Solucionar problemas de soluções de dados de serviços de saúde no Microsoft Fabric
Este artigo fornece informações sobre alguns problemas ou erros que você pode ver ao usar as soluções de dados de serviços de saúde no Microsoft Fabric e como resolvê-los. O artigo também inclui algumas orientações de monitoramento de aplicativos.
Se o problema persistir depois de seguir as orientações neste artigo, crie um tíquete de incidente para a equipe de suporte.
Solucionar problemas de implantação
Às vezes, você pode encontrar problemas intermitentes ao implantar soluções de dados de serviços de saúde no espaço de trabalho do Fabric. Veja alguns problemas comumente observados e soluções alternativas para corrigi-los:
Há falha na criação da solução ou demora muito.
Erro: a criação da soluções de dados de serviços de saúde está em andamento há mais de cinco minutos e/ou tem falha.
Causa: esse erro ocorre se houver outra solução de dados de serviços de saúde que compartilha o mesmo nome ou foi excluída recentemente.
Resolução: se você excluiu uma solução recentemente, aguarde de 30 a 60 minutos antes de tentar outra implantação.
Falha na implantação do recurso.
Erro: falha na implantação de recursos nas soluções de dados de serviços de saúde.
Resolução: verifique se o recurso está listado na seção Gerenciar recursos implantados.
- Se o recurso não estiver listado na tabela, tente implantá-lo novamente. Selecione o bloco do recursos e, em seguida, selecione o botão Implantar no espaço de trabalho.
- Se o recurso estiver listado na tabela com o valor de status Falha na implantação, reimplante o recurso. Como alternativa, você pode criar um ambiente de soluções de dados de serviços de saúde e reimplantar o recurso nele.
Solucionar problemas de tabelas não identificadas
Quando as tabelas delta são criadas no lakehouse pela primeira vez, elas podem aparecer temporariamente como "não identificadas" ou vazias na exibição do Explorador do Lakehouse. No entanto, elas devem aparecer corretamente na pasta de tabelas após alguns minutos.

Executar novamente o pipeline de dados
Para executar novamente os dados de exemplo de ponta a ponta, siga estas etapas:
Execute uma instrução do Spark SQL a partir de um notebook para excluir todas as tabelas de um lakehouse. Veja um exemplo:
lakehouse_name = "<lakehouse_name>" tables = spark.sql(f"SHOW TABLES IN {lakehouse_name}") for row in tables.collect(): spark.sql(f"DROP TABLE {lakehouse_name}.{row[1]}")Use o explorador de arquivos do OneLake para se conectar ao OneLake no Explorador de Arquivos do Windows.
Navegue até a pasta do espaço de trabalho no Explorador de Arquivos do Windows. Em
<solution_name>.HealthDataManager\DMHCheckpoint, exclua todas as pastas correspondentes em<lakehouse_id>/<table_name>. Como alternativa, você também pode usar Microsoft Spark Utilities (MSSparkUtils) para Fabric para excluir a pasta.Execute novamente os pipelines de dados, começando com a ingestão de dados clínicos no lakehouse bronze.
Monitorar aplicativos do Apache Spark com o Azure Log Analytics
Os logs de aplicativo do Apache Spark são enviados para uma instância do espaço de trabalho do Azure Log Analytics que você pode consultar. Use este exemplo de consulta do Kusto para filtrar os logs específicos para soluções de dados de serviços de saúde:
AppTraces
| where Properties['LoggerName'] contains "Healthcaredatasolutions"
or Properties['LoggerName'] contains "DMF"
or Properties['LoggerName'] contains "RMT"
| limit 1000
Os logs do console do notebook também registram a RunId de cada execução. Você pode usar esse valor para recuperar logs de uma execução específica, conforme mostrado na consulta de exemplo a seguir:
AppTraces
| where Properties['RunId'] == "<RunId>"
Para obter informações gerais de monitoramento, consulte Usar o Hub de Monitoramento do Fabric.
Usar o explorador de arquivos do OneLake
O aplicativo Explorador de arquivos do OneLake integra perfeitamente o OneLake com o explorador de arquivos do Windows. Você pode usar o explorador de arquivos do OneLake para exibir qualquer pasta ou arquivo implantado em seu espaço de trabalho do Fabric. Você também pode ver os dados de exemplo, arquivos e pastas do OneLake e os arquivos de ponto de verificação.
