Экспорт данных Dataverse в формате Delta Lake
Используйте Azure Synapse Link для Dataverse, чтобы экспортировать данные Microsoft Dataverse в Azure Synapse Analytics в формате Delta Lake. Затем изучайте данные и сокращайте время получения аналитической информации. В этой статье представлена следующая информация и показано, как выполнить следующие задачи:
- Описание Delta Lake и Parquet и объяснение того, почему следует экспортировать данные в этом формате.
- Экспортируйте данные Dataverse в рабочую область Azure Synapse Analytics в формате Delta Lake с помощью Azure Synapse Link.
- Отслеживайте Azure Synapse Link и преобразование данных.
- Просмотр данных в Azure Data Lake Storage 2-го поколения.
- Просмотр данных в рабочей области Synapse.
Внимание!
- Если вы переходите с CSV на Delta Lake с существующими пользовательскими представлениями, рекомендуется обновить скрипт, чтобы заменить все секционированные таблицы на non_partitioned. Для этого найдите экземпляры
_partitionedи замените их на пустую строку. - В конфигурации Dataverse функция "только добавление" включена по умолчанию для экспорта данных CSV в режиме
appendonly. Однако таблица Delta Lake будет иметь готовую структуру обновления, поскольку преобразование Delta Lake сопровождается периодическим процессом слияния. - Создание пулов Spark не требует затрат. Плата взимается только после выполнения задания Spark в целевом пуле Spark и создания экземпляра Spark по запросу. Эти расходы связаны с использованием Spark Azure Synapse workspace и оплачиваются ежемесячно. Стоимость проведения вычисления Spark в основном зависит от временного интервала добавочного обновления и объемов данных. Дополнительные сведения: Цены Azure Synapse Analytics
- Важно учитывать эти дополнительные расходы при принятии решения об использовании этой функции, поскольку они не являются необязательными и должны быть оплачены, чтобы продолжить использование этой функции.
- Объявлено об окончании поддержки (EOLA) для среды выполнения Azure Synapse Runtime для Apache Spark 3.3 с 12 июля 2024 г. В соответствии с политикой жизненного цикла среды выполнения Synapse для Apache Spark, среда выполнения Azure Synapse для Apache Spark 3.3 будет выведена из эксплуатации и отключена 31 марта 2025 г. После даты EOL устаревшие среды выполнения недоступны для новых пулов Spark, а существующие рабочие процессы не могут выполняться. Метаданные временно останутся в рабочей области Synapse. Дополнительные сведения: Среда выполнения Azure Synapse для Apache Spark 3.3 (EOSA). Чтобы иметь ссылку Synapse Link для Dataverse с экспортом в формат Delta Lake и обновлением до Spark 3.4, выполните обновление существующих профилей на месте. Дополнительные сведения: Обновление на месте до Apache Spark 3.4 с Delta Lake 2.4
- Начиная с 25 декабря 2024 г. при первоначальном создании ссылки будет поддерживаться только пул Spark версии 3.4.
Заметка
Состояние Azure Synapse Link в Power Apps (make.powerapps.com) отражает состояние преобразования Delta Lake:
-
Countпоказывает общее число записей в таблице Delta Lake. -
Last synchronized onDatetime представляет временную метку последнего успешного преобразования. -
Sync statusотображается как активный после завершения синхронизации данных и преобразования Delta Lake, что указывает на то, что данные готовы к использованию.
Что такое Delta Lake?
Delta Lake — это проект с открытым исходным кодом, который позволяет создавать архитектуру хранилища в озере данных на основе озер данных. Delta Lake обеспечивает транзакции ACID (атомарность, согласованность, изоляция и надежность) и масштабируемую обработку метаданных, а также унифицирует потоковую передачу и пакетную обработку данных на основании существующих озер данных. Служба Azure Synapse Analytics совместима с Linux Foundation Delta Lake. Текущая версия Delta Lake, включенная в Azure Synapse, поддерживает языки Scala, PySpark и .NET. Дополнительные сведения: Что такое Delta Lake?. Вы также можете узнать больше в видео Введение в Delta Tables.
