Executar uma avaliação e visualizar os resultados
Importante
Esta funcionalidade está em Pré-visualização Pública.
Este artigo descreve como executar uma avaliação e visualizar os resultados à medida que desenvolve a sua aplicação de IA. Para obter informações sobre como monitorar a qualidade dos agentes implantados no tráfego de produção, consulte Como monitorar a qualidade do agente no tráfego de produção.
Para avaliar um agente, você deve especificar um conjunto de avaliação. No mínimo, um conjunto de avaliação é um conjunto de solicitações para a sua aplicação que pode vir de um conjunto curado de solicitações de avaliação ou registos de utilizadores do agente. Para obter mais detalhes, consulte Conjuntos de Avaliação e Avaliação do Agente esquema de entrada.
Executar uma avaliação
Para executar uma avaliação, use o método mlflow.evaluate() da API MLflow, especificando o model_type como databricks-agent para habilitar a Avaliação do Agente no Databricks e juízes de IA internos.
O exemplo a seguir especifica um conjunto de diretrizes de resposta global para as diretrizes globais de julgamento de IA que fazem com que a avaliação falhe quando as respostas não aderem às diretrizes. Você não precisa coletar rótulos por solicitação para avaliar seu agente com essa abordagem.
import mlflow
from mlflow.deployments import get_deploy_client
# The guidelines below will be used to evaluate any response of the agent.
global_guidelines = [
"If the request is unrelated to Databricks, the response must should be a rejection of the request",
"If the request is related to Databricks, the response must should be concise",
"If the request is related to Databricks and question about API, the response must have code",
"The response must be professional."
]
eval_set = [{
"request": {"messages": [{"role": "user", "content": "What is the difference between reduceByKey and groupByKey in Databricks Spark?"}]}
}, {
"request": "What is the weather today?",
}]
# Define a very simple system-prompt agent.
@mlflow.trace(span_type="AGENT")
def llama3_agent(messages):
SYSTEM_PROMPT = """
You are a chatbot that answers questions about Databricks.
For requests unrelated to Databricks, reject the request.
"""
return get_deploy_client("databricks").predict(
endpoint="databricks-meta-llama-3-3-70b-instruct",
inputs={"messages": [{"role": "system", "content": SYSTEM_PROMPT}, *messages]}
)
# Evaluate the Agent with the evaluation set and log it to the MLFlow run "system_prompt_v0".
with mlflow.start_run(run_name="system_prompt_v0") as run:
mlflow.evaluate(
data=eval_set,
model=lambda request: llama3_agent(**request),
model_type="databricks-agent",
evaluator_config={
"databricks-agent": {
"global_guidelines": global_guidelines
}
}
)
Este exemplo executa os seguintes juízes que não precisam de rótulos de verdade-base: Adesão à diretriz, Relevância para pesquisa, Segurança.
Se você usar um agente com um retriever, os seguintes juízes serão executados: Groundedness, Chunk relevance
mlflow.evaluate() também calcula métricas de latência e custo para cada registro de avaliação, agregando resultados em todas as entradas para uma determinada execução. Estes são designados por resultados da avaliação. Os resultados da avaliação são registrados na execução anexa, juntamente com as informações registradas por outros comandos, como parâmetros do modelo. Se você chamar mlflow.evaluate() fora de uma execução MLflow, uma nova execução será criada.
Avalie com rótulos de verdade-base
O exemplo a seguir especifica rótulos de referência por linha:
%pip install databricks-agents
dbutils.library.restartPython()
import mlflow
from mlflow.types.llm import ChatCompletionResponse, ChatCompletionRequest
from mlflow.deployments import get_deploy_client
import dataclasses
eval_set = [{
"request": "What is the difference between reduceByKey and groupByKey in Databricks Spark?",
"expected_facts": [
"reduceByKey aggregates data before shuffling",
"groupByKey shuffles all data",
],
"guidelines": ["The response must be concice and show a code snippet."]
}, {
"request": "What is the weather today?",
"guidelines": ["The response must reject the request."]
}]
# Define a very simple system-prompt agent.
@mlflow.trace(span_type="AGENT")
def llama3_agent(messages):
SYSTEM_PROMPT = """
You are a chatbot that answers questions about Databricks.
For requests unrelated to Databricks, reject the request.
"""
return get_deploy_client("databricks").predict(
endpoint="databricks-meta-llama-3-3-70b-instruct",
inputs={"messages": [{"role": "system", "content": SYSTEM_PROMPT}, *messages]}
)
# Evaluate the agent with the evaluation set and log it to the MLFlow run "system_prompt_v0".
with mlflow.start_run(run_name="system_prompt_v0") as run:
mlflow.evaluate(
data=eval_set,
model=lambda request: llama3_agent(**request),
model_type="databricks-agent"
)
Este exemplo executa os mesmos juízes mencionados acima, além do seguinte: Correção, Relevância, Segurança
Se você usar um agente com retriever, o seguinte juiz será executado: Suficiência de contexto
Requisitos
Os recursos de assistência de IA alimentados por IA do Azure devem ser habilitados para seu espaço de trabalho.
Fornecer entradas para um processo de avaliação
Há duas maneiras de fornecer informações para uma execução de avaliação:
Fornecer resultados gerados anteriormente para comparar com o conjunto de avaliação. Essa opção é recomendada se você quiser avaliar as saídas de um aplicativo que já está implantado na produção ou se quiser comparar os resultados da avaliação entre as configurações de avaliação.
