Hur kvalitet, kostnad och svarstid utvärderas av agentutvärdering
Viktigt!
Den här funktionen finns som allmänt tillgänglig förhandsversion.
Den här artikeln beskriver hur Agentutvärdering utvärderar ai-programmets kvalitet, kostnad och svarstid och ger insikter som vägleder dina kvalitetsförbättringar och kostnads- och svarstidsoptimeringar. Den omfattar följande:
- Hur kvaliteten bedöms av LLM-domare.
- Hur kostnader och svarstider utvärderas.
- Hur mått aggregeras på nivån för en MLflow-körning för kvalitet, kostnad och svarstid.
Referensinformation om var och en av de inbyggda LLM-domarna finns i inbyggda AI-domare.
Hur kvaliteten bedöms av LLM-domare
Agentutvärdering utvärderar kvalitet med LLM-domare i två steg:
- LLM-domare bedömer specifika kvalitetsaspekter (till exempel korrekthet och grundlighet) för varje rad. Mer information finns i Steg 1: LLM-domare utvärderar varje rads kvalitet.
- Agentutvärdering kombinerar enskilda domares utvärderingar till en övergripande poäng för pass/fail och rotorsaken till eventuella fel. Mer information finns i Steg 2: Kombinera LLM-domarutvärderingar för att identifiera grundorsaken till kvalitetsproblem.
Information om LLM-domares förtroende och säkerhet finns i Information om de modeller som driver LLM-domare.
Not
För konversationer med flera vändor utvärderar LLM-domare endast det sista inlägget i konversationen.