Apache Parquet — это базовый формат для Delta Lake, позволяющий использовать эффективные схемы сжатия и кодирования, присущие этому формату. Формат файла Parquet использует сжатие по столбцам. Это эффективно и экономит место в хранилище. Запросам, которые извлекают определенные значения столбца, не требуется считывать все данные строки, что повышает производительность. Поэтому бессерверному пулу SQL требуется меньше времени и меньше запросов к хранилищу для чтения данных.
Зачем использовать Delta Lake?
- Масштабируемость: Delta Lake создан на основании лицензии Apache с открытым исходным кодом, которая разработана в соответствии с отраслевыми стандартами для обработки крупномасштабных рабочих нагрузок обработки данных.
- Надежность: Delta Lake предоставляет транзакции ACID, обеспечивая согласованность и надежность данных даже в случае сбоев или одновременного доступа.
- Производительность: Delta Lake использует формат хранения в столбцах Parquet, обеспечивая улучшенные методы сжатия и кодирования, что может привести к повышению производительности запросов по сравнению с CSV-файлами запросов.
- Рентабельность: формат файла Delta Lake — это технология хранения данных с высокой степенью сжатия, которая обеспечивает значительную потенциальную экономию места в хранилище для предприятий. Этот формат специально разработан для оптимизации обработки данных и потенциального сокращения общего объема обработанных данных или времени выполнения, необходимого для вычисления по требованию.
- Соответствие требованиям к защите данных: Delta Lake с Azure Synapse Link предоставляет инструменты и функции, включая обратимое и необратимое удаление, для соблюдения различных правил конфиденциальности данных, включая Общий регламент по защите данных (GDPR).
Как Delta Lake работает с Azure Synapse Link для Dataverse?
При настройке Azure Synapse Link для Dataverse можно включить функцию экспорта в Delta Lake и подключиться к рабочей области Synapse и пулу Spark. Azure Synapse Link экспортирует выбранные таблицы Dataverse в формате CSV через заданные интервалы времени и обрабатывает их с помощью задания Spark для преобразования Delta Lake. По завершении этого процесса преобразования данные CSV очищаются для хранения в хранилище. Кроме того, планируется ежедневное выполнение ряда заданий обслуживания, автоматически выполняющих процессы сжатия и очистки с целью объединения и очистки файлов данных для дальнейшей оптимизации хранилища и повышения производительности запросов.
Предварительные условия
- Dataverse. У вас должна быть роль безопасности Системный администратор в Dataverse. Кроме того, для таблиц, которые вы хотите экспортировать через Azure Synapse Link, должно быть включено свойство Отслеживать изменения. Больше информации: Дополнительные параметры
- Azure Data Lake Storage Gen2: у вас должна быть учетная запись Azure Data Lake Storage Gen2 и доступ с ролью Владелец и Участник данных хранилища BLOB-объектов. В вашей учетной записи хранения должны быть включены иерархическое пространство имен и доступ к общедоступной сети как для первоначальной настройки, так и для дельта-синхронизации. Параметр Разрешить доступ к ключу учетной записи хранения требуется только для первоначальной настройки.
- Рабочая область Synapse: у вас должна быть рабочая область и роль Владелец в системе управления идентификацией и доступом (IAM), а также доступ с ролью Администратор Synapse в Synapse Studio. Рабочая область Synapse должна находиться в том же регионе, что и ваша учетная запись Azure Data Lake Storage Gen2. Учетная запись хранения должна быть добавлена в качестве связанной службы в Synapse Studio. Чтобы создать рабочую область Synapse, перейдите в Создание рабочей области Synapse.
- Пул Apache Spark в подключенной рабочей области Azure Synapse workspace с Apache Spark 3.4, использующий эту рекомендуемую конфигурацию пула Spark. Информацию о том, как создать пул Spark, см. в статье Создание нового пула Apache Spark.
- Минимальная версия Microsoft Dynamics 365 для использования этой функции — 9.2.22082. Дополнительные сведения: Согласие на обновления раннего доступа
Рекомендуемая конфигурация пула Spark
Эту конфигурацию можно считать шагом начальной загрузки для обычных вариантов использования.