Com essa opção, você especifica um conjunto de avaliação conforme mostrado no código a seguir. O conjunto de avaliação deve incluir resultados previamente gerados. Para obter exemplos mais detalhados, consulte Exemplo: Como passar saídas geradas anteriormente para a Avaliação do agente.
evaluation_results = mlflow.evaluate( data=eval_set_with_chain_outputs_df, # pandas DataFrame with the evaluation set and application outputs model_type="databricks-agent", )Passe o aplicativo como um argumento de entrada.
mlflow.evaluate()chama a aplicação para cada entrada no conjunto de avaliação e reporta avaliações de qualidade e outras métricas para cada saída gerada. Essa opção é recomendada se seu aplicativo foi registrado usando MLflow com MLflow Tracing habilitado ou se seu aplicativo é implementado como uma função Python em um bloco de anotações. Esta opção não é recomendada se o seu aplicativo foi desenvolvido fora do Databricks ou é implantado fora do Databricks.Com essa opção, você especifica o conjunto de avaliação e o aplicativo na chamada de função, conforme mostrado no código a seguir. Para obter exemplos mais detalhados, consulte Exemplo: Como passar um aplicativo para a Avaliação do Agente.
evaluation_results = mlflow.evaluate( data=eval_set_df, # pandas DataFrame containing just the evaluation set model=model, # Reference to the MLflow model that represents the application model_type="databricks-agent", )
Para obter detalhes sobre o esquema do conjunto de avaliação, consulte esquema de entrada de avaliação do agente.
Resultados da avaliação
A Avaliação do Agente retorna suas saídas como mlflow.evaluate() dataframes e também registra essas saídas na execução do MLflow. Você pode inspecionar as saídas no bloco de anotações ou na página da execução MLflow correspondente.
Rever a saída no bloco de notas
O código a seguir mostra alguns exemplos de como revisar os resultados de uma avaliação executada a partir do seu bloco de anotações.
