Обеспечение наблюдаемости агента посредством отслеживания в MLflow
В этой статье описывается, как добавить наблюдаемость для генеративных приложений ИИ с помощью трассировки MLflow в Databricks.
Что такое трассировка MLflow?
MLflow Tracing обеспечивает сквозное наблюдение за генеративными приложениями ИИ от разработки до развертывания. Трассировка полностью интегрирована с инструментарием генеративного ИИ от Databricks, предоставляя подробные аналитические сведения на всех этапах жизненного цикла разработки и производства.
Ниже приведены ключевые варианты использования трассировки в приложениях ИИ поколения.
Упрощенная отладка: трассировка обеспечивает видимость каждого шага вашего приложения генеративного ИИ, что упрощает диагностику и устранение проблем.
офлайн-оценка: Трассировка генерирует ценные данные для оценки агента, позволяя измерять и улучшать качество агента с течением времени.
Производственный мониторинг: Трассировка обеспечивает видимость поведения агента и подробные шаги его выполнения, что позволяет контролировать и оптимизировать производительность агента в производственной среде.
журналы аудита: трассировка MLflow создает комплексные журналы аудита действий и решений агента. Это жизненно важно для обеспечения соответствия требованиям и поддержки отладки при возникновении непредвиденных проблем.
Требования
Отслеживание MLflow доступно в MLflow версии 2.13.0 и выше. Databricks рекомендует установить последнюю версию MLflow для доступа к новейшим функциям и улучшениям.
%pip install mlflow>=2.13.0 -qqqU
%restart_python
автоматическая трассировка
автоматический журнал MLflow позволяет быстро инструментировать агент, добавив одну строку в код, mlflow.<library>.autolog().
MLflow поддерживает автологирование для наиболее популярных библиотек разработки агентов. Дополнительные сведения о каждой библиотеке разработки см. в документации по автологированию MLflow:
| Библиотека | Поддержка версий автологирования | Команда автологирования |
|---|---|---|
| LangChain | 0.1.0 ~ Последняя версия | mlflow.langchain.autolog() |
| Langgraph | 0.1.1 ~ Последняя версия | mlflow.langgraph.autolog() |
| OpenAI | 1.0.0 ~ Последняя версия | mlflow.openai.autolog() |
| LlamaIndex | 0.10.44 ~ Последняя версия | mlflow.llamaindex.autolog() |
| DSPy | 2.5.17 ~ Последняя версия | mlflow.dspy.autolog() |
| Amazon Bedrock | 1.33.0 ~ Latest (boto3) | mlflow.bedrock.autolog() |
| Антропик | 0.30.0 ~ Последняя версия | mlflow.anthropic.autolog() |
| AutoGen | 0.2.36 ~ 0.2.40 | mlflow.autogen.autolog() |
| Гугл Джемини | 1.0.0 ~ Последняя версия | mlflow.gemini.autolog() |
| CrewAI | 0.80.0 ~ Последняя версия | mlflow.crewai.autolog() |
| LiteLLM | 1.52.9 ~ Последняя версия | mlflow.litellm.autolog() |
| Groq | 0.13.0 ~ Последняя версия | mlflow.groq.autolog() |
| Мистраль | 1.0.0 ~ Последняя версия | mlflow.mistral.autolog() |
Отключение автоматической записи
Трассировка автологирования включена по умолчанию в Databricks Runtime 15.4 ML и выше для следующих библиотек:
- LangChain
- Langgraph
- OpenAI
- LlamaIndex
Чтобы отключить трассировку автологирования для этих библиотек, выполните следующую команду в записной книжке:
`mlflow.<library>.autolog(log_traces=False)`
Добавление трассировок вручную
В то время как автологирование обеспечивает удобный способ инструментирования агентов, может потребоваться инструментировать агент более детально или добавить дополнительные трассировки, которые автологирование не фиксирует. В этих случаях используйте API трассировки MLflow для добавления трассировок вручную.
