MLflow Tracing para agentes
Importante
Esta funcionalidade está em Pré-visualização Pública.
Este artigo descreve o MLflow Tracing em Databricks e como usá-lo para adicionar observabilidade aos seus aplicativos de IA generativa.
O que é MLflow Tracing?
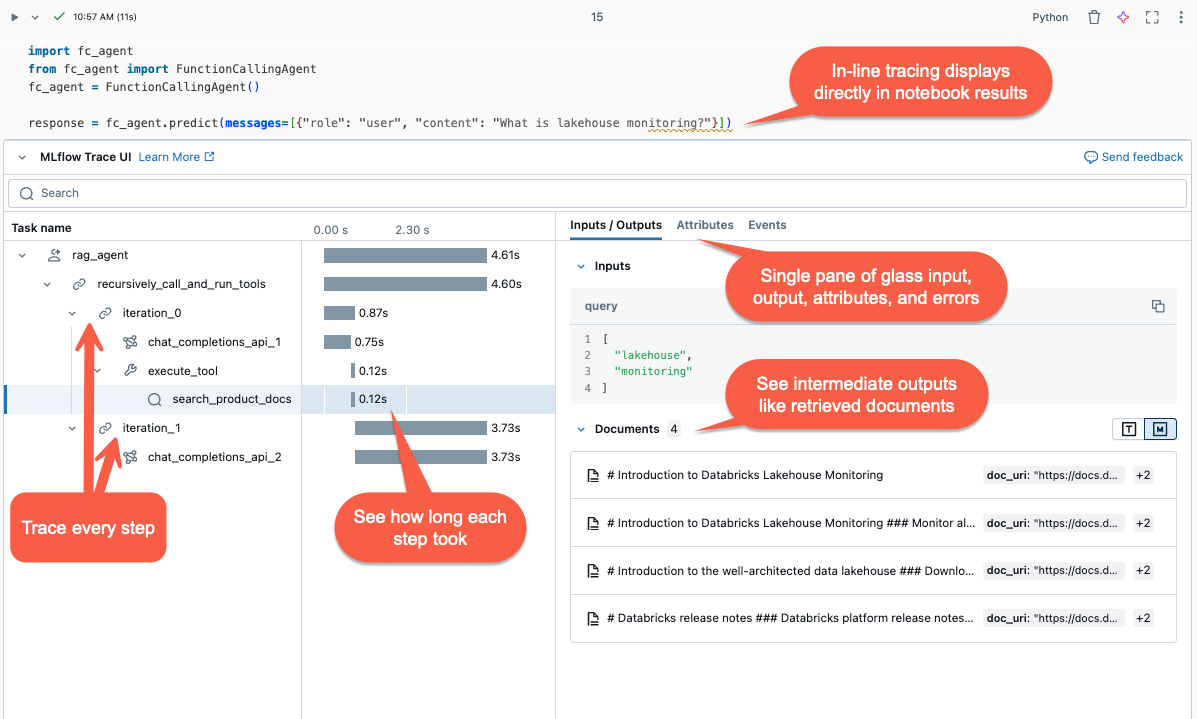
MLflow Tracing captura informações detalhadas sobre a execução de aplicações de IA generativa. O rastreamento registra entradas, saídas e metadados associados a cada etapa intermediária de uma solicitação para que você possa identificar a origem de bugs e comportamentos inesperados. Por exemplo, se o seu modelo alucina, você pode inspecionar rapidamente cada passo que levou à alucinação.
O MLflow Tracing é integrado com as ferramentas e a infraestrutura do Databricks, permitindo armazenar e exibir rastreamentos em notebooks Databricks ou na interface do usuário do experimento MLflow.
Por que usar o MLflow Tracing?
O MLflow Tracing oferece vários benefícios:
- Revise uma visualização de rastreamento interativa e use a ferramenta de investigação para diagnosticar problemas.
- Verifique se os modelos de instrução e diretrizes produzem resultados razoáveis.
- Analise a latência de diferentes estruturas, modelos e tamanhos de blocos.
- Estime os custos do aplicativo medindo o uso do token em diferentes modelos.