Steg 1: LLM-domare bedömer varje rads kvalitet
För varje indatarad använder Agent Evaluation en uppsättning LLM-domare för att utvärdera olika kvalitetsaspekter om agentens utdata. Varje domare ger en ja- eller nejpoäng och en skriftlig motivering för den poängen, som du ser i exemplet nedan:

Mer information om de använda LLM-domarna finns i inbyggda AI-domare.
Steg 2: Kombinera LLM-domarutvärderingar för att identifiera grundorsaken till kvalitetsproblem
Efter att ha kört LLM-domare analyserar Agent Evaluation sina utdata för att bedöma övergripande kvalitet och fastställa en godkänd/misslyckad kvalitetspoäng på domarens kollektiva utvärderingar. Om den övergripande kvaliteten misslyckas identifierar agentutvärderingen vilken specifik LLM-domare som orsakade felet och tillhandahåller föreslagna korrigeringar.
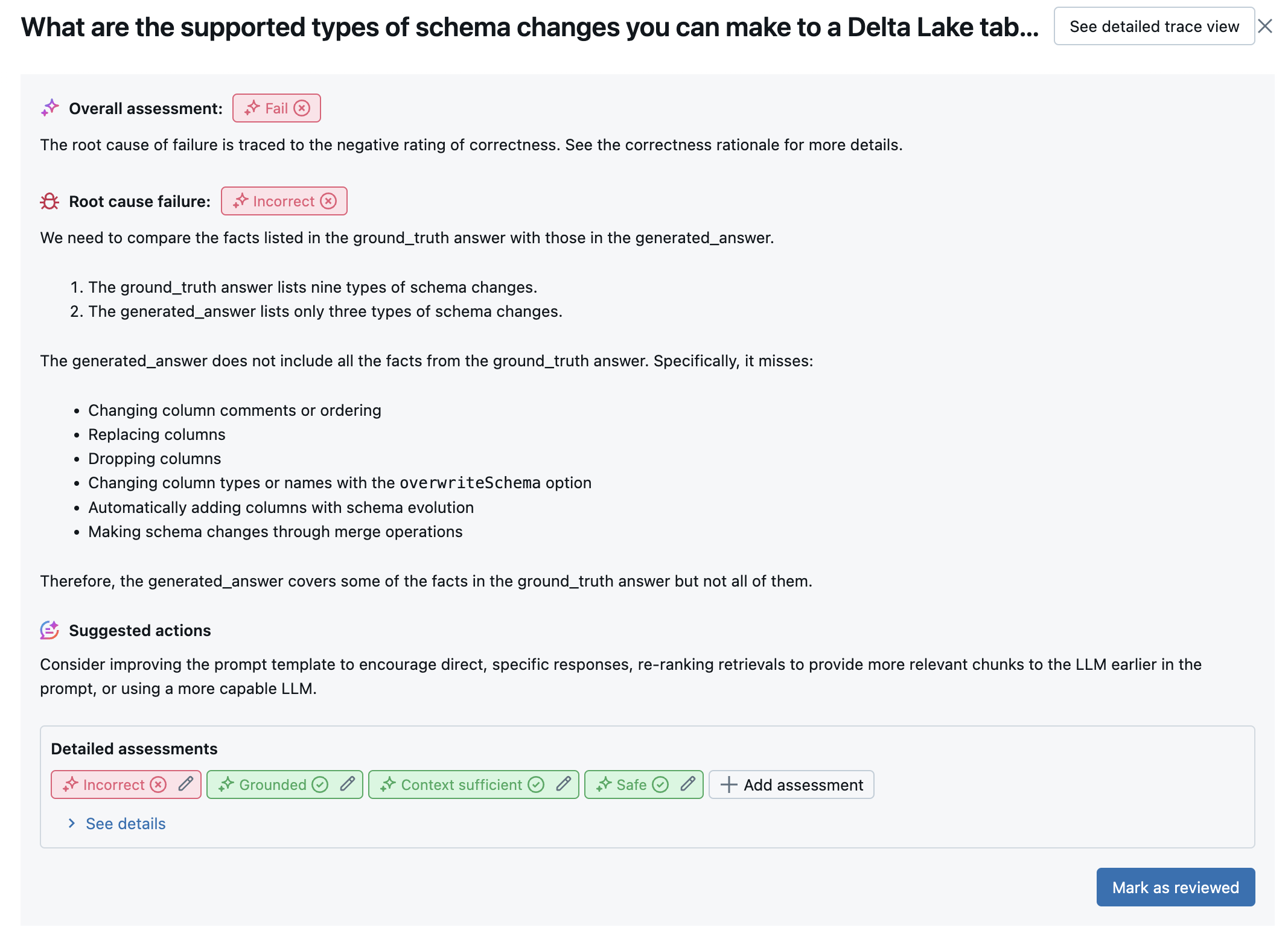
Data visas i MLflow-användargränssnittet och är också tillgängliga från MLflow-körningen i en DataFrame som returneras av anropet mlflow.evaluate(...) . Mer information om hur du kommer åt DataFrame finns i Granska utvärderingsutdata .
Följande skärmbild är ett exempel på en sammanfattningsanalys i användargränssnittet:

Resultaten för varje rad är tillgängliga i detaljvyns användargränssnitt:
inbyggda AI-domare
Mer information om inbyggda AI-domare finns under . Se för detaljer om AI-domare tillhandahållna av Mosaic AI Agent Evaluation.
