Como monitorar a qualidade do seu agente no tráfego de produção
Importante
Esta funcionalidade está em Pré-visualização Pública.
Este artigo descreve como monitorar a qualidade dos agentes implantados no tráfego de produção usando o Mosaic AI Agent Evaluation.
O monitoramento on-line é um aspeto crucial para garantir que seu agente esteja trabalhando como pretendido com solicitações do mundo real. Usando o bloco de anotações fornecido abaixo, você pode executar a Avaliação do Agente continuamente nas solicitações atendidas por meio de um ponto de extremidade de atendimento ao agente. O bloco de anotações gera um painel que exibe métricas de qualidade, bem como feedback do usuário (polegar para cima 👍 ou polegar para baixo 👎) para as saídas do seu agente em solicitações de produção. Esse feedback pode chegar por meio do aplicativo de avaliação das partes interessadas ou da API de feedback sobre pontos de extremidade de produção que permite capturar as reações do usuário final. O painel permite dividir as métricas por diferentes dimensões, incluindo por tempo, feedback do usuário, status de aprovação/reprovação e tópico da solicitação de entrada (por exemplo, para entender se tópicos específicos estão correlacionados com saídas de qualidade inferior). Além disso, você pode se aprofundar em solicitações individuais com respostas de baixa qualidade para depurá-las ainda mais. Todos os artefatos, como o painel, são totalmente personalizáveis.
Requisitos
- Os recursos de assistência de IA alimentados por IA do Azure devem ser habilitados para seu espaço de trabalho.
- Tabelas de inferência devem ser ativadas no ponto de extremidade que está a servir o agente.
Processar continuamente o tráfego de produção através da Avaliação de Agentes
O bloco de anotações de exemplo a seguir ilustra como executar a Avaliação do Agente nos logs de solicitação de um ponto de extremidade de serviço do agente. Para executar o bloco de notas, siga estes passos:
- Importe o bloco de notas na sua área de trabalho (instruções). Você pode clicar no botão "Copiar link para importação" abaixo para obter um URL para a importação.
- Preencha os parâmetros necessários no topo do notebook importado.
- O nome do ponto de extremidade de serviço do agente implantado.
- Uma taxa de amostragem entre 0,0 e 1,0 para solicitações de amostra. Use uma taxa mais baixa para pontos finais com grandes quantidades de tráfego.
- (Opcional) Uma pasta de espaço de trabalho para armazenar artefatos gerados (como painéis). O padrão é a pasta base.
- (Opcional) Uma lista de tópicos para categorizar as solicitações de entrada. O padrão é uma lista que consiste em um único tópico abrangente.
- Clique em Executar tudo no bloco de anotações importado. Isso fará um processamento inicial de seus logs de produção dentro de uma janela de 30 dias e inicializará o painel que resume as métricas de qualidade.
- Clique em Agendar para criar um trabalho para executar o bloco de anotações periodicamente. O trabalho processará incrementalmente seus logs de produção e manterá o painel atualizado.
O notebook requer computação sem servidor ou um cluster executando o Databricks Runtime 15.2 ou superior. Ao monitorar continuamente o tráfego de produção em endpoints com um grande número de solicitações, recomendamos definir uma programação mais frequente. Por exemplo, uma programação horária funcionaria bem para um ponto final com mais de 10.000 solicitações por hora e uma taxa de amostragem de 10%.
Executar avaliação de agente no bloco de anotações de tráfego de produção
Aplique diretrizes nas respostas do seu agente
O juiz de aderência à diretriz garante que as saídas do seu modelo estejam de acordo com as diretrizes fornecidas. Você pode escrever essas diretrizes globais conforme mostrado no bloco de anotações fornecido acima ou da seguinte maneira:
mlflow.evaluate(
...,
evaluator_config={
"databricks-agent": {
# You can also just pass an array of guidelines directly to guidelines, but Databricks recommends naming them with a dictionary.