- Estabeleça conjuntos de dados de referência "dourados" para avaliar o desempenho de diferentes versões.
- Guarde registos de endpoints do modelo de produção para depurar problemas e realizar revisão e avaliação offline.
Adicionar rastreamentos ao seu agente
O MLflow Tracing suporta três métodos para adicionar rastreamentos às suas aplicações de IA generativas. Para obter detalhes de referência da API, consulte a documentação do MLflow.
| API | Caso de uso recomendado | Description |
|---|---|---|
| registro automático do MLflow | Desenvolvimento com bibliotecas GenAI integradas | O autologging regista automaticamente as operações para frameworks de código aberto suportados, como LangChain, LlamaIndex e OpenAI. |
| APIs fluentes | Agente personalizado com Pyfunc | APIs low-code para adicionar rastros sem se preocupar com o gerenciamento da estrutura em árvore do rastro. MLflow determina automaticamente as relações apropriadas de abrangência pai-filho usando a stack Python. |
| APIs do cliente MLflow | Casos de uso avançados, como multi-threading |
MLflowClient fornece APIs granulares e seguras para o uso em threads para casos de uso avançados. Você deve gerenciar manualmente a relação pai-filho de intervalos. Isso oferece um melhor controlo sobre o ciclo de vida do rastreamento, especialmente para casos de uso multi-thread. |
Instalar o MLflow Tracing
O MLflow Tracing está disponível nas versões 2.13.0 e superiores do MLflow, que vêm pré-instaladas no ML <DBR< 15.4 LTS e versões posteriores. Se necessário, instale o MLflow com o seguinte código:
%pip install mlflow>=2.13.0 -qqqU
%restart_python
Como alternativa, você pode instalar a versão mais recente do databricks-agents, que inclui uma versão MLflow compatível:
%pip install databricks-agents
Use o registro automático para adicionar rastreamentos aos seus agentes
Se sua biblioteca GenAI suportar rastreamento, como LangChain ou OpenAI, habilite o registro automático adicionando mlflow.<library>.autolog() ao seu código. Por exemplo:
mlflow.langchain.autolog()
Nota
A partir do Databricks Runtime 15.4 LTS ML, o rastreamento MLflow é habilitado por padrão em notebooks. Para desativar o rastreamento, por exemplo, com o LangChain, podes executar mlflow.langchain.autolog(log_traces=False) no teu caderno.
O MLflow suporta bibliotecas adicionais para o registo automático de rastreio. Para obter uma lista completa de bibliotecas integradas, consulte a documentação do MLflow Tracing.
Use APIs Fluent para adicionar rastreamentos manualmente ao seu agente
APIs fluentes no MLflow criam automaticamente hierarquias de rastreamento com base no fluxo de execução do seu código.
Decore a sua função
Use o decorador @mlflow.trace para criar um intervalo para o escopo da função decorada.
O objeto MLflow Span organiza as etapas de rastreamento. Spans captura informações sobre operações ou etapas individuais, como chamadas de API ou consultas de armazenamento vetorial, dentro de um fluxo de trabalho.
O intervalo começa quando a função é invocada e termina quando esta retorna. MLflow registra a entrada e saída da função e quaisquer exceções geradas pela função.
Por exemplo, o código a seguir cria uma extensão chamada my_function que captura argumentos de entrada x e y e a saída.
@mlflow.trace(name="agent", span_type="TYPE", attributes={"key": "value"})
def my_function(x, y):
return x + y
Usar o gerenciador de contexto de rastreamento
Se você quiser criar uma extensão para um bloco arbitrário de código, não apenas uma função, você pode usámlflow.start_span() como um gerenciador de contexto que encapsula o bloco de código. O período começa quando o contexto é inserido e termina quando o contexto é saído. As entradas e saídas de span devem ser fornecidas manualmente usando métodos setter do objeto span produzido pelo gerenciador de contexto.
with mlflow.start_span("my_span") as span:
span.set_inputs({"x": x, "y": y})
result = x + y
span.set_outputs(result)
span.set_attribute("key", "value")
Envolver uma função externa
Para rastrear funções de biblioteca externas, envolva a função com mlflow.trace.