- Размер узла: небольшой (4 виртуальных ядра/32 ГБ)
- Автомасштабирование: включено
- Число узлов: 5–10
- Автоматическая приостановка: включено
- Количество минут простоя: 5
- Apache Spark: 3.4
- Динамическое выделение исполнителей: включено
- Количество исполнителей по умолчанию: от 1 до 9
Внимание!
Используйте пул Spark исключительно для разговорной операций Delta Lake с помощью Synapse Link для Dataverse. Для обеспечения оптимальной надежности и производительности избегайте выполнения других заданий Spark с использованием одного и того же пула Spark.
Подключение Dataverse к рабочей области Synapse и экспорт данных в формате Delta Lake
Войдите в Power Apps и выберите нужную среду.
В левой области переходов выберите Azure Synapse Link. Если этого пункта нет на боковой панели, выберите …Еще, а затем выберите нужный пункт.
На панели команд выберите Создать связь
Выберите Подключиться к рабочей области Azure Synapse Analytics, а затем выберите Подписка, Группа ресурсов и Имя рабочей области.
Выберите Использовать для обработки пул Spark, а затем выберите предварительно созданные Пул Spark и Учетную запись хранения.
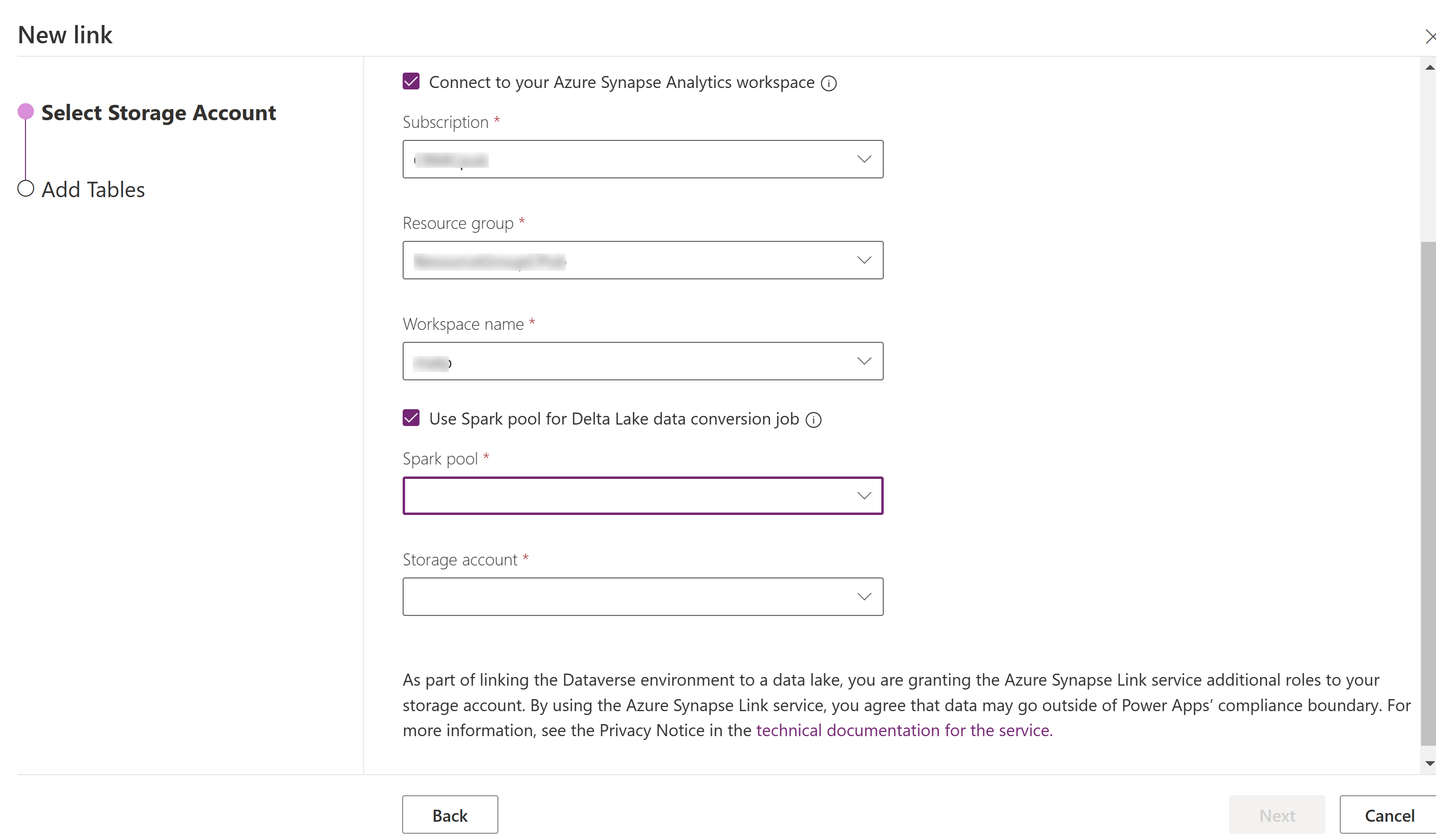
Выберите Далее.
