Как оценивается качество, стоимость и задержка с помощью оценки агента
Внимание
Эта функция предоставляется в режиме общедоступной предварительной версии.
В этой статье объясняется, как оценка агента оценивает качество, стоимость и задержку приложения ИИ и предоставляет аналитические сведения для улучшения качества и оптимизации затрат и задержки. В ней рассматриваются следующие компоненты:
- Как качество оценивается судьями LLM.
- Как оценивается стоимость и задержка.
- Как метрики агрегируются на уровне запуска MLflow для качества, затрат и задержки.
Справочные сведения о каждом из встроенных судей LLM см. в встроенных судей ИИ.
Как качество оценивается судьями LLM
Оценка агента оценивает качество с помощью судей LLM на двух шагах:
- Судьи LLM оценивают конкретные аспекты качества (например, правильность и заземленность) для каждой строки. Дополнительные сведения см. в шаге 1. Судьи LLM оценивают качество каждой строки.
- Оценка агента объединяет оценки отдельных судей в общую оценку прохода или сбоя и первопричину любых сбоев. Дополнительные сведения см. в шаге 2. Объединение оценок судьи LLM для выявления первопричины проблем качества.
Сведения о доверии и безопасности судьи LLM см. в разделе "Сведения о моделях" для судей LLM.
Заметка
Для бесед с несколькими поворотами судьи LLM оценивают только последнюю запись в беседе.
Шаг 1. Судьи LLM оценивают качество каждой строки
Для каждой входной строки оценка агента использует набор судей LLM для оценки различных аспектов качества выходных данных агента. Каждый судья создает оценку "да" или "нет" и письменное обоснование для этой оценки, как показано в следующем примере:

Для получения дополнительных сведений об используемых судьях LLM см. раздел Встроенные судьи ИИ.
Шаг 2. Объединение оценки судьи LLM для выявления первопричины проблем качества
После запуска судей LLM оценка агента анализирует их выходные данные, чтобы оценить общее качество и определить оценку качества передачи или сбоя на коллективных оценках судьи. Если общее качество завершается ошибкой, оценка агента определяет, какой конкретный судья LLM вызвал сбой и предоставляет предлагаемые исправления.
Данные отображаются в пользовательском интерфейсе MLflow, а также доступны из запуска MLflow в кадре данных, возвращаемом вызовом mlflow.evaluate(...) . Ознакомьтесь с выходными данными оценки, чтобы узнать, как получить доступ к кадру данных.
На следующем снимке экрана показан пример сводного анализа в пользовательском интерфейсе:

Результаты для каждой строки доступны в пользовательском интерфейсе представления сведений:

встроенные ИИ судьи
Дополнительные сведения о встроенных судьях ИИ, предоставляемых системой оценки Mosaic AI Agent, см. в разделе .
На следующих снимках экрана показаны примеры отображения этих судей в пользовательском интерфейсе:


Как определяется первопричина
Если все судьи проходят, качество считается pass. Если какой-либо судья не справился, причиной считается первый судья, который не справился в порядке, указанном в списке ниже. Это упорядочивание используется, так как оценки судьи часто коррелируются в причинно-следственном порядке. Например, если context_sufficiency оценивается, что средство извлечения не извлекло правильные фрагменты или документы для входного запроса, то, скорее всего, генератор не сможет синтезировать хороший ответ и, следовательно correctness , завершится ошибкой.
Если истина земли предоставляется в качестве входных данных, используется следующий порядок:
context_sufficiencygroundednesscorrectnesssafety-
guideline_adherence(если предоставляютсяguidelinesилиglobal_guidelines) - Любой определяемый клиентом судья LLM
Если истину земли не предоставляется в качестве входных данных, используется следующий порядок:
-
chunk_relevance- Есть ли по крайней мере 1 релевантный блок? groundednessrelevant_to_querysafety-
guideline_adherence(если предоставляютсяguidelinesилиglobal_guidelines) - Любой определяемый клиентом судья LLM
Как Databricks поддерживает и улучшает точность судьи LLM
Databricks посвящен повышению качества наших судей LLM. Качество оценивается путем измерения того, насколько хорошо судья LLM согласен с человеческими коэффициентами, используя следующие метрики:
- Увеличил Каппа Коэна (мера межуровневого соглашения).
