Desempenho e solução de problemas para extração de dados SAP
Este artigo faz parte da série de artigos "Estender e inovar dados: práticas recomendadas" do SAP.
- Identificar fontes de dados SAP
- Escolha o melhor conector SAP
- Desempenho e solução de problemas para extração de dados SAP
- Segurança de integração de dados para SAP no Azure
- Arquitetura genérica de integração de dados do SAP
Há muitas maneiras de se conectar ao sistema SAP para integração de dados. As seções abaixo descrevem considerações e recomendações gerais e específicas do conector.
Desempenho
É importante definir as configurações ideais para a origem e o destino para que você possa obter o melhor desempenho durante a extração e o processamento de dados.
Considerações gerais
- Verifique se os parâmetros SAP corretos estão definidos para uma conexão simultânea máxima.
- Considere usar o tipo de logon do Grupo SAP para melhorar o desempenho e a distribuição de carga.
- Verifique se a máquina virtual SHIR (integration runtime) auto-hospedada é dimensionada adequadamente e está altamente disponível.
- Quando você trabalha com grandes conjuntos de dados, marcar se o conector que você está usando fornece uma funcionalidade de particionamento. Muitos dos conectores SAP dão suporte a recursos de particionamento e paralelização para acelerar as cargas de dados. Quando você usa esse método, os dados são empacotados em partes menores que podem ser carregadas usando vários processos paralelos. Para obter mais informações, consulte a documentação específica do conector.
Recomendações gerais
Use a transação SAP RZ12 para modificar valores para conexões simultâneas máximas.
Parâmetros SAP para RFC – RZ12: o parâmetro a seguir pode restringir o número de chamadas RFC permitidas para um usuário ou um aplicativo, portanto, verifique se essa restrição não está causando um gargalo.
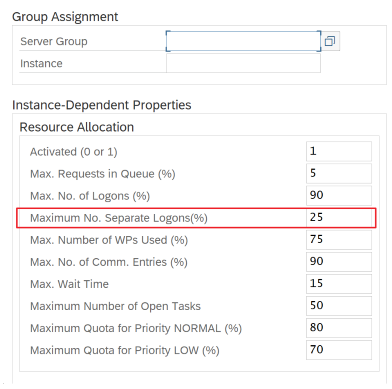

Conexão com o SAP usando o Grupo de Logon: O SHIR (runtime de integração auto-hospedada) deve se conectar ao SAP usando um Grupo de Logon do SAP (por meio do servidor de mensagens) e não a um servidor de aplicativos específico para garantir uma distribuição de carga de trabalho em todos os servidores de aplicativos disponíveis.
Observação
O cluster Spark de fluxo de dados e o SHIR são poderosos. Muitas atividades internas de cópia do SAP, por exemplo, 16, podem ser disparadas e executadas. Mas se o número de conexão simultânea do servidor SAP for pequeno, por exemplo, 8, o perf lerá os dados do lado do SAP.
Comece com VMs de 4vCPUs e 16 GB para SHIR. As etapas a seguir mostram a conexão do processo de trabalho da caixa de diálogo no SAP com o SHIR.
- Verifique se o cliente usa um computador físico ruim para configurar e instalar o SHIR para executar uma cópia interna do SAP.
- Vá para o portal de Azure Data Factory e localize o serviço vinculado sap CDC relacionado que é usado no fluxo de dados. Verifique o nome SHIR referenciado.
- Verifique as configurações de CPU, memória, rede e disco do computador físico em que o SHIR está instalado.
- Verifique quantos
diawp.exeestão em execução no computador SHIR. Édiawp.exepossível executar uma atividade de cópia. O número dediawp.exeé baseado nas configurações de CPU, memória, rede e disco do computador.
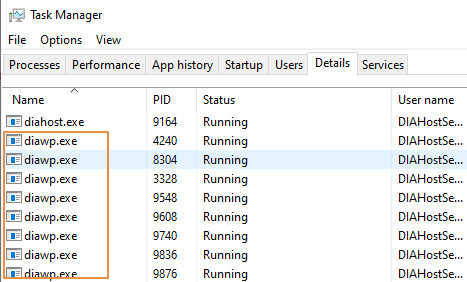
Se você quiser executar várias partições em paralelo no SHIR ao mesmo tempo, use uma máquina virtual poderosa para configurar o SHIR. Ou use escalar horizontalmente usando recursos de alta disponibilidade e escalabilidade do SHIR para ter vários nós. Para saber mais, confira Alta disponibilidade e escalabilidade.
Partições
A seção a seguir descreve o processo de particionamento para um conector SAP CDC. O processo é o mesmo para uma tabela SAP e um conector do SAP BW Open Hub.

O dimensionamento pode ser executado no IR auto-hospedado ou no IR do Azure, dependendo dos seus requisitos de desempenho. Examine o consumo de CPU do SHIR para exibir as métricas para ajudá-lo a decidir sobre sua abordagem de dimensionamento. O SHIR pode ser dimensionado vertical ou horizontalmente de acordo com suas necessidades. Recomendamos que você implante o IR do Azure em um SKU inferior. Escale verticalmente para atender aos seus requisitos de desempenho conforme determinado por meio do teste de carga, em vez de começar na extremidade superior desnecessariamente.