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
###
# Run evaluation
###
evaluation_results = mlflow.evaluate(..., model_type="databricks-agent")
###
# Access aggregated evaluation results across the entire evaluation set
###
results_as_dict = evaluation_results.metrics
results_as_pd_df = pd.DataFrame([evaluation_results.metrics])
# Sample usage
print(f"The percentage of generated responses that are grounded: {results_as_dict['response/llm_judged/groundedness/percentage']}")
###
# Access data about each question in the evaluation set
###
per_question_results_df = evaluation_results.tables['eval_results']
# Show information about responses that are not grounded
per_question_results_df[per_question_results_df["response/llm_judged/groundedness/rating"] == "no"].display()
O dataframe per_question_results_df inclui todas as colunas no esquema de entrada e todos os resultados da avaliação específicos para cada solicitação. Para obter mais detalhes sobre os resultados calculados, consulte Como a qualidade, o custo e a latência são avaliados pela Avaliação do Agente.
Revisar a saída usando a interface do usuário MLflow
Os resultados da avaliação também estão disponíveis na interface do usuário MLflow. Para acessar a interface do usuário MLflow, clique no ícone ![]() Experimentar na barra lateral direita do bloco de anotações e, em seguida, na execução correspondente, ou clique nos links que aparecem nos resultados da célula do bloco de anotações na qual você executou
Experimentar na barra lateral direita do bloco de anotações e, em seguida, na execução correspondente, ou clique nos links que aparecem nos resultados da célula do bloco de anotações na qual você executou mlflow.evaluate().
Rever os resultados da avaliação para uma única execução
Esta seção descreve como revisar os resultados da avaliação para uma corrida individual. Para comparar resultados entre execuções, consulte Comparar resultados de avaliação entre execuções.