API трассировки в MLflow — это API-интерфейсы с минимальным кодированием для добавления трассировок без необходимости управления древовидной структурой трассировки. MLflow определяет соответствующие связи между родительскими и дочерними элементами автоматически с помощью стека Python.
Объедините автоматическое логирование и ручную трассировку
Интерфейсы отслеживания вручную можно использовать с автологированием. MLflow объединяет диапазоны, созданные с помощью автологирования и ручной трассировки, чтобы создать полную трассировку выполнения агента. Пример объединения автоматического ведения журнала и ручной трассировки см. в Пример использования агента вызова инструментов с трассировкой MLflow.
Функции трассировки с помощью декоратора @mlflow.trace
Самый простой способ вручную инструментировать код — декорировать функцию с помощью декоратора @mlflow.trace.
декоратор трассировки MLflow создает "диапазон" с областью украшенной функции, которая представляет единицу выполнения в трассировке и отображается в виде одной строки в визуализации трассировки. Диапазон записывает входные и выходные данные функции, задержки и все исключения, вызванные функцией.
Например, следующий код создает диапазон с именем my_function, который записывает входные аргументы x и y и выходные данные.
import mlflow
@mlflow.trace
def add(x: int, y: int) -> int:
return x + y
Кроме того, можно настроить имя диапазона, тип диапазона и добавить настраиваемые атрибуты в диапазон:
from mlflow.entities import SpanType
@mlflow.trace(
# By default, the function name is used as the span name. You can override it with the `name` parameter.
name="my_add_function",
# Specify the span type using the `span_type` parameter.
span_type=SpanType.TOOL,
# Add custom attributes to the span using the `attributes` parameter. By default, MLflow only captures input and output.
attributes={"key": "value"}
)
def add(x: int, y: int) -> int:
return x + y
Трассировка произвольных блоков кода с помощью диспетчера контекстов
Чтобы создать диапазон для произвольного блока кода, а не только функции, используйте mlflow.start_span() в качестве диспетчера контекстов, который упаковывает блок кода. Диапазон начинается при вводе контекста и заканчивается при выходе контекста. Входные и выходные параметры диапазона должны быть предоставлены вручную с помощью методов установки объекта диапазона, предоставленного контекстным менеджером. Дополнительные сведения см. в документации по MLflow — обработчик контекста.
with mlflow.start_span(name="my_span") as span:
span.set_inputs({"x": x, "y": y})
result = x + y
span.set_outputs(result)
span.set_attribute("key", "value")
Библиотеки трассировки нижнего уровня
MLflow также предоставляет низкоуровневые API для явного управления структурой дерева трассировки. См. документацию по MLflow —ручная инструментализация.
Пример трассировки : сочетание автоматического логирования и ручной трассировки.
В следующем примере объединяются автоматическая запись OpenAI и ручное отслеживание для полного оснащения инструментами агента, вызов которого осуществляется с помощью инструментов.
import json
from openai import OpenAI
import mlflow
from mlflow.entities import SpanType
client = OpenAI()
# Enable OpenAI autologging to capture LLM API calls
# (*Not necessary if you are using the Databricks Runtime 15.4 ML and above, where OpenAI autologging is enabled by default)
mlflow.openai.autolog()
# Define the tool function. Decorate it with `@mlflow.trace` to create a span for its execution.
@mlflow.trace(span_type=SpanType.TOOL)
def get_weather(city: str) -> str:
if city == "Tokyo":
return "sunny"
elif city == "Paris":
return "rainy"
return "unknown"
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"parameters": {
"type": "object",
"properties": {"city": {"type": "string"}},
},
},
}
]
_tool_functions = {"get_weather": get_weather}
# Define a simple tool-calling agent
@mlflow.trace(span_type=SpanType.AGENT)
def run_tool_agent(question: str):
messages = [{"role": "user", "content": question}]
# Invoke the model with the given question and available tools
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=messages,
tools=tools,
)
ai_msg = response.choices[0].message
messages.append(ai_msg)
# If the model requests tool calls, invoke the function(s) with the specified arguments
if tool_calls := ai_msg.tool_calls:
for tool_call in tool_calls:
function_name = tool_call.function.name
if tool_func := _tool_functions.get(function_name):
args = json.loads(tool_call.function.arguments)
tool_result = tool_func(**args)
else:
raise RuntimeError("An invalid tool is returned from the assistant!")
