Så här övervakar du kvaliteten på din agent i produktionstrafiken
Viktigt!
Den här funktionen finns som allmänt tillgänglig förhandsversion.
Den här artikeln beskriver hur du övervakar kvaliteten på distribuerade agenter på produktionstrafik med hjälp av Mosaic AI Agent Evaluation.
Onlineövervakning är en viktig aspekt av att se till att din agent fungerar som avsett med verkliga begäranden. Med hjälp av notebook-filen nedan kan du köra Agentutvärdering kontinuerligt på de begäranden som hanteras via en agentbetjäningsslutpunkt. Notebook-filen genererar en instrumentpanel som visar kvalitetsmått samt användarfeedback (tummen upp 👍 eller tummen ner 👎) för agentens utdata på produktionsbegäranden. Den här feedbacken kan komma via granskningsappen från intressenter eller feedback-API:et på produktionsslutpunkter som gör att du kan samla in slutanvändarreaktioner. På instrumentpanelen kan du dela upp måtten efter olika dimensioner, till exempel efter tid, användarfeedback, status för pass/fail och ämnet för indatabegäran (till exempel för att förstå om specifika ämnen är korrelerade med utdata av lägre kvalitet). Dessutom kan du fördjupa dig i enskilda begäranden med svar av låg kvalitet för att ytterligare felsöka dem. Alla artefakter, till exempel instrumentpanelen, är helt anpassningsbara.
Krav
- Azure AI-baserade AI-hjälpmedelsfunktioner måste vara aktiverade för din arbetsyta.
- inferenstabeller måste aktiveras på slutpunkten som betjänar agenten.
Bearbeta produktionstrafik kontinuerligt via agentutvärdering
Följande notebook-exempel visar hur du kör Agentutvärdering på begärandeloggarna från en agent som betjänar slutpunkten. Så här kör du notebook-filen:
- Importera anteckningsboken på din arbetsyta (instruktioner). Du kan klicka på knappen "Kopiera länk för import" nedan för att hämta en URL för importen.
- Fyll i de obligatoriska parametrarna överst i den importerade notebook-filen.
- Namnet på den distribuerade agentens serverslutpunkt.
- En exempelfrekvens mellan 0,0 och 1,0 för exempelbegäranden. Använd en lägre frekvens för slutpunkter med stora mängder trafik.
- (Valfritt) En arbetsytemapp som ska lagra genererade artefakter (till exempel instrumentpaneler). Standardinställningen är hemmappen.
- (Valfritt) En lista med ämnen för att kategorisera indatabegäranden. Standardvärdet är en lista som består av ett enda catch-all-ämne.
- Klicka på Kör alla i den importerade notebook-filen. Detta gör en inledande bearbetning av dina produktionsloggar inom ett 30-dagarsfönster och initierar instrumentpanelen som sammanfattar kvalitetsmåtten.
- Klicka på Schemalägg för att skapa ett jobb för att köra notebook-filen med jämna mellanrum. Jobbet bearbetar dina produktionsloggar stegvis och håller instrumentpanelen uppdaterad.
Notebook-filen kräver antingen serverlös beräkning eller ett kluster som kör Databricks Runtime 15.2 eller senare. När du kontinuerligt övervakar produktionstrafik på slutpunkter med ett stort antal begäranden rekommenderar vi att du anger ett mer frekvent schema. Till exempel skulle ett schema per timme fungera bra för en slutpunkt med mer än 10 000 begäranden per timme och en exempelfrekvens på 10 %.
Kör agentutvärdering på notebook-filen för produktionstrafik
Framtvinga riktlinjer för agentens svar
Riktlinjens efterlevnadsdomare ser till att modellens utdata följer de angivna riktlinjerna. Du kan skriva dessa globala riktlinjer enligt beskrivningen i notebook-filen ovan eller enligt följande:
mlflow.evaluate(
...,
evaluator_config={
"databricks-agent": {
"global_guidelines": [
"The response must be in English",
"The response must be clear, coherent, and concise",
],
}
}
)
Resultaten från denna domare fylls i tabellen för utvärderade begärandeloggar som genereras av exempelanteckningsboken (eval_requests_log_table_name i anteckningsboken). Kontrollpanelen kan anpassas för att visa domarens resultat över tid.