Visão geral das avaliações de qualidade por juízes de LLM
As avaliações por juiz a pedido estão disponíveis na databricks-agents versão 0.3.0 e superior.
Para ver uma visão geral da qualidade julgada pelo LLM de cada solicitação no conjunto de avaliações, clique na guia Resultados da avaliação na página MLflow Run. Esta página mostra uma tabela de resumo de cada execução de avaliação. Para obter mais detalhes, clique no ID de avaliação de uma execução.
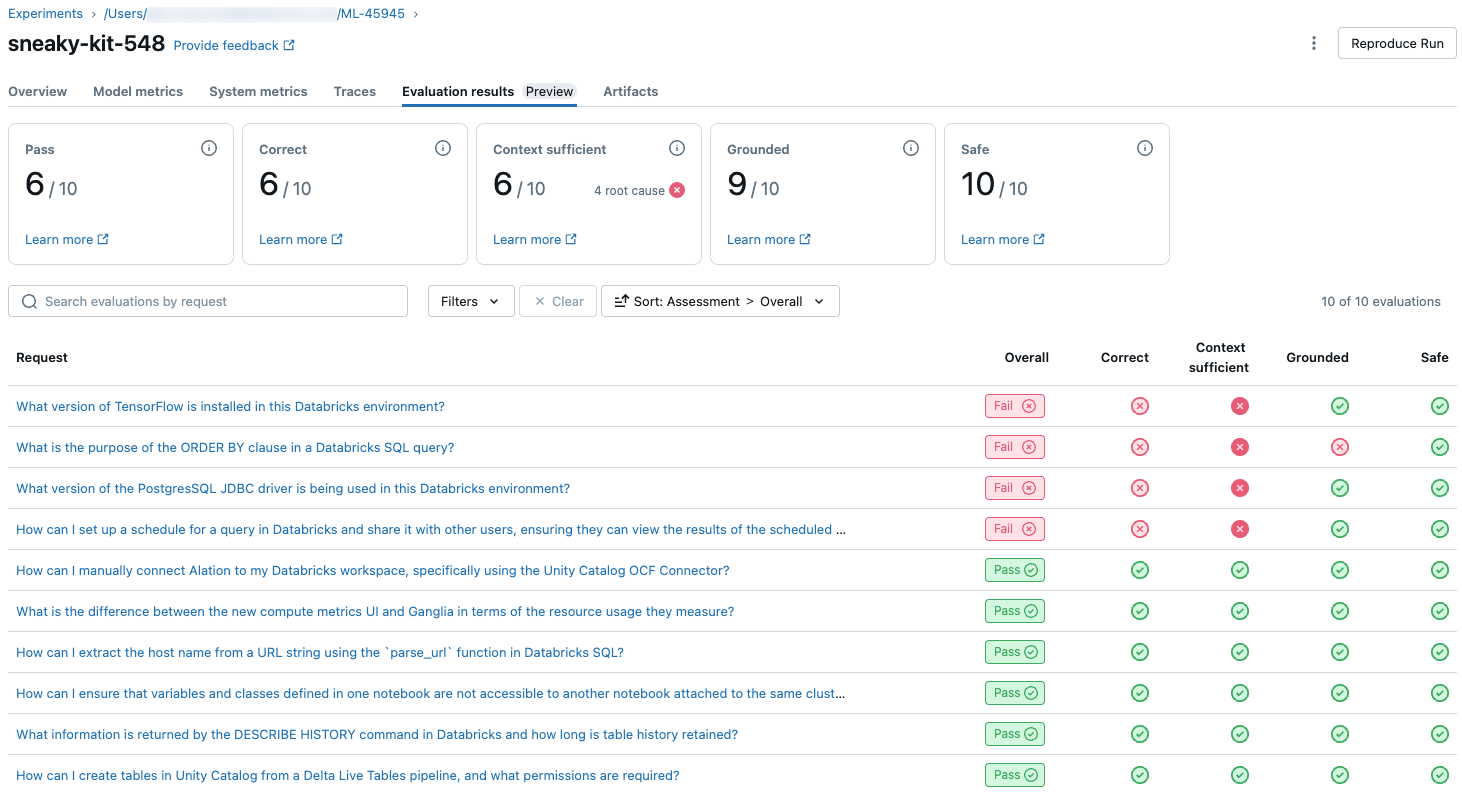
Esta visão geral mostra as avaliações de diferentes juízes para cada solicitação, o status de qualidade-aprovação/reprovação de cada solicitação com base nessas avaliações e a causa básica das solicitações com falha. Ao clicar em uma linha na tabela, você será direcionado para a página de detalhes dessa solicitação que inclui o seguinte:
- Saída do modelo: a resposta gerada do aplicativo agentic e seu rastreamento, se incluído.
- Saída esperada: a resposta esperada para cada solicitação.
- Avaliações detalhadas: As avaliações dos juízes do LLM sobre estes dados. Clique em Ver detalhes para exibir as justificativas fornecidas pelos juízes.
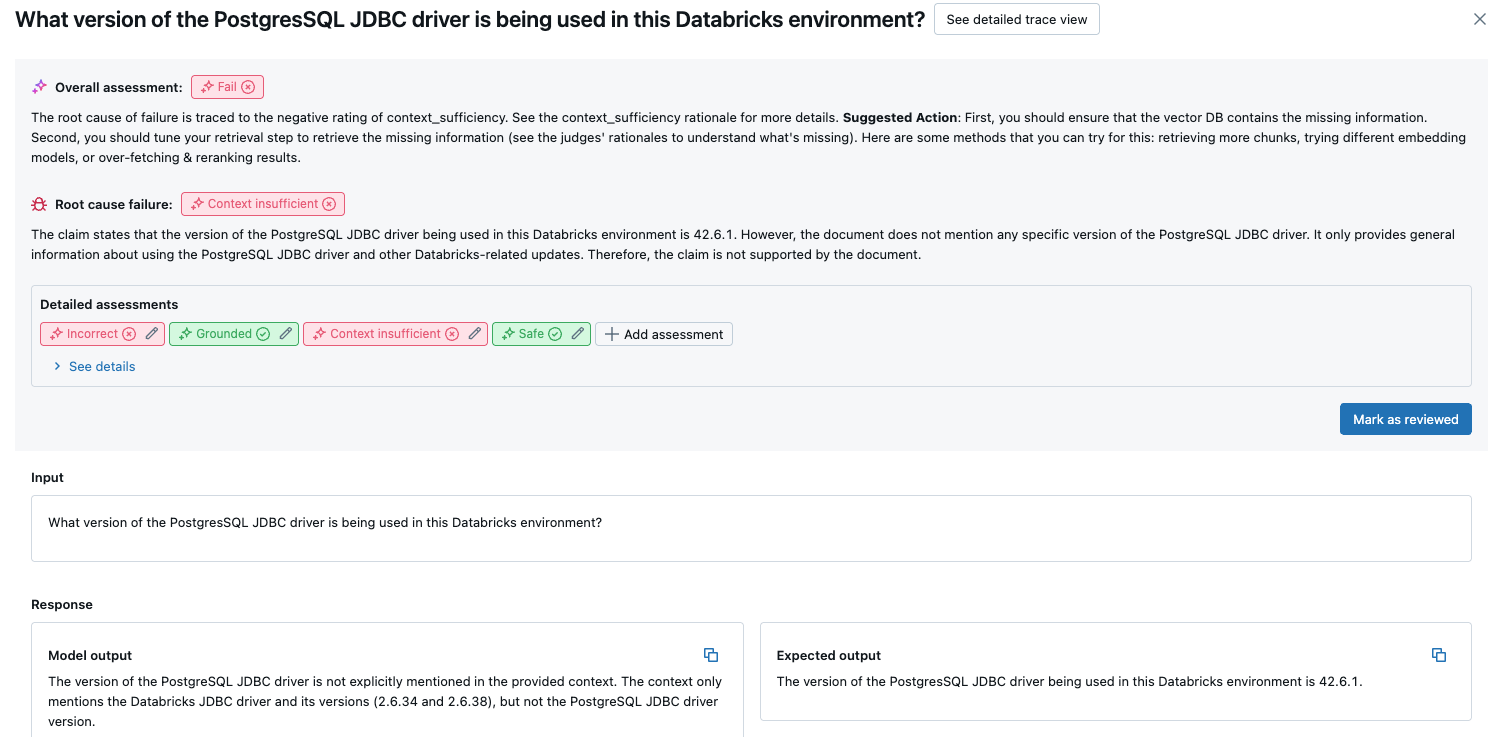
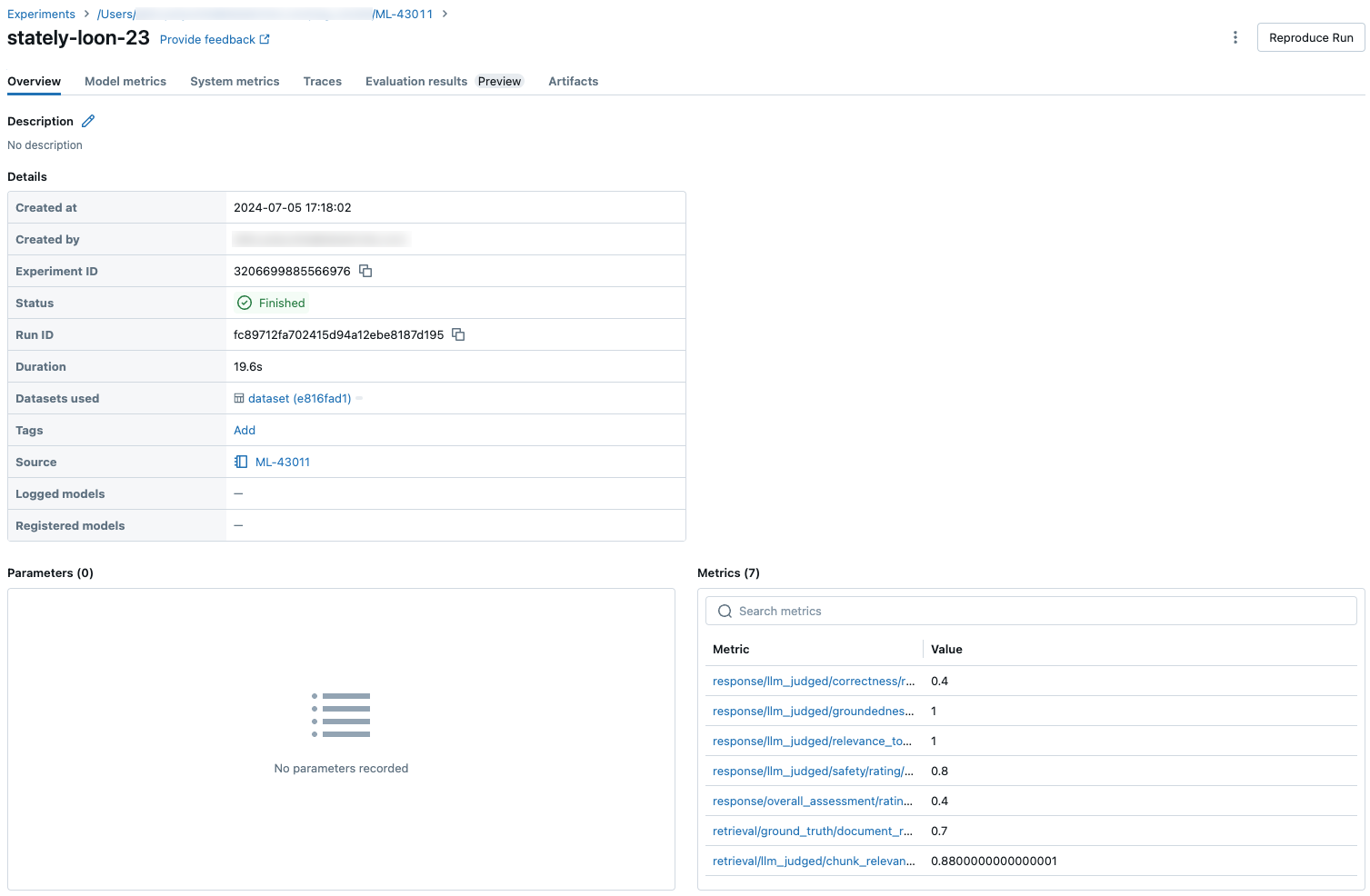
Resultados agregados em todo o conjunto de avaliações
Para ver os resultados agregados em todo o conjunto de avaliações, clique na guia
Comparar os resultados da avaliação entre as corridas
É importante comparar os resultados da avaliação entre as execuções para ver como seu aplicativo agentic responde às alterações. Comparar os resultados pode ajudá-lo a entender se as alterações estão impactando positivamente a qualidade ou ajudá-lo a solucionar problemas de mudança de comportamento.
Compare os resultados por solicitação entre execuções
Para comparar os dados de cada solicitação individual entre execuções, clique na guia Avaliação na página Experimento. Uma tabela mostra cada pergunta do conjunto de avaliação. Use os menus suspensos para selecionar quais colunas ver.