Добавьте таблицы, которые требуется экспортировать, а затем выберите Дополнительно.
При желании выберите Показать дополнительные параметры конфигурации и введите временной интервал (в минутах) для определения того, как часто должны собираться добавочные обновления.
Выберите Сохранить.
Отслеживание Azure Synapse Link и преобразования данных
- Выберите требуемую Azure Synapse Link и затем выберите Перейти к рабочей области Azure Synapse Analytics на панели команд.
- Выберите Мониторинг>Приложения Apache Spark. Дополнительные сведения: Использование Synapse Studio для мониторинга приложений Apache Spark
Просмотр данных в рабочей области Synapse
- Выберите требуемую Azure Synapse Link и затем выберите Перейти к рабочей области Azure Synapse Analytics на панели команд.
- Разверните Базы данных озер в левой области, выберите dataverse-environmentNameorganizationUniqueName, затем разверните Таблицы. Все таблицы Parquet перечислены и доступны для анализа в соответствии с соглашением об именовании DataverseTableName_partitioned.Таблица Non_partitioned
Заметка
Не используйте таблицы с соглашением об именовании _partitioned. Если в качестве формата выбран формат delta parquet, таблицы с соглашением об именовании _partition используются в качестве промежуточных таблиц и удаляются после их использования системой.
Просмотр данных в Azure Data Lake Storage 2-го поколения
- Выберите требуемую функцию Azure Synapse Link и затем выберите Перейти к озеру данных Azure на панели команд.
- Выберите Контейнеры в разделе Хранилище данных.
- Выберите *dataverse- *environmentName-organizationUniqueName. Все файлы Parquet сохранятся в папке deltalake.
Обновление на месте до Apache Spark 3.4 с Delta Lake 2.4
Предварительные требования
- У вас должен быть существующий профиль Azure Synapse Link для Dataverse Delta Lake, работающий с Synapse Spark версии 3.3.
- Необходимо создать новый пул Synapse Spark с Spark версии 3.4, используя ту же или более позднюю конфигурацию оборудования узлов в той же рабочей области Synapse. Информацию о том, как создать пул Spark, см. в статье Создание нового пула Apache Spark. Этот пул Spark должен быть создан независимо от текущего пула 3.3.
Обновление на месте до Spark 3.4:
- Войдите в Power Apps и выберите предпочитаемую среду.
- В левой области переходов выберите Azure Synapse Link. Если этого пункта нет на левой панели навигации, выберите …Еще, а затем выберите нужный пункт.
- Откройте профиль Azure Synapse Link, затем выберите Обновить до Apache Spark версии 3.4 с Delta Lake 2.4.
- Выберите доступный пул Spark из списка, затем выберите Обновить.
Заметка
Обновление пула Spark происходит только при запуске нового задания Spark для преобразования Delta Lake. Убедитесь, что у вас есть хотя бы одно изменение данных после выбора Обновить.