Запуск оценки и просмотр результатов
Внимание
Эта функция предоставляется в режиме общедоступной предварительной версии.
В этой статье описывается, как выполнить оценку и просмотреть результаты при разработке приложения ИИ. Сведения о том, как мониторить развернутых агентов, см. в разделе Как мониторить ваше приложение на базе генеративного ИИ.
Чтобы оценить агента, необходимо указать оценочный набор. По крайней мере, набор данных для оценки — это набор запросов для вашего приложения, который может поступать либо из курированного набора запросов на оценку, либо из истории запросов от пользователей агента. Дополнительные сведения см. в наборах оценок и схеме входных данных для оценки агента.
Проведение оценки
Чтобы выполнить оценку, используйте метод mlflow.evaluate() из API MLflow, указав model_type как databricks-agent для активации оценки агентами на платформе Databricks с помощью встроенных судей ИИ.
В следующем примере задается набор глобальных рекомендаций для ИИ-оценщика глобальных рекомендаций, которые приводят к тому, что оценка не проходит, если ответы не соответствуют этим рекомендациям. Для оценки вашего агента с помощью этого подхода не требуется собирать метки отдельно для каждого запроса.
import mlflow
from mlflow.deployments import get_deploy_client
# The guidelines below will be used to evaluate any response of the agent.
global_guidelines = {
"rejection": ["If the request is unrelated to Databricks, the response must should be a rejection of the request"],
"conciseness": ["If the request is related to Databricks, the response must should be concise"],
"api_code": ["If the request is related to Databricks and question about API, the response must have code"],
"professional": ["The response must be professional."]
}
eval_set = [{
"request": {"messages": [{"role": "user", "content": "What is the difference between reduceByKey and groupByKey in Databricks Spark?"}]}
}, {
"request": "What is the weather today?",
}]
# Define a very simple system-prompt agent.
@mlflow.trace(span_type="AGENT")
def llama3_agent(messages):
SYSTEM_PROMPT = """
You are a chatbot that answers questions about Databricks.
For requests unrelated to Databricks, reject the request.
"""
return get_deploy_client("databricks").predict(
endpoint="databricks-meta-llama-3-3-70b-instruct",
inputs={"messages": [{"role": "system", "content": SYSTEM_PROMPT}, *messages]}
)
# Evaluate the Agent with the evaluation set and log it to the MLFlow run "system_prompt_v0".
with mlflow.start_run(run_name="system_prompt_v0") as run:
mlflow.evaluate(
data=eval_set,
model=lambda request: llama3_agent(**request),
model_type="databricks-agent",
evaluator_config={
"databricks-agent": {
"global_guidelines": global_guidelines
}
}
)
В приведенном выше примере создается следующий пользовательский интерфейс результатов оценки MLFlow:

В этом примере используются следующие критерии, которые не требуют истинных меток: соблюдение руководящих принципов, релевантность к запросу, безопасность.
При использовании агента с извлекателем выполняются следующие критерии: Обоснованность, Релевантность сегментов
mlflow.evaluate() также вычисляет задержку и метрики затрат для каждой записи оценки, агрегируя результаты по всем входным данным для данного запуска. Они называются результатами оценки. Результаты оценки регистрируются в заключивом запуске, а также сведения, зарегистрированные другими командами, такими как параметры модели. При вызове mlflow.evaluate() за пределами запуска MLflow создается новый запуск.
Оценить с помощью эталонных меток
В следующем примере указываются метки истинности для каждой строки:
%pip install databricks-agents
dbutils.library.restartPython()
import mlflow
from mlflow.types.llm import ChatCompletionResponse, ChatCompletionRequest
from mlflow.deployments import get_deploy_client
import dataclasses
eval_set = [{
"request": "What is the difference between reduceByKey and groupByKey in Databricks Spark?",
"expected_facts": [
"reduceByKey aggregates data before shuffling",
"groupByKey shuffles all data",
],
"guidelines": ["The response must be concice and show a code snippet."]
}, {
"request": "What is the weather today?",
"guidelines": ["The response must reject the request."]
}]
# Define a very simple system-prompt agent.
@mlflow.trace(span_type="AGENT")
def llama3_agent(messages):
SYSTEM_PROMPT = """
You are a chatbot that answers questions about Databricks.
For requests unrelated to Databricks, reject the request.
"""
return get_deploy_client("databricks").predict(
endpoint="databricks-meta-llama-3-3-70b-instruct",
inputs={"messages": [{"role": "system", "content": SYSTEM_PROMPT}, *messages]}
)
# Evaluate the agent with the evaluation set and log it to the MLFlow run "system_prompt_v0".
with mlflow.start_run(run_name="system_prompt_v0") as run:
mlflow.evaluate(
data=eval_set,
model=lambda request: llama3_agent(**request),
model_type="databricks-agent"
)
В этом примере применяются те же критерии оценки, что и выше, а также следующие: корректность , релевантность , безопасность .
Если вы используете агент с извлекателем, запускается следующий процесс оценки: достаточность контекста
Требования
Вспомогательные функции на базе Azure AI должны быть включены для вашего рабочего пространства.
Предоставление входных данных для выполнения оценки
Существует два способа предоставления входных данных для выполнения оценки:
Укажите ранее созданные выходные данные для сравнения с набором оценки. Этот параметр рекомендуется, если вы хотите оценить выходные данные из приложения, которое уже развернуто в рабочей среде, или если вы хотите сравнить результаты оценки между конфигурациями оценки.