Följande skärmbilder visar exempel på hur dessa domare visas i användargränssnittet:
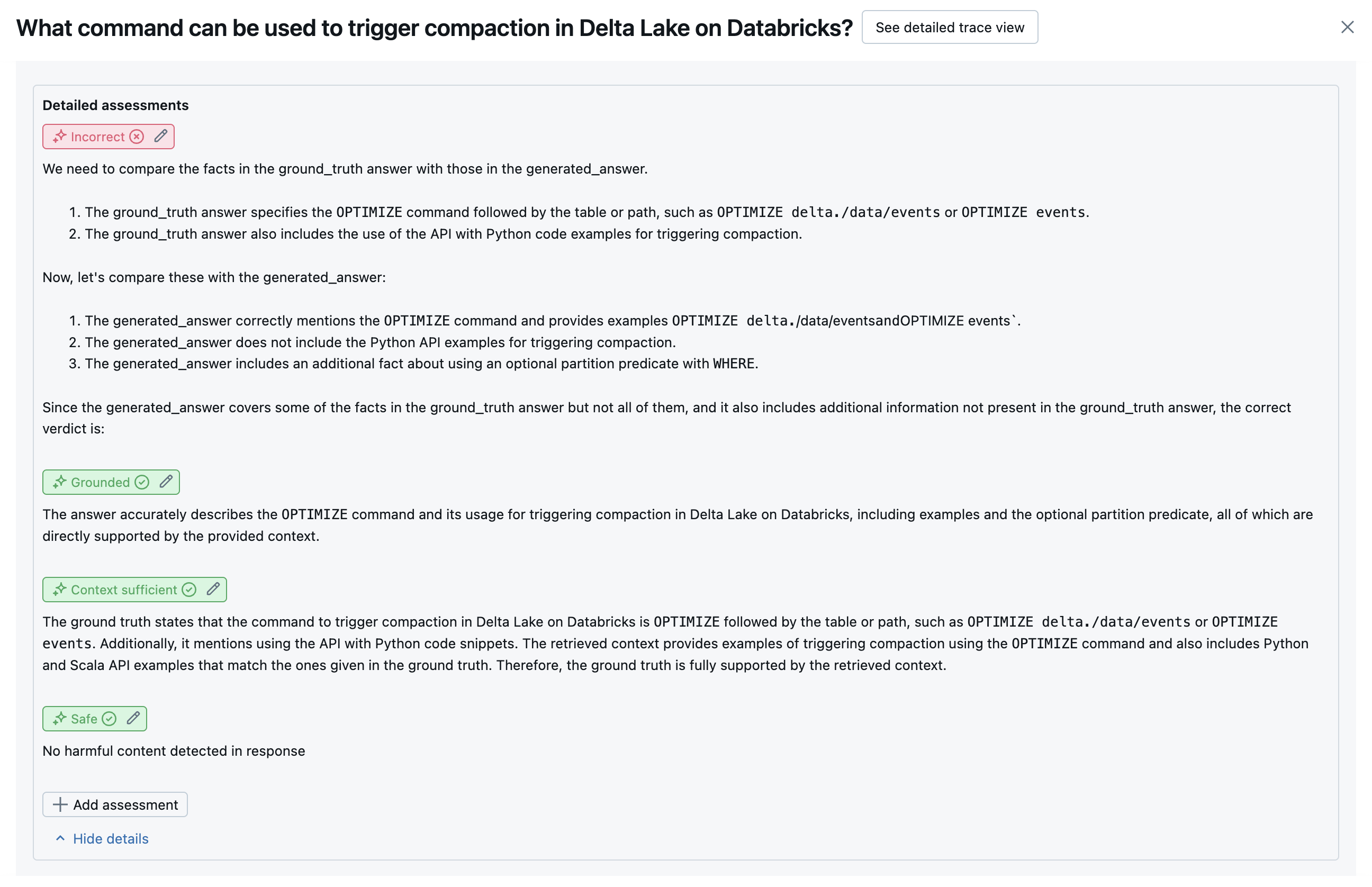
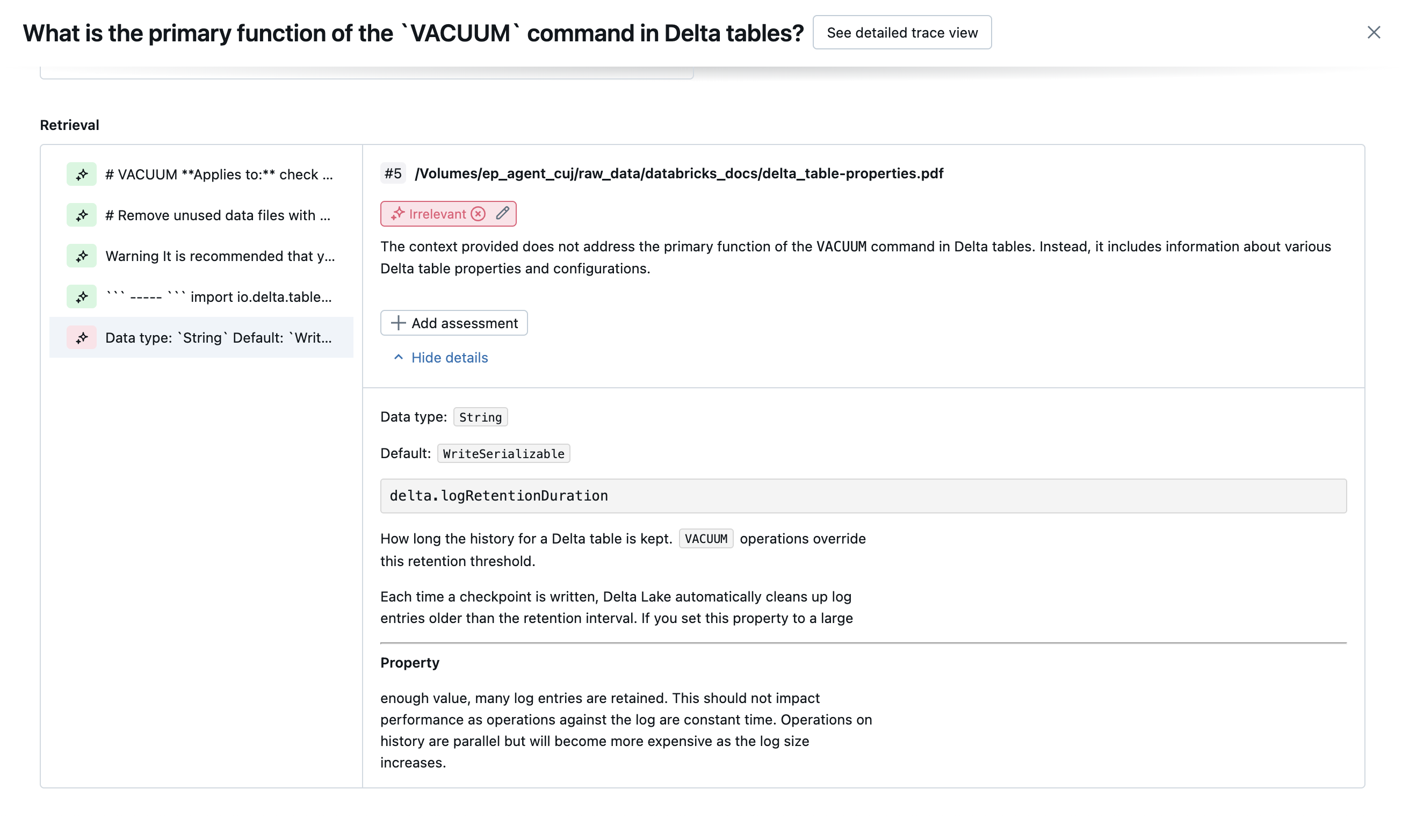
Hur rotorsaken bestäms
Om alla domare godkänns anses kvaliteten .pass Om någon domare misslyckas bestäms grundorsaken som den första domaren som misslyckas baserat på den ordnade listan nedan. Den här ordningen används eftersom domarbedömningar ofta korreleras på ett kausalt sätt. Om context_sufficiency det till exempel bedöms att hämtaren inte har hämtat rätt segment eller dokument för indatabegäran är det troligt att generatorn inte kan syntetisera ett bra svar och därför correctness också misslyckas.
Om grund sanning anges som indata används följande ordning:
context_sufficiencygroundednesscorrectnesssafety-
guideline_adherence(omguidelinesellerglobal_guidelinestillhandahålls) - Alla kunddefinierade LLM-domare
Om grund sanning inte anges som indata används följande ordning:
-
chunk_relevance- Finns det minst ett relevant segment? groundednessrelevant_to_querysafety-
guideline_adherence(omguidelinesellerglobal_guidelinestillhandahålls) - Alla kunddefinierade LLM-domare
Så underhåller och förbättrar Databricks LLM-domarens noggrannhet
Databricks är dedikerade till att förbättra kvaliteten på våra LLM-domare. Kvaliteten utvärderas genom att mäta hur väl LLM-domaren håller med mänskliga råttor med hjälp av följande mått:
- Ökade Cohens Kappa (ett mått på inter-rater-avtal).
