factory-pipelines definierar du dessa egenskaper infogade i pipelineaktiviteter och inuti det anslutningsobjekt som refererades tidigare i avsnittet Länkad tjänst.
Dataflöden
I Data Factory for Fabric refererar termen dataflöden till de kodfria datatransformeringsaktiviteterna, medan samma funktion i ADF kallas dataflöden. Fabric Data Factory-dataflöden har ett användargränssnitt som bygger på Power Query, som används i ADF Power Query-aktiviteten. Den beräkning som används för att köra dataflöden i Fabric är en inhemsk körmotor som kan skalas ut för storskalig datatransformering med hjälp av den nya beräkningsmotorn för Fabric Data Warehouse.
I ADF bygger dataflöden på Synapse Spark-infrastrukturen och definieras med hjälp av ett användargränssnitt för konstruktion som använder ett underliggande domänspecifikt språk (DSL) som kallas dataflödesskript. Det här definitionsspråket skiljer sig avsevärt från Power Query-baserade dataflöden i Fabric, som använder ett definitionsspråk som kallas M för att definiera sitt beteende. På grund av dessa skillnader i användargränssnitt, språk och körningsmotorer är Fabric dataflöden och ADF dataflöden inte kompatibla och du måste återskapa dina ADF-dataflöden som Fabric dataflöden när du uppgraderar dina lösningar till Fabric.
Utlösare
Utlösare signalerar ADF att köra en pipeline baserat på ett tidsschema för väggklockan, rullande fönstertidssektorer, filbaserade händelser eller anpassade händelser. De här funktionerna är samma i Fabric, även om den underliggande implementeringen skiljer sig åt.
I Fabric existerar -utlösare endast som ett pipelinekoncept. Det större ramverk som pipelineutlösare använder i Fabric kallas Data Activator, vilket är ett händelse- och aviseringsundersystem för funktionerna för realtidsinformation i Fabric.
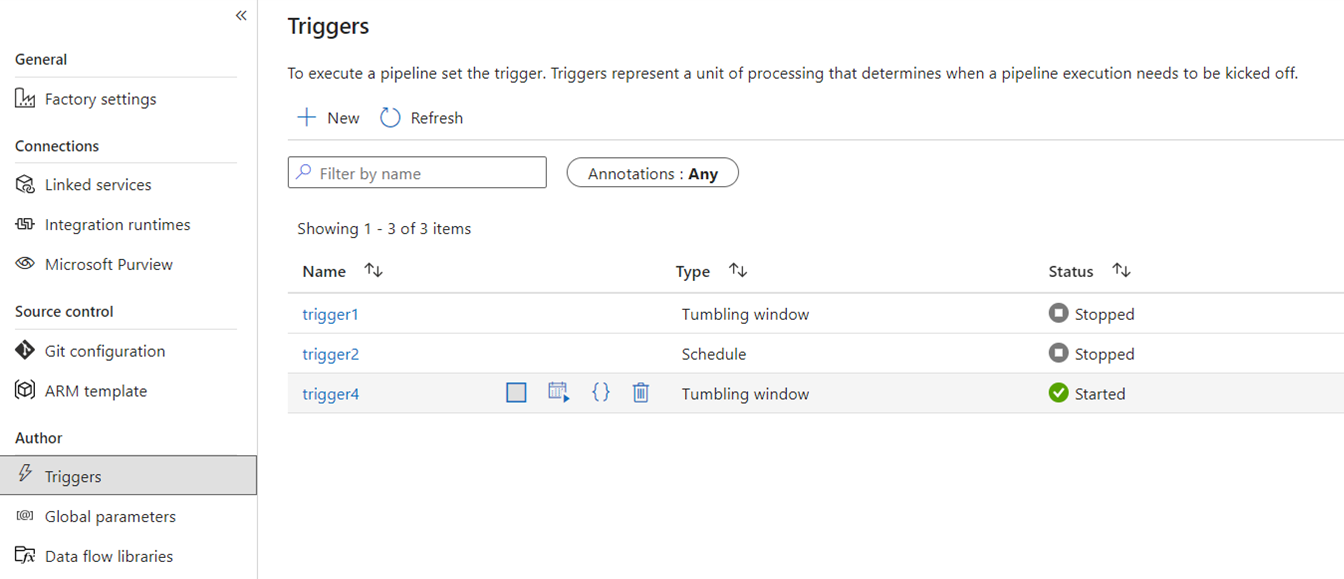
Fabric Data Activator har aviseringar som kan användas för att skapa filhändelse och anpassade händelseutlösare. Schemautlösare är en separat entitet i Fabric som kallas schema. Dessa tidscheman finns på plattformsnivå i Fabric och är inte specifika för pipelines. De kallas inte heller utlösare i Fabric.
