Migrera Spark-pooler från Azure Synapse Analytics till Fabric
Medan Azure Synapse tillhandahåller Spark-pooler erbjuder Fabric startpooler och anpassade pooler. Startpoolen kan vara ett bra val om du har en enda pool utan anpassade konfigurationer eller bibliotek i Azure Synapse och om nodstorleken Medel uppfyller dina krav. Men om du vill ha mer flexibilitet med dina Spark-poolkonfigurationer rekommenderar vi att du använder anpassade pooler. Det finns två alternativ här:
- Alternativ 1: Flytta Spark-poolen till en arbetsytas standardpool.
- Alternativ 2: Flytta Spark-poolen till en anpassad miljö i Infrastrukturresurser.
Om du har fler än en Spark-pool och du planerar att flytta dem till samma infrastrukturarbetsyta rekommenderar vi att du använder alternativ 2 och skapar flera anpassade miljöer och pooler.
Mer information om Spark-pooler finns i skillnader mellan Azure Synapse Spark och Fabric.
Förutsättningar
Om du inte redan har en skapar du en Infrastruktur-arbetsyta i klientorganisationen.
Alternativ 1: Från Spark-pool till arbetsytans standardpool
Du kan skapa en anpassad Spark-pool från din Infrastruktur-arbetsyta och använda den som standardpool på arbetsytan. Standardpoolen används av alla notebook-filer och Spark-jobbdefinitioner på samma arbetsyta.
Så här flyttar du från en befintlig Spark-pool från Azure Synapse till en standardpool för arbetsytan:
- Få åtkomst till Azure Synapse-arbetsytan: Logga in på Azure. Gå till din Azure Synapse-arbetsyta, gå till Analyspooler och välj Apache Spark-pooler.
- Leta upp Spark-poolen: Leta upp den Spark-pool som du vill flytta till Infrastrukturresurser från Apache Spark-pooler och kontrollera poolegenskaperna.
- Hämta egenskaper: Hämta egenskaper för Spark-poolen, till exempel Apache Spark-version, nodstorleksfamilj, nodstorlek eller autoskalning. Se Överväganden för Spark-pooler för att se eventuella skillnader.
-
Skapa en anpassad Spark-pool i Infrastrukturresurser:
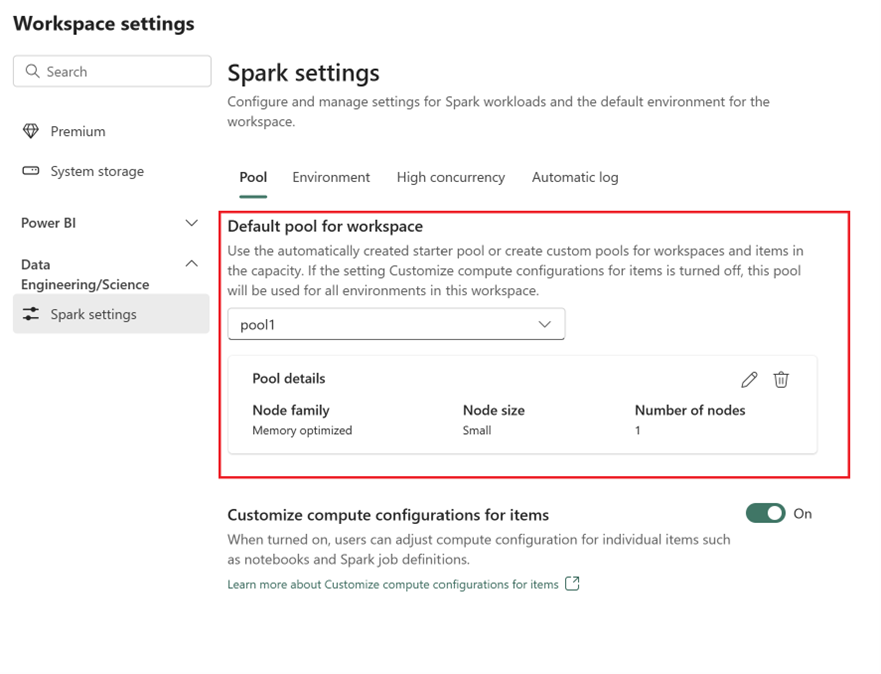
- Gå till arbetsytan Infrastruktur och välj Inställningar för arbetsyta.
- Gå till Dataingenjör ing/Science och välj Spark-inställningar.
- På fliken Pool och i avsnittet Standardpool för arbetsyta expanderar du den nedrullningsbara menyn och väljer skapa Ny pool.
