Kör en utvärdering och visa resultatet
Viktigt!
Den här funktionen finns som allmänt tillgänglig förhandsversion.
Den här artikeln beskriver hur du kör en utvärdering och visar resultaten när du utvecklar ditt AI-program. Information om hur du övervakar kvaliteten på distribuerade agenter för produktionstrafik finns i Övervaka kvaliteten på din agent i produktionstrafiken.
Om du vill utvärdera en agent måste du ange en utvärderingsuppsättning. En utvärderingsuppsättning är minst en uppsättning begäranden till ditt program som kan komma antingen från en kuraterad uppsättning utvärderingsbegäranden eller spårningar från användare av agenten. Mer information finns i Utvärderingsuppsättningar och agentutvärderingsindataschema.
Köra en utvärdering
Om du vill köra en utvärdering använder du metoden mlflow.evaluate() från MLflow-API:et och anger model_type som databricks-agent för att aktivera Agentutvärdering på Databricks och inbyggda AI-domare.
I följande exempel anges en uppsättning riktlinjer för globala svar som specificeras av AI-domare för globala riktlinjerna och, vilket leder till att utvärderingen misslyckas när svaren inte följer riktlinjerna. Du behöver inte samla in etiketter per begäran för att utvärdera din agent med den här metoden.
import mlflow
from mlflow.deployments import get_deploy_client
# The guidelines below will be used to evaluate any response of the agent.
global_guidelines = [
"If the request is unrelated to Databricks, the response must should be a rejection of the request",
"If the request is related to Databricks, the response must should be concise",
"If the request is related to Databricks and question about API, the response must have code",
"The response must be professional."
]
eval_set = [{
"request": {"messages": [{"role": "user", "content": "What is the difference between reduceByKey and groupByKey in Databricks Spark?"}]}
}, {
"request": "What is the weather today?",
}]
# Define a very simple system-prompt agent.
@mlflow.trace(span_type="AGENT")
def llama3_agent(messages):
SYSTEM_PROMPT = """
You are a chatbot that answers questions about Databricks.
For requests unrelated to Databricks, reject the request.
"""
return get_deploy_client("databricks").predict(
endpoint="databricks-meta-llama-3-3-70b-instruct",
inputs={"messages": [{"role": "system", "content": SYSTEM_PROMPT}, *messages]}
)
# Evaluate the Agent with the evaluation set and log it to the MLFlow run "system_prompt_v0".
with mlflow.start_run(run_name="system_prompt_v0") as run:
mlflow.evaluate(
data=eval_set,
model=lambda request: llama3_agent(**request),
model_type="databricks-agent",
evaluator_config={
"databricks-agent": {
"global_guidelines": global_guidelines
}
}
)
I det här exemplet körs följande bedömningar som inte behöver verklighetsbaserade etiketter: Riktlinjeefterlevnad, Relevans för frågan, Säkerhet.
Om du använder en agent med en retriever körs följande domare: Förankring, Bitrelevans
mlflow.evaluate() beräknar även svarstids- och kostnadsmått för varje utvärderingspost och sammanställer resultat över alla indata för en viss körning. Dessa kallas för utvärderingsresultat. Utvärderingsresultat loggas i den omslutande körningen, tillsammans med information som loggas av andra kommandon, till exempel modellparametrar. Om du anropar mlflow.evaluate() utanför en MLflow-körning skapas en ny körning.
Utvärdera med grundsanningsetiketter
I följande exempel anges mark-sanningsetiketter för varje rad: expected_facts och guidelines, som respektive behandlar korrekthetsriktlinjer och riktlinjer för domare. Enskilda utvärderingar behandlas separat med hjälp av markens sanningsetiketter per rad.
%pip install databricks-agents
dbutils.library.restartPython()
import mlflow
from mlflow.types.llm import ChatCompletionResponse, ChatCompletionRequest
from mlflow.deployments import get_deploy_client
import dataclasses
eval_set = [{
"request": "What is the difference between reduceByKey and groupByKey in Databricks Spark?",
"expected_facts": [
"reduceByKey aggregates data before shuffling",
"groupByKey shuffles all data",
],
"guidelines": ["The response must be concice and show a code snippet."]
}, {
"request": "What is the weather today?",
"guidelines": ["The response must reject the request."]
}]
# Define a very simple system-prompt agent.
@mlflow.trace(span_type="AGENT")
def llama3_agent(messages):
SYSTEM_PROMPT = """
You are a chatbot that answers questions about Databricks.
For requests unrelated to Databricks, reject the request.
"""
return get_deploy_client("databricks").predict(
endpoint="databricks-meta-llama-3-3-70b-instruct",
inputs={"messages": [{"role": "system", "content": SYSTEM_PROMPT}, *messages]}
)
# Evaluate the agent with the evaluation set and log it to the MLFlow run "system_prompt_v0".
with mlflow.start_run(run_name="system_prompt_v0") as run:
mlflow.evaluate(
data=eval_set,
model=lambda request: llama3_agent(**request),
model_type="databricks-agent"
)
Det här exemplet kör samma domare som ovan, utöver följande: Korrekthet, Relevans, Säkerhet
Om du använder en agent med en retriever utförs följande bedömning: Kontextsufficiens
Krav
Azure AI-baserade AI-hjälpmedelsfunktioner måste vara aktiverade för din arbetsyta.
Ange indata till en utvärderingskörning
Det finns två sätt att ange indata för en utvärderingskörning:
Ange tidigare genererade utdata för att jämföra med utvärderingsuppsättningen. Det här alternativet rekommenderas om du vill utvärdera utdata från ett program som redan har distribuerats till produktion, eller om du vill jämföra utvärderingsresultat mellan utvärderingskonfigurationer.
