Agentobservabilitet med MLflow Tracing
Den här artikeln beskriver hur du lägger till observerbarhet i dina generativa AI-program med MLflow Tracing på Databricks.
Vad är MLflow-spårning?
MLflow Tracing- ger fullständig observerbarhet för generativa AI-program från utveckling till distribution. Spårning är helt integrerat med Databricks gen AI-verktygsuppsättning och samlar in detaljerade insikter under hela utvecklings- och produktionslivscykeln.
Följande är de viktigaste användningsfallen för spårning i gen AI-program:
Effektiviserad felsökning: Spårning ger insyn i varje steg i ditt gen-AI-program, vilket gör det enklare att diagnostisera och lösa problem.
offlineutvärdering: Spårning genererar värdefulla data för agentutvärdering, så att du kan mäta och förbättra kvaliteten på agenter över tid.
Produktionsövervakning: Spårning ger insyn i agentens beteende och detaljerade körningssteg, vilket möjliggör att du kan övervaka och optimera agentprestanda i produktion.
Granskningsloggar: MLflow Tracing genererar omfattande granskningsloggar för agentåtgärder och beslut. Detta är viktigt för att säkerställa efterlevnad och stödja felsökning när oväntade problem uppstår.
Krav
MLflow Tracing är tillgängligt i MLflow-versionerna 2.13.0 och senare. Databricks rekommenderar att du installerar den senaste versionen av MLflow för att få åtkomst till de senaste funktionerna och förbättringarna.
%pip install mlflow>=2.13.0 -qqqU
%restart_python
automatisk spårning
MLflow autologgning låter dig snabbt konfigurera din agent genom att lägga till en enda rad i koden mlflow.<library>.autolog().
MLflow stöder automatisk loggning för de mest populära biblioteken för agentredigering. Mer information om varje redigeringsbibliotek finns i dokumentation om automatisk MLflow-loggning:
| Bibliotek | Stöd för autologgning av versioner | Autologgningskommando |
|---|---|---|
| LangChain | 0.1.0 ~ Senaste | mlflow.langchain.autolog() |
| Langgraph | 0.1.1 ~ Senaste | mlflow.langgraph.autolog() |
| OpenAI | 1.0.0 ~ Senaste | mlflow.openai.autolog() |
| LlamaIndex | 0.10.44 ~ Senaste | mlflow.llamaindex.autolog() |
| DSPy | 2.5.17 ~ Senaste | mlflow.dspy.autolog() |
| Amazon Bedrock | 1.33.0 ~ Senaste (boto3) | mlflow.bedrock.autolog() |
| Människoorienterad | 0.30.0 ~ Senaste | mlflow.anthropic.autolog() |
| AutoGen | 0.2.36 ~ 0.2.40 | mlflow.autogen.autolog() |
| Google Gemini | 1.0.0 ~ Senaste | mlflow.gemini.autolog() |
| CrewAI | 0.80.0 ~ Senaste | mlflow.crewai.autolog() |
| LiteLLM | 1.52.9 ~ Senaste | mlflow.litellm.autolog() |
| Groq | 0.13.0 ~ Senaste | mlflow.groq.autolog() |
| Mistralen | 1.0.0 ~ Senaste | mlflow.mistral.autolog() |
Inaktivera automatisk loggning
Automatisk loggningsspårning är aktiverad som standard i Databricks Runtime 15.4 ML och senare för följande bibliotek:
- LangChain
- Langgraph
- OpenAI
- LlamaIndex
Om du vill inaktivera autologgningens spårning för dessa bibliotek kör du följande kommando i en notebook:
`mlflow.<library>.autolog(log_traces=False)`
Lägg till spårningar manuellt
Automatisk loggning är ett bekvämt sätt att instrumentera agenter, men du kanske vill instrumentera agenten mer detaljerat eller lägga till ytterligare spårningar som autologgning inte samlar in. I dessa fall använder du API:er för MLflow-spårning för att lägga till spårningar manuellt.