Observação
Se você estiver atingindo 70% de capacidade, escale verticalmente ou escale verticalmente para SHIR.

O particionamento é útil para cargas completas iniciais ou grandes e normalmente não é necessário para cargas delta. Se você não especificar a partição, por padrão, 1 "produtor" no sistema SAP (normalmente um processo em lote) buscará os dados de origem na fila de dados operacional (ODQ) e o SHIR buscará os dados do ODQ. Por padrão, o SHIR usa quatro threads para buscar os dados do ODQ, portanto, potencialmente, quatro processos de caixa de diálogo são ocupados no SAP nesse momento.
A ideia do particionamento é dividir um grande conjunto de dados inicial em vários subconjuntos desarticulados menores que são idealmente iguais em tamanho e que podem ser processados em paralelo. Esse método reduz o tempo necessário para produzir os dados da tabela de origem para o ODQ de forma linear. Esse método pressupõe que haja recursos suficientes no lado do SAP para lidar com a carga.
Observação
- O número de partições executadas em paralelo é limitado pelo número de núcleos de driver no Azure IR. Uma resolução para essa limitação está em andamento no momento.
- Cada unidade ou pacote na transação SAP ODQMON é um único arquivo na pasta de preparo.
Considerações de design ao executar os pipelines usando CDC
Verifique o SAP para a duração do estágio.
Verifique o desempenho do runtime no coletor.
Considere usar o recurso de particionamento para melhorar o desempenho para obter uma melhor taxa de transferência.
Se a duração do sap para estágio for lenta, considere redimensionar o SHIR para especificações mais altas.
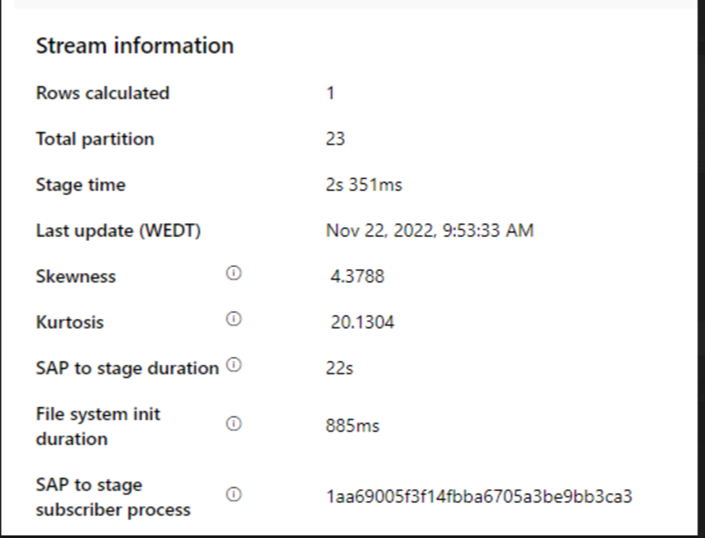
Verifique se o tempo de processamento do coletor está muito lento.
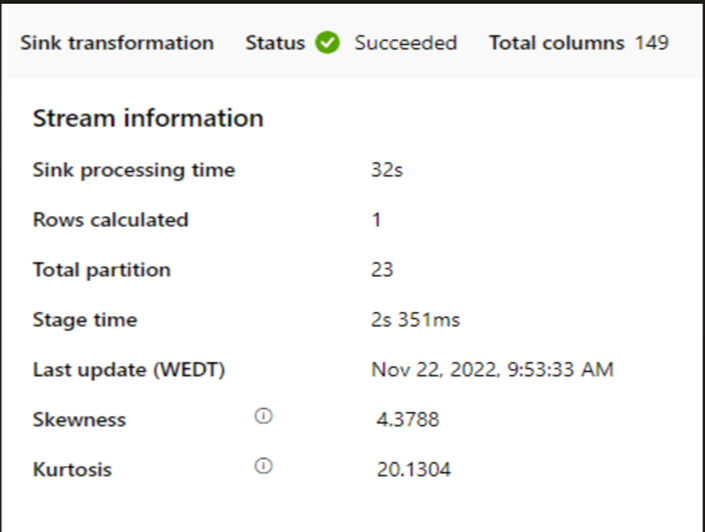
Se um cluster pequeno for usado para executar o fluxo de dados de mapeamento, isso poderá afetar o desempenho no coletor. Use um cluster grande, por exemplo, 16 + 256 núcleos, para que o perf leia os dados do estágio e grave no coletor.