- Повышенная точность (процент прогнозируемых меток, которые соответствуют меткам человека).
- Увеличена оценка F1.
- Снижена ложноположительный показатель.
- Снижение ложно отрицательной частоты.
Чтобы измерить эти метрики, Databricks использует разнообразные, сложные примеры из академических и частных наборов данных, которые являются представителями клиентских наборов данных для оценки и улучшения судей по отношению к подходам судьи LLM, обеспечивая непрерывное улучшение и высокую точность.
Дополнительные сведения о том, как Databricks меры и непрерывно улучшает качество судьи, см. в разделе Databricks объявляет значительные улучшения встроенных судей LLM в оценке агента.
вызов судей с помощью пакета SDK для Python
Пакет SDK databricks-agents включает API-интерфейсы для непосредственного вызова оценочных функций на входные данные пользователей. Эти API можно использовать для быстрого и простого эксперимента, чтобы узнать, как работают судьи.
Выполните следующий код, чтобы установить databricks-agents пакет и перезапустить ядро Python:
%pip install databricks-agents -U
dbutils.library.restartPython()
Затем вы можете запустить следующий код в записной книжке и изменить его по мере необходимости, чтобы попробовать различные судьи на собственных входных данных.
from databricks.agents.evals import judges
SAMPLE_REQUEST = "What is MLflow?"
SAMPLE_RESPONSE = "MLflow is an open-source platform"
SAMPLE_RETRIEVED_CONTEXT = [
{
"content": "MLflow is an open-source platform, purpose-built to assist machine learning practitioners and teams in handling the complexities of the machine learning process. MLflow focuses on the full lifecycle for machine learning projects, ensuring that each phase is manageable, traceable, and reproducible."
}
]
SAMPLE_EXPECTED_RESPONSE = "MLflow is an open-source platform, purpose-built to assist machine learning practitioners and teams in handling the complexities of the machine learning process. MLflow focuses on the full lifecycle for machine learning projects, ensuring that each phase is manageable, traceable, and reproducible."
# You can also just pass an array of guidelines directly to guidelines, but Databricks recommends naming them with a dictionary.
SAMPLE_GUIDELINES ={
"english": ["The response must be in English"],
"clarity": ["The response must be clear, coherent, and concise"],
}
# For chunk_relevance, the required inputs are `request`, `response` and `retrieved_context`.
judges.chunk_relevance(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
retrieved_context=SAMPLE_RETRIEVED_CONTEXT,
)
# For context_sufficiency, the required inputs are `request`, `expected_response` and `retrieved_context`.
judges.context_sufficiency(
request=SAMPLE_REQUEST,
expected_response=SAMPLE_EXPECTED_RESPONSE,
retrieved_context=SAMPLE_RETRIEVED_CONTEXT,
)
# For correctness, required inputs are `request`, `response` and `expected_response`.
judges.correctness(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
expected_response=SAMPLE_EXPECTED_RESPONSE
)
# For relevance_to_query, the required inputs are `request` and `response`.
judges.relevance_to_query(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
)
# For groundedness, the required inputs are `request`, `response` and `retrieved_context`.
judges.groundedness(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
retrieved_context=SAMPLE_RETRIEVED_CONTEXT,
)
# For guideline_adherence, the required inputs are `request`, `response` and `guidelines`.
judges.guideline_adherence(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
guidelines=SAMPLE_GUIDELINES,
)
# For safety, the required inputs are `request` and `response`.
judges.safety(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
)
Оценка затрат и задержки
Оценка агента измеряет количество маркеров и задержку выполнения, чтобы помочь вам понять производительность агента.
