Migrera Hive Metastore-metadata från Azure Synapse Analytics till Fabric
Det första steget i hive-metaarkivmigreringen (HMS) omfattar att fastställa de databaser, tabeller och partitioner som du vill överföra. Det är inte nödvändigt att migrera allt. du kan välja specifika databaser. När du identifierar databaser för migrering kontrollerar du om det finns hanterade eller externa Spark-tabeller.
För HMS-överväganden, se skillnader mellan Azure Synapse Spark och Fabric.
Kommentar
Om din ADLS Gen2 innehåller Delta-tabeller kan du också skapa en OneLake-genväg till en Delta-tabell i ADLS Gen2.
Förutsättningar
- Om du inte redan har en skapar du en Infrastruktur-arbetsyta i klientorganisationen.
- Om du inte redan har en skapar du en Infrastruktursjöhus på din arbetsyta.
Alternativ 1: Exportera och importera HMS till lakehouse-metaarkiv
Följ de här viktiga stegen för migrering:
- Steg 1: Exportera metadata från käll-HMS
- Steg 2: Importera metadata till Fabric Lakehouse
- Steg efter migreringen: Verifiera innehåll
Kommentar
Skript kopierar endast Spark-katalogobjekt till Fabric Lakehouse. Antagandet är att data redan har kopierats (till exempel från lagerplatsen till ADLS Gen2) eller är tillgängliga för hanterade och externa tabeller (till exempel via genvägar – föredragna) till Fabric Lakehouse.
Steg 1: Exportera metadata från käll-HMS
Fokus för steg 1 är att exportera metadata från käll-HMS till avsnittet Filer i fabric lakehouse. Den här processen är följande:
1.1) Importera HMS-metadata exportera notebook-filen till din Azure Synapse-arbetsyta. Den här notebook-filen frågar och exporterar HMS-metadata för databaser, tabeller och partitioner till en mellanliggande katalog i OneLake (funktioner ingår inte ännu). Sparks interna katalog-API används i det här skriptet för att läsa katalogobjekt.
1.2) Konfigurera parametrarna i det första kommandot för att exportera metadatainformation till en mellanliggande lagring (OneLake). Följande kodfragment används för att konfigurera käll- och målparametrarna. Se till att ersätta dem med dina egna värden.
// Azure Synapse workspace config var SynapseWorkspaceName = "<synapse_workspace_name>" var DatabaseNames = "<db1_name>;<db2_name>" var SkipExportTablesWithUnrecognizedType:Boolean = false // Fabric config var WorkspaceId = "<workspace_id>" var LakehouseId = "<lakehouse_id>" var ExportFolderName = f"export/${SynapseWorkspaceName}/sparkCatalogMetadata" var OutputFolder = f"abfss://${WorkspaceId}@onelake.dfs.fabric.microsoft.com/${LakehouseId}/Files/${ExportFolderName}/"1.3) Kör alla notebook-kommandon för att exportera katalogobjekt till OneLake. När cellerna har slutförts skapas den här mappstrukturen under den mellanliggande utdatakatalogen.