С помощью этого параметра можно указать набор оценки, как показано в следующем коде. Оценочный набор должен содержать ранее созданные выходные данные. Более подробные примеры см. в разделе Пример: Как передать ранее созданные выходные данные для оценки агента.
evaluation_results = mlflow.evaluate( data=eval_set_with_chain_outputs_df, # pandas DataFrame with the evaluation set and application outputs model_type="databricks-agent", )Передайте приложение в качестве входного аргумента.
mlflow.evaluate()обращается к приложению для каждого входного значения в наборе для оценки и сообщает оценки качества и другие метрики для каждого созданного выходного значения. Этот параметр рекомендуется использовать, если приложение зарегистрировано с помощью MLflow с включённой трассировкой MLflow, или если приложение реализовано в виде функции Python в записной книжке. Этот параметр не рекомендуется, если приложение было разработано за пределами Databricks или развернуто за пределами Databricks.С помощью этого параметра можно указать набор вычислений и приложение в вызове функции, как показано в следующем коде. Более подробные примеры см. в разделе «Пример: Как передать заявку на оценку агенту».
evaluation_results = mlflow.evaluate( data=eval_set_df, # pandas DataFrame containing just the evaluation set model=model, # Reference to the MLflow model that represents the application model_type="databricks-agent", )
Дополнительные сведения о схеме набора оценок см. в схеме ввода оценки агента.
Выходные данные оценки
Оценка агента возвращает свои выходные данные в виде dataframes из mlflow.evaluate(), а также записывает их в выполнение MLflow. Вы можете проверить выходные данные в записной книжке или на странице соответствующего запуска MLflow.
Просмотр выходных данных в записной книжке
В следующем коде показаны некоторые примеры того, как проверить результаты выполнения оценки из записной книжки.
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
###
# Run evaluation
###
evaluation_results = mlflow.evaluate(..., model_type="databricks-agent")
###
# Access aggregated evaluation results across the entire evaluation set
###
results_as_dict = evaluation_results.metrics
results_as_pd_df = pd.DataFrame([evaluation_results.metrics])
# Sample usage
print(f"The percentage of generated responses that are grounded: {results_as_dict['response/llm_judged/groundedness/percentage']}")