Skapa aviseringar om utvärderingsmått
När du har schemalagt notebook-filen så att den körs regelbundet kan du lägga till aviseringar som ska meddelas när kvalitetsmåtten sjunker lägre än förväntat. Dessa aviseringar skapas och används på samma sätt som andra Databricks SQL-aviseringar. Skapa först en Databricks SQL-fråga i loggtabellen för utvärderingsbegäranden som genereras av exempelanteckningsboken. Följande kod visar en exempelfråga över tabellen med utvärderingsbegäranden som filtrerar begäranden från den senaste timmen:
SELECT
`date`,
AVG(pass_indicator) as avg_pass_rate
FROM (
SELECT
*,
CASE
WHEN `response/overall_assessment/rating` = 'yes' THEN 1
WHEN `response/overall_assessment/rating` = 'no' THEN 0
ELSE NULL
END AS pass_indicator
-- The eval requests log table is generated by the example notebook
FROM {eval_requests_log_table_name}
WHERE `date` >= CURRENT_TIMESTAMP() - INTERVAL 1 DAY
)
GROUP BY ALL
Skapa sedan en Databricks SQL-avisering för att utvärdera frågan med önskad frekvens och skicka ett meddelande om aviseringen utlöses. Följande bild visar en exempelkonfiguration för att skicka en avisering när den totala passeringsfrekvensen understiger 80 %.
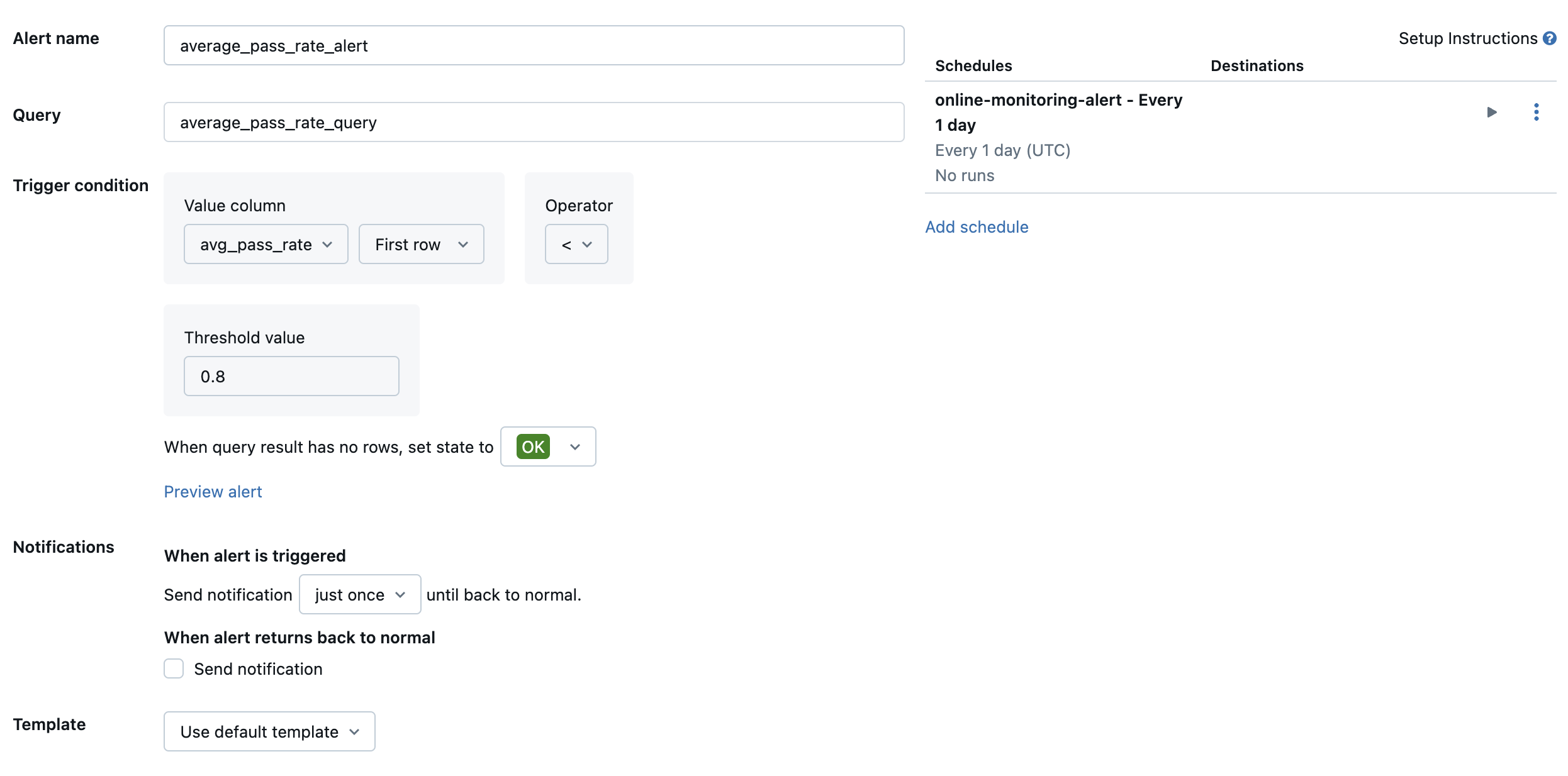
Som standard skickas ett e-postmeddelande. Du kan också konfigurera en webhook eller skicka meddelanden till andra program som Slack eller PagerDuty.
Lägga till valda produktionsloggar i granskningsappen för mänsklig granskning
När användarna ger feedback om dina begäranden kanske du vill be ämnesexperter att granska begäranden med negativ feedback (begäranden med tummen ner på svaret eller hämtningarna). För att göra det lägger du till specifika loggar i granskningsappen för att begära expertgranskning.