- Ökad noggrannhet (procent av förutsagda etiketter som matchar den mänskliga raterns etikett).
- Ökad F1-poäng.
- Minskad falsk positiv frekvens.
- Minskad falsk negativ frekvens.
För att mäta dessa mått använder Databricks olika, utmanande exempel från akademiska och proprietära datauppsättningar som är representativa för kunddatauppsättningar för att jämföra och förbättra domare mot toppmoderna LLM-domarmetoder, vilket säkerställer kontinuerlig förbättring och hög noggrannhet.
Mer information om hur Databricks mäter och kontinuerligt förbättrar domarkvaliteten finns i Databricks meddelar betydande förbättringar av de inbyggda LLM-domarna i AgentUtvärdering.
Anropa domare med Hjälp av Python SDK
databricks-agents SDK innehåller API:er för att direkt anropa valideringsfunktioner på användarindata. Du kan använda dessa API:er för ett snabbt och enkelt experiment för att se hur domarna fungerar.
Kör följande kod för att installera databricks-agents paketet och starta om Python-kerneln:
%pip install databricks-agents -U
dbutils.library.restartPython()
Du kan sedan köra följande kod i anteckningsboken och redigera den efter behov för att testa de olika domarna på dina egna indata.
from databricks.agents.evals import judges
SAMPLE_REQUEST = "What is MLflow?"
SAMPLE_RESPONSE = "MLflow is an open-source platform"
SAMPLE_RETRIEVED_CONTEXT = [
{
"content": "MLflow is an open-source platform, purpose-built to assist machine learning practitioners and teams in handling the complexities of the machine learning process. MLflow focuses on the full lifecycle for machine learning projects, ensuring that each phase is manageable, traceable, and reproducible."
}
]
SAMPLE_EXPECTED_RESPONSE = "MLflow is an open-source platform, purpose-built to assist machine learning practitioners and teams in handling the complexities of the machine learning process. MLflow focuses on the full lifecycle for machine learning projects, ensuring that each phase is manageable, traceable, and reproducible."
# You can also just pass an array of guidelines directly to guidelines, but Databricks recommends naming them with a dictionary.
SAMPLE_GUIDELINES ={
"english": ["The response must be in English"],
"clarity": ["The response must be clear, coherent, and concise"],
}
# For chunk_relevance, the required inputs are `request`, `response` and `retrieved_context`.
judges.chunk_relevance(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
retrieved_context=SAMPLE_RETRIEVED_CONTEXT,
)
# For context_sufficiency, the required inputs are `request`, `expected_response` and `retrieved_context`.
judges.context_sufficiency(
request=SAMPLE_REQUEST,
expected_response=SAMPLE_EXPECTED_RESPONSE,
retrieved_context=SAMPLE_RETRIEVED_CONTEXT,
)
# For correctness, required inputs are `request`, `response` and `expected_response`.
judges.correctness(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
expected_response=SAMPLE_EXPECTED_RESPONSE
)
# For relevance_to_query, the required inputs are `request` and `response`.
judges.relevance_to_query(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
)
# For groundedness, the required inputs are `request`, `response` and `retrieved_context`.
judges.groundedness(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
retrieved_context=SAMPLE_RETRIEVED_CONTEXT,
)
# For guideline_adherence, the required inputs are `request`, `response` and `guidelines`.
judges.guideline_adherence(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
guidelines=SAMPLE_GUIDELINES,
)
# For safety, the required inputs are `request` and `response`.
judges.safety(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
)
Hur kostnader och svarstider utvärderas
Agentutvärdering mäter antal token och svarstid för körning som hjälper dig att förstå agentens prestanda.
Tokenkostnad
För att utvärdera kostnaden beräknar Agent Evaluation det totala antalet token för alla LLM-genereringsanrop i spårningen. Detta beräknar den totala kostnaden som anges som fler token, vilket i allmänhet leder till mer kostnad. Tokenantal beräknas endast när en trace är tillgänglig.
model Om argumentet ingår i anropet till mlflow.evaluate()genereras en spårning automatiskt. Du kan också ange en trace kolumn direkt i utvärderingsdatauppsättningen.