from sklearn.metrics import accuracy_score
y_pred = [0, 2, 1, 3]
y_true = [0, 1, 2, 3]
traced_accuracy_score = mlflow.trace(accuracy_score)
traced_accuracy_score(y_true, y_pred)
Exemplo de API fluente
O exemplo a seguir mostra como usar as APIs Fluent mlflow.trace e mlflow.start_span para rastrear o quickstart-agent:
import mlflow
from mlflow.deployments import get_deploy_client
class QAChain(mlflow.pyfunc.PythonModel):
def __init__(self):
self.client = get_deploy_client("databricks")
@mlflow.trace(name="quickstart-agent")
def predict(self, model_input, system_prompt, params):
messages = [
{
"role": "system",
"content": system_prompt,
},
{
"role": "user",
"content": model_input[0]["query"]
}
]
traced_predict = mlflow.trace(self.client.predict)
output = traced_predict(
endpoint=params["model_name"],
inputs={
"temperature": params["temperature"],
"max_tokens": params["max_tokens"],
"messages": messages,
},
)
with mlflow.start_span(name="_final_answer") as span:
# Initiate another span generation
span.set_inputs({"query": model_input[0]["query"]})
answer = output["choices"][0]["message"]["content"]
span.set_outputs({"generated_text": answer})
# Attributes computed at runtime can be set using the set_attributes() method.
span.set_attributes({
"model_name": params["model_name"],
"prompt_tokens": output["usage"]["prompt_tokens"],
"completion_tokens": output["usage"]["completion_tokens"],
"total_tokens": output["usage"]["total_tokens"]
})
return answer
Depois de adicionar o rastreamento, execute a função. O exemplo a seguir continua com a função predict() na seção anterior. Os rastreamentos são mostrados automaticamente quando você executa o método de invocação, predict().
SYSTEM_PROMPT = """
You are an assistant for Databricks users. You answer Python, coding, SQL, data engineering, spark, data science, DW and platform, API, or infrastructure administration questions related to Databricks. If the question is unrelated to one of these topics, kindly decline to answer. If you don't know the answer, say that you don't know; don't try to make up an answer. Keep the answer as concise as possible. Use the following pieces of context to answer the question at the end:
"""
model = QAChain()
prediction = model.predict(
[
{"query": "What is in MLflow 5.0"},
],
SYSTEM_PROMPT,
{
# Using Databricks Foundation Model for easier testing, feel free to replace it.
"model_name": "databricks-dbrx-instruct",
"temperature": 0.1,
"max_tokens": 1000,
}
)
APIs do cliente MLflow
MlflowClient expõe APIs granulares e seguras para threads para iniciar e terminar rastreamentos, gerenciar extensões e definir campos de extensão. A solução fornece controle completo do ciclo de vida e da estrutura do rastreamento. Essas APIs são úteis quando as APIs Fluent são insuficientes para as suas necessidades, como nos casos de aplicativos multithreaded e de retornos de chamada.
A seguir estão as etapas para criar um rastreamento completo usando o MLflow Client.
Crie uma instância de MLflowClient por
client = MlflowClient().Inicie um rastreamento usando o método
client.start_trace(). Isso inicia o contexto de rastreamento, inicia um intervalo de raiz absoluto e retorna um objeto de intervalo de raiz. Esse método deve ser executado antes da APIstart_span().- Defina seus atributos, entradas e saídas para o rastreamento no
client.start_trace().
Nota
Não há um equivalente ao método
start_trace()nas APIs Fluent. Isso ocorre porque as APIs Fluent inicializam automaticamente o contexto de rastreamento e determinam se é a extensão raiz com base no estado gerenciado.- Defina seus atributos, entradas e saídas para o rastreamento no
A API start_trace() retorna um span. Obtenha a ID da solicitação, um identificador exclusivo do rastreamento também conhecido como
trace_ide a ID da extensão retornada usandospan.request_idespan.span_id.Inicie uma extensão filho usando
client.start_span(request_id, parent_id=span_id)para definir seus atributos, entradas e saídas para a extensão.- Esse método requer
request_ideparent_idpara associar a extensão com a posição correta na hierarquia de rastreamento. Ele retorna outro objeto span.
