Konfigurationsinställningar för Spark-beräkning i Infrastrukturmiljöer
Microsoft Fabric-Datateknik- och Datavetenskap-upplevelser fungerar på en fullständigt hanterad Spark-beräkningsplattform. Den här plattformen är utformad för att leverera oöverträffad hastighet och effektivitet. Den innehåller startpooler och anpassade pooler.
En Infrastrukturmiljö innehåller en samling konfigurationer, inklusive Spark-beräkningsegenskaper som gör det möjligt för användare att konfigurera Spark-sessionen när de är anslutna till notebook-filer och Spark-jobb. Med en miljö har du ett flexibelt sätt att anpassa beräkningskonfigurationer för att köra dina Spark-jobb. I en miljö kan du i beräkningsavsnittet konfigurera egenskaper på Spark-sessionsnivå för att anpassa minne och kärnor för exekutorer baserat på arbetsbelastningskrav.
Arbetsyteadministratörer kan aktivera eller inaktivera beräkningsanpassningar med växeln Anpassa beräkningskonfigurationer för objekt på fliken Pool i avsnittet Datateknik/Vetenskap på skärmen Inställningar för arbetsyta.
Arbetsyteadministratörer kan delegera medlemmar och deltagare att ändra standardkonfigurationerna för beräkning på sessionsnivå i infrastrukturmiljö genom att aktivera den här inställningen.
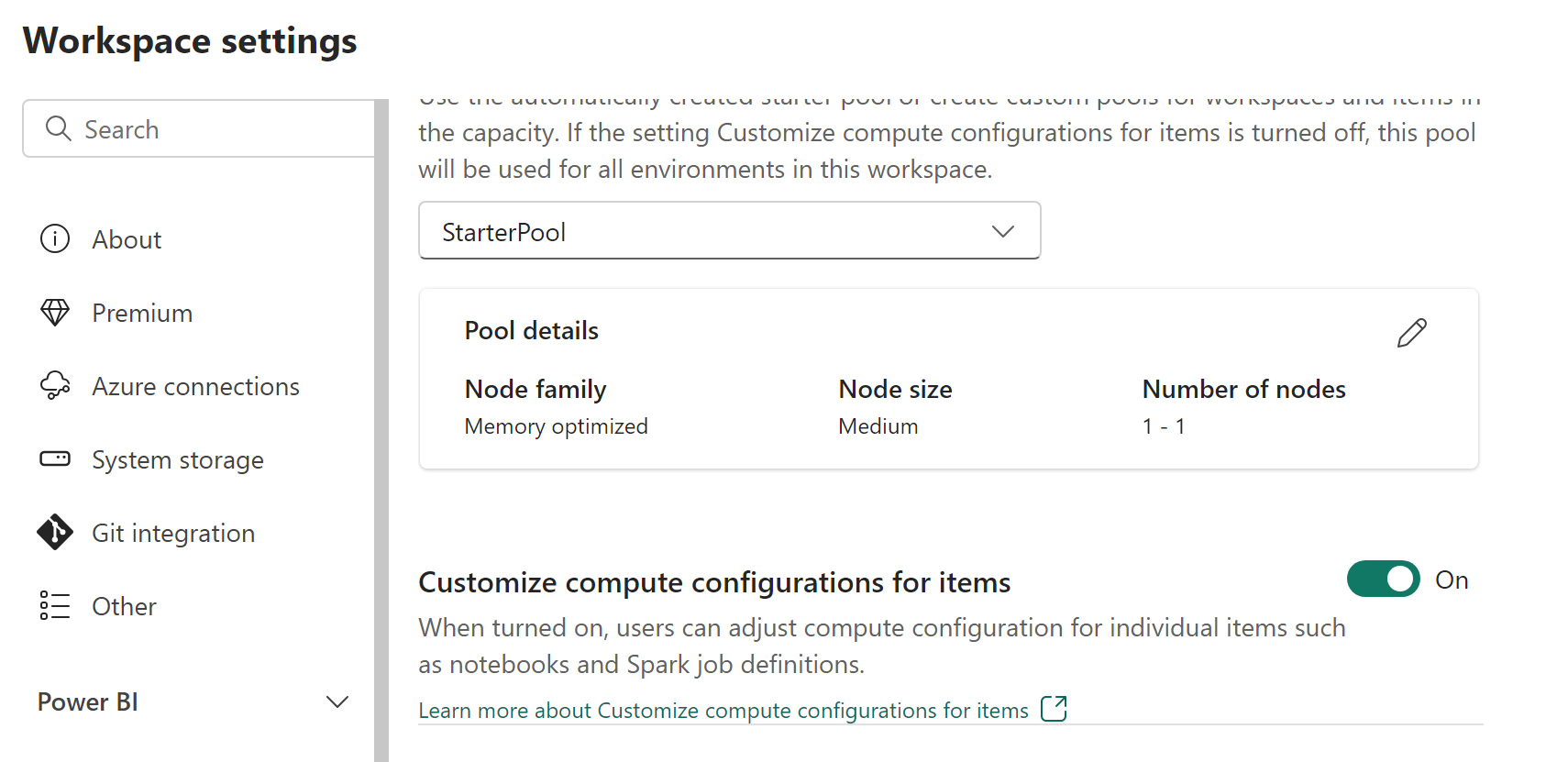
Om arbetsyteadministratören inaktiverar det här alternativet i inställningarna för arbetsytan inaktiveras beräkningsavsnittet i miljön och standardkonfigurationerna för poolberäkning för arbetsytan används för att köra Spark-jobb.
Anpassa beräkningsegenskaper på sessionsnivå i en miljö
Som användare kan du välja en pool för miljön från listan över pooler som är tillgängliga på arbetsytan Infrastruktur. Administratören för infrastrukturarbetsytan skapar standardstartpoolen och anpassade pooler.
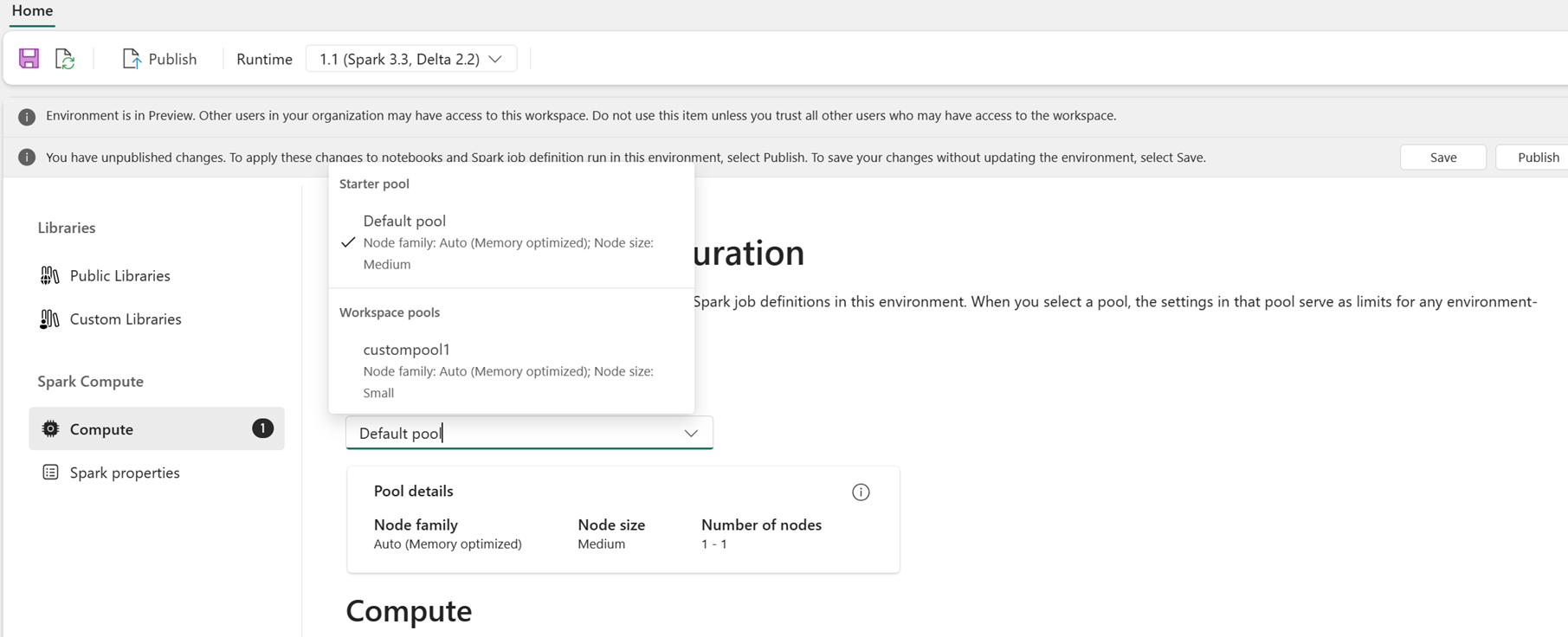
När du har valt en pool i avsnittet Beräkning kan du justera kärnor och minne för körarna inom gränserna för nodstorlekarna och gränserna för den valda poolen.