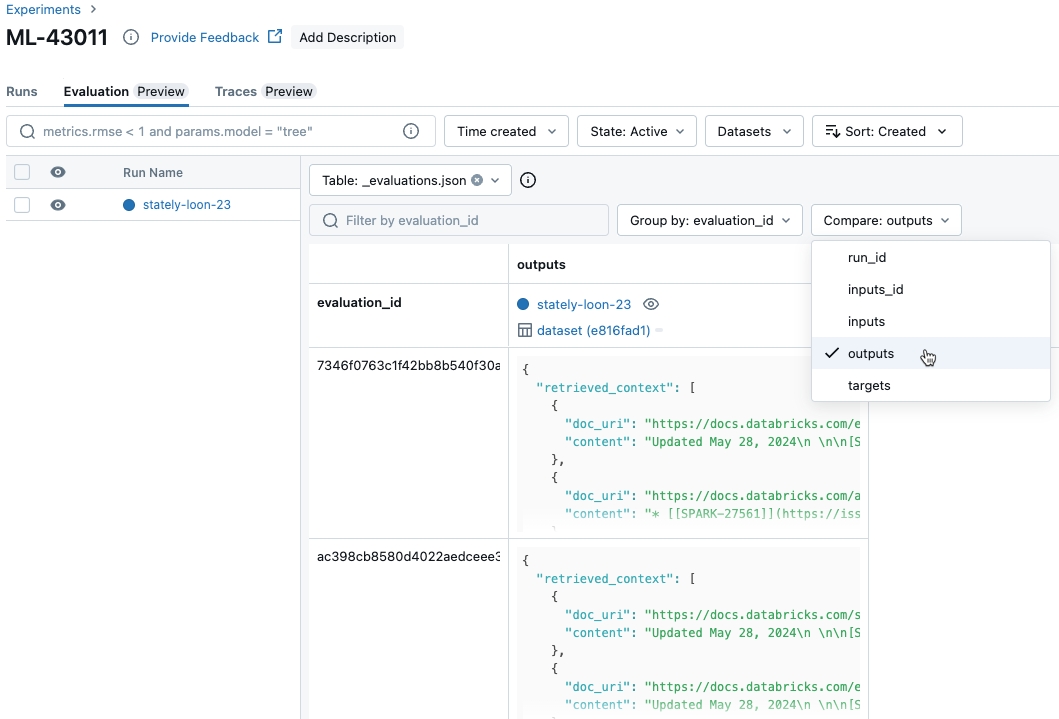
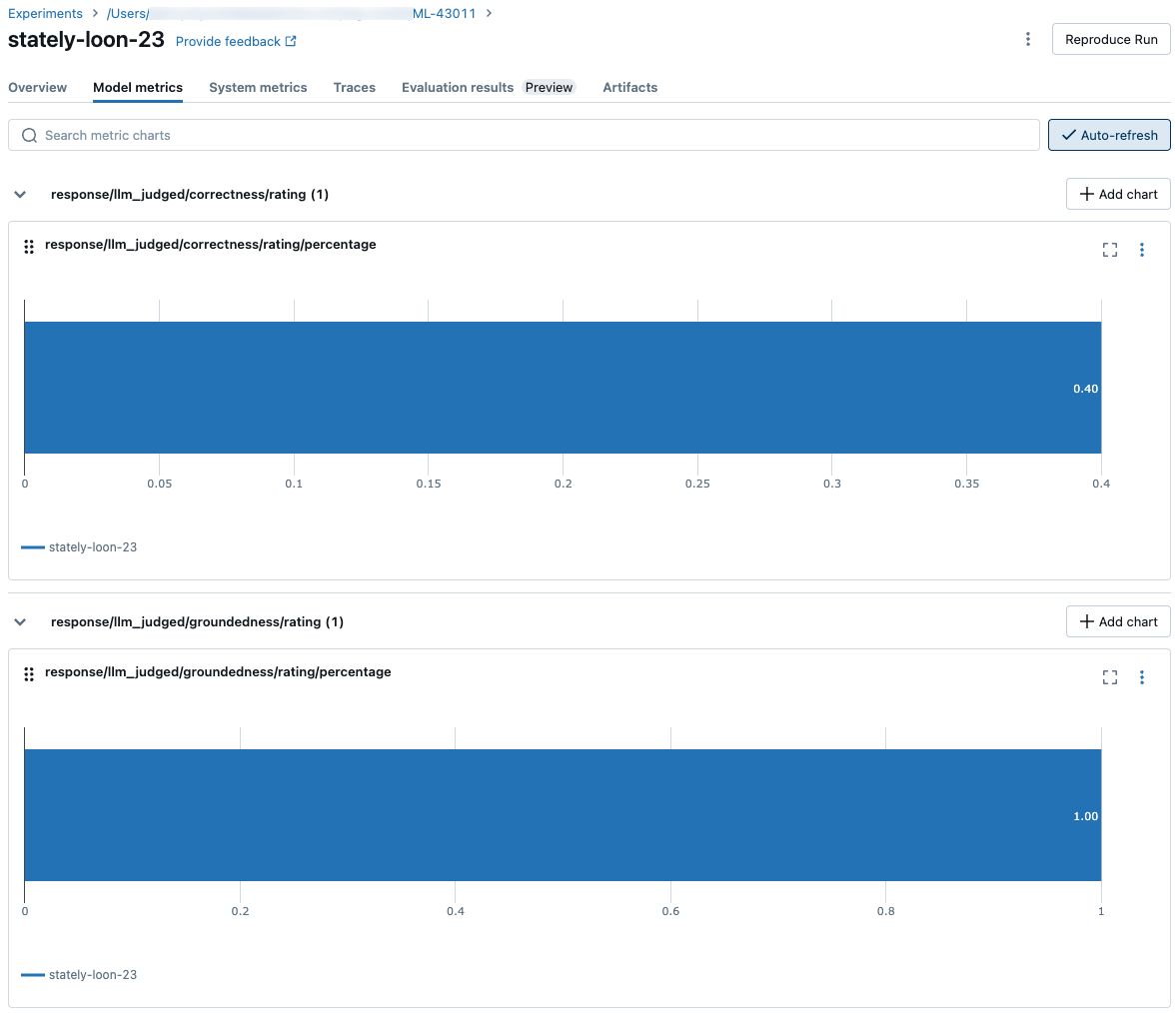
Comparar resultados agregados entre execuções
Você pode acessar os mesmos resultados agregados na página Experimento, que também permite comparar resultados em diferentes execuções. Para acessar a página Experimento, clique no ícone ![]() Experiência na barra lateral direita do bloco de anotações ou clique nos links que aparecem nos resultados da célula do bloco de anotações em que você executou
Experiência na barra lateral direita do bloco de anotações ou clique nos links que aparecem nos resultados da célula do bloco de anotações em que você executou mlflow.evaluate().