- Esse método requer
Termine o intervalo da criança chamando
client.end_span(request_id, span_id).Repita as etapas 3 a 5 para qualquer subintervalo que pretenda criar.
Depois que todos os intervalos da criança terminarem, chame
client.end_trace(request_id)para fechar o rastreamento e gravá-lo.
from mlflow.client import MlflowClient
mlflow_client = MlflowClient()
root_span = mlflow_client.start_trace(
name="simple-rag-agent",
inputs={
"query": "Demo",
"model_name": "DBRX",
"temperature": 0,
"max_tokens": 200
}
)
request_id = root_span.request_id
# Retrieve documents that are similar to the query
similarity_search_input = dict(query_text="demo", num_results=3)
span_ss = mlflow_client.start_span(
"search",
# Specify request_id and parent_id to create the span at the right position in the trace
request_id=request_id,
parent_id=root_span.span_id,
inputs=similarity_search_input
)
retrieved = ["Test Result"]
# You must explicitly end the span
mlflow_client.end_span(request_id, span_id=span_ss.span_id, outputs=retrieved)
root_span.end_trace(request_id, outputs={"output": retrieved})
Revisão de vestígios
Para revisar os rastreamentos depois de executar o agente, use uma das seguintes opções:
- A visualização de rastreamento é renderizada embutida na saída da célula.
- Os rastreamentos são registrados em seu experimento MLflow. Pode rever e pesquisar a lista completa de vestígios históricos no separador Traces na página Experiment. Quando o agente é executado numa Execução ativa do MLflow, os rastros aparecem na página Executar.
- Recupere rastreamentos programaticamente usando a API search_traces( ).
Usar o MLflow Tracing na produção
O MLflow Tracing também é integrado ao Mosaic AI Model Serving, permitindo depurar problemas de forma eficiente, monitorar o desempenho e criar um conjunto de dados dourado para avaliação offline. Quando o MLflow Tracing está ativado para o seu ponto de extremidade de serviço, os rastreamentos são registrados numa tabela de inferência de na coluna response.
Você pode visualizar os rastreamentos que são registrados em tabelas de inferência consultando a tabela e exibindo os resultados em um bloco de anotações. Utilize display(<the request logs table>) no seu bloco de notas e selecione as linhas individuais dos rastreios que pretende visualizar.
Para habilitar o MLflow Tracing para seu ponto de extremidade de serviço, você deve definir a variável de ambiente ENABLE_MLFLOW_TRACING na configuração do ponto de extremidade como True. Para saber como implantar um endpoint com variáveis de ambiente personalizadas, consulte Adicionar variáveis de ambiente de texto simples. Se você implantou seu agente usando a API do deploy(), os rastreamentos serão automaticamente registrados em uma tabela de inferência. Consulte Implantar um agente para aplicativo de IA generativa.
Nota
A gravação de rastreamentos numa tabela de inferências é feita de forma assíncrona, por isso não gera a mesma sobrecarga que no ambiente de notebook durante o desenvolvimento. No entanto, ele ainda pode introduzir alguma sobrecarga na velocidade de resposta do ponto de extremidade, particularmente quando o tamanho do rastreamento para cada solicitação de inferência é grande. O Databricks não garante nenhum contrato de nível de serviço (SLA) para o impacto real da latência no endpoint do modelo, pois depende muito do ambiente e da implementação do modelo. O Databricks recomenda testar o desempenho do endpoint e obter informações sobre a sobrecarga de rastreamento antes de implantar em um aplicativo de produção.
A tabela a seguir fornece uma indicação aproximada do impacto na latência de inferência para diferentes tamanhos de rastreamento.
| Tamanho do rastreamento por solicitação | Impacto na latência (ms) |
|---|---|
| ~10 KB | ~ 1 ms |
| ~ 1 MB | 50 ~ 100 ms |
| 10 MB | 150 ms ~ |
Limitações
- O MLflow Tracing está disponível em notebooks Databricks, trabalhos de notebook e Model Serving.
O registro automático do LangChain pode não suportar todas as APIs de previsão do LangChain. Para obter a lista completa de APIs suportadas, consulte documentação do MLflow.