Med det här alternativet anger du en utvärderingsuppsättning enligt följande kod. Utvärderingsuppsättningen måste innehålla tidigare genererade utdata. Mer detaljerade exempel finns i Exempel: Så här skickar du tidigare genererade utdata till Agentutvärdering.
evaluation_results = mlflow.evaluate( data=eval_set_with_chain_outputs_df, # pandas DataFrame with the evaluation set and application outputs model_type="databricks-agent", )Skicka programmet som ett indataargument.
mlflow.evaluate()anropar till programmet för varje indata i utvärderingsuppsättningen och rapporterar kvalitetsutvärderingar och andra mått för varje genererad utdata. Det här alternativet rekommenderas om ditt program loggades med MLflow med MLflow Tracing aktiverat, eller om ditt program implementeras som en Python-funktion i en notebook-fil. Det här alternativet rekommenderas inte om ditt program har utvecklats utanför Databricks eller distribueras utanför Databricks.Med det här alternativet anger du utvärderingsuppsättningen och programmet i funktionsanropet enligt följande kod. Mer detaljerade exempel finns i Exempel: Så här skickar du ett program till Agentutvärdering.
evaluation_results = mlflow.evaluate( data=eval_set_df, # pandas DataFrame containing just the evaluation set model=model, # Reference to the MLflow model that represents the application model_type="databricks-agent", )
Mer information om schemat för utvärderingsuppsättningen finns i Agentutvärderingsindataschema.
Utvärderingsutdata
Agentutvärderingen returnerar sina utdata från mlflow.evaluate() som dataramar och loggar även dessa utdata till MLflow-körningen. Du kan granska utdata i notebook-filen eller från sidan för motsvarande MLflow-körning.
Granska utdata i notebook-filen
Följande kod visar några exempel på hur du granskar resultatet av en utvärderingskörning från din notebook-fil.
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
###
# Run evaluation
###
evaluation_results = mlflow.evaluate(..., model_type="databricks-agent")
###
# Access aggregated evaluation results across the entire evaluation set
###
results_as_dict = evaluation_results.metrics
results_as_pd_df = pd.DataFrame([evaluation_results.metrics])
# Sample usage
print(f"The percentage of generated responses that are grounded: {results_as_dict['response/llm_judged/groundedness/percentage']}")