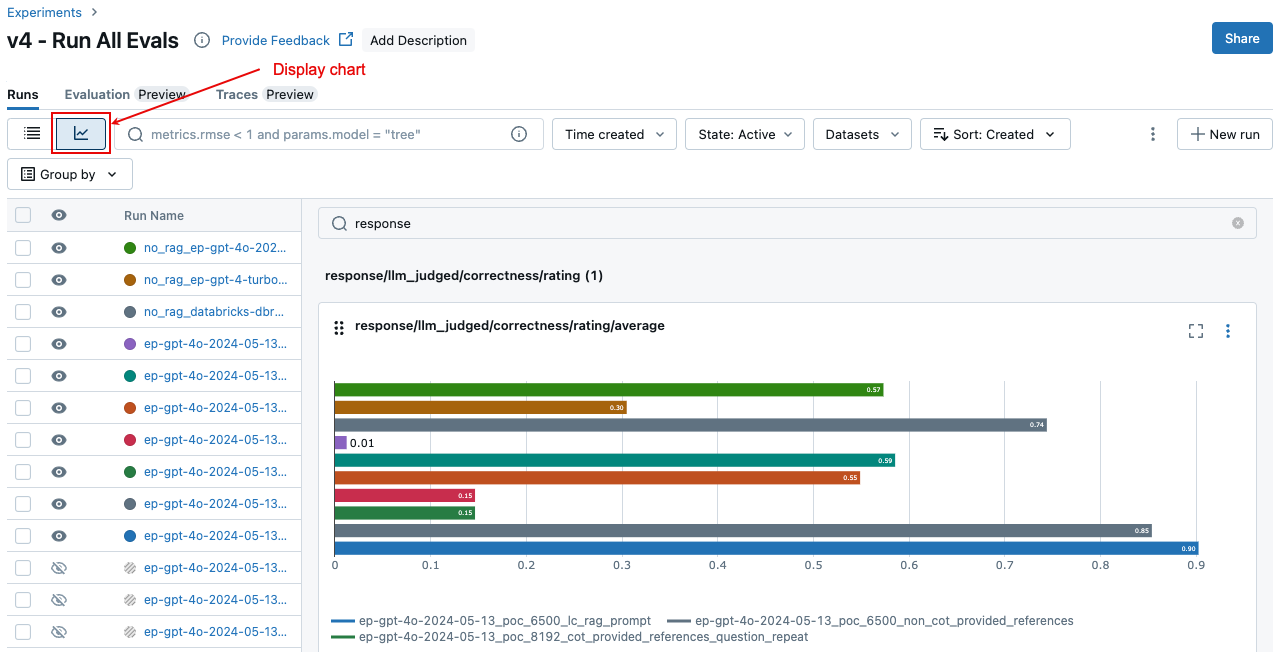
Na página Experimento, clique em ![]() . Isso permite visualizar os resultados agregados para a execução selecionada e comparar com execuções anteriores.
. Isso permite visualizar os resultados agregados para a execução selecionada e comparar com execuções anteriores.
Que juízes são dirigidos
Por padrão, para cada registro de avaliação, o Mosaic AI Agent Evaluation aplica o subconjunto de juízes que melhor corresponde às informações presentes no registro. Especificamente:
- Se o registro incluir uma resposta de verdade fundamental, a Avaliação do Agente aplicará os
context_sufficiency,groundedness,correctness,safetyeguideline_adherencejuízes. - Se o registro não incluir uma resposta de verdade fundamental, a Avaliação do Agente aplicará os juízes
chunk_relevance,groundedness,relevance_to_query,safetyeguideline_adherence.
Para mais pormenores, consulte:
- Executar um subconjunto de avaliadores incorporados
- A IA personalizada avalia
- Como a qualidade, o custo e a latência são avaliados pelo Agent Evaluation
Para obter informações sobre a confiança e segurança dos juízes de LLM, por favor consulte Informações sobre os modelos que suportam os juízes de LLM.
Exemplo: Como passar um aplicativo para a Avaliação do Agente
Para passar um aplicativo para mlflow_evaluate(), use o model argumento. Existem 5 opções para passar um aplicativo no model argumento.
- Um modelo registrado no Unity Catalog.
- Um modelo de log MLflow no experimento MLflow atual.
- Um modelo PyFunc que é carregado no notebook.
- Uma função local no bloco de notas.
- Um ponto de extremidade de agente implantado.
Consulte as seções a seguir para obter exemplos de código que ilustram cada opção.
Opção 1. Modelo registrado no Catálogo Unity
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model = "models:/catalog.schema.model_name/1" # 1 is the version number
model_type="databricks-agent",
)
Opção 2. Modelo de log MLflow no experimento MLflow atual
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
# In the following lines, `6b69501828264f9s9a64eff825371711` is the run_id, and `chain` is the artifact_path that was
# passed with mlflow.xxx.log_model(...).
# If you called model_info = mlflow.langchain.log_model() or mlflow.pyfunc.log_model(), you can access this value using `model_info.model_uri`.
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model = "runs:/6b69501828264f9s9a64eff825371711/chain"
model_type="databricks-agent",
)
Opção 3. Modelo PyFunc carregado no notebook
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model = mlflow.pyfunc.load_model(...)
model_type="databricks-agent",
)
Opção 4. Função local no bloco de notas
A função recebe uma entrada formatada da seguinte forma:
{
"messages": [
{
"role": "user",
"content": "What is MLflow?",
}
],
...