Till exempel: Du väljer en anpassad pool med nodstorleken stor, vilket är 16 virtuella Spark-kärnor, som miljöpool. Du kan sedan välja att drivrutinen/körkärnan ska vara antingen 4, 8 eller 16, baserat på dina krav på jobbnivå. För det minne som allokeras till drivrutin och köre kan du välja 28 g, 56 g eller 112 g, som alla ligger inom gränserna för en stor nodminnesgräns.
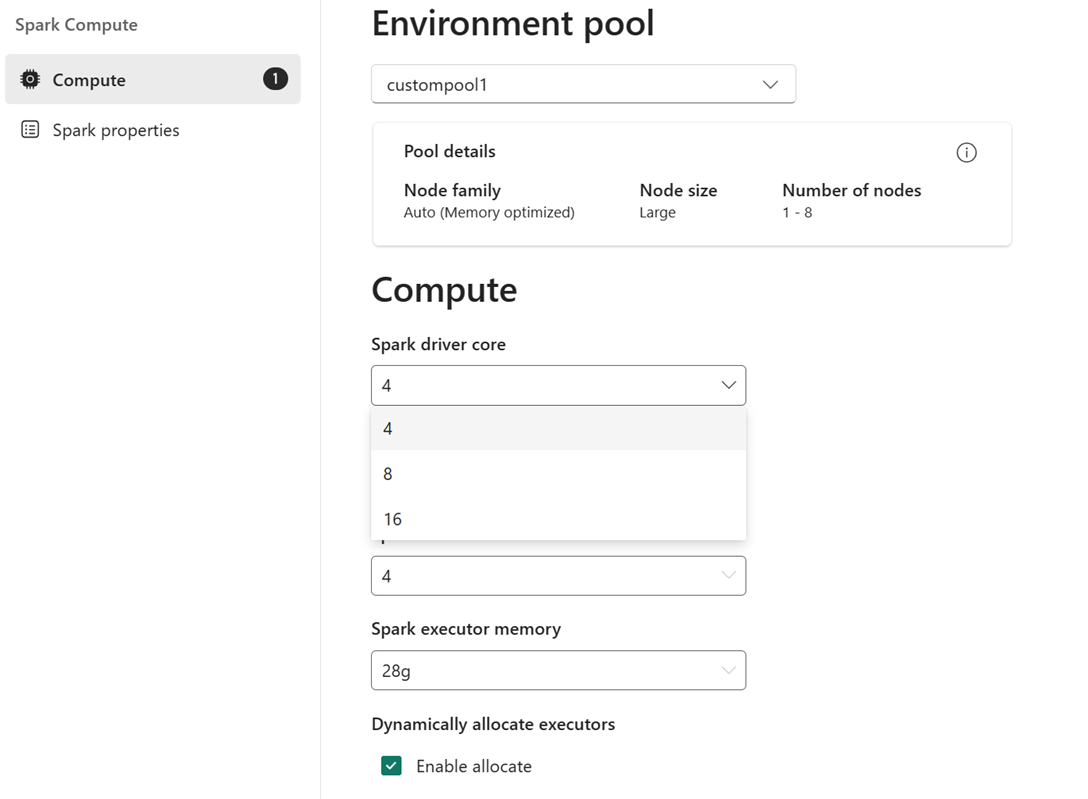
Mer information om Spark-beräkningsstorlekar och deras kärnor eller minnesalternativ finns i Vad är Spark-beräkning i Microsoft Fabric?.