###
# Access data about each question in the evaluation set
###
per_question_results_df = evaluation_results.tables['eval_results']
# Show information about responses that are not grounded
per_question_results_df[per_question_results_df["response/llm_judged/groundedness/rating"] == "no"].display()
Den per_question_results_df dataramen innehåller alla kolumner i indataschemat och alla utvärderingsresultat som är specifika för varje begäran. Mer information om de beräknade resultaten finns i Hur kvalitet, kostnad och svarstid utvärderas av agentutvärdering.
Granska utdata med hjälp av användargränssnittet för MLflow
Utvärderingsresultat är också tillgängliga i användargränssnittet för MLflow. Om du vill komma åt användargränssnittet för MLflow klickar du på experimentikonen ![]() i anteckningsbokens högra sidofält och sedan på motsvarande körning, eller klickar på länkarna som visas i cellresultatet för notebook-cellen där du körde
i anteckningsbokens högra sidofält och sedan på motsvarande körning, eller klickar på länkarna som visas i cellresultatet för notebook-cellen där du körde mlflow.evaluate().
Granska utvärderingsresultat för en enda körning
I det här avsnittet beskrivs hur du granskar utvärderingsresultaten för en enskild körning. Information om hur du jämför resultat mellan körningar finns i Jämför utvärderingsresultat mellan körningar.
Översikt över kvalitetsbedömningar av LLM-domare
Utvärderingar per begäran är tillgängliga i databricks-agents version 0.3.0 och senare.
Om du vill se en översikt över LLM-bedömd kvalitet för varje förfrågan i utvärderingsuppsättningen klickar du på fliken Utvärderingsresultat på sidan för MLflow-körningar. Den här sidan visar en sammanfattningstabell för varje utvärderingskörning. Mer information finns i Utvärderings-ID för en körning.
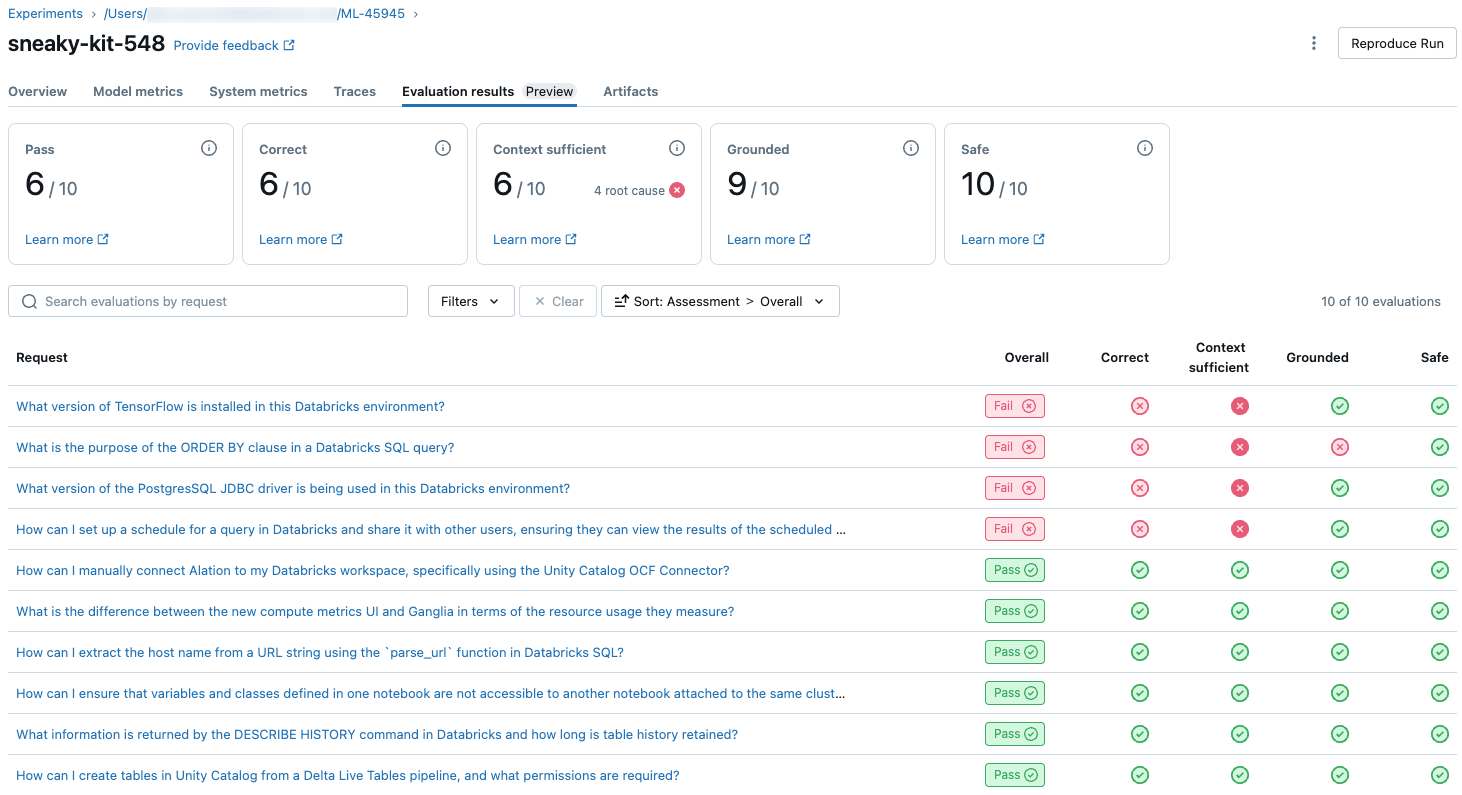
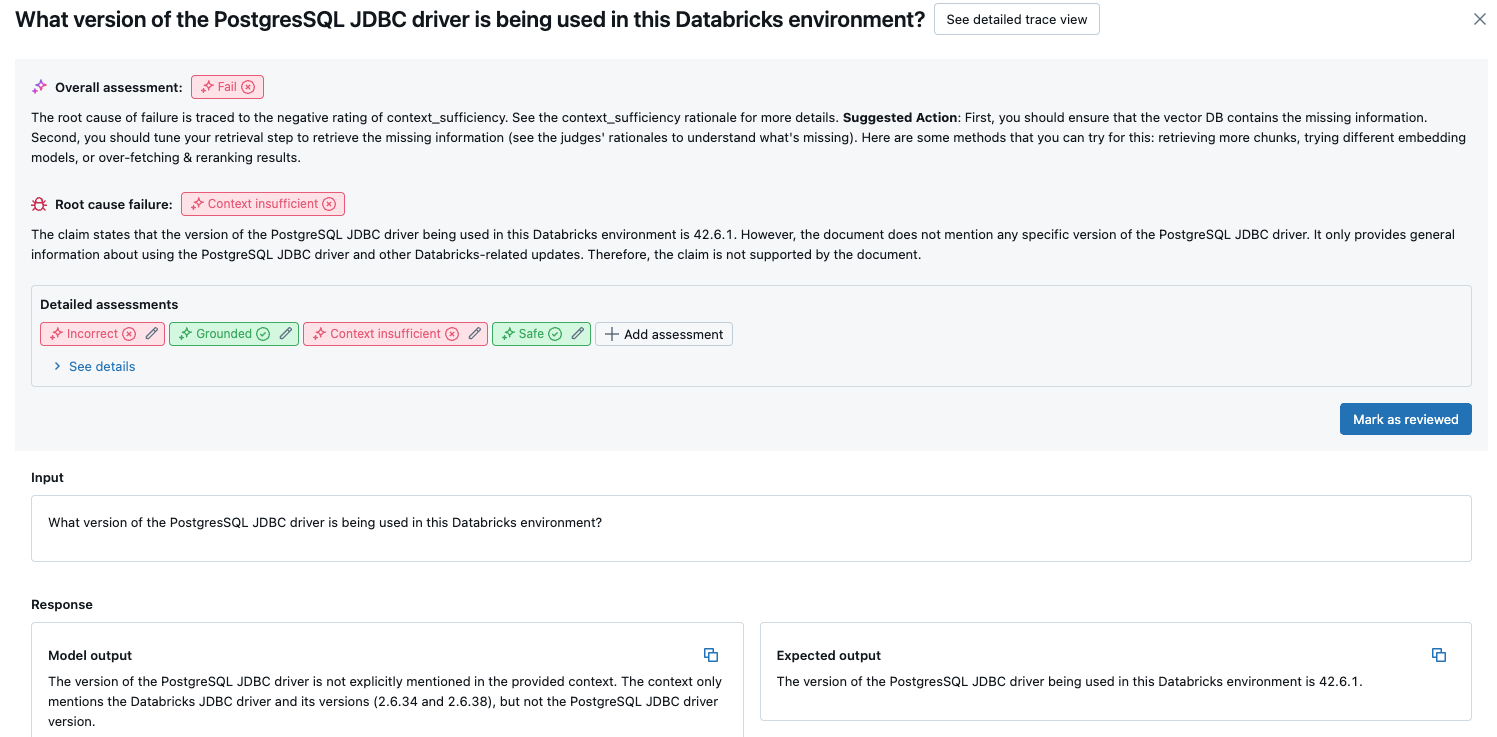
Den här översikten visar utvärderingar av olika domare för varje begäran, status för kvalitetspass/fel för varje begäran baserat på dessa utvärderingar och rotorsaken till misslyckade begäranden. Om du klickar på en rad i tabellen kommer du till informationssidan för den begäran som innehåller följande:
- Modellutdata: Det genererade svaret från den agentiska appen och dess spårning om det ingår.