}
A função deve retornar um valor em um dos três formatos suportados a seguir:
Cadeia de caracteres simples contendo a resposta do modelo.
Um dicionário em
ChatCompletionResponseformato. Por exemplo:{ "choices": [ { "message": { "role": "assistant", "content": "MLflow is a machine learning toolkit.", }, ... } ], ..., }Um dicionário em
StringResponseformato, como{ "content": "MLflow is a machine learning toolkit.", ... }.
O exemplo a seguir usa uma função local para encapsular um ponto de extremidade do modelo de base e avaliá-lo:
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
def model(model_input):
client = mlflow.deployments.get_deploy_client("databricks")
return client.predict(endpoint="endpoints:/databricks-meta-llama-3-1-405b-instruct", inputs={"messages": model_input["messages"]})
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model = model
model_type="databricks-agent",
)
Opção 5. Ponto de extremidade do agente implantado
Essa opção só funciona quando você usa pontos de extremidade de agente que foram implantados usando databricks.agents.deploy e com databricks-agents a versão 0.8.0 do SDK ou superior. Para modelos de base ou versões mais antigas do SDK, use a Opção 4 para envolver o modelo em uma função local.
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
# In the following lines, `endpoint-name-of-your-agent` is the name of the agent endpoint.
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model = "endpoints:/endpoint-name-of-your-agent"
model_type="databricks-agent",
)
Como passar no conjunto de avaliação quando a aplicação é incluída na chamada mlflow_evaluate()
No código a seguir, data é um pandas DataFrame com o seu conjunto de avaliação. Estes são exemplos simples. Consulte o esquema de entrada para obter detalhes do.
# You do not have to start from a dictionary - you can use any existing pandas or Spark DataFrame with this schema.
# Minimal evaluation set
bare_minimum_eval_set_schema = [
{
"request": "What is the difference between reduceByKey and groupByKey in Spark?",
}]
# Complete evaluation set
complete_eval_set_schema = [
{
"request_id": "your-request-id",
"request": "What is the difference between reduceByKey and groupByKey in Spark?",
"expected_retrieved_context": [
{
# In `expected_retrieved_context`, `content` is optional, and does not provide any additional functionality.
"content": "Answer segment 1 related to What is the difference between reduceByKey and groupByKey in Spark?",
"doc_uri": "doc_uri_2_1",
},
{
"content": "Answer segment 2 related to What is the difference between reduceByKey and groupByKey in Spark?",
"doc_uri": "doc_uri_2_2",
},
],
"expected_response": "There's no significant difference.",
}]
# Convert dictionary to a pandas DataFrame
eval_set_df = pd.DataFrame(bare_minimum_eval_set_schema)
# Use a Spark DataFrame
import numpy as np
spark_df = spark.table("catalog.schema.table") # or any other way to get a Spark DataFrame
eval_set_df = spark_df.toPandas()
Exemplo: Como passar saídas geradas anteriormente para a Avaliação do Agente
Esta seção descreve como passar saídas geradas anteriormente na mlflow_evaluate() chamada. Para obter o esquema do conjunto de avaliação necessário, consulte esquema de entrada de avaliação do agente.
No código a seguir, data é um DataFrame pandas com o seu conjunto de avaliação e as saídas geradas pela aplicação. Estes são exemplos simples. Consulte o esquema de entrada para obter detalhes do.
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
evaluation_results = mlflow.evaluate(
data=eval_set_with_app_outputs_df, # pandas DataFrame with the evaluation set and application outputs
model_type="databricks-agent",
)
# You do not have to start from a dictionary - you can use any existing pandas or Spark DataFrame with this schema.
# Minimum required input
bare_minimum_input_schema = [
{
"request": "What is the difference between reduceByKey and groupByKey in Spark?",
"response": "reduceByKey aggregates data before shuffling, whereas groupByKey shuffles all data, making reduceByKey more efficient.",
}]
# Input including optional arguments
complete_input_schema = [
{
"request_id": "your-request-id",
"request": "What is the difference between reduceByKey and groupByKey in Spark?",
"expected_retrieved_context": [
{
# In `expected_retrieved_context`, `content` is optional, and does not provide any additional functionality.
"content": "Answer segment 1 related to What is the difference between reduceByKey and groupByKey in Spark?",
"doc_uri": "doc_uri_2_1",
},
{
"content": "Answer segment 2 related to What is the difference between reduceByKey and groupByKey in Spark?",
"doc_uri": "doc_uri_2_2",
},
],
"expected_response": "There's no significant difference.",
"response": "reduceByKey aggregates data before shuffling, whereas groupByKey shuffles all data, making reduceByKey more efficient.",
"retrieved_context": [
{
# In `retrieved_context`, `content` is optional. If provided, the Databricks Context Relevance LLM Judge is executed to check the `content`'s relevance to the `request`.
"content": "reduceByKey reduces the amount of data shuffled by merging values before shuffling.",
"doc_uri": "doc_uri_2_1",
},
{
"content": "groupByKey may lead to inefficient data shuffling due to sending all values across the network.",
"doc_uri": "doc_uri_6_extra",
},
],
"guidelines": [
"The response must be in English",
]
}]
# Convert dictionary to a pandas DataFrame
eval_set_with_app_outputs_df = pd.DataFrame(bare_minimum_input_schema)
# Use a Spark DataFrame
import numpy as np
spark_df = spark.table("catalog.schema.table") # or any other way to get a Spark DataFrame
eval_set_with_app_outputs_df = spark_df.toPandas()
Exemplo: Use uma função personalizada para processar respostas do LangGraph
Os agentes LangGraph, especialmente aqueles com funcionalidade de chat, podem retornar várias mensagens para uma única chamada de inferência. É da responsabilidade do utilizador converter a resposta do agente para um formato suportado pela Avaliação do Agente.