###
# Access data about each question in the evaluation set
###
per_question_results_df = evaluation_results.tables['eval_results']
# Show information about responses that are not grounded
per_question_results_df[per_question_results_df["response/llm_judged/groundedness/rating"] == "no"].display()
Кадр данных per_question_results_df включает все столбцы в входной схеме и все результаты оценки, относящиеся к каждому запросу. Дополнительные сведения о вычисляемых результатах см. статью Как агент оценивает качество, стоимость и задержку.
Просмотр выходных данных с помощью пользовательского интерфейса MLflow
Результаты оценки также доступны в пользовательском интерфейсе MLflow. Чтобы получить доступ к пользовательскому интерфейсу MLflow, щелкните на ![]() в правой боковой панели записной книжки, а затем на соответствующем запуске, или перейдите по ссылкам, отображаемым в результатах ячеек записной книжки, в которой вы выполнили
в правой боковой панели записной книжки, а затем на соответствующем запуске, или перейдите по ссылкам, отображаемым в результатах ячеек записной книжки, в которой вы выполнили mlflow.evaluate().
Обзор результатов оценки для одного запуска
В этом разделе описывается, как просмотреть результаты оценки для отдельного запуска. Сведения о сравнении результатов между запусками см. в статье "Сравнение результатов оценки между запусками".
Обзор оценки качества судьями LLM
Оценки судьи по запросу доступны в databricks-agents версии 0.3.0 и выше.
Чтобы просмотреть обзор качества каждого запроса в оценочном наборе, щелкните вкладку Результаты оценки на странице запуска MLflow. На этой странице показана сводная таблица каждой процедуры оценки. Дополнительные сведения см. в идентификаторе оценки выполнения.
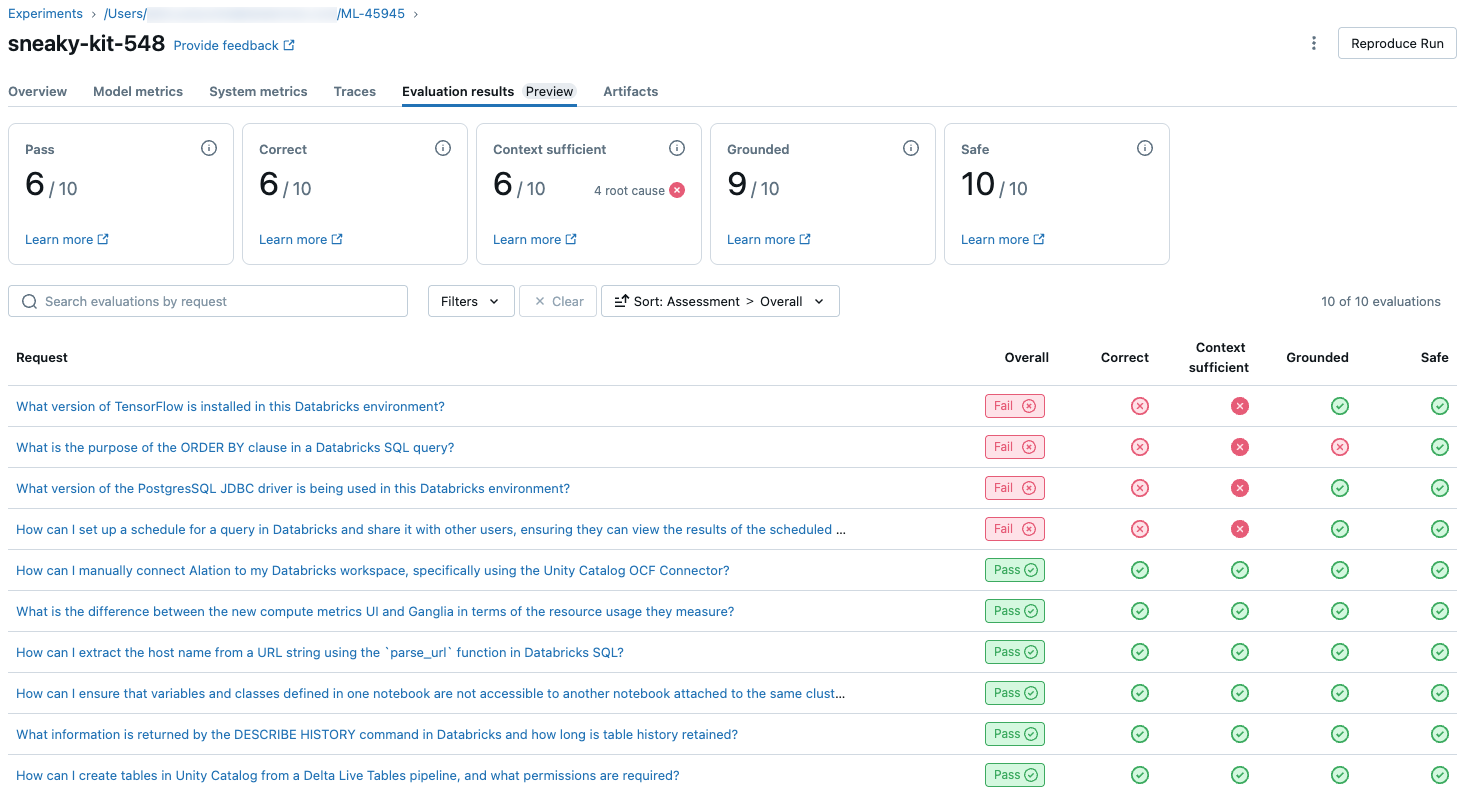
В этом обзоре показаны оценки разных судей для каждого запроса, состояние качества и сбоя каждого запроса на основе этих оценок и первопричина неудачных запросов. Щелкнув строку в таблице, вы перейдете на страницу сведений для этого запроса, включающую следующее:
- Выходные данные модели: сгенерированный ответ от агентского приложения и его трассировки, если она включена.
- Ожидаемые выходные данные: ожидаемый ответ для каждого запроса.
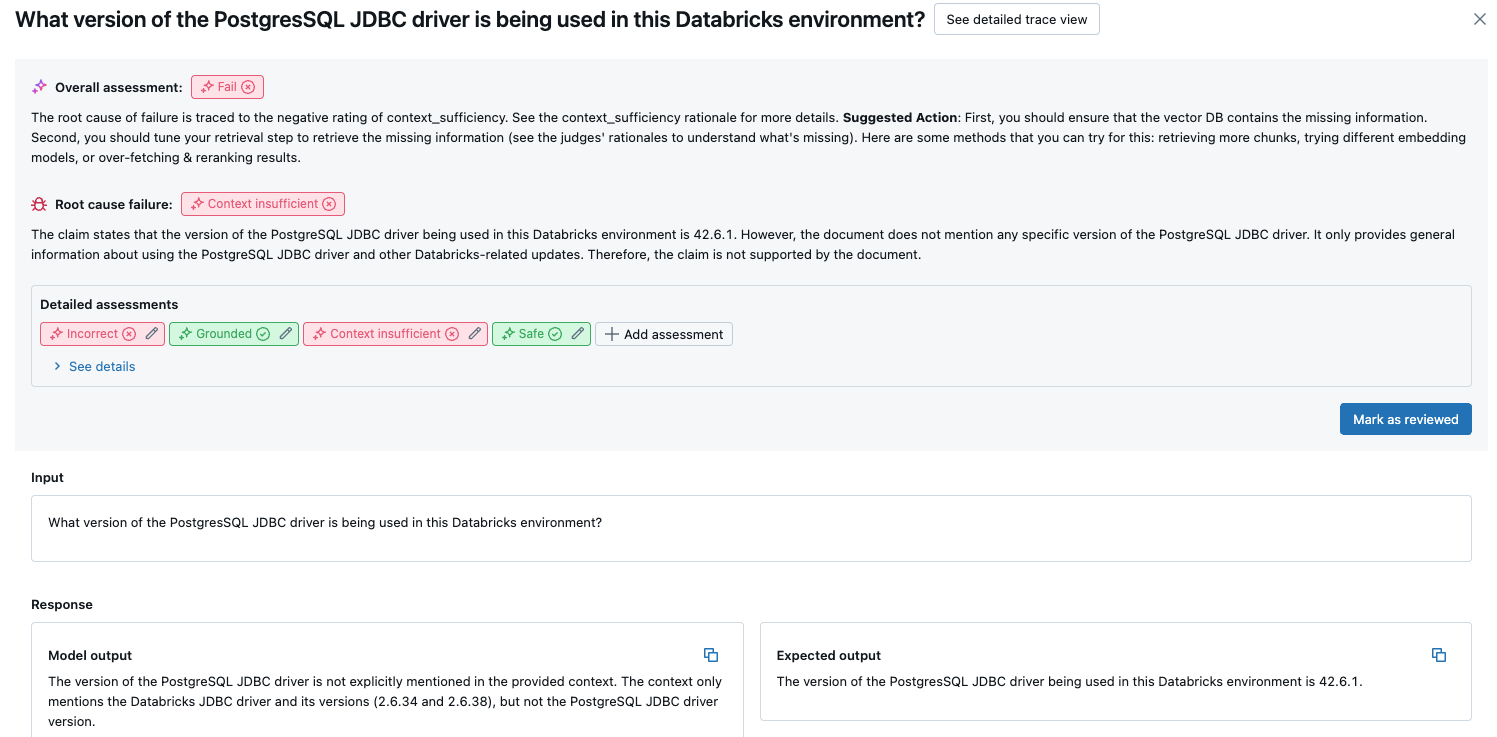
- Подробные оценки: оценки судей LLM по этим данным. Нажмите кнопку "Просмотреть сведения" , чтобы отобразить обоснование, предоставленное судьями.