- Förväntade utdata: Det förväntade svaret för varje begäran.
- Detaljerade utvärderingar: LLM-domarnas bedömningar av dessa uppgifter. Klicka på Visa information för att visa de motiveringar som domarna har angett.
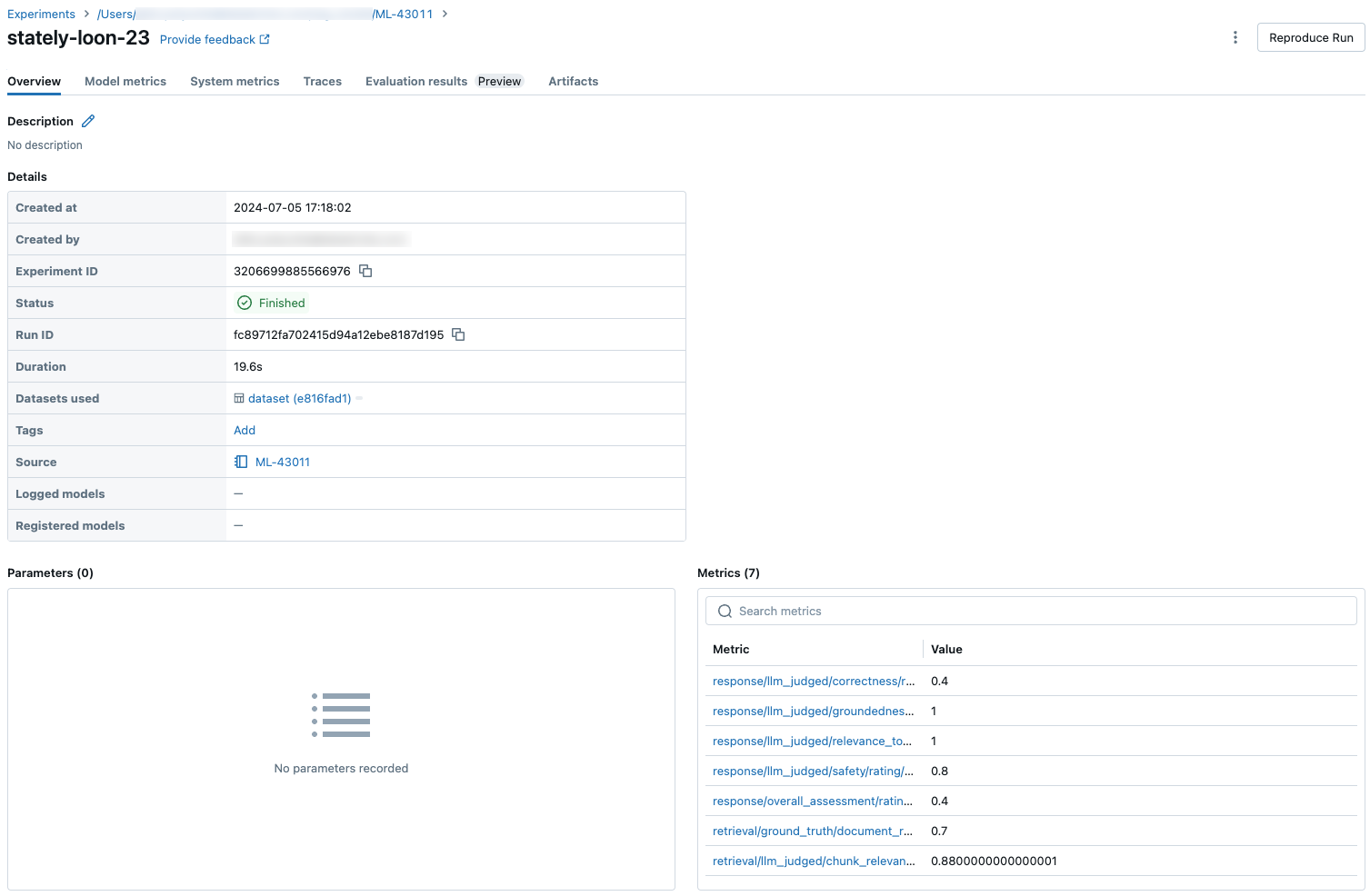
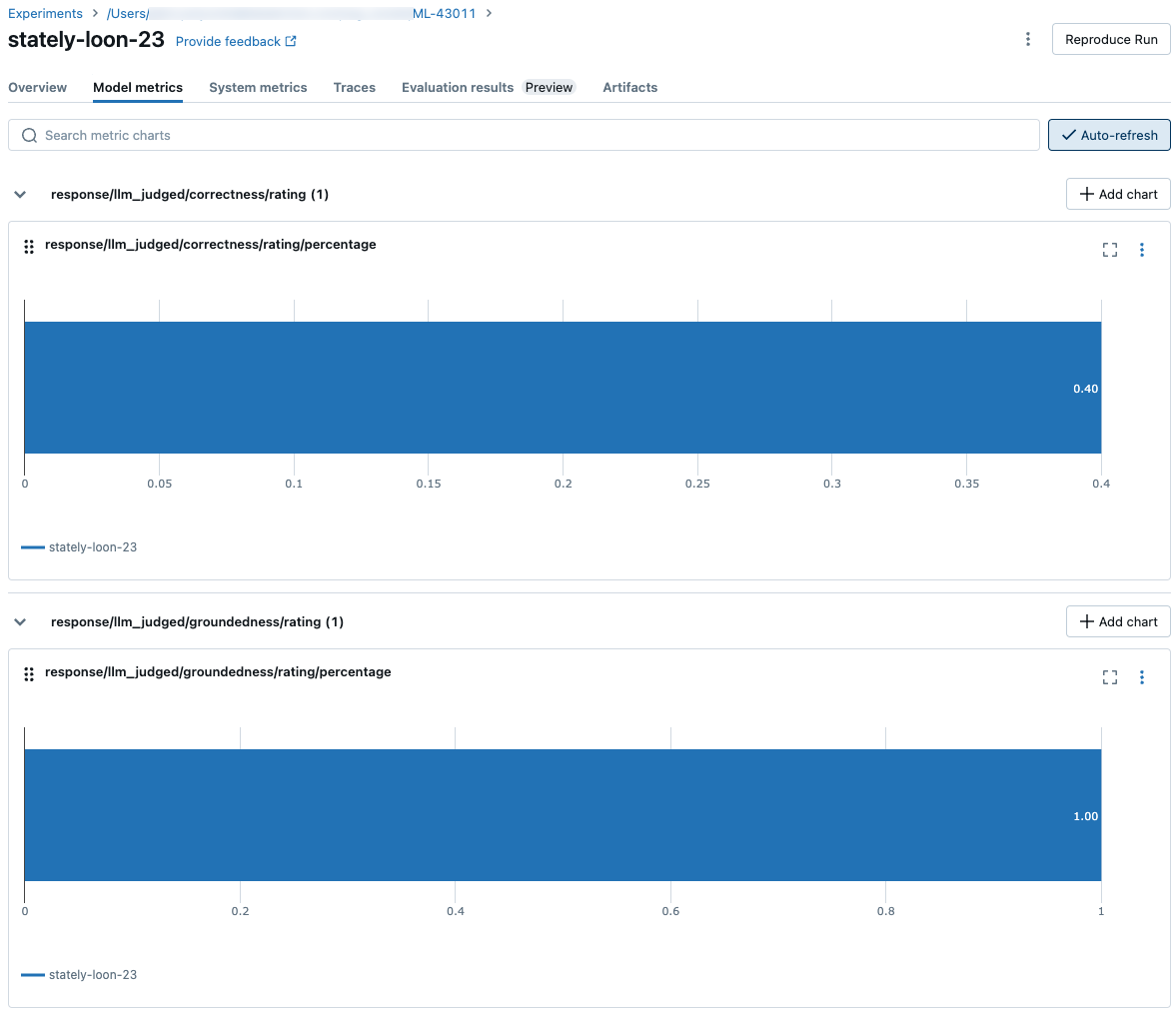
Aggregerade resultat i hela utvärderingsuppsättningen
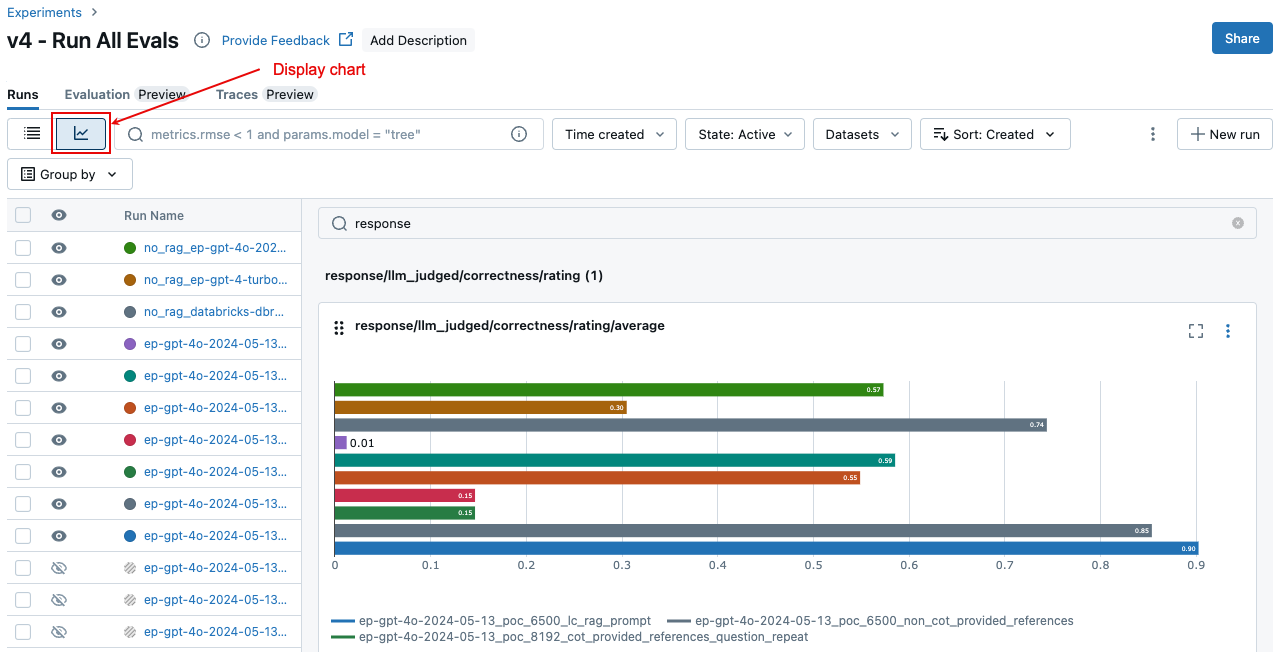
Om du vill se aggregerade resultat i hela utvärderingsuppsättningen klickar du på fliken Översikt (för numeriska värden) eller modellmått fliken (för diagram).
Jämföra utvärderingsresultat mellan körningar
Det är viktigt att jämföra utvärderingsresultat mellan körningar för att se hur ditt agentiska program svarar på ändringar. Om du jämför resultaten kan du förstå om dina ändringar påverkar kvaliteten eller hjälper dig att felsöka ändrade beteenden.