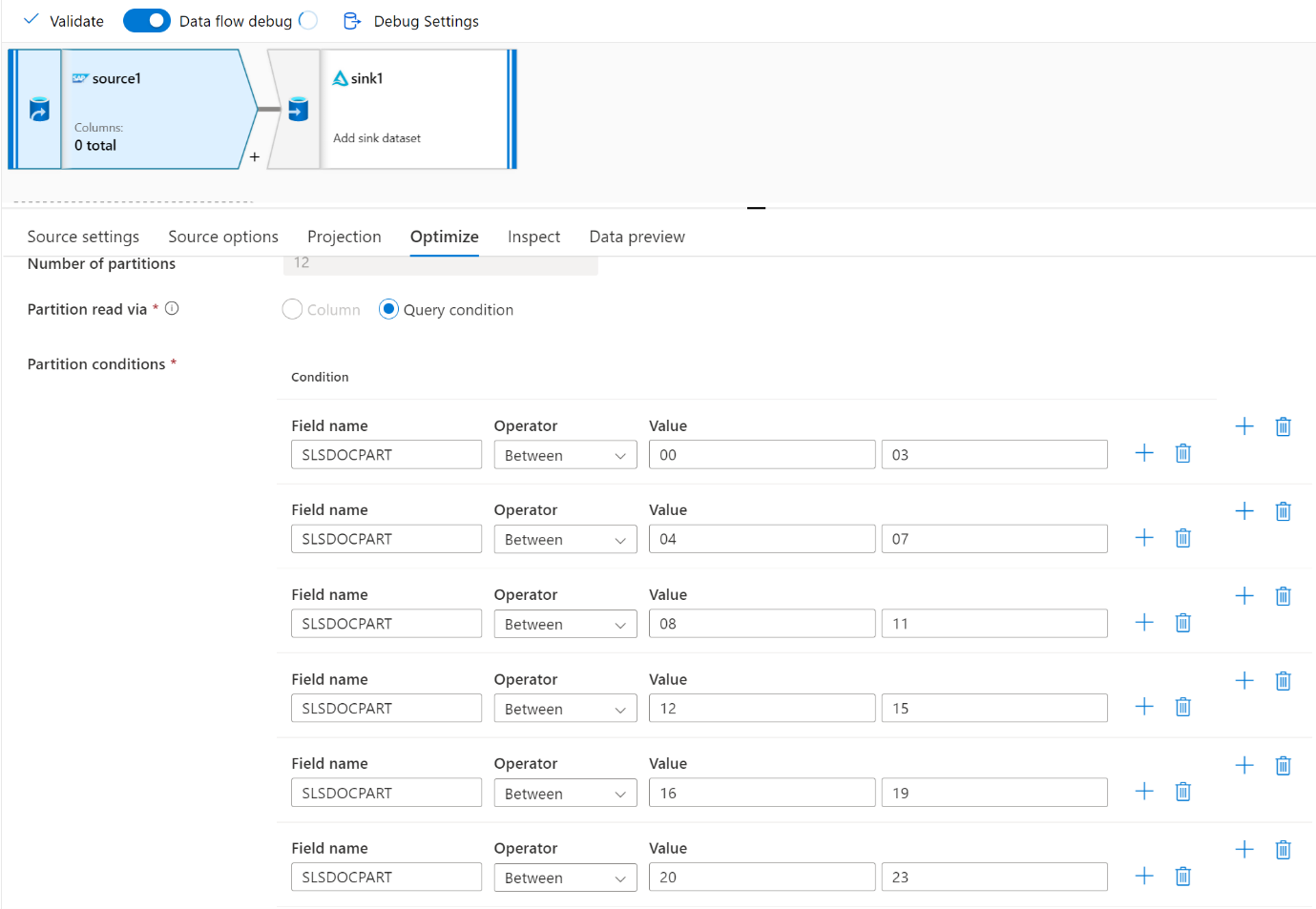
Para grandes volumes de dados, recomendamos particionar a carga para executar trabalhos paralelos, mas manter o número de partições menor ou igual ao núcleo do IR do Azure, também chamado de núcleo de cluster do Spark.
Use a guia Otimizar para definir as partições. Você pode usar o particionamento de origem no conector CDC.
Observação
- Há uma correlação direta entre o número de partições com núcleos SHIR e nós de IR do Azure.
- O conector SAP CDC é listado como o tipo de assinante Odata "Acesso Odata para Provisionamento de Dados Operacionais" em ODQMON no sistema SAP.
Considerações de design ao usar um conector de tabela
- Otimize o particionamento para melhor desempenho.
- Considere o grau de paralelismo da tabela SAP.
- Considere um único design de arquivo para o coletor de destino.
- Faça o benchmark da taxa de transferência ao usar grandes volumes de dados.
Recomendações de design ao usar um conector de tabela
Partição: Quando você particiona no conector de Tabela SAP, ela divide uma instrução select subjacente em várias usando onde as cláusulas estão em um campo adequado, por exemplo, um campo com alta cardinalidade. Se a tabela SAP tiver um grande volume de dados, habilite o particionamento para dividir os dados em partições menores. Tente otimizar o número de partições (parâmetro
maxPartitionsNumber) para que as partições sejam pequenas o suficiente para evitar despejos de memória no SAP, mas grandes o suficiente para acelerar a extração.Paralelismo: O grau de paralelismo de cópia (parâmetro
parallelCopies) funciona em conjunