Beräkningsresurser för notebook-filer
Den här artikeln beskriver alternativen för beräkningsresurser för notebook-filer. Du kan köra en notebook på en beräkningsresurs för allmän användning, serverlös beräkning, eller, för SQL-kommandon, använda ett SQL-lager, en beräkningsresurs optimerad för SQL-analys. Mer information om beräkningstyper finns i Compute.
Serverlös beräkning för notebook-filer
Med serverlös beräkning kan du snabbt ansluta notebook-filen till databehandlingsresurser på begäran.
Om du vill ansluta till den serverlösa beräkningen klickar du på den nedrullningsbara menyn Anslut i anteckningsboken och väljer Serverlös.
Mer information finns i Serverlös beräkning för notebook-filer .
Koppla en notebook till en universal beräkningsresurs
Om du vill koppla en anteckningsbok till en allmän beräkningsresurs behöver du behörighet att koppla till på beräkningsresursen.
Viktigt!
Så länge en notebook-fil är kopplad till en beräkningsresurs har alla användare med behörigheten CAN RUN i notebook-filen implicit behörighet att komma åt beräkningsresursen.
Om du vill koppla en notebook-fil till en beräkningsresurs klickar du på beräkningsväljaren i notebook-verktygsfältet och väljer resursen på den nedrullningsbara menyn.
Menyn visar ett urval av beräknings- och SQL-lager för alla ändamål som du har använt nyligen eller som körs för närvarande.
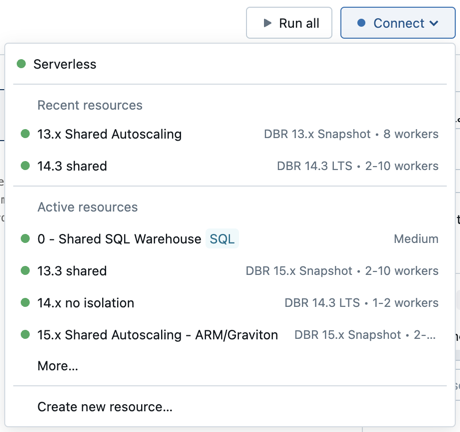
Om du vill välja från alla tillgängliga beräkningar klickar du på Mer.... Välj från tillgängliga allmänna beräknings- eller SQL-lager.
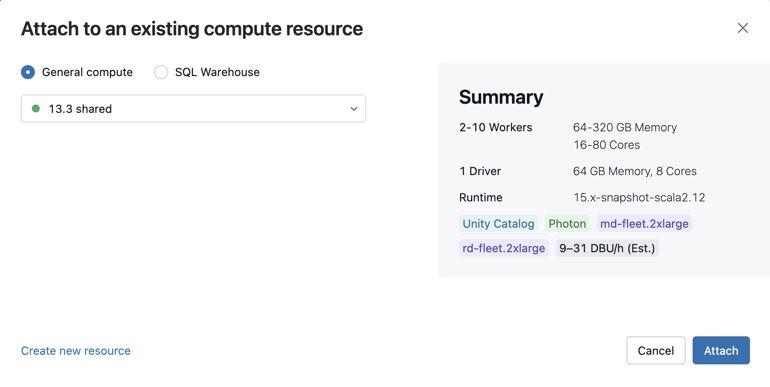
Du kan också skapa en ny beräkningsresurs för alla syften genom att välja Skapa ny resurs... från listrutan.
Viktigt!
En bifogad notebook-fil har följande Apache Spark-variabler definierade.
| Klass | Variabelnamn |
|---|---|
SparkContext |
sc |
SQLContext/HiveContext |
sqlContext |
SparkSession (Spark 2.x) |
spark |
Skapa inte en SparkSession, SparkContext, eller SQLContext. Detta leder till inkonsekvent beteende.