Om du vill migrera dina utlösare från ADF till Fabric, överväg att återskapa dina schemautlösare som scheman, vilket är egenskaper för dina Fabric-pipelines. Och för alla andra utlösartyper använder du knappen Utlösare i Fabric-pipelinen eller använder Data Activator direkt i Fabric.
Felsökning
Felsökning av pipelines är enklare i Fabric än i ADF. Den här enkelheten beror på att Fabric Data Factory-pipelines inte har ett separat begrepp för felsökningsläge som du hittar i ADF-pipelines och dataflöden. När du skapar din pipeline är du i stället alltid i interaktivt läge. Om du vill testa och felsöka dina pipelines behöver du bara välja uppspelningsknappen i verktygsfältet Pipeline-redigeraren när du är redo i utvecklingscykeln. Pipelines i Fabric inkluderar inte felsökning förrän stegvis interaktivt felsökningsmönster. I Infrastruktur använder du i stället aktivitetstillståndet och anger endast de aktiviteter som du vill testa som aktiva samtidigt som du ställer in alla andra aktiviteter som inaktiva för att uppnå samma test- och felsökningsmönster. Se följande video som beskriver hur du uppnår processen för felsökning i Fabric.
Ändra datainsamling
Change Data Capture (CDC) i ADF är en förhandsversionsfunktion som gör det enkelt att snabbt flytta data på ett inkrementellt sätt genom att tillämpa CDC-funktioner på källsidan i dina datalager. Om du vill migrera dina CDC-artefakter till Fabric Data Factory återskapar du dessa artefakter som Kopia jobb objekt i din Fabric-arbetsyta. Den här funktionen ger liknande funktioner för inkrementell dataförflyttning med ett användarvänligt användargränssnitt utan att kräva en pipeline, precis som i ADF CDC. För mer information, se kopieringsjobb för Data Factory i Fabric.
Azure Synapse Link
Även om de inte är tillgängliga i ADF använder Synapse-pipelineanvändare ofta Azure Synapse Link för att replikera data från SQL-databaser till sin datasjö i nyckelfärdig metod. I Infrastruktur återskapar du Azure Synapse Link-artefakterna som speglingsobjekt på din arbetsyta. Mer information finns i Fabric databasspegling.
SQL Server Integration Services (SSIS)
SSIS är det lokala dataintegrerings- och ETL-verktyget som Microsoft levererar med SQL Server. I ADF kan du lyfta och flytta dina SSIS-paket till molnet med hjälp av ADF SSIS IR. I Fabric har vi inte begreppet IR, så den här funktionen är inte möjlig i dag. Vi arbetar dock med att aktivera SSIS-paketkörning internt från Fabric som vi hoppas kunna ta med till produkten snart. Under tiden är det bästa sättet att köra SSIS-paket i molnet med Fabric Data Factory att starta en SSIS IR i din ADF-fabrik och sedan anropa en ADF-pipeline för att anropa dina SSIS-paket. Du kan fjärranropa en ADF-pipeline från dina Fabric-pipelines med hjälp av aktiviteten "Anropad pipeline" som beskrivs nedan i följande avsnitt.
Anropa pipelineaktivitet
En vanlig aktivitet som används i ADF-pipelines är Kör pipelineaktivitet som gör att du kan anropa en annan pipeline i din fabrik. I Fabric har vi förbättrat den här aktiviteten som den Anropa pipelineaktivitet. Se dokumentationen för anropa pipelineaktivitet .
Den här aktiviteten är användbar för migreringsscenarier där du har många ADF-pipelines som använder ADF-specifika funktioner som Mappa dataflöden eller SSIS. Du kan underhålla dessa pipelines as-is i ADF eller till och med Synapse-pipelines och sedan anropa pipelinen internt från din nya Fabric Data Factory-pipeline med hjälp av aktiviteten Anropa pipeline och peka på fjärrfabrikspipelinen.
Exempel på migreringsscenarier
Följande scenarier är vanliga migreringsscenarier som du kan stöta på när du migrerar från ADF till Fabric Data Factory.