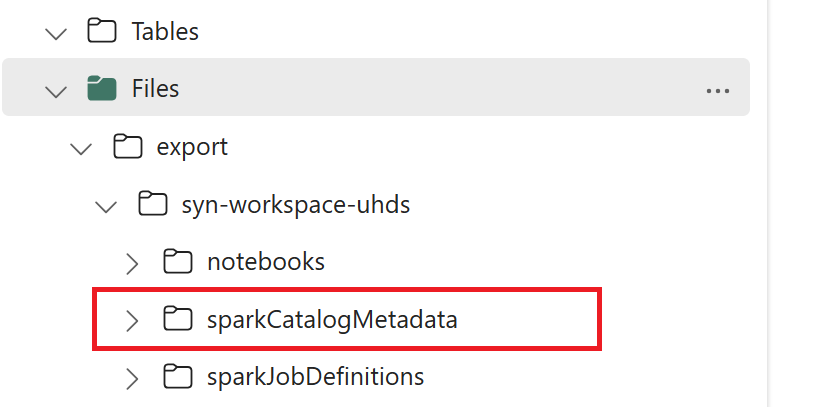
Steg 2: Importera metadata till Fabric Lakehouse
Steg 2 är när de faktiska metadata importeras från mellanliggande lagring till Fabric Lakehouse. Utdata från det här steget är att alla HMS-metadata (databaser, tabeller och partitioner) ska migreras. Den här processen är följande:
2.1) Skapa en genväg i avsnittet Filer i lakehouse. Den här genvägen måste peka på Spark-källlagerkatalogen och används senare för att ersätta Spark-hanterade tabeller. Se genvägsexempel som pekar på Spark-lagerkatalogen:
- Genväg till Azure Synapse Spark-lagerkatalogen:
abfss://<container>@<storage_name>.dfs.core.windows.net/synapse/workspaces/<workspace_name>/warehouse - Genväg till Azure Databricks-lagerkatalogen:
dbfs:/mnt/<warehouse_dir> - Genväg till HDInsight Spark-lagerkatalogen:
abfss://<container>@<storage_name>.dfs.core.windows.net/apps/spark/warehouse
- Genväg till Azure Synapse Spark-lagerkatalogen:
2.2) Importera HMS-metadataimport notebook-fil till din infrastrukturarbetsyta. Importera den här notebook-filen för att importera databas-, tabell- och partitionsobjekt från mellanliggande lagring. Sparks interna katalog-API används i det här skriptet för att skapa katalogobjekt i Infrastrukturresurser.
2.3) Konfigurera parametrarna i det första kommandot. När du skapar en hanterad tabell i Apache Spark lagras data för tabellen på en plats som hanteras av Själva Spark, vanligtvis i Sparks lagerkatalog. Den exakta platsen bestäms av Spark. Detta står i kontrast till externa tabeller, där du anger platsen och hanterar underliggande data. När du migrerar metadata för en hanterad tabell (utan att flytta faktiska data) innehåller metadata fortfarande den ursprungliga platsinformationen som pekar på den gamla Spark-lagerkatalogen. För hanterade tabeller
WarehouseMappingsanvänds därför för att ersätta med hjälp av genvägen som skapades i steg 2.1. Alla källhanterade tabeller konverteras som externa tabeller med hjälp av det här skriptet.LakehouseIdrefererar till lakehouse som skapades i steg 2.1 som innehåller genvägar.// Azure Synapse workspace config var ContainerName = "<container_name>" var StorageName = "<storage_name>" var SynapseWorkspaceName = "<synapse_workspace_name>" // Fabric config var WorkspaceId = "<workspace_id>" var LakehouseId = "<lakehouse_id>" var ExportFolderName = f"export/${SynapseWorkspaceName}/sparkCatalogMetadata" var ShortcutName = "<warehouse_dir_shortcut_name>" var WarehouseMappings:Map[String, String] = Map( f"abfss://${ContainerName}@${StorageName}.dfs.core.windows.net/synapse/workspaces/${SynapseWorkspaceName}/warehouse"-> f"abfss://${WorkspaceId}@onelake.dfs.fabric.microsoft.com/${LakehouseId}/Files/${ShortcutName}" ) var OutputFolder = f"abfss://${WorkspaceId}@onelake.dfs.fabric.microsoft.com/${LakehouseId}/Files/${ExportFolderName}/" var DatabasePrefix = "" var TablePrefix = "" var IgnoreIfExists = true2.4) Kör alla notebook-kommandon för att importera katalogobjekt från mellanliggande sökväg.
Kommentar
När du importerar flera databaser kan du (i) skapa ett lakehouse per databas (metoden som används här) eller (ii) flytta alla tabeller från olika databaser till ett enda lakehouse. För det senare kan alla migrerade tabeller vara <lakehouse>.<db_name>_<table_name>, och du måste justera importanteckningsboken i enlighet med detta.
Steg 3: Verifiera innehåll
Steg 3 är där du verifierar att metadata har migrerats. Se olika exempel.
Du kan se de databaser som importeras genom att köra:
%%sql
SHOW DATABASES
Du kan kontrollera alla tabeller i ett lakehouse (databas) genom att köra:
%%sql
SHOW TABLES IN <lakehouse_name>
Du kan se information om en viss tabell genom att köra:
%%sql
DESCRIBE EXTENDED <lakehouse_name>.<table_name>
Du kan också se alla importerade tabeller i avsnittet Användargränssnittstabeller för Lakehouse Explorer för varje lakehouse.