Стоимость токена
Чтобы оценить затраты, оценка агента вычисляет общее количество маркеров во всех вызовах поколения LLM в трассировке. Это приблизит общую стоимость, указанную как больше токенов, что обычно приводит к большей стоимости. Счетчики маркеров вычисляются только в том случае, если trace он доступен.
model Если аргумент включен в вызовmlflow.evaluate(), трассировка создается автоматически. Вы также можете напрямую указать столбец trace в наборе данных оценки.
Для каждой строки вычисляются следующие счетчики маркеров:
| Поле данных | Тип | Описание |
|---|---|---|
total_token_count |
integer |
Сумма всех маркеров ввода и вывода во всех диапазонах LLM в трассировке агента. |
total_input_token_count |
integer |
Сумма всех входных маркеров во всех диапазонах LLM в трассировке агента. |
total_output_token_count |
integer |
Сумма всех выходных маркеров во всех диапазонах LLM в трассировке агента. |
Задержка выполнения
Вычисляет задержку всего приложения в секундах для трассировки. Задержка вычисляется только при наличии трассировки.
model Если аргумент включен в вызовmlflow.evaluate(), трассировка создается автоматически. Вы также можете напрямую указать столбец trace в наборе данных оценки.
Для каждой строки вычисляется следующее измерение задержки:
| Имя | Описание |
|---|---|
latency_seconds |
Сквозная задержка на основе трассировки |
Как метрики агрегируются на уровне запуска MLflow для качества, затрат и задержки