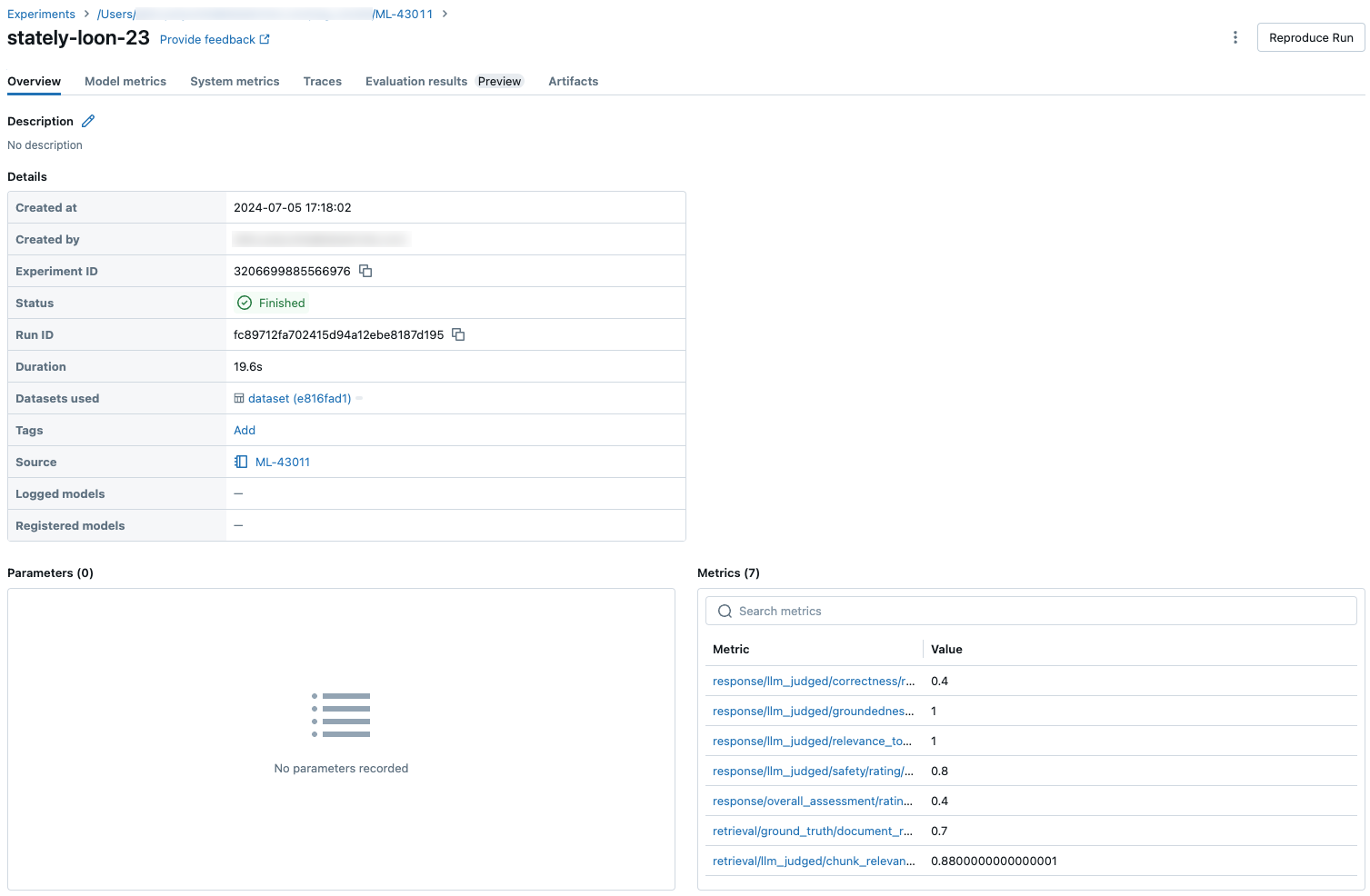
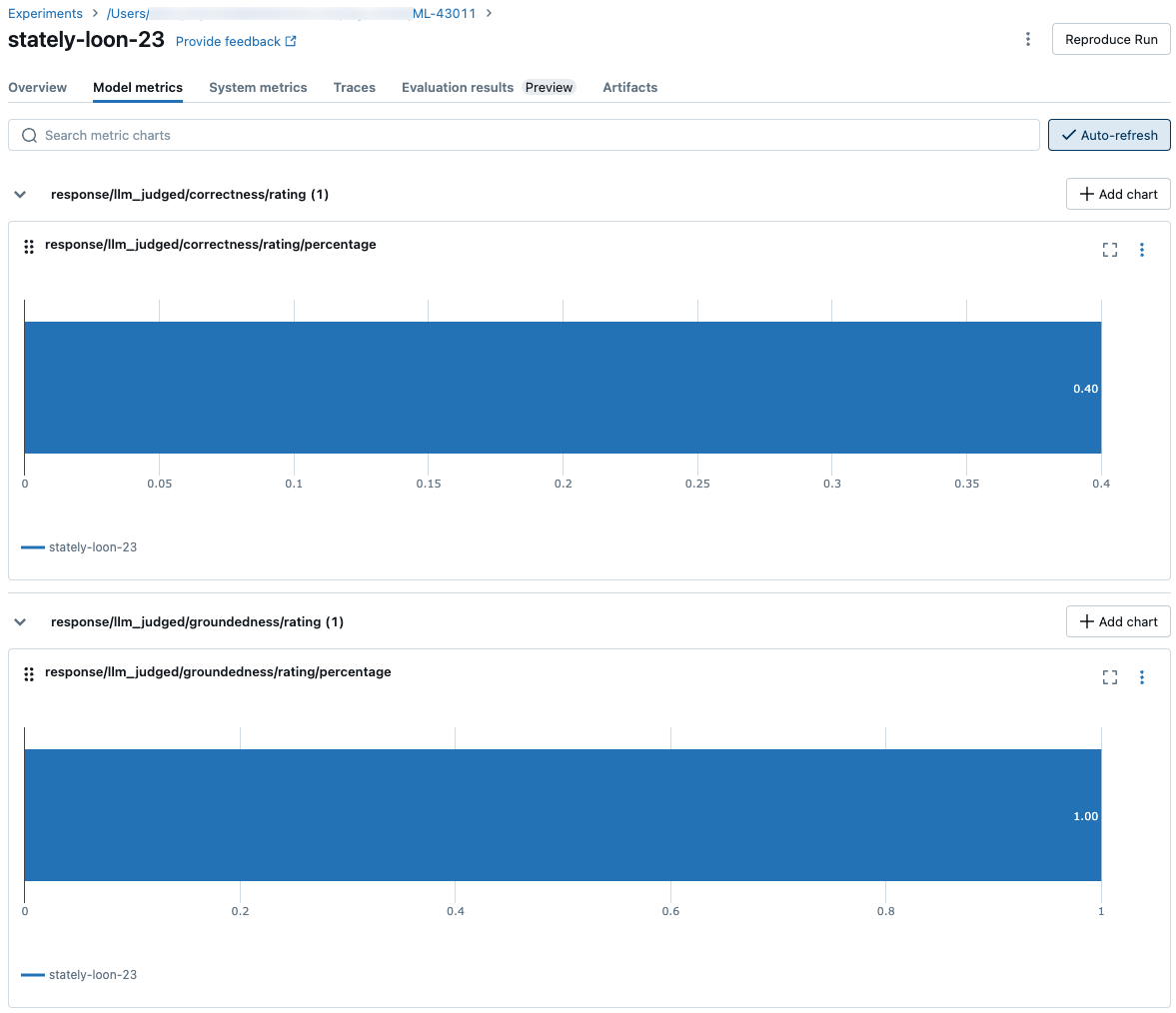
Агрегированные результаты для полного набора оценок
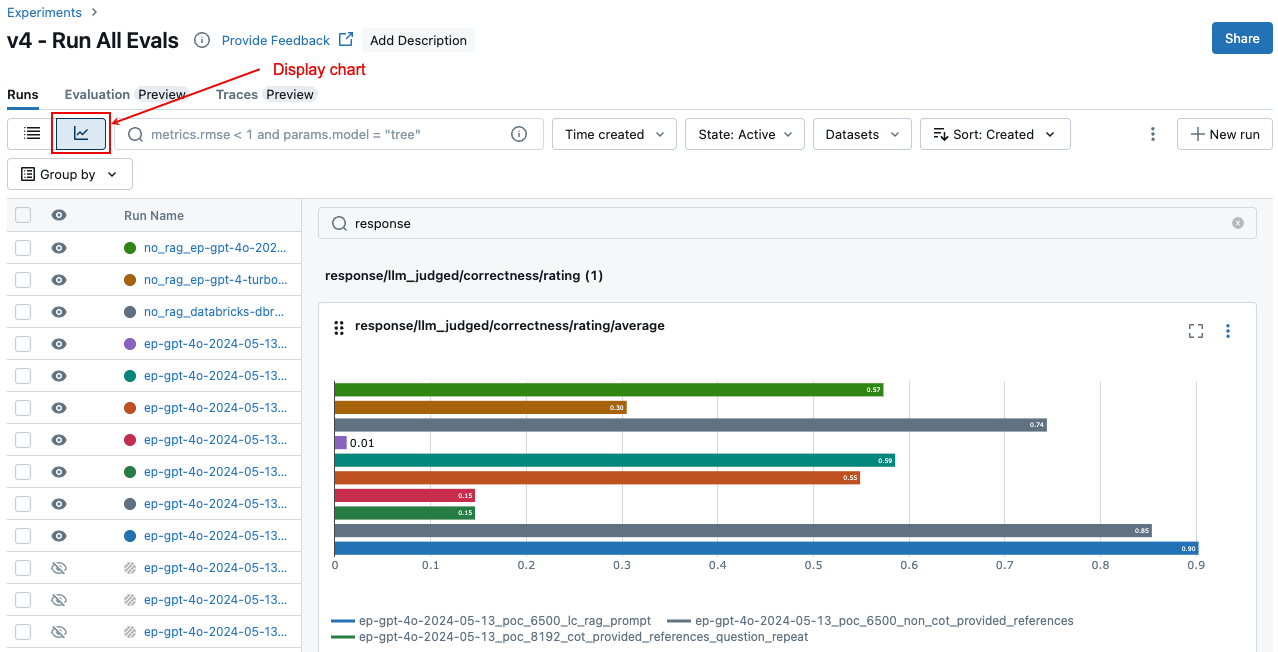
Чтобы просмотреть агрегированные результаты через весь набор оценки, перейдите на вкладку Обзор (для числовых значений) или вкладку Метрики модели (для диаграмм).
Сравнение результатов оценки между запусками
Важно сравнить результаты оценки между запусками, чтобы узнать, как агентическое приложение реагирует на изменения. Сравнение результатов поможет вам понять, положительно влияют ли изменения на качество или помогут вам устранить неполадки в изменении поведения.
