Migrera Spark-jobbdefinition från Azure Synapse till Fabric
Om du vill flytta Spark-jobbdefinitioner (SJD) från Azure Synapse till Fabric har du två olika alternativ:
- Alternativ 1: Skapa Spark-jobbdefinition manuellt i Infrastrukturresurser.
- Alternativ 2: Du kan använda ett skript för att exportera Spark-jobbdefinitioner från Azure Synapse och importera dem i Infrastruktur med hjälp av API:et.
För definitionsöverväganden för Spark-jobb refererar du till skillnader mellan Azure Synapse Spark och Fabric.
Förutsättningar
Om du inte redan har en skapar du en Infrastruktur-arbetsyta i klientorganisationen.
Alternativ 1: Skapa Spark-jobbdefinition manuellt
Så här exporterar du en Spark-jobbdefinition från Azure Synapse:
- Öppna Synapse Studio: Logga in i Azure. Gå till din Azure Synapse-arbetsyta och öppna Synapse Studio.
- Leta upp Jobbet Python/Scala/R Spark: Leta upp och identifiera den Python/Scala/R Spark-jobbdefinition som du vill migrera.
-
Exportera jobbdefinitionskonfigurationen:
- Öppna Spark-jobbdefinitionen i Synapse Studio.
- Exportera eller anteckna konfigurationsinställningarna, inklusive plats för skriptfiler, beroenden, parametrar och annan relevant information.
Så här skapar du en ny Spark-jobbdefinition (SJD) baserat på den exporterade SJD-informationen i Infrastrukturresurser:
- Access Fabric-arbetsyta: Logga in på Infrastrukturresurser och få åtkomst till din arbetsyta.
-
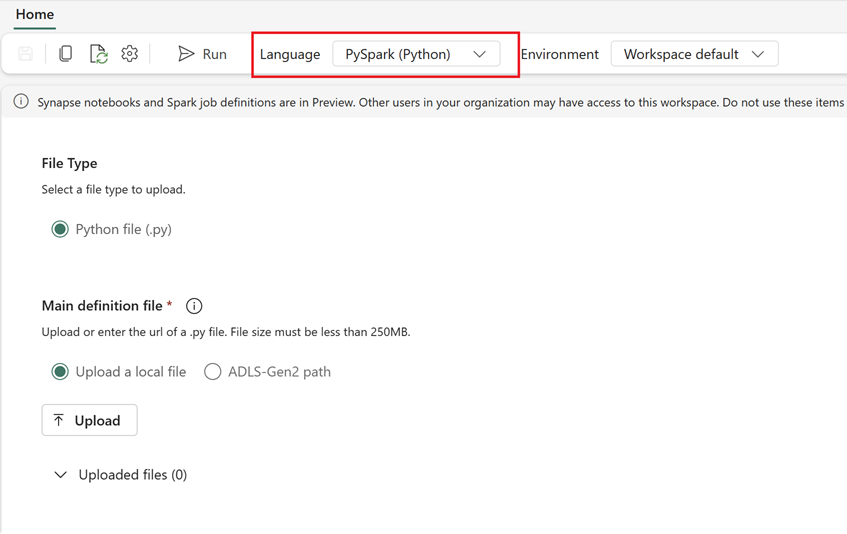
Skapa en ny Spark-jobbdefinition i Infrastrukturresurser:
- I Infrastruktur går du till startsidan för Dataingenjör ing.
- Välj Spark-jobbdefinition.
- Konfigurera jobbet med hjälp av den information som du exporterade från Synapse, inklusive skriptplats, beroenden, parametrar och klusterinställningar.
- Anpassa och testa: Gör alla nödvändiga anpassningar av skriptet eller konfigurationen för att passa Fabric-miljön. Testa jobbet i Infrastrukturresurser för att säkerställa att det körs korrekt.
När Spark-jobbdefinitionen har skapats verifierar du beroenden:
- Se till att använda samma Spark-version.
- Verifiera förekomsten av huvuddefinitionsfilen.
- Verifiera förekomsten av de refererade filerna, beroendena och resurserna.
- Länkade tjänster, datakällanslutningar och monteringspunkter.
Läs mer om hur du skapar en Apache Spark-jobbdefinition i Infrastrukturresurser.