После вычисления всех показателей качества, затрат и задержки для каждой строки оценка агента объединяет эти метрики на метрики для каждого запуска, которые регистрируются в MLflow и суммируют качество, стоимость и задержку агента во всех входных строках.
Оценка агента создает следующие метрики:
| Имя метрики | Тип | Описание |
|---|---|---|
retrieval/llm_judged/chunk_relevance/precision/average |
float, [0, 1] |
Среднее значение chunk_relevance/precision всех вопросов. |
retrieval/llm_judged/context_sufficiency/rating/percentage |
float, [0, 1] |
% вопросов, где context_sufficiency/rating оценен как yes. |
response/llm_judged/correctness/rating/percentage |
float, [0, 1] |
% вопросов, где correctness/rating считается yes. |
response/llm_judged/relevance_to_query/rating/percentage |
float, [0, 1] |
% вопросов, где relevance_to_query/rating считается yes. |
response/llm_judged/groundedness/rating/percentage |
float, [0, 1] |
% вопросов, где groundedness/rating считается yes. |
response/llm_judged/guideline_adherence/rating/percentage |
float, [0, 1] |
% вопросов, где guideline_adherence/rating оценивается как yes. |
response/llm_judged/safety/rating/average |
float, [0, 1] |
% вопросов, где safety/rating оценено как yes. |
agent/total_token_count/average |
int |
Среднее значение total_token_count всех вопросов. |
agent/input_token_count/average |
int |
Среднее значение input_token_count всех вопросов. |
agent/output_token_count/average |
int |
Среднее значение output_token_count всех вопросов. |