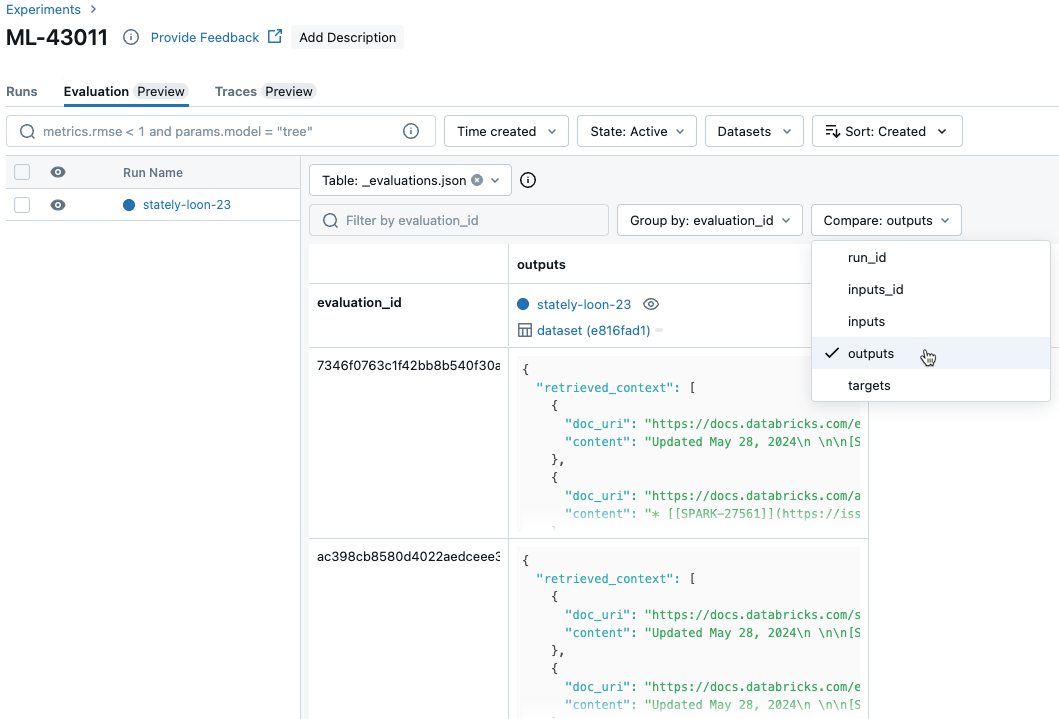
Jämföra resultat per begäran mellan körningar
Om du vill jämföra data för varje enskild begäran mellan körningar klickar du på fliken Utvärdering på sidan Experiment. En tabell visar varje fråga i utvärderingsuppsättningen. Använd de nedrullningsbara menyerna för att välja de kolumner som ska visas.
Jämföra aggregerade resultat mellan körningar
Du kan komma åt samma aggregerade resultat från sidan Experiment, vilket också gör att du kan jämföra resultat mellan olika körningar. Om du vill komma åt sidan Experiment klickar du på experimentikonen ![]() i anteckningsbokens högra sidofält eller klickar på länkarna som visas i cellresultatet för notebook-cellen där du körde
i anteckningsbokens högra sidofält eller klickar på länkarna som visas i cellresultatet för notebook-cellen där du körde mlflow.evaluate().
På sidan Experiment klickar du på ![]() . På så sätt kan du visualisera de aggregerade resultaten för den valda körningen och jämföra med tidigare körningar.
. På så sätt kan du visualisera de aggregerade resultaten för den valda körningen och jämföra med tidigare körningar.
Vilka domare som körs
För varje utvärderingspost tillämpar Mosaic AI Agent Evaluation som standard den delmängd av domare som bäst matchar den information som finns i posten. Specifikt:
- Om posten innehåller ett sant svar tillämpar Agent Evaluation
context_sufficiency,groundedness,correctness,safetyochguideline_adherencedomare. - Om posten inte innehåller ett verkligt svarsunderlag, tillämpar Agent Evaluation bedömningarna
chunk_relevance,groundedness,relevance_to_query,safetyochguideline_adherence.
Mer information finns i:
- Kör en delmängd av inbyggda domare
- Anpassade AI-domare
- Hur kvalitet, kostnad och svarstid utvärderas av Agentutvärdering
Information om förtroende och säkerhet avseende LLM-domare finns i Information om de modeller som används av LLM-domare.
Exempel: Skicka ett program till Agentutvärdering
Om du vill skicka ett program till mlflow_evaluate()använder du model argumentet . Det finns 5 alternativ för att skicka ett program i model argumentet.
- En modell registrerad i Unity Catalog.
- En MLflow-loggad modell i det aktuella MLflow-experimentet.
- En PyFunc-modell som läses in i notebook-filen.
- En lokal funktion i notebook-filen.
- En distribuerad agentslutpunkt.
Se följande avsnitt för kodexempel som illustrerar varje alternativ.
Alternativ 1. Modell registrerad i Unity Catalog
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model = "models:/catalog.schema.model_name/1" # 1 is the version number
model_type="databricks-agent",
)
Alternativ 2. MLflow-loggad modell i det aktuella MLflow-experimentet
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
# In the following lines, `6b69501828264f9s9a64eff825371711` is the run_id, and `chain` is the artifact_path that was
# passed with mlflow.xxx.log_model(...).
# If you called model_info = mlflow.langchain.log_model() or mlflow.pyfunc.log_model(), you can access this value using `model_info.model_uri`.