Usar o Gerenciador de Armazenamento do Azure
Você também pode usar o Gerenciador de Armazenamento do Azure para:
- Acesse os arquivos do OneLake em seus lakehouses do Fabric
- Conectar-se ao caminho do arquivo da URL do OneLake
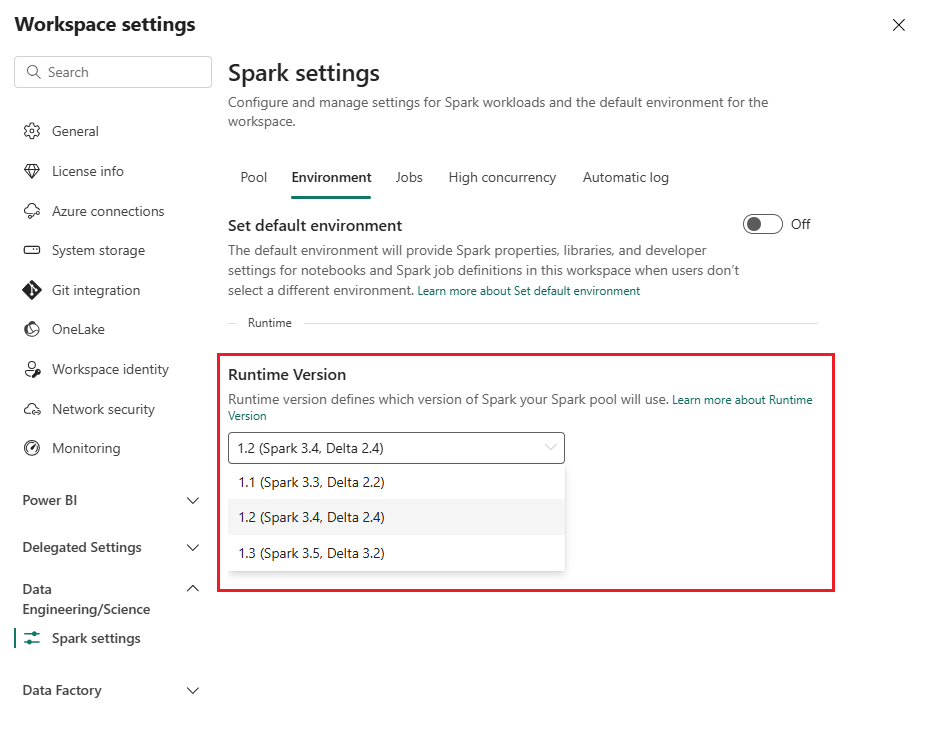
Redefinir a versão de runtime do Spark no espaço de trabalho do Fabric
Por padrão, todos os novos espaços de trabalho do Fabric usam a versão de runtime mais recente do Fabric, que atualmente é o Runtime 1.3. No entanto, as soluções de dados de serviços de saúde oferecem suporte somente ao Runtime 1.2.
Portanto, depois de implantar soluções de dados de serviços de saúde em seu espaço de trabalho, verifique se a versão de runtime padrão do Fabric está definida como Runtime 1.2 (Apache Spark 3.4 e Delta Lake 2.4). Caso contrário, as execuções do pipeline de dados e do notebook podem ter falha. Para obter mais informações, consulte Suporte a vários runtimes no Fabric.
Siga estas etapas para revisar/atualizar a versão de runtimes do Fabric:
Acesse o espaço de trabalho de soluções de dados de serviços de saúde e selecione Configurações do espaço de trabalho.
Na página de configurações do espaço de trabalho, expanda a caixa suspensa Engenharia/Ciência de Dados e selecione Configurações do Spark.
Na guia Ambiente, atualize o valor de Versão de Runtime para 1.2 (Spark 3.4, Delta 2.4) e salve as alterações.

Atualizar a interface do usuário do Fabric e o explorador de arquivos do OneLake
Às vezes, você pode notar que a interface do usuário do Fabric ou o explorador de arquivos do OneLake nem sempre atualiza o conteúdo após cada execução do notebook. Se você não vir o resultado esperado na interface do usuário após qualquer etapa de execução (como criar uma pasta ou lakehouse, ou ingerir novos dados em uma tabela), tente atualizar o artefato (tabela, lakehouse, pasta). Essa atualização geralmente pode resolver discrepâncias antes que você explore outras opções ou investigue mais.