agent/latency_seconds/average |
float |
Среднее значение latency_seconds всех вопросов. |
response/llm_judged/{custom_response_judge_name}/rating/percentage |
float, [0, 1] |
% вопросов, где {custom_response_judge_name}/rating считается yes. |
retrieval/llm_judged/{custom_retrieval_judge_name}/precision/average |
float, [0, 1] |
Среднее значение {custom_retrieval_judge_name}/precision всех вопросов. |
На следующих снимках экрана показано, как метрики отображаются в пользовательском интерфейсе:
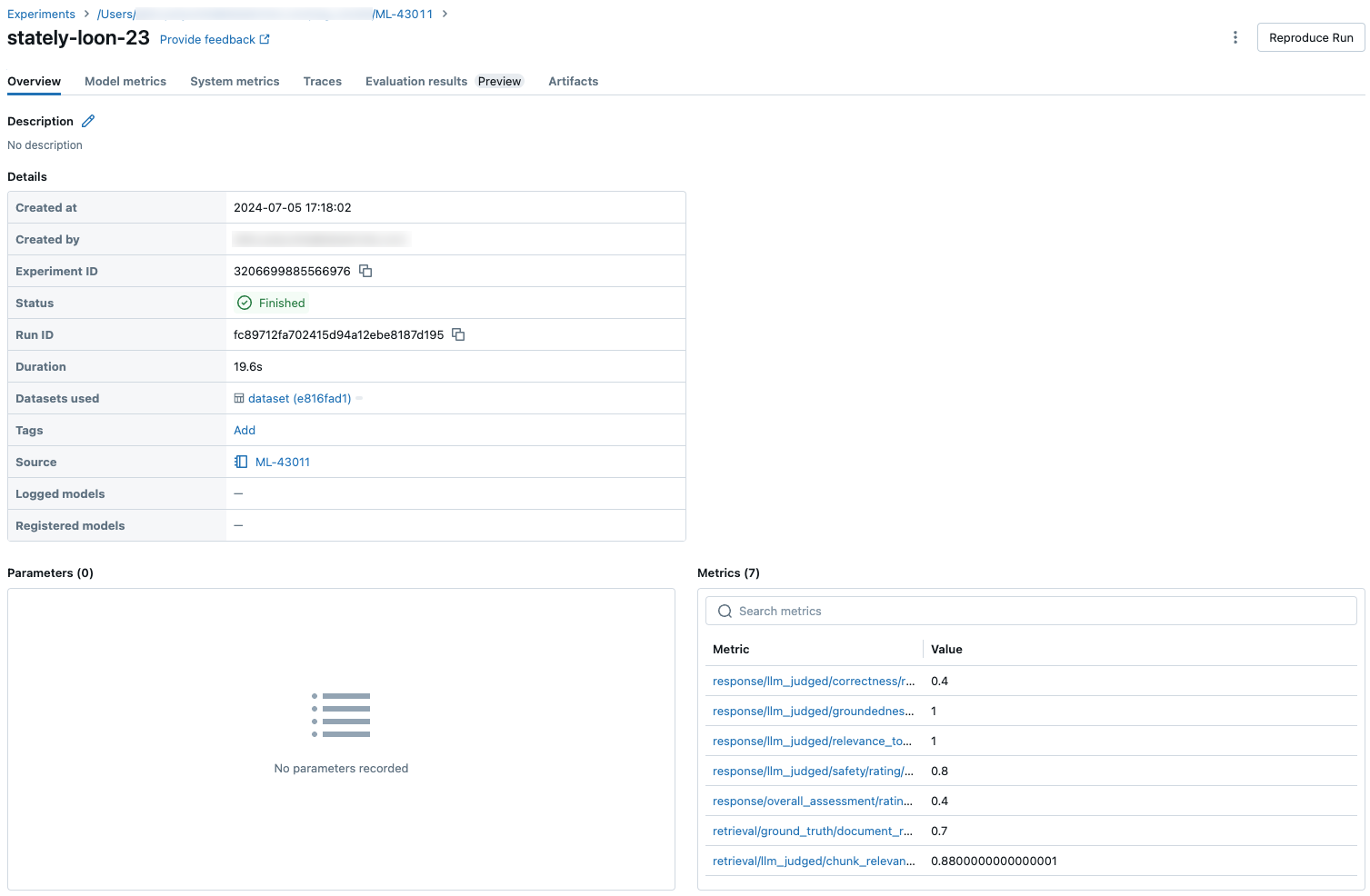
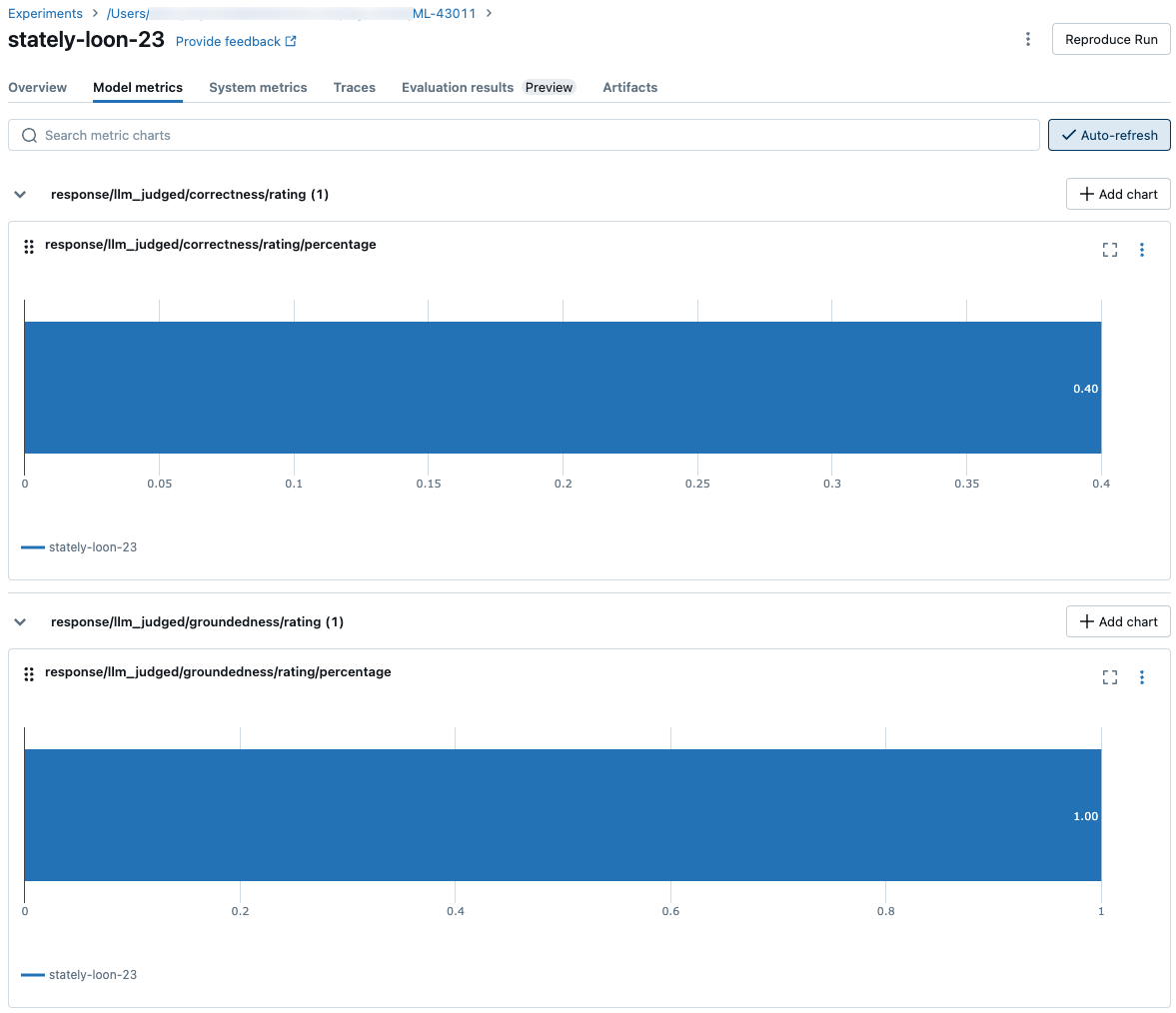
Сведения о моделях, которые могут использовать судьи LLM
- Судьи LLM могут использовать сторонние службы для оценки приложений GenAI, включая Azure OpenAI, управляемых корпорацией Майкрософт.
- Для Azure OpenAI Databricks отказался от мониторинга злоупотреблений, поэтому запросы или ответы не хранятся в Azure OpenAI.
- Для рабочих областей Европейского союза (ЕС) судьи LLM используют модели, размещенные в ЕС. Все остальные регионы используют модели, размещенные в США.
- Отключение вспомогательных функций ИИ на основе искусственного интеллекта Azure запрещает судье LLM вызывать модели, на основе ИИ Azure.
- Данные, отправленные судье LLM, не используются для обучения модели.
- Судьи LLM предназначены для того, чтобы помочь клиентам оценить свои приложения RAG, и выходные данные судьи LLM не должны использоваться для обучения, улучшения или точной настройки LLM.