messages.append(
{
"role": "tool",
"tool_call_id": tool_call.id,
"content": tool_result,
}
)
# Send the tool results to the model and get a new response
response = client.chat.completions.create(
model="gpt-4o-mini", messages=messages
)
return response.choices[0].message.content
# Run the tool calling agent
question = "What's the weather like in Paris today?"
answer = run_tool_agent(question)
Аннотирование трассировок с использованием тегов
теги трассировки MLflow являются парами "ключ-значение", которые позволяют добавлять пользовательские метаданные в трассировки, такие как идентификатор беседы, идентификатор пользователя, хэш фиксации Git и т. д. Теги отображаются в пользовательском интерфейсе MLflow для фильтрации и поиска трассировок.
Теги можно задать для текущей или завершенной трассировки с помощью API MLflow или пользовательского интерфейса MLflow. В следующем примере показано добавление тега в текущую трассировку с помощью API mlflow.update_current_trace().
@mlflow.trace
def my_func(x):
mlflow.update_current_trace(tags={"fruit": "apple"})
return x + 1
Дополнительные сведения о тегах трассировки и их использовании для фильтрации и поиска см. в документации по MLflow . Настройка тегов трассировки.
Рассмотрение трассировок
Чтобы просмотреть следы после запуска агента, используйте один из следующих вариантов:
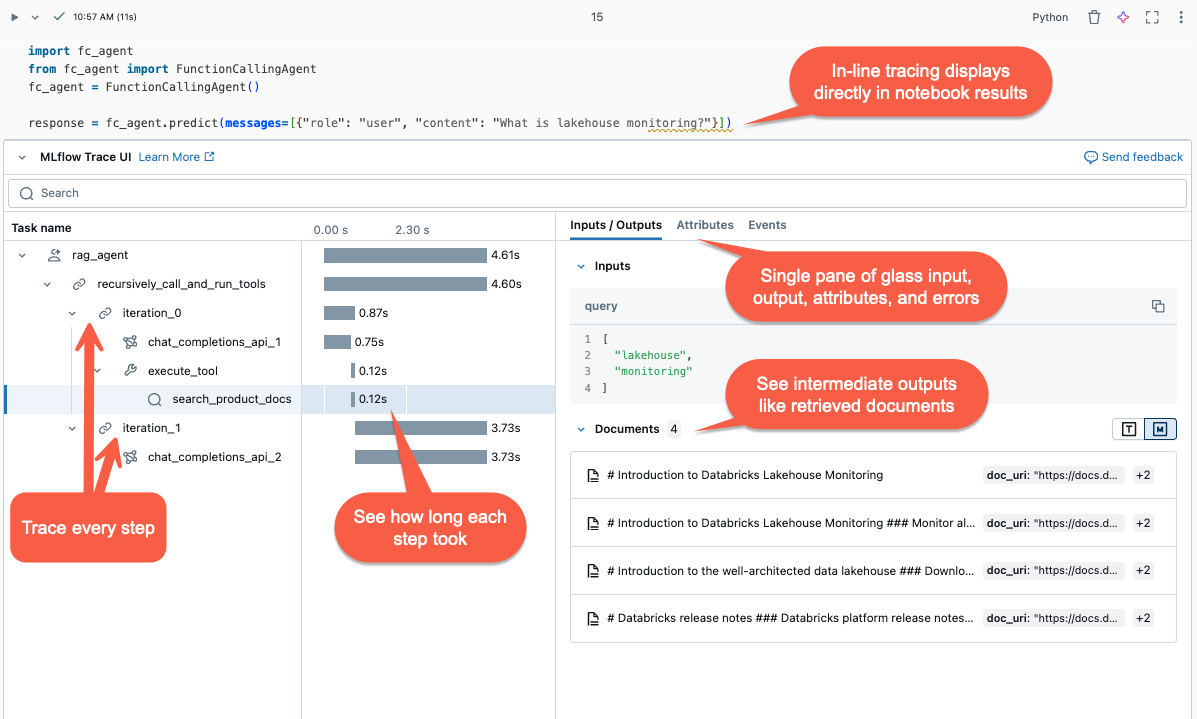
- визуализация в строке. В записных книжках Databricks трассировки отображаются в выходных данных ячейки.