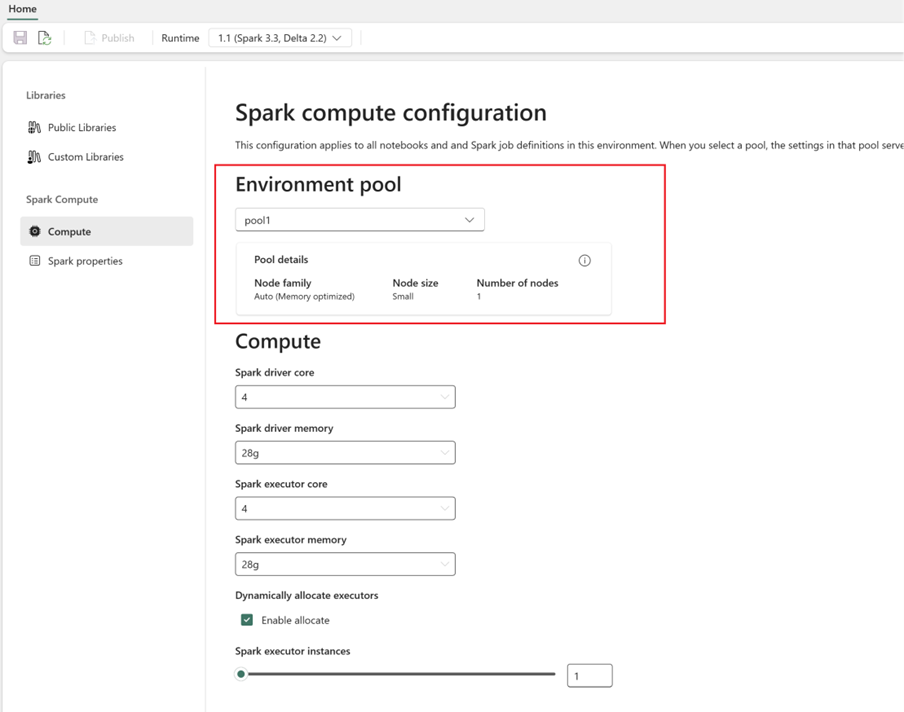
- Skapa din anpassade pool med motsvarande målvärden. Fyll i alternativ för namn, nodfamilj, nodstorlek, automatisk skalning och dynamisk körningsallokering.
-
Välj en körningsversion:
- Gå till fliken Miljö och välj den körningsversion som krävs. Se tillgängliga körningar här.
- Inaktivera alternativet Ange standardmiljö.
Kommentar
I det här alternativet stöds inte bibliotek eller konfigurationer på poolnivå. Du kan dock justera beräkningskonfigurationen för enskilda objekt som notebook-filer och Spark-jobbdefinitioner och lägga till infogade bibliotek. Om du behöver lägga till anpassade bibliotek och konfigurationer i en miljö bör du överväga en anpassad miljö.
Alternativ 2: Från Spark-pool till anpassad miljö
Med anpassade miljöer kan du konfigurera anpassade Spark-egenskaper och -bibliotek. Så här skapar du en anpassad miljö:
- Få åtkomst till Azure Synapse-arbetsytan: Logga in på Azure. Gå till din Azure Synapse-arbetsyta, gå till Analyspooler och välj Apache Spark-pooler.
- Leta upp Spark-poolen: Leta upp den Spark-pool som du vill flytta till Infrastrukturresurser från Apache Spark-pooler och kontrollera poolegenskaperna.
- Hämta egenskaper: Hämta egenskaper för Spark-poolen, till exempel Apache Spark-version, nodstorleksfamilj, nodstorlek eller autoskalning. Se Överväganden för Spark-pooler för att se eventuella skillnader.
-
Skapa en anpassad Spark-pool:
- Gå till arbetsytan Infrastruktur och välj Inställningar för arbetsyta.
- Gå till Dataingenjör ing/Science och välj Spark-inställningar.
- På fliken Pool och i avsnittet Standardpool för arbetsyta expanderar du den nedrullningsbara menyn och väljer skapa Ny pool.
- Skapa din anpassade pool med motsvarande målvärden. Fyll i alternativ för namn, nodfamilj, nodstorlek, automatisk skalning och dynamisk körningsallokering.
- Skapa ett miljöobjekt om du inte har något.
-
Konfigurera Spark-beräkning:
- I miljön går du till >
- Välj den nyligen skapade poolen för den nya miljön.
- Du kan konfigurera kärnor och minne för drivrutins- och körkörningar.
- Välj en körningsversion för miljön. Se tillgängliga körningar här.
- Klicka på Spara och publicera ändringar.
Läs mer om att skapa och använda en miljö.