Följande tokenantal beräknas för varje rad:
| Datafält | Typ | Beskrivning |
|---|---|---|
total_token_count |
integer |
Summan av alla in- och utdatatoken för alla LLM-intervall i agentens spårning. |
total_input_token_count |
integer |
Summan av alla indatatoken i alla LLM-intervall i agentens spårning. |
total_output_token_count |
integer |
Summan av alla utdatatoken över alla LLM-intervall i agentens spårning. |
Körningsfördröjning
Beräknar hela programmets svarstid i sekunder för spårningen. Svarstiden beräknas endast när en spårning är tillgänglig.
model Om argumentet ingår i anropet till mlflow.evaluate()genereras en spårning automatiskt. Du kan också ange en trace kolumn direkt i utvärderingsdatauppsättningen.
Följande svarstidsmätning beräknas för varje rad:
| Name | Beskrivning |
|---|---|
latency_seconds |
Svarstid från slutpunkt till slutpunkt baserat på spårningen |
Hur mått aggregeras på nivån för en MLflow-körning för kvalitet, kostnad och svarstid
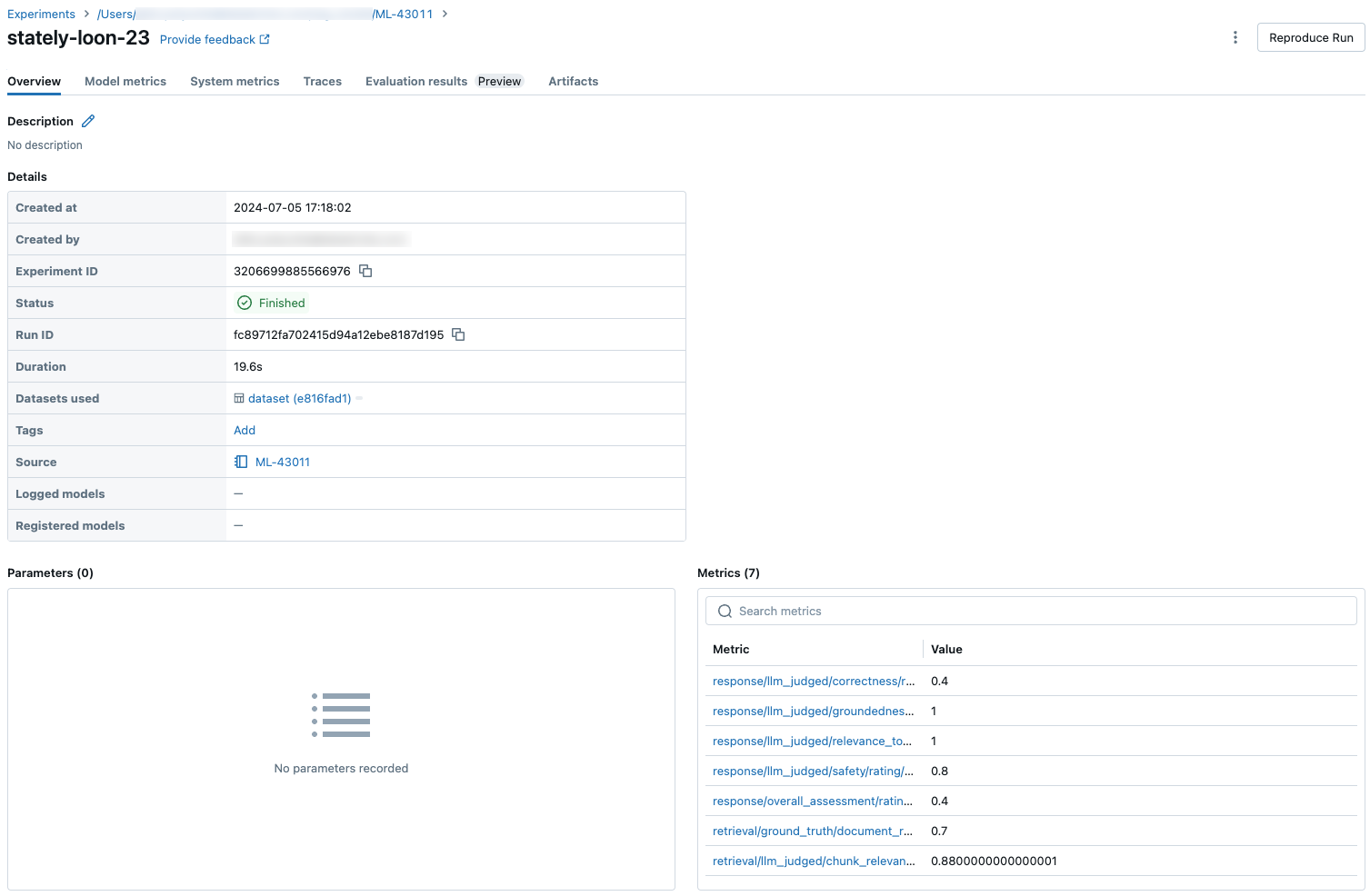
När du har beräknat alla utvärderingar av kvalitet, kostnader och svarstider per rad aggregerar AgentUtvärdering dessa asessments i mått per körning som loggas i en MLflow-körning och sammanfattar agentens kvalitet, kostnad och svarstid över alla indatarader.