API:er för MLflow-spårning är API:er med låg kod för att lägga till spårningar utan att behöva bekymra dig om att hantera spårningens trädstruktur. MLflow bestämmer lämpliga överordnade och underordnade span-relationer automatiskt med hjälp av Python-stacken.
Kombinera automatisk loggning och manuell spårning
Api:er för manuell spårning kan användas med automatisk loggning. MLflow kombinerar de intervall som skapas genom automatisk loggning och manuell spårning för att skapa en fullständig spårning av agentkörningen. Ett exempel på hur du kombinerar automatisk loggning och manuell spårning finns i Instrumentering av ett verktyg som kallar agent med MLflow-spårning.
Spåra funktioner med hjälp av @mlflow.trace-dekorator
Det enklaste sättet att manuellt instrumentera koden är att dekorera en funktion med dekoratören @mlflow.trace.
MLflow-spårningsdekoratören skapar ett "span" som täcker området för den dekorerade funktionen, vilket representerar en körningsenhet i en spårning och visas som en enda rad i spårningsvisualiseringen. Spannet samlar in in- och utdata för funktionen, svarstiden och eventuella undantag som genereras från funktionen.
Följande kod skapar till exempel ett spann med namnet my_function som samlar in indataargument x och y och utdata.
import mlflow
@mlflow.trace
def add(x: int, y: int) -> int:
return x + y
Du kan också anpassa spannsnamn, spantyp och lägga till anpassade attribut i intervallet:
from mlflow.entities import SpanType
@mlflow.trace(
# By default, the function name is used as the span name. You can override it with the `name` parameter.
name="my_add_function",
# Specify the span type using the `span_type` parameter.
span_type=SpanType.TOOL,
# Add custom attributes to the span using the `attributes` parameter. By default, MLflow only captures input and output.
attributes={"key": "value"}
)
def add(x: int, y: int) -> int:
return x + y
Spåra godtyckliga kodblock med hjälp av en kontexthanterare
Om du vill skapa ett intervall för ett godtyckligt kodblock, inte bara en funktion, använder du mlflow.start_span() som en kontexthanterare som omsluter kodblocket. Intervallet börjar när kontexten anges och slutar när kontexten avslutas. Span-indata och utdata ska anges manuellt med hjälp av settermetoder för span-objektet som genereras av kontexthanteraren. Mer information finns i MLflow-dokumentation – kontexthanterare.
with mlflow.start_span(name="my_span") as span:
span.set_inputs({"x": x, "y": y})
result = x + y
span.set_outputs(result)
span.set_attribute("key", "value")
Spårningsbibliotek på lägre nivå
MLflow tillhandahåller också API:er på låg nivå för att uttryckligen styra spårningsträdstrukturen. Se MLflow-dokumentation och Manuell instrumentering.
spårningsexempel: Kombinera automatisk loggning och manuella spårningar
I följande exempel kombineras OpenAI:s autologgning och manuell spårning för att helt instrumentera en agent som anropar verktyg.
import json
from openai import OpenAI
import mlflow
from mlflow.entities import SpanType
client = OpenAI()
# Enable OpenAI autologging to capture LLM API calls
# (*Not necessary if you are using the Databricks Runtime 15.4 ML and above, where OpenAI autologging is enabled by default)
mlflow.openai.autolog()
# Define the tool function. Decorate it with `@mlflow.trace` to create a span for its execution.
@mlflow.trace(span_type=SpanType.TOOL)
def get_weather(city: str) -> str:
if city == "Tokyo":
return "sunny"
elif city == "Paris":
return "rainy"
return "unknown"
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"parameters": {
"type": "object",
"properties": {"city": {"type": "string"}},
},
},
}
]
_tool_functions = {"get_weather": get_weather}
# Define a simple tool-calling agent
@mlflow.trace(span_type=SpanType.AGENT)
def run_tool_agent(question: str):
messages = [{"role": "user", "content": question}]
# Invoke the model with the given question and available tools
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=messages,
tools=tools,
)
ai_msg = response.choices[0].message
messages.append(ai_msg)
# If the model requests tool calls, invoke the function(s) with the specified arguments
if tool_calls := ai_msg.tool_calls:
for tool_call in tool_calls:
function_name = tool_call.function.name
if tool_func := _tool_functions.get(function_name):
args = json.loads(tool_call.function.arguments)
tool_result = tool_func(**args)
else:
raise RuntimeError("An invalid tool is returned from the assistant!")