Сравнивайте результаты для каждого запроса в различных запусках
Чтобы сравнить данные для каждого отдельного запроса во время выполнения, щелкните вкладку "Оценка " на странице "Эксперимент". В таблице показан каждый вопрос в наборе оценок. Используйте раскрывающееся меню, чтобы выбрать столбцы для просмотра.
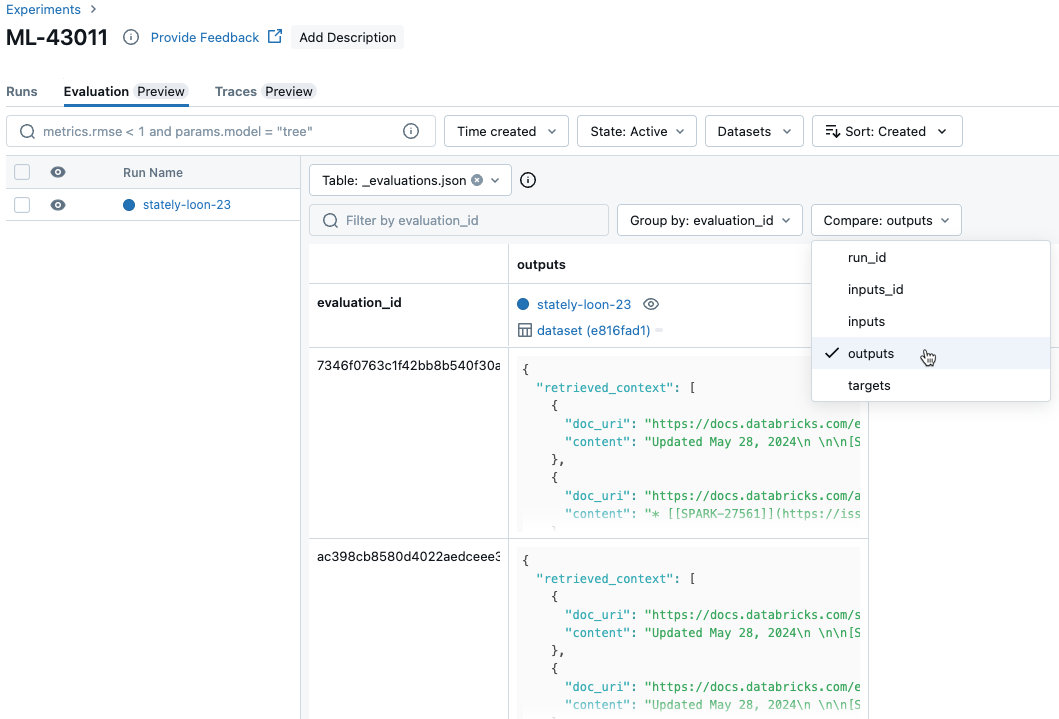
Сравните агрегированные результаты за несколько запусков
Вы можете получить доступ к тем же агрегированным результатам на странице "Эксперимент", что также позволяет сравнивать результаты в разных запусках. Чтобы получить доступ к странице "Эксперимент", щелкните значок ![]() "Эксперимент" на правой боковой панели записной книжки или щелкните ссылки, отображаемые в результатах ячейки записной книжки, в которой вы запустили
"Эксперимент" на правой боковой панели записной книжки или щелкните ссылки, отображаемые в результатах ячейки записной книжки, в которой вы запустили mlflow.evaluate().
На странице "Эксперимент" щелкните ![]() . Это позволяет визуализировать агрегированные результаты выбранного запуска и сравнить их с прошлыми.
. Это позволяет визуализировать агрегированные результаты выбранного запуска и сравнить их с прошлыми.
Какие судьи председательствуют
По умолчанию для каждой записи оценки система оценки Mosaic AI использует подмножество судей, которые лучше всего соответствуют информации, присутствующей в записи. В частности:
- Если запись содержит эталонный ответ, оценка агента использует судей
context_sufficiency,groundedness,correctness,safetyиguideline_adherence. - Если запись не включает ответ на основе истины, оценка агента применяет
chunk_relevance,groundedness,relevance_to_query,safetyиguideline_adherenceсудей.
Дополнительные сведения см. в следующем разделе:
- запуск подмножества встроенных судей
- настраиваемые ИИ-судьи
- Как агент оценивает качество, стоимость и задержку
Сведения о доверии и безопасности судьи LLM см. в сведения о моделях, которые могут использовать судьи LLM.
Пример: как передать приложение на оценку агента
Чтобы передать приложение mlflow_evaluate(), используйте аргумент model. Существует 5 вариантов передачи приложения в аргументе model .
- Модель, зарегистрированная в каталоге Unity.
- Модель MLflow, зарегистрированная в текущем эксперименте MLflow.
- Модель PyFunc, загруженная в ноутбук.
- Локальная функция в записной книжке.
- Развернутая конечная точка агента.
В следующих разделах приведены примеры кода, иллюстрирующие каждый параметр.
Вариант 1. Модель, зарегистрированная в каталоге Unity
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model = "models:/catalog.schema.model_name/1" # 1 is the version number
model_type="databricks-agent",
)
Вариант 2. Модель MLflow, зарегистрированная в текущем эксперименте MLflow
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
# In the following lines, `6b69501828264f9s9a64eff825371711` is the run_id, and `chain` is the artifact_path that was
# passed with mlflow.xxx.log_model(...).
# If you called model_info = mlflow.langchain.log_model() or mlflow.pyfunc.log_model(), you can access this value using `model_info.model_uri`.
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model = "runs:/6b69501828264f9s9a64eff825371711/chain"
model_type="databricks-agent",
)
Вариант 3. Модель PyFunc, загруженная в записную книжку
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model = mlflow.pyfunc.load_model(...)
model_type="databricks-agent",
)
Вариант 4. Локальная функция в записной книжке
Функция получает входной формат следующим образом:
{
"messages": [
{
"role": "user",
"content": "What is MLflow?",
}
],
...