Följande kod visar en exempelfråga i tabellen för utvärderingsloggen för att hämta den senaste mänskliga utvärderingen per begärande-ID och käll-ID:
with ranked_logs as (
select
`timestamp`,
request_id,
source.id as source_id,
text_assessment.ratings["answer_correct"]["value"] as text_rating,
retrieval_assessment.ratings["answer_correct"]["value"] as retrieval_rating,
retrieval_assessment.position as retrieval_position,
row_number() over (
partition by request_id, source.id, retrieval_assessment.position order by `timestamp` desc
) as rank
from {assessment_log_table_name}
)
select
request_id,
source_id,
text_rating,
retrieval_rating
from ranked_logs
where rank = 1
order by `timestamp` desc
I följande kod ersätter du ... på raden human_ratings_query = "..." med en fråga som liknar den ovan. Följande kod extraherar sedan begäranden med negativ feedback och lägger till dem i granskningsappen:
from databricks import agents
human_ratings_query = "..."
human_ratings_df = spark.sql(human_ratings_query).toPandas()
# Filter out the positive ratings, leaving only negative and "IDK" ratings
negative_ratings_df = human_ratings_df[
(human_ratings_df["text_rating"] != "positive") | (human_ratings_df["retrieval_rating"] != "positive")
]
negative_ratings_request_ids = negative_ratings_df["request_id"].drop_duplicates().to_list()
agents.enable_trace_reviews(
model_name=YOUR_MODEL_NAME,
request_ids=negative_ratings_request_ids,
)
Mer information om granskningsappen finns i Få feedback om hur bra en applikation för agenter är.