Uma abordagem é usar uma função personalizada para processar a resposta. O exemplo a seguir mostra uma função personalizada que extrai a última mensagem de chat de um modelo LangGraph. Essa função é então usada em mlflow.evaluate() para retornar uma única resposta de cadeia de caracteres, que pode ser comparada à coluna ground_truth.
O código de exemplo faz as seguintes suposições:
- O modelo aceita entrada no formato {"messages": [{"role": "user", "content": "hello"}]}.
- O modelo retorna uma lista de cadeias de caracteres no formato ["resposta 1", "resposta 2"].
O código a seguir envia as respostas concatenadas ao juiz neste formato: "response 1nresponse2"
import mlflow
import pandas as pd
from typing import List
loaded_model = mlflow.langchain.load_model(model_uri)
eval_data = pd.DataFrame(
{
"inputs": [
"What is MLflow?",
"What is Spark?",
],
"expected_response": [
"MLflow is an open-source platform for managing the end-to-end machine learning (ML) lifecycle. It was developed by Databricks, a company that specializes in big data and machine learning solutions. MLflow is designed to address the challenges that data scientists and machine learning engineers face when developing, training, and deploying machine learning models.",
"Apache Spark is an open-source, distributed computing system designed for big data processing and analytics. It was developed in response to limitations of the Hadoop MapReduce computing model, offering improvements in speed and ease of use. Spark provides libraries for various tasks such as data ingestion, processing, and analysis through its components like Spark SQL for structured data, Spark Streaming for real-time data processing, and MLlib for machine learning tasks",
],
}
)
def custom_langgraph_wrapper(model_input):
predictions = loaded_model.invoke({"messages": model_input["messages"]})
# Assuming `predictions` is a list of strings
return predictions.join("\n")
with mlflow.start_run() as run:
results = mlflow.evaluate(
custom_langgraph_wrapper, # Pass the function defined above
data=eval_data,
model_type="databricks-agent",
)
print(results.metrics)
Criar um painel com métricas
Quando você estiver iterando sobre a qualidade do seu agente, talvez queira compartilhar um painel com as partes interessadas que mostre como a qualidade melhorou ao longo do tempo. Você pode extrair as métricas de suas execuções de avaliação MLflow, salvar os valores em uma tabela Delta e criar um painel.
O exemplo a seguir mostra como extrair e salvar os valores de métrica da avaliação mais recente executada em seu bloco de anotações:
uc_catalog_name = "catalog"
uc_schema_name = "schema"
table_name = "results"
eval_results = mlflow.evaluate(
model=logged_agent_info.model_uri, # use the logged Agent
data=evaluation_set, # Run the logged Agent for all queries defined above
model_type="databricks-agent", # use Agent Evaluation
)
# The `append_metrics_to_table function` is defined below
append_metrics_to_table("<identifier-for-table>", eval_results.metrics, f"{uc_catalog_name}.{uc_schema_name}.{table_name}")
O exemplo a seguir mostra como extrair e salvar valores de métrica para execuções anteriores que você salvou em seu experimento MLflow.
import pandas as pd
def get_mlflow_run(experiment_name, run_name):
runs = mlflow.search_runs(experiment_names=[experiment_name], filter_string=f"run_name = '{run_name}'", output_format="list")
if len(runs) != 1:
raise ValueError(f"Found {len(runs)} runs with name {run_name}. {run_name} must identify a single run. Alternatively, you can adjust this code to search for a run based on `run_id`")
return runs[0]
run = get_mlflow_run(experiment_name ="/Users/<user_name>/db_docs_mlflow_experiment", run_name="evaluation__2024-10-09_02:27:17_AM")
# The `append_metrics_to_table` function is defined below
append_metrics_to_table("<identifier-for-table>", run.data.metrics, f"{uc_catalog_name}.{uc_schema_name}.{table_name}")
Agora você pode criar um painel usando esses dados.
O código a seguir define a função append_metrics_to_table usada nos exemplos anteriores.
# Definition of `append_metrics_to_table`
def append_metrics_to_table(run_name, mlflow_metrics, delta_table_name):
data = mlflow_metrics.copy()
# Add identifying run_name and timestamp
data["run_name"] = run_name
data["timestamp"] = pd.Timestamp.now()
# Remove metrics with error counts
data = {k: v for k, v in mlflow_metrics.items() if "error_count" not in k}
# Convert to a Spark DataFrame(
metrics_df = pd.DataFrame([data])
metrics_df_spark = spark.createDataFrame(metrics_df)
# Append to the Delta table
metrics_df_spark.write.mode("append").saveAsTable(delta_table_name)
Informações sobre os modelos que capacitam os juízes LLM
- Os juízes LLM podem usar serviços de terceiros para avaliar seus aplicativos GenAI, incluindo o Azure OpenAI operado pela Microsoft.
- Para o Azure OpenAI, o Databricks optou por não participar do Monitoramento de Abuso, portanto, nenhum prompt ou resposta é armazenado com o Azure OpenAI.
- Para os espaços de trabalho da União Europeia (UE), os juízes LLM utilizam modelos alojados na UE. Todas as outras regiões usam modelos hospedados nos EUA.
- A desativação dos recursos de assistência de IA alimentados por IA do Azure impede que o juiz LLM chame modelos com tecnologia de IA do Azure.
- Os dados enviados ao juiz LLM não são usados para nenhum modelo de treinamento.
- Os juízes LLM destinam-se a ajudar os clientes a avaliar seus aplicativos RAG, e os resultados dos juízes LLM não devem ser usados para treinar, melhorar ou ajustar um LLM.