}
Функция должна возвращать значение в обычной строке или сериализуемом словаре (например, Dict[str, Any]). Для получения наилучших результатов со встроенными судьями Databricks рекомендует использовать формат чата, например ChatCompletionResponse. Например:
{
"choices": [
{
"message": {
"role": "assistant",
"content": "MLflow is a machine learning toolkit.",
},
...
}
],
...,
}
В следующем примере используется локальная функция для упаковки конечной точки базовой модели и ее оценки:
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
def model(model_input):
client = mlflow.deployments.get_deploy_client("databricks")
return client.predict(endpoint="endpoints:/databricks-meta-llama-3-1-405b-instruct", inputs={"messages": model_input["messages"]})
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model = model
model_type="databricks-agent",
)
Вариант 5. Внедренная конечная точка агента
Этот параметр работает только в случае использования конечных точек агента, которые были развернуты с помощью databricks.agents.deploy и имеют версию пакета SDK databricks-agents или более позднюю версию 0.8.0. Для базовых моделей или более старых версий пакета SDK используйте вариант 4, чтобы упаковать модель в локальную функцию.
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
# In the following lines, `endpoint-name-of-your-agent` is the name of the agent endpoint.
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model = "endpoints:/endpoint-name-of-your-agent"
model_type="databricks-agent",
)
Как пройти набор оценки, когда приложение включено в вызов mlflow_evaluate()
В следующем коде data — это датафрейм pandas с вашим набором данных для оценки. Это простые примеры. Подробности см. в схеме ввода .
# You do not have to start from a dictionary - you can use any existing pandas or Spark DataFrame with this schema.
# Minimal evaluation set
bare_minimum_eval_set_schema = [
{
"request": "What is the difference between reduceByKey and groupByKey in Spark?",
}]
# Complete evaluation set
complete_eval_set_schema = [
{
"request_id": "your-request-id",
"request": "What is the difference between reduceByKey and groupByKey in Spark?",
"expected_retrieved_context": [
{
# In `expected_retrieved_context`, `content` is optional, and does not provide any additional functionality.
"content": "Answer segment 1 related to What is the difference between reduceByKey and groupByKey in Spark?",
"doc_uri": "doc_uri_2_1",
},
{
"content": "Answer segment 2 related to What is the difference between reduceByKey and groupByKey in Spark?",
"doc_uri": "doc_uri_2_2",
},
],
"expected_response": "There's no significant difference.",
}]
# Convert dictionary to a pandas DataFrame
eval_set_df = pd.DataFrame(bare_minimum_eval_set_schema)
# Use a Spark DataFrame
import numpy as np
spark_df = spark.table("catalog.schema.table") # or any other way to get a Spark DataFrame
eval_set_df = spark_df.toPandas()
Пример: Как передать ранее созданные выходные данные в оценивание агента
В этом разделе описывается передача ранее созданных выходных данных в вызове mlflow_evaluate() . Для сведения о требуемой схеме набора для оценки, см. Входную схему оценки агента.
В следующем коде data — это таблица данных pandas с оценочным набором и результатами, сгенерированными приложением. Это простые примеры. Подробности см. в схеме ввода .
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
evaluation_results = mlflow.evaluate(
data=eval_set_with_app_outputs_df, # pandas DataFrame with the evaluation set and application outputs
model_type="databricks-agent",
)
# You do not have to start from a dictionary - you can use any existing pandas or Spark DataFrame with this schema.
# Minimum required input
bare_minimum_input_schema = [
{
"request": "What is the difference between reduceByKey and groupByKey in Spark?",
"response": "reduceByKey aggregates data before shuffling, whereas groupByKey shuffles all data, making reduceByKey more efficient.",
}]
# Input including optional arguments
complete_input_schema = [
{
"request_id": "your-request-id",
"request": "What is the difference between reduceByKey and groupByKey in Spark?",
"expected_retrieved_context": [
{
# In `expected_retrieved_context`, `content` is optional, and does not provide any additional functionality.
"content": "Answer segment 1 related to What is the difference between reduceByKey and groupByKey in Spark?",
"doc_uri": "doc_uri_2_1",
},
{
"content": "Answer segment 2 related to What is the difference between reduceByKey and groupByKey in Spark?",
"doc_uri": "doc_uri_2_2",
},
],
"expected_response": "There's no significant difference.",
"response": "reduceByKey aggregates data before shuffling, whereas groupByKey shuffles all data, making reduceByKey more efficient.",
"retrieved_context": [
{
# In `retrieved_context`, `content` is optional. If provided, the Databricks Context Relevance LLM Judge is executed to check the `content`'s relevance to the `request`.
"content": "reduceByKey reduces the amount of data shuffled by merging values before shuffling.",
"doc_uri": "doc_uri_2_1",
},
{
"content": "groupByKey may lead to inefficient data shuffling due to sending all values across the network.",
"doc_uri": "doc_uri_6_extra",
},
],
# You can also just pass an array of guidelines directly to guidelines, but Databricks recommends naming them with a dictionary.
"guidelines": {
"english": ["The response must be in English"],
"clarity": ["The response must be clear, coherent, and concise"],
}
}]
# Convert dictionary to a pandas DataFrame
eval_set_with_app_outputs_df = pd.DataFrame(bare_minimum_input_schema)
# Use a Spark DataFrame
import numpy as np
spark_df = spark.table("catalog.schema.table") # or any other way to get a Spark DataFrame
eval_set_with_app_outputs_df = spark_df.toPandas()
Пример. Использование пользовательской функции для обработки ответов из LangGraph
Агенты LangGraph, особенно те, у которых есть функция чата, могут возвращать несколько сообщений за один вызов вывода. На пользователя возлагается ответственность по преобразованию ответа агента в формат, который поддерживает оценка агента.