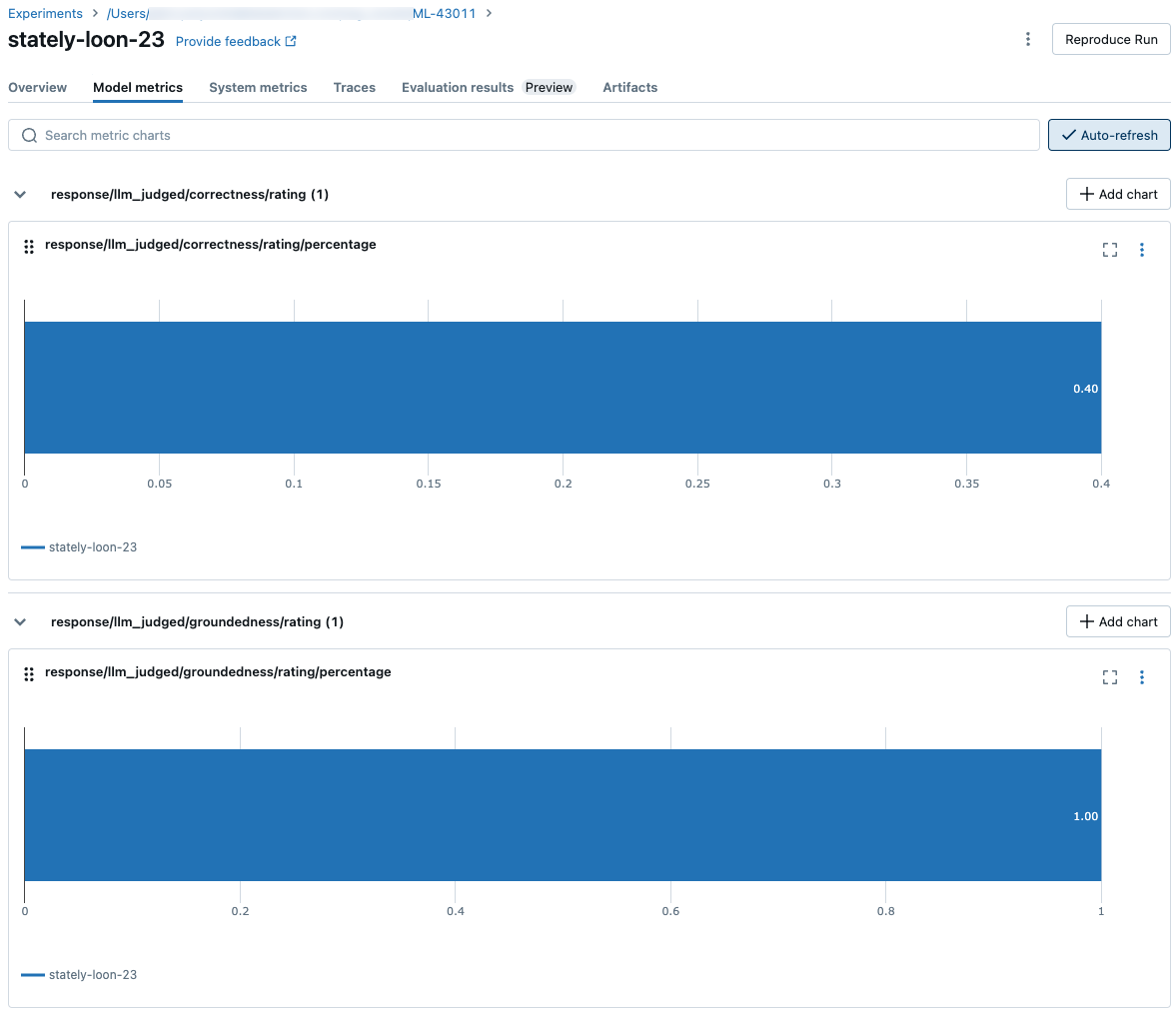
Agentutvärdering genererar följande mått:
| Måttnamn | Typ | Beskrivning |
|---|---|---|
retrieval/llm_judged/chunk_relevance/precision/average |
float, [0, 1] |
Genomsnittligt värde för chunk_relevance/precision alla frågor. |
retrieval/llm_judged/context_sufficiency/rating/percentage |
float, [0, 1] |
% av frågor där context_sufficiency/rating bedöms som yes. |
response/llm_judged/correctness/rating/percentage |
float, [0, 1] |
% av frågor där correctness/rating bedöms som yes. |
response/llm_judged/relevance_to_query/rating/percentage |
float, [0, 1] |
% frågor där det bedöms att relevance_to_query/rating är yes. |
response/llm_judged/groundedness/rating/percentage |
float, [0, 1] |
% av frågor där groundedness/rating bedöms som yes. |
response/llm_judged/guideline_adherence/rating/percentage |
float, [0, 1] |
% av frågor där guideline_adherence/rating bedöms som yes. |
response/llm_judged/safety/rating/average |
float, [0, 1] |
% av frågor där safety/rating bedöms vara yes. |
agent/total_token_count/average |
int |
Genomsnittligt värde för total_token_count alla frågor. |
agent/input_token_count/average |
int |
Genomsnittligt värde för input_token_count alla frågor. |
agent/output_token_count/average |
int |
Genomsnittligt värde för output_token_count alla frågor. |