Använda en notebook-fil med ett SQL-lager
När en notebook-fil är ansluten till ett SQL-lager kan du köra SQL- och Markdown-celler. Om du kör en cell på något annat språk (till exempel Python eller R) genereras ett fel. SQL-celler som körs på ett SQL-lager visas i SQL-lagrets frågehistorik. Användaren som körde en fråga kan visa frågeprofilen från notebook-filen genom att klicka på den förflutna tiden längst ned i utdata.
För att köra en notebook-fil krävs ett proffs- eller serverlöst SQL-lager. Du måste ha åtkomst till arbetsytan och SQL-lagret.
Så här kopplar du en notebook-fil till ett SQL-lager :
Klicka på beräkningsväljaren i notebook-verktygsfältet. Den nedrullningsbara menyn visar beräkningsresurser som för närvarande körs eller som du har använt nyligen. SQL-lager markeras med
 .
.Välj ett SQL-lager på menyn.
Om du vill se alla tillgängliga SQL-lager väljer du Mer... i listrutan. En dialogruta visas som visar beräkningsresurser som är tillgängliga för notebook-filen. Välj SQL Warehouse, välj det databaslager du vill använda och klicka på Koppla.
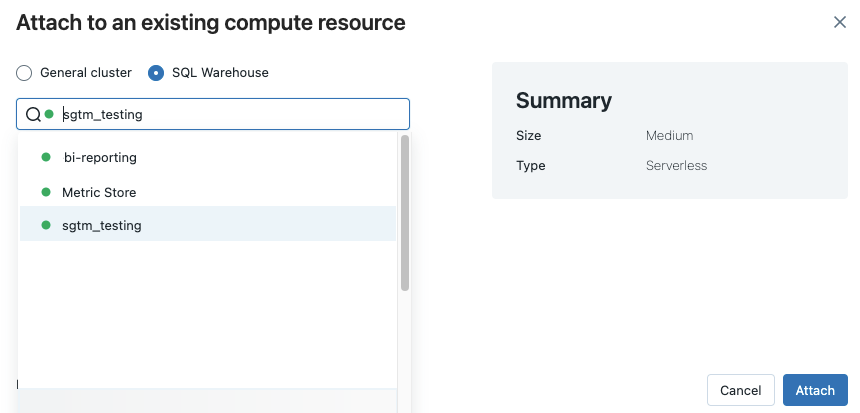
Du kan också välja ett SQL-lager som beräkningsresurs för en SQL-notebook-fil när du skapar ett arbetsflöde eller ett schemalagt jobb.
Begränsningar för SQL-lager
Mer information finns i Kända begränsningar i Databricks-notebook-filer .
Koppla från en notebook-fil
Om du vill koppla från en notebook från en beräkningsresurs klickar du på beräkningsväljaren i verktygsfältet för notebooken och hovrar över den anslutna resursen i listan för att visa en sidomeny. På sidomenyn väljer du Koppla från.
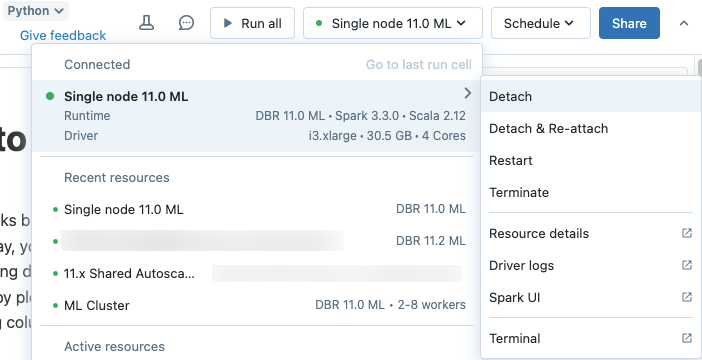
Du kan också koppla från notebookar från en generell beräkningsresurs med hjälp av fliken Notebooks på beräkningsdetaljsidan.
Dricks
Azure Databricks rekommenderar att du kopplar bort oanvända anteckningsböcker från beräkningsresurser. Detta frigör minne på drivrutinen.