Одним из способов является использование пользовательской функции для обработки ответа. В следующем примере показана пользовательская функция, извлекающая последнее сообщение чата из модели LangGraph. Затем эта функция используется в mlflow.evaluate() для возврата одного строкового ответа, который можно сравнить с столбцом ground_truth.
В примере кода приводятся следующие предположения:
- Модель принимает входные данные в формате {"messages": [{"role": "user", "content": "hello"}]}.
- Модель возвращает список строк в формате ["ответ 1", "ответ 2"].
Следующий код отправляет сцепленные ответы судье в этом формате: "ответ 1nresponse2"
import mlflow
import pandas as pd
from typing import List
loaded_model = mlflow.langchain.load_model(model_uri)
eval_data = pd.DataFrame(
{
"inputs": [
"What is MLflow?",
"What is Spark?",
],
"expected_response": [
"MLflow is an open-source platform for managing the end-to-end machine learning (ML) lifecycle. It was developed by Databricks, a company that specializes in big data and machine learning solutions. MLflow is designed to address the challenges that data scientists and machine learning engineers face when developing, training, and deploying machine learning models.",
"Apache Spark is an open-source, distributed computing system designed for big data processing and analytics. It was developed in response to limitations of the Hadoop MapReduce computing model, offering improvements in speed and ease of use. Spark provides libraries for various tasks such as data ingestion, processing, and analysis through its components like Spark SQL for structured data, Spark Streaming for real-time data processing, and MLlib for machine learning tasks",
],
}
)
def custom_langgraph_wrapper(model_input):
predictions = loaded_model.invoke({"messages": model_input["messages"]})
# Assuming `predictions` is a list of strings
return predictions.join("\n")
with mlflow.start_run() as run:
results = mlflow.evaluate(
custom_langgraph_wrapper, # Pass the function defined above
data=eval_data,
model_type="databricks-agent",
)
print(results.metrics)
Создание панели мониторинга с метриками
Когда вы работаете над улучшением качества вашего агента, возможно, вам захочется поделиться панелью инструментов с вашими заинтересованными сторонами, показывающей, как качество улучшалось с течением времени. Вы можете извлечь метрики из выполнения оценки MLflow, сохранить значения в таблице Delta и создать панель мониторинга.
В следующем примере показано, как извлечь и сохранить метрические значения из последнего оценочного запуска в вашем блокноте.
uc_catalog_name = "catalog"
uc_schema_name = "schema"
table_name = "results"
eval_results = mlflow.evaluate(
model=logged_agent_info.model_uri, # use the logged Agent
data=evaluation_set, # Run the logged Agent for all queries defined above
model_type="databricks-agent", # use Agent Evaluation
)
# The `append_metrics_to_table function` is defined below
append_metrics_to_table("<identifier-for-table>", eval_results.metrics, f"{uc_catalog_name}.{uc_schema_name}.{table_name}")
В следующем примере показано, как извлечь и сохранить значения метрик для прошлых запусков, сохраненных в эксперименте MLflow.
import pandas as pd
def get_mlflow_run(experiment_name, run_name):
runs = mlflow.search_runs(experiment_names=[experiment_name], filter_string=f"run_name = '{run_name}'", output_format="list")
if len(runs) != 1:
raise ValueError(f"Found {len(runs)} runs with name {run_name}. {run_name} must identify a single run. Alternatively, you can adjust this code to search for a run based on `run_id`")
return runs[0]
run = get_mlflow_run(experiment_name ="/Users/<user_name>/db_docs_mlflow_experiment", run_name="evaluation__2024-10-09_02:27:17_AM")
# The `append_metrics_to_table` function is defined below
append_metrics_to_table("<identifier-for-table>", run.data.metrics, f"{uc_catalog_name}.{uc_schema_name}.{table_name}")
Теперь вы можете создать панель мониторинга с помощью этих данных.
Следующий код определяет функцию append_metrics_to_table , используемую в предыдущих примерах.
# Definition of `append_metrics_to_table`
def append_metrics_to_table(run_name, mlflow_metrics, delta_table_name):
data = mlflow_metrics.copy()
# Add identifying run_name and timestamp
data["run_name"] = run_name
data["timestamp"] = pd.Timestamp.now()
# Remove metrics with error counts
data = {k: v for k, v in mlflow_metrics.items() if "error_count" not in k}
# Convert to a Spark DataFrame(
metrics_df = pd.DataFrame([data])
metrics_df_spark = spark.createDataFrame(metrics_df)
# Append to the Delta table
metrics_df_spark.write.mode("append").saveAsTable(delta_table_name)
Сведения о моделях, которые могут использовать судьи LLM
- Судьи LLM могут использовать сторонние службы для оценки приложений GenAI, включая Azure OpenAI, управляемых корпорацией Майкрософт.
- Для Azure OpenAI Databricks отказался от мониторинга злоупотреблений, поэтому запросы или ответы не хранятся в Azure OpenAI.
- Для рабочих пространств Европейского союза (ЕС) судьи LLM используют модели, хостированные в ЕС. Все остальные регионы используют модели, размещенные в США.
- Отключение вспомогательных функций ИИ на основе искусственного интеллекта Azure запрещает судье LLM вызывать модели, на основе ИИ Azure.
- Данные, отправленные судье LLM, не используются для обучения модели.
- Судьи LLM предназначены для того, чтобы помочь клиентам оценить свои приложения RAG, и выходные данные судьи LLM не должны использоваться для обучения, улучшения или точной настройки LLM.