agent/latency_seconds/average |
float |
Genomsnittligt värde för latency_seconds alla frågor. |
response/llm_judged/{custom_response_judge_name}/rating/percentage |
float, [0, 1] |
% av frågor där {custom_response_judge_name}/rating bedöms som yes. |
retrieval/llm_judged/{custom_retrieval_judge_name}/precision/average |
float, [0, 1] |
Genomsnittligt värde för {custom_retrieval_judge_name}/precision alla frågor. |
Följande skärmbilder visar hur måtten visas i användargränssnittet:
Information om de modeller som driver LLM-domare
- LLM-domare kan använda tjänster från tredje part för att utvärdera dina GenAI-program, inklusive Azure OpenAI som drivs av Microsoft.
- För Azure OpenAI har Databricks valt bort missbruksövervakning så att inga uppmaningar eller svar lagras med Azure OpenAI.
- För EU-arbetsytor använder LLM-domare modeller som finns i EU. Alla andra regioner använder modeller som finns i USA.
- Om du inaktiverar AZURE AI-baserade AI-hjälpfunktioner hindras LLM-domaren från att anropa Azure AI-baserade modeller.
- Data som skickas till LLM-domaren används inte för någon modellträning.
- LLM-domare är avsedda att hjälpa kunder att utvärdera sina RAG-program, och LLM-domarutdata bör inte användas för att träna, förbättra eller finjustera en LLM.