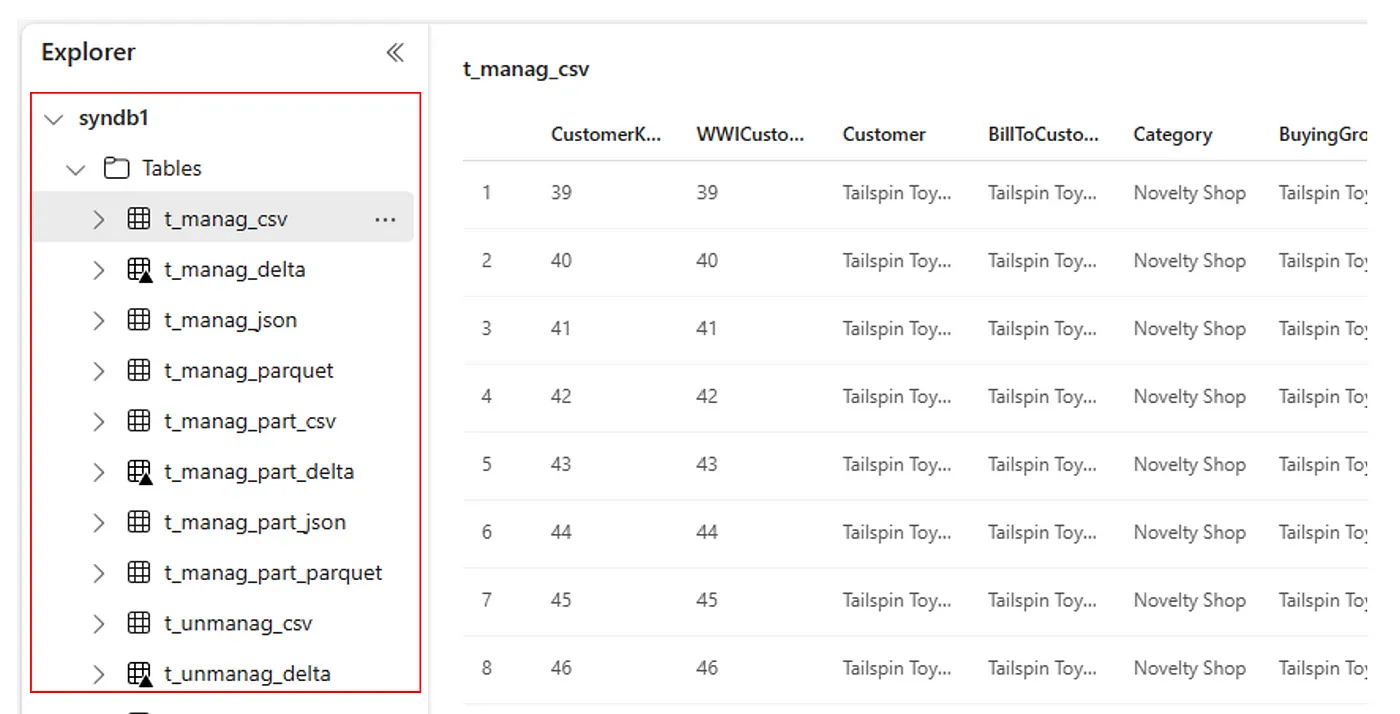
Övriga beaktanden
- Skalbarhet: Lösningen här använder det interna Spark-katalog-API:et för import/export, men den ansluter inte direkt till HMS för att hämta katalogobjekt, så lösningen kan inte skalas bra om katalogen är stor. Du skulle behöva ändra exportlogik med hjälp av HMS DB.
- Datanoggrannhet: Det finns ingen isoleringsgaranti, vilket innebär att om Spark-beräkningsmotorn gör samtidiga ändringar i metaarkivet medan migreringsanteckningsboken körs kan inkonsekventa data introduceras i Fabric Lakehouse.
Relaterat innehåll
- Infrastrukturresurser jämfört med Azure Synapse Spark
- Läs mer om migreringsalternativ för Spark-pooler, konfigurationer, bibliotek, notebook-filer och Spark-jobbdefinitioner