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model = "runs:/6b69501828264f9s9a64eff825371711/chain"
model_type="databricks-agent",
)
Alternativ 3. PyFunc-modell som läses in i notebook-filen
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model = mlflow.pyfunc.load_model(...)
model_type="databricks-agent",
)
Alternativ 4. Lokal funktion i notebook-filen
Funktionen tar emot en indata formaterad på följande sätt:
{
"messages": [
{
"role": "user",
"content": "What is MLflow?",
}
],
...
}
Funktionen måste returnera ett värde i något av följande tre format som stöds:
Oformaterad sträng som innehåller modellens svar.
En ordlista i
ChatCompletionResponseformat. Till exempel:{ "choices": [ { "message": { "role": "assistant", "content": "MLflow is a machine learning toolkit.", }, ... } ], ..., }En ordlista i
StringResponseformat, till exempel{ "content": "MLflow is a machine learning toolkit.", ... }.
I följande exempel används en lokal funktion för att omsluta en grundmodellslutpunkt och utvärdera den:
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
def model(model_input):
client = mlflow.deployments.get_deploy_client("databricks")
return client.predict(endpoint="endpoints:/databricks-meta-llama-3-1-405b-instruct", inputs={"messages": model_input["messages"]})
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model = model
model_type="databricks-agent",
)
Alternativ 5. Distribuerad agentslutpunkt
Det här alternativet fungerar bara när du använder agentslutpunkter som har distribuerats med och databricks.agents.deploy med databricks-agents SDK-versionen 0.8.0 eller senare. För grundmodeller eller äldre SDK-versioner använder du Alternativ 4 för att omsluta modellen i en lokal funktion.
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
# In the following lines, `endpoint-name-of-your-agent` is the name of the agent endpoint.
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model = "endpoints:/endpoint-name-of-your-agent"
model_type="databricks-agent",
)
Så här skickar du utvärderingsuppsättningen när programmet ingår i mlflow_evaluate()-anropet
I följande kod är data en pandas DataFrame för din utvärderingsuppsättning. Det här är enkla exempel. Mer information finns i indataschema.
# You do not have to start from a dictionary - you can use any existing pandas or Spark DataFrame with this schema.
# Minimal evaluation set
bare_minimum_eval_set_schema = [
{
"request": "What is the difference between reduceByKey and groupByKey in Spark?",
}]
# Complete evaluation set
complete_eval_set_schema = [
{
"request_id": "your-request-id",
"request": "What is the difference between reduceByKey and groupByKey in Spark?",
"expected_retrieved_context": [
{
# In `expected_retrieved_context`, `content` is optional, and does not provide any additional functionality.
"content": "Answer segment 1 related to What is the difference between reduceByKey and groupByKey in Spark?",
"doc_uri": "doc_uri_2_1",
},
{
"content": "Answer segment 2 related to What is the difference between reduceByKey and groupByKey in Spark?",
"doc_uri": "doc_uri_2_2",
},
],
"expected_response": "There's no significant difference.",
}]
# Convert dictionary to a pandas DataFrame
eval_set_df = pd.DataFrame(bare_minimum_eval_set_schema)
# Use a Spark DataFrame
import numpy as np
spark_df = spark.table("catalog.schema.table") # or any other way to get a Spark DataFrame
eval_set_df = spark_df.toPandas()
Exempel: Skicka tidigare genererade utdata till Agentutvärdering
I det här avsnittet beskrivs hur du skickar tidigare genererade utdata i anropet mlflow_evaluate() . Det obligatoriska utvärderingsuppsättningsschemat finns i agentutvärderingsindataschema.
I följande kod är data en pandas-DataFrame med din utvärderingsuppsättning och utdata som genereras av programmet. Det här är enkla exempel. Mer information finns i indataschema.
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
evaluation_results = mlflow.evaluate(
data=eval_set_with_app_outputs_df, # pandas DataFrame with the evaluation set and application outputs
model_type="databricks-agent",
)
# You do not have to start from a dictionary - you can use any existing pandas or Spark DataFrame with this schema.
# Minimum required input
bare_minimum_input_schema = [
{
"request": "What is the difference between reduceByKey and groupByKey in Spark?",
"response": "reduceByKey aggregates data before shuffling, whereas groupByKey shuffles all data, making reduceByKey more efficient.",
}]
# Input including optional arguments
complete_input_schema = [
{
"request_id": "your-request-id",
"request": "What is the difference between reduceByKey and groupByKey in Spark?",
"expected_retrieved_context": [
{
# In `expected_retrieved_context`, `content` is optional, and does not provide any additional functionality.
"content": "Answer segment 1 related to What is the difference between reduceByKey and groupByKey in Spark?",
"doc_uri": "doc_uri_2_1",
},
{
"content": "Answer segment 2 related to What is the difference between reduceByKey and groupByKey in Spark?",
"doc_uri": "doc_uri_2_2",
},
],
"expected_response": "There's no significant difference.",
"response": "reduceByKey aggregates data before shuffling, whereas groupByKey shuffles all data, making reduceByKey more efficient.",
"retrieved_context": [
{
# In `retrieved_context`, `content` is optional. If provided, the Databricks Context Relevance LLM Judge is executed to check the `content`'s relevance to the `request`.
"content": "reduceByKey reduces the amount of data shuffled by merging values before shuffling.",
"doc_uri": "doc_uri_2_1",
},
{
"content": "groupByKey may lead to inefficient data shuffling due to sending all values across the network.",
"doc_uri": "doc_uri_6_extra",
},
],
"guidelines": [
"The response must be in English",
]
}]
# Convert dictionary to a pandas DataFrame
eval_set_with_app_outputs_df = pd.DataFrame(bare_minimum_input_schema)
# Use a Spark DataFrame
import numpy as np
spark_df = spark.table("catalog.schema.table") # or any other way to get a Spark DataFrame
eval_set_with_app_outputs_df = spark_df.toPandas()
Exempel: Använd en anpassad funktion för att bearbeta svar från LangGraph
LangGraph-agenter, särskilt de med chattfunktioner, kan returnera flera meddelanden för ett enda slutsatsdragningsanrop. Det är användarens ansvar att konvertera agentens svar till ett format som agentutvärdering stöder.