"guidelines": {
"english": ["The response must be in English"],
"clarity": ["The response must be clear, coherent, and concise"],
}
}
}
)
Os resultados deste avaliador serão inseridos na tabela de logs de solicitações avaliadas gerada pelo notebook de exemplo (eval_requests_log_table_name no notebook) e o dashboard pode ser personalizado para exibir os resultados do avaliador ao longo do tempo.
Criar alertas sobre métricas de avaliação
Depois de agendar a execução periódica do bloco de anotações, você pode adicionar alertas para ser notificado quando as métricas de qualidade caírem abaixo do esperado. Esses alertas são criados e usados da mesma forma que outros alertas SQL do Databricks. Primeiro, crie um de consulta SQL Databricks na tabela de log de solicitações de avaliação gerada pelo bloco de anotações de exemplo. O código a seguir mostra um exemplo de consulta na tabela de solicitações de avaliação, filtrando solicitações da hora anterior:
SELECT
`date`,
AVG(pass_indicator) as avg_pass_rate
FROM (
SELECT
*,
CASE
WHEN `response/overall_assessment/rating` = 'yes' THEN 1
WHEN `response/overall_assessment/rating` = 'no' THEN 0
ELSE NULL
END AS pass_indicator
-- The eval requests log table is generated by the example notebook
FROM {eval_requests_log_table_name}
WHERE `date` >= CURRENT_TIMESTAMP() - INTERVAL 1 DAY
)
GROUP BY ALL
Em seguida, crie um alerta Databricks SQL para avaliar a consulta na frequência desejada e envie uma notificação se o alerta for acionado. A imagem a seguir mostra um exemplo de configuração para enviar um alerta quando a taxa de aprovação geral cai abaixo de 80%.
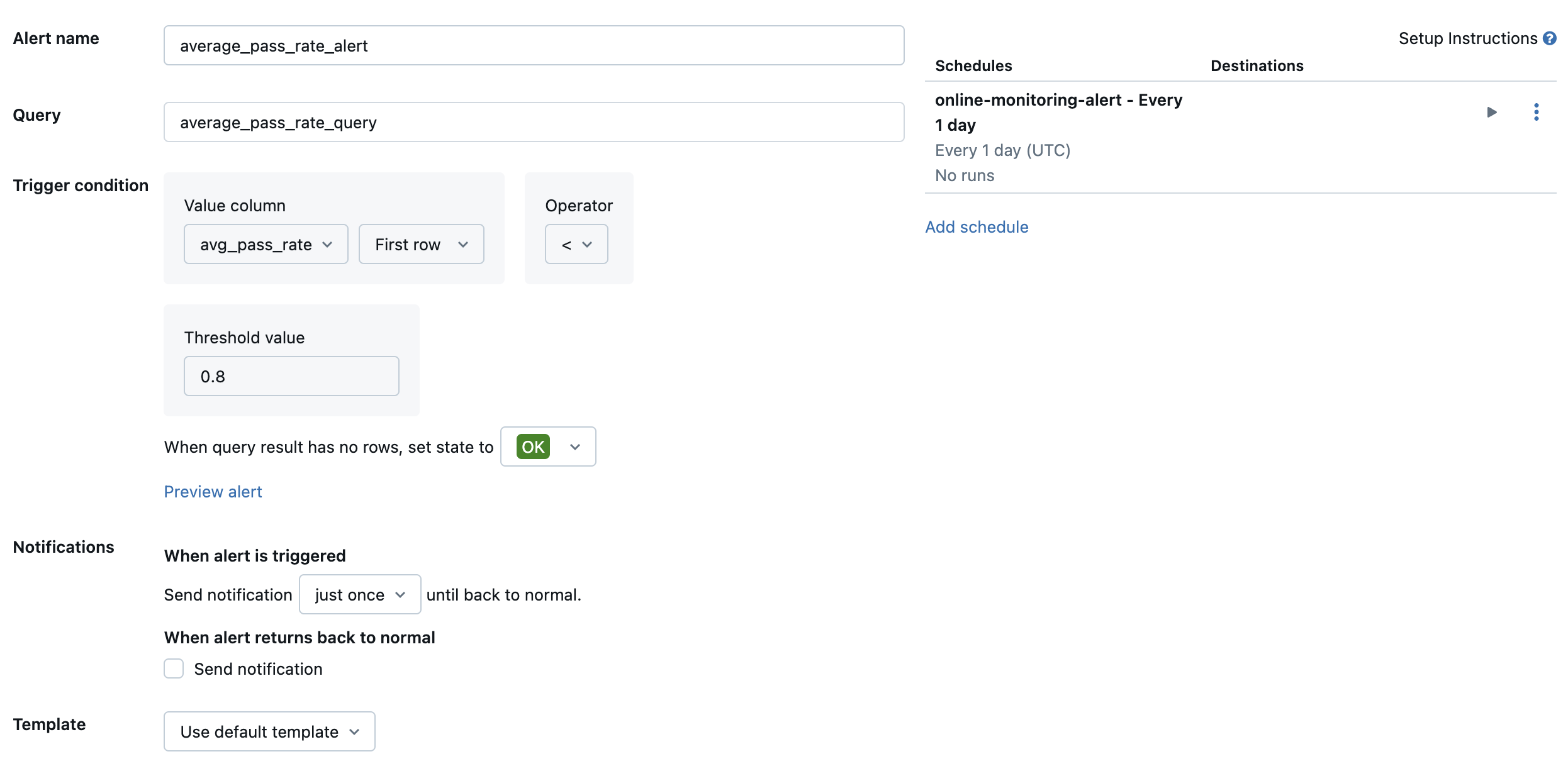
Por padrão, uma notificação por e-mail é enviada. Você também pode configurar um webhook ou enviar notificações para outros aplicativos, como Slack ou PagerDuty.
Adicionar logs de produção selecionados ao aplicativo de revisão para revisão humana