Scenario nr 1: ADF-pipelines och dataflöden
De primära användningsfallen för fabriksmigreringar baseras på modernisering av din ETL-miljö från ADF-fabrikens PaaS-modell till den nya Fabric SaaS-modellen. De primära fabriksobjekten som ska migreras är pipelines och dataflöden. Det finns flera grundläggande fabrikselement som du behöver planera för migrering utanför de två översta objekten: länkade tjänster, integreringskörningar, datauppsättningar och utlösare.
- Länkade tjänster måste återskapas i Fabric som anslutningar i dina pipelineaktiviteter.
- Datauppsättningar finns inte i Factory. Egenskaperna för dina datauppsättningar representeras som egenskaper i pipelineaktiviteter som Kopiera eller Uppslag, medan Anslutningar innehåller andra datauppsättningsegenskaper.
- Integreringskörningar finns inte i Fabric. Dina självhostade IR:er kan dock återskapas med On-premises Data Gateways (OPDG) i Fabric och Azure-virtuella nätverks-IR:er som hanterade virtuella nätverksgatewayer i Fabric.
- Dessa ADF-pipelineaktiviteter ingår inte i Fabric Data Factory:
- Data Lake Analytics (U-SQL) – Den här funktionen är en inaktuell Azure-tjänst.
- Valideringsaktivitet – Valideringsaktiviteten i ADF är en stödaktivitet som du enkelt kan återskapa i dina Fabric-pipelines med hjälp av en Get Metadata-aktivitet, en pipeline-loop och en If-aktivitet.
- Power Query – I Fabric skapas alla dataflöden med Power Query-användargränssnittet, så du kan kopiera och klistra in M-koden från dina ADF Power Query-aktiviteter och skapa dem som dataflöden i Fabric.
- Om du använder någon av de ADF-pipelinefunktioner som inte finns i Fabric Data Factory, använd aktiviteten "Anropa pipeline" i Fabric för att anropa dina befintliga pipelines i ADF.
- Följande ADF-pipelineaktiviteter kombineras till en enskild aktivitet:
- Azure Databricks-aktiviteter (Notebook, Jar, Python)
- Azure HDInsight (Hive, Pig, MapReduce, Spark, Streaming)
Följande bild visar konfigurationssidan för ADF-datauppsättningen med dess filsökväg och komprimeringsinställningar:
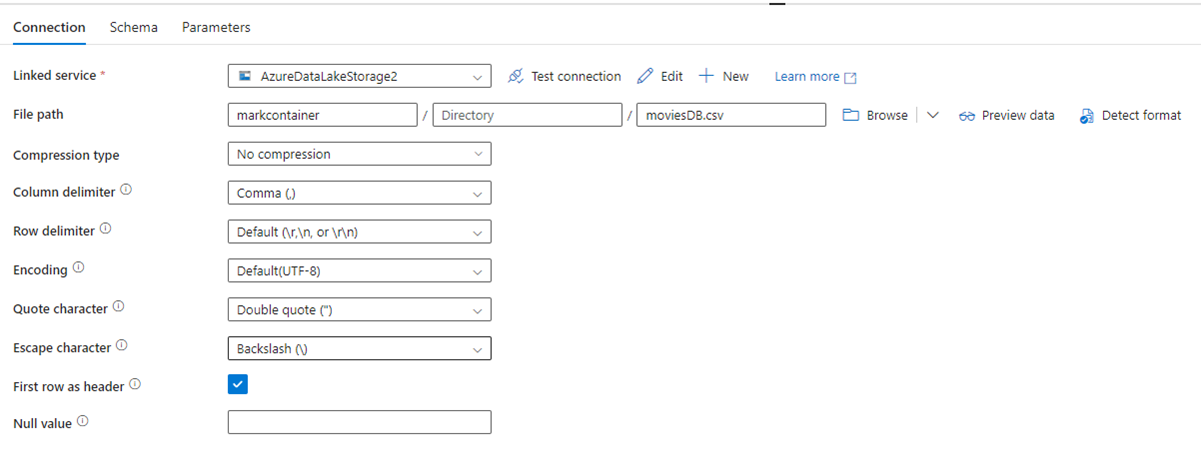
Följande bild visar konfigurationen av Kopiera-aktiviteten för Data Factory i Fabric, där komprimering och filsökväg är inkluderade i aktiviteten.