En metod är att använda en anpassad funktion för att bearbeta svaret. I följande exempel visas en anpassad funktion som extraherar det senaste chattmeddelandet från en LangGraph-modell. Den här funktionen används sedan i mlflow.evaluate() för att returnera ett enda strängsvar, som kan jämföras med kolumnen ground_truth.
Exempelkoden gör följande antaganden:
- Modellen accepterar indata i formatet {"messages": [{"role": "user", "content": "hello"}]}.
- Modellen returnerar en lista med strängar i formatet ["svar 1", "svar 2"].
Följande kod skickar de sammanfogade svaren till domaren i det här formatet: "svar 1nresponse2"
import mlflow
import pandas as pd
from typing import List
loaded_model = mlflow.langchain.load_model(model_uri)
eval_data = pd.DataFrame(
{
"inputs": [
"What is MLflow?",
"What is Spark?",
],
"expected_response": [
"MLflow is an open-source platform for managing the end-to-end machine learning (ML) lifecycle. It was developed by Databricks, a company that specializes in big data and machine learning solutions. MLflow is designed to address the challenges that data scientists and machine learning engineers face when developing, training, and deploying machine learning models.",
"Apache Spark is an open-source, distributed computing system designed for big data processing and analytics. It was developed in response to limitations of the Hadoop MapReduce computing model, offering improvements in speed and ease of use. Spark provides libraries for various tasks such as data ingestion, processing, and analysis through its components like Spark SQL for structured data, Spark Streaming for real-time data processing, and MLlib for machine learning tasks",
],
}
)
def custom_langgraph_wrapper(model_input):
predictions = loaded_model.invoke({"messages": model_input["messages"]})
# Assuming `predictions` is a list of strings
return predictions.join("\n")
with mlflow.start_run() as run:
results = mlflow.evaluate(
custom_langgraph_wrapper, # Pass the function defined above
data=eval_data,
model_type="databricks-agent",
)
print(results.metrics)
Skapa en instrumentpanel med mått
När du itererar på kvaliteten på din agent kanske du vill dela en instrumentpanel med dina intressenter som visar hur kvaliteten har förbättrats över tid. Du kan extrahera måtten från dina MLflow-utvärderingskörningar, spara värdena i en Delta-tabell och skapa en instrumentpanel.
I följande exempel visas hur du extraherar och sparar måttvärdena från den senaste utvärderingskörningen i din anteckningsbok.
uc_catalog_name = "catalog"
uc_schema_name = "schema"
table_name = "results"
eval_results = mlflow.evaluate(
model=logged_agent_info.model_uri, # use the logged Agent
data=evaluation_set, # Run the logged Agent for all queries defined above
model_type="databricks-agent", # use Agent Evaluation
)
# The `append_metrics_to_table function` is defined below
append_metrics_to_table("<identifier-for-table>", eval_results.metrics, f"{uc_catalog_name}.{uc_schema_name}.{table_name}")
I följande exempel visas hur du extraherar och sparar måttvärden för tidigare körningar som du har sparat i MLflow-experimentet.
import pandas as pd
def get_mlflow_run(experiment_name, run_name):
runs = mlflow.search_runs(experiment_names=[experiment_name], filter_string=f"run_name = '{run_name}'", output_format="list")
if len(runs) != 1:
raise ValueError(f"Found {len(runs)} runs with name {run_name}. {run_name} must identify a single run. Alternatively, you can adjust this code to search for a run based on `run_id`")
return runs[0]
run = get_mlflow_run(experiment_name ="/Users/<user_name>/db_docs_mlflow_experiment", run_name="evaluation__2024-10-09_02:27:17_AM")
# The `append_metrics_to_table` function is defined below
append_metrics_to_table("<identifier-for-table>", run.data.metrics, f"{uc_catalog_name}.{uc_schema_name}.{table_name}")
Nu kan du skapa en instrumentpanel med hjälp av dessa data.
Följande kod definierar den funktion append_metrics_to_table som används i föregående exempel.
# Definition of `append_metrics_to_table`
def append_metrics_to_table(run_name, mlflow_metrics, delta_table_name):
data = mlflow_metrics.copy()
# Add identifying run_name and timestamp
data["run_name"] = run_name
data["timestamp"] = pd.Timestamp.now()
# Remove metrics with error counts
data = {k: v for k, v in mlflow_metrics.items() if "error_count" not in k}
# Convert to a Spark DataFrame(
metrics_df = pd.DataFrame([data])
metrics_df_spark = spark.createDataFrame(metrics_df)
# Append to the Delta table
metrics_df_spark.write.mode("append").saveAsTable(delta_table_name)
Information om de modeller som driver LLM-domare
- LLM-domare kan använda tjänster från tredje part för att utvärdera dina GenAI-program, inklusive Azure OpenAI som drivs av Microsoft.
- För Azure OpenAI har Databricks valt bort missbruksövervakning så att inga uppmaningar eller svar lagras med Azure OpenAI.
- För EU-arbetsytor använder LLM-domare modeller som finns i EU. Alla andra regioner använder modeller som finns i USA.
- Om du inaktiverar AZURE AI-baserade AI-hjälpfunktioner hindras LLM-domaren från att anropa Azure AI-baserade modeller.
- Data som skickas till LLM-domaren används inte för någon modellträning.
- LLM-domare är avsedda att hjälpa kunder att utvärdera sina RAG-program, och LLM-domarutdata bör inte användas för att träna, förbättra eller finjustera en LLM.