À medida que os usuários fornecem feedback sobre suas solicitações, você pode solicitar a especialistas no assunto que analisem as solicitações com feedback negativo (solicitações com o polegar para baixo na resposta ou recuperações). Para fazer isso, você adiciona logs específicos ao aplicativo de revisão para solicitar revisão de especialistas.
O código a seguir mostra um exemplo de consulta na tabela de log de avaliação para recuperar a avaliação humana mais recente por ID de solicitação e ID de origem:
with ranked_logs as (
select
`timestamp`,
request_id,
source.id as source_id,
text_assessment.ratings["answer_correct"]["value"] as text_rating,
retrieval_assessment.ratings["answer_correct"]["value"] as retrieval_rating,
retrieval_assessment.position as retrieval_position,
row_number() over (
partition by request_id, source.id, retrieval_assessment.position order by `timestamp` desc
) as rank
from {assessment_log_table_name}
)
select
request_id,
source_id,
text_rating,
retrieval_rating
from ranked_logs
where rank = 1
order by `timestamp` desc
No código a seguir, substitua ... na linha human_ratings_query = "..." por uma consulta semelhante à acima. Em seguida, o código a seguir extrai solicitações com comentários negativos e as adiciona ao aplicativo de revisão:
from databricks import agents
human_ratings_query = "..."
human_ratings_df = spark.sql(human_ratings_query).toPandas()
# Filter out the positive ratings, leaving only negative and "IDK" ratings
negative_ratings_df = human_ratings_df[
(human_ratings_df["text_rating"] != "positive") | (human_ratings_df["retrieval_rating"] != "positive")
]
negative_ratings_request_ids = negative_ratings_df["request_id"].drop_duplicates().to_list()
agents.enable_trace_reviews(
model_name=YOUR_MODEL_NAME,
request_ids=negative_ratings_request_ids,
)
Para obter mais detalhes sobre o aplicativo de avaliação, consulte Obter feedback sobre a qualidade de um aplicativo agentic.