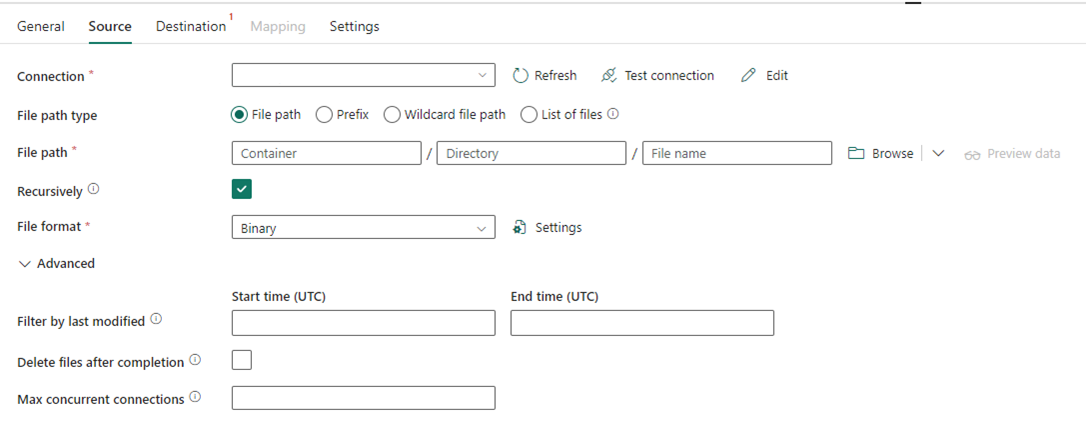
Scenario nr 2: ADF med CDC, SSIS och Airflow
CDC & Airflow i ADF är förhandsversionsfunktioner medan SSIS i ADF är en allmänt tillgänglig funktion i många år. Var och en av dessa funktioner tjänar olika dataintegreringsbehov, men kräver särskild uppmärksamhet vid migrering från ADF till Fabric. Change Data Capture (CDC) är ett ADF-koncept på toppnivå, men i Fabric ser du den här funktionen som kopieringsjobb.
Airflow är den molnhanterade Apache Airflow-funktionen ADF och finns även i Fabric Data Factory. Du bör kunna använda samma lagringsplats för Airflow-källan eller ta dina DAG:er och kopiera/klistra in koden i Fabric Airflow-erbjudandet med liten eller ingen ändring krävs.
Scenario nr 3: Git-aktiverad Data Factory-migrering till Fabric
Det är vanligt, även om det inte krävs, att dina ADF- eller Synapse-fabriker och arbetsytor är anslutna till din egen externa Git-provider i ADO eller GitHub. I det här scenariot måste du migrera dina fabriks- och arbetsyteobjekt till en Infrastruktur-arbetsyta och sedan konfigurera Git-integrering på din Infrastruktur-arbetsyta.
Infrastrukturresurser tillhandahåller två huvudsakliga sätt att aktivera CI/CD, både på arbetsytenivå: Git-integrering, där du tar med din egen Git-lagringsplats i ADO och ansluter till den från Infrastrukturresurser och inbyggda distributionspipelines där du kan höja upp kod till högre miljöer utan att behöva ta med din egen Git.
I båda fallen fungerar inte din befintliga Git-lagringsplats från ADF med Fabric. Istället måste du peka på ett nytt repository eller starta en ny distributionspipeline i Fabric och återskapa dina pipelineartefakter i Fabric.
Montera dina befintliga ADF-instanser direkt till en Fabric-arbetsyta
Tidigare talade vi om att använda aktiviteten Fabric Data Factory Invoke Pipeline som en mekanism för att underhålla befintliga ADF pipeline-investeringar och anropa dem direkt från Fabric. Inom Fabric kan du ta det liknande konceptet ett steg längre och montera hela fabriken i din Fabric-arbetsyta som ett inbyggt Fabric-objekt.
Mer information om hur du monterar användningsscenarier finns i Scenarier för samarbete och leverans av innehåll.
Att montera Din Azure Data Factory i din Fabric-arbetsyta medför många fördelar att tänka på. Om du är nybörjare på Fabric och vill behålla dina fabriker sida vid sida i samma fönsterruta, kan du montera dem i Infrastruktur så att du kan hantera båda i Fabric. Det fullständiga ADF-användargränssnittet är nu tillgängligt från din uppsatta fabrik där du helt kan övervaka, hantera och redigera dina ADF-objekt inom Fabric arbetsyta. Den här funktionen gör det mycket enklare att börja migrera dessa objekt till Fabric som inbyggda Fabric-artifakter. Den här funktionen är främst till för enkel användning och gör det enkelt att se dina ADF-fabriker i din Fabric-arbetsyta. Den faktiska körningen av pipelines, aktiviteter, integreringskörningar osv. sker dock fortfarande i dina Azure-resurser.