messages.append(
{
"role": "tool",
"tool_call_id": tool_call.id,
"content": tool_result,
}
)
# Send the tool results to the model and get a new response
response = client.chat.completions.create(
model="gpt-4o-mini", messages=messages
)
return response.choices[0].message.content
# Run the tool calling agent
question = "What's the weather like in Paris today?"
answer = run_tool_agent(question)
Kommentera spårningar med taggar
MLflow-spårningstaggar är nyckel/värde-par som gör att du kan lägga till anpassade metadata i spårningar, till exempel ett konversations-ID, ett användar-ID, Git-incheckningshash osv. Taggar visas i användargränssnittet för MLflow för att filtrera och söka efter spårningar.
Taggar kan anges till en pågående eller slutförd spårning med hjälp av MLflow-API:er eller MLflow-användargränssnittet. I följande exempel visas hur du lägger till en tagg i en pågående spårning med hjälp av api:et mlflow.update_current_trace().
@mlflow.trace
def my_func(x):
mlflow.update_current_trace(tags={"fruit": "apple"})
return x + 1
Mer information om taggning av spårningar och hur du använder dem för att filtrera och söka efter spårningar finns i MLflow-dokumentation – Ange spårningstaggar.
Granska spårningar
Om du vill granska loggar när agenten har körts använder du något av följande alternativ.
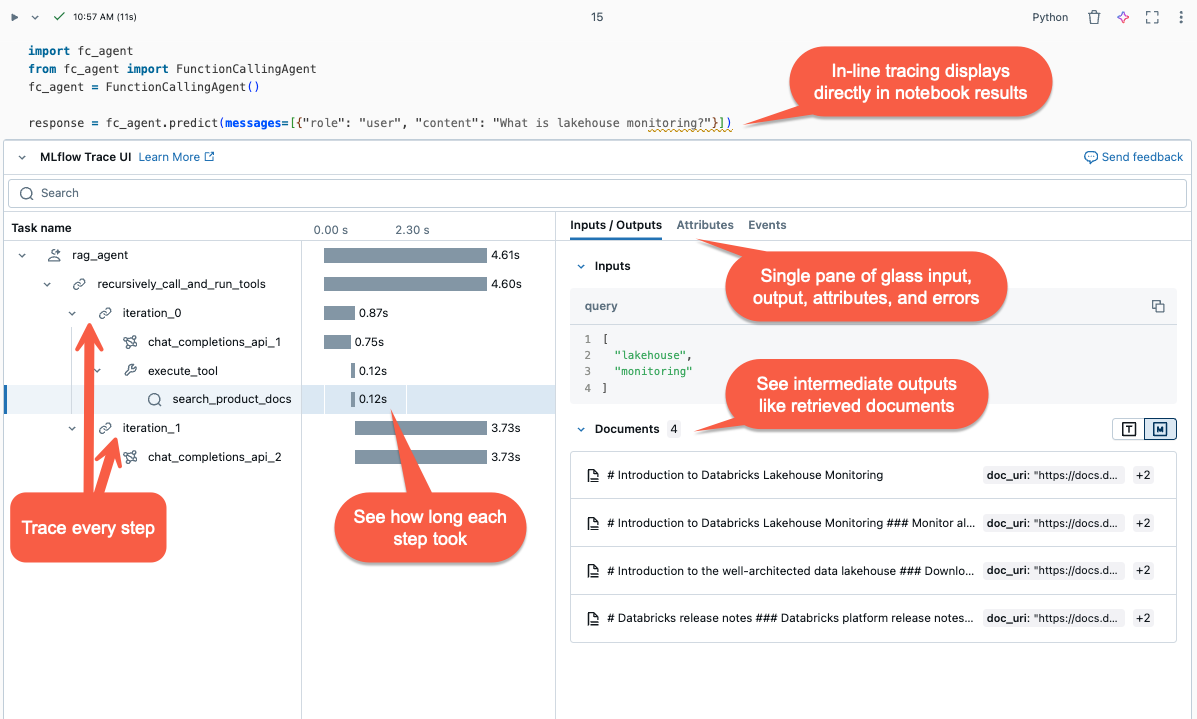
- Inline-visualiseringar: I Databricks-notebook-filer visas spår inline i cellens utdata.