- эксперимент MLflow: в Databricks перейдите к Эксперименты>, выберите эксперимент >итрассировки для просмотра и поиска по всем трассировкам этого эксперимента.
- запуск MLflow: когда агент запускается в рамках активного сеанса MLflow, трассировки (traces) отображаются на странице сеанса пользовательского интерфейса MLflow.
- интерфейса оценивания агента. В Mosaic AI оценке агента, вы можете просмотреть трассировки для каждого выполнения агента, нажав на Просмотреть подробную трассировку в результате оценки.
- API поиска трассировки: для программного извлечения трассировок используйте API поискатрассировки.
Оценка агентов с помощью трассировок
Данные трассировки служат ценным ресурсом для оценки агентов. Записывая подробные сведения о выполнении моделей, трассировка MLflow играет важную роль в офлайн оценке. Данные трассировки можно использовать для оценки производительности вашего агента в сравнении с эталонным набором данных, выявления проблем и повышения его производительности.
%pip install -U mlflow databricks-agents
%restart_python
import mlflow
# Get the recent 50 successful traces from the experiment
traces = mlflow.search_traces(
max_results=50,
filter_string="status = 'OK'",
)
traces.drop_duplicates("request", inplace=True) # Drop duplicate requests.
traces["trace"] = traces["trace"].apply(lambda x: x.to_json()) # Convert the trace to JSON format.
# Evaluate the agent with the trace data
mlflow.evaluate(data=traces, model_type="databricks-agent")
Дополнительные сведения об оценке агента см. в статье Запуск оценки и просмотр результатов.
Мониторинг развернутых агентов с таблицами вывода данных
После развертывания агента на платформе Mosaic AI для предоставления моделей, можно использовать таблицы вывода данных для мониторинга агента. Таблицы вывода содержат подробные журналы запросов, ответов, трассировок агента и обратную связь агента из приложения для проверки. Эта информация позволяет отлаживать проблемы, отслеживать производительность и создавать золотой набор данных для автономной оценки.
Сведения о включении таблиц вывода для развертываний агентов см. в разделе Включение таблиц вывода для агентов ИИ.
Запрос сетевых трассировок
Используйте записную книжку для запроса таблицы вывода и анализа результатов.
Чтобы визуализировать трассировки, выполните display(<the request logs table>) и выберите строки для проверки:
# Query the inference table
df = spark.sql("SELECT * FROM <catalog.schema.my-inference-table-name>")
display(df)
Мониторинг агентов
См. Как отслеживать приложения генеративного ИИ.
** Задержка из-за накладных издержек трассировки
Трассировки записываются асинхронно, чтобы свести к минимуму влияние на производительность. Однако трассировка по-прежнему добавляет задержку к скорости отклика конечной точки, особенно если размер трассировки для каждого запроса вывода велик. Databricks рекомендует протестировать конечную точку, чтобы понять влияние задержки трассировки перед развертыванием в рабочей среде.
В следующей таблице приведены приблизительные оценки влияния задержки на размер трассировки:
| Размер трассы на запрос | Влияние на задержку скорости отклика (мс) |
|---|---|
| ~10 КБ | ~ 1 мс |
| ~ 1 МБ | 50 ~ 100 мс |
| 10 МБ | 150 мс ~ |
Устранение неполадок
Сведения об устранении неполадок и распространенных проблемах см. в документации по MLflow: руководство по трассировке и документации по MLflow: вопросы и ответы