Alternativ 2: Använd Infrastruktur-API:et
Följ de här viktiga stegen för migrering:
- Förutsättningar.
- Steg 1: Exportera Spark-jobbdefinition från Azure Synapse till OneLake (.json).
- Steg 2: Importera Spark-jobbdefinition automatiskt till Infrastrukturresurser med hjälp av Infrastruktur-API:et.
Förutsättningar
Kraven omfattar åtgärder som du måste tänka på innan du påbörjar migreringen av Spark-jobbdefinitionen till Infrastrukturresurser.
- En infrastrukturarbetsyta.
- Om du inte redan har en skapar du en Infrastruktursjöhus på din arbetsyta.
Steg 1: Exportera Spark-jobbdefinition från Azure Synapse-arbetsytan
Fokus för steg 1 är att exportera Spark-jobbdefinitionen från Azure Synapse-arbetsytan till OneLake i json-format. Den här processen är följande:
- 1.1) Importera SJD-migreringsanteckningsboken till Arbetsytan Infrastruktur . Den här notebook-filen exporterar alla Spark-jobbdefinitioner från en viss Azure Synapse-arbetsyta till en mellanliggande katalog i OneLake. Synapse API används för att exportera SJD.
- 1.2) Konfigurera parametrarna i det första kommandot för att exportera Spark-jobbdefinitionen till en mellanliggande lagring (OneLake). Detta exporterar endast json-metadatafilen. Följande kodfragment används för att konfigurera käll- och målparametrarna. Se till att ersätta dem med dina egna värden.
# Azure config
azure_client_id = "<client_id>"
azure_tenant_id = "<tenant_id>"
azure_client_secret = "<client_secret>"
# Azure Synapse workspace config
synapse_workspace_name = "<synapse_workspace_name>"
# Fabric config
workspace_id = "<workspace_id>"
lakehouse_id = "<lakehouse_id>"
export_folder_name = f"export/{synapse_workspace_name}"
prefix = "" # this prefix is used during import {prefix}{sjd_name}
output_folder = f"abfss://{workspace_id}@onelake.dfs.fabric.microsoft.com/{lakehouse_id}/Files/{export_folder_name}"
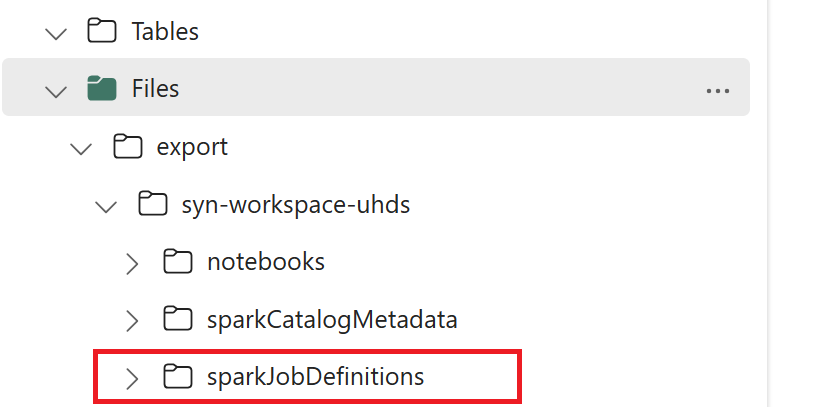
- 1.3) Kör de två första cellerna i export-/importanteckningsboken för att exportera Metadata för Spark-jobbdefinition till OneLake. När cellerna har slutförts skapas den här mappstrukturen under den mellanliggande utdatakatalogen.
Steg 2: Importera Spark-jobbdefinition till Infrastrukturresurser
Steg 2 är när Spark-jobbdefinitioner importeras från mellanliggande lagring till arbetsytan Infrastruktur. Den här processen är följande:
- 2.1) Verifiera konfigurationerna i 1.2 för att säkerställa att rätt arbetsyta och prefix anges för att importera Spark-jobbdefinitionerna.
- 2.2) Kör den tredje cellen i export-/importanteckningsboken för att importera alla Spark-jobbdefinitioner från mellanliggande plats.
Kommentar
Exportalternativet matar ut en json-metadatafil. Se till att körbara filer, referensfiler och argument för Spark-jobbdefinition är tillgängliga från Infrastrukturresurser.