- MLflow-experiment: I Databricks går du till Experiment> Välj ett experiment >Traces för att visa och söka igenom alla spårningar efter ett experiment.
- MLflow-körning: När agenten körs under en aktiv MLflow-körning visas spår på Run-sidan i MLflow-användargränssnittet.
- Agent Evaluation UI: I Mosaic AI Agent Evaluation kan du granska spårningar för varje agentkörning genom att klicka på Se detaljerad spårningsvy i utvärderingsresultatet.
- API för spårningssökning: Om du vill hämta spårningar programmatiskt använder du API:et för spårningssökning.
Utvärdera agenter med hjälp av spårningar
Spårningsdata fungerar som en värdefull resurs för att utvärdera dina agenter. Genom att samla in detaljerad information om körningen av dina modeller är MLflow Tracing avgörande för offlineutvärdering. Du kan använda spårningsdata för att utvärdera agentens prestanda mot en gyllene datauppsättning, identifiera problem och förbättra agentens prestanda.
%pip install -U mlflow databricks-agents
%restart_python
import mlflow
# Get the recent 50 successful traces from the experiment
traces = mlflow.search_traces(
max_results=50,
filter_string="status = 'OK'",
)
traces.drop_duplicates("request", inplace=True) # Drop duplicate requests.
traces["trace"] = traces["trace"].apply(lambda x: x.to_json()) # Convert the trace to JSON format.
# Evaluate the agent with the trace data
mlflow.evaluate(data=traces, model_type="databricks-agent")
Mer information om agentutvärdering finns i Kör en utvärdering och visa resultatet.
Övervaka distribuerade agenter med slutsatsdragningstabeller
När en agent har distribuerats till Mosaic AI Model Serving kan du använda slutsatsdragningstabeller för att övervaka agenten. Slutsatsdragningstabellerna innehåller detaljerade loggar med begäranden, svar, agentspårningar och agentfeedback från granskningsappen. Med den här informationen kan du felsöka problem, övervaka prestanda och skapa en gyllene datauppsättning för offlineutvärdering.
Information om hur du aktiverar slutsatsdragningstabeller för agentdistributioner finns i Aktivera slutsatsdragningstabeller för AI-agenter.
Sök efter onlinespår
Använd en notebook-fil för att köra frågor mot slutsatsdragningstabellen och analysera resultaten.
Om du vill visualisera spårningar kör du display(<the request logs table>) och väljer rader att inspektera:
# Query the inference table
df = spark.sql("SELECT * FROM <catalog.schema.my-inference-table-name>")
display(df)
Övervaka agenter
Se Så här övervakar du din gen AI-app.
Fördröjning av omkostnader
Spårningar skrivs asynkront för att minimera prestandapåverkan. Spårning lägger dock fortfarande till svarstid till svarshastigheten för slutpunkten, särskilt när spårningsstorleken för varje slutsatsdragningsbegäran är stor. Databricks rekommenderar att du testar slutpunkten för att förstå påverkan på spårningsfördröjning innan du distribuerar till produktion.
Följande tabell innehåller ungefärliga uppskattningar för svarstidspåverkan efter spårningsstorlek:
| Spårningsstorlek per begäran | Påverkan på svarshastighetens svarstid (ms) |
|---|---|
| ~10 kB | ~ 1 ms |
| ~ 1 MB | 50 ~ 100 ms |
| 10 MB | 150 ms ~ |
Felsökning
För felsökning och vanliga frågor, se dokumentationen MLflow: Tracing How-to Guide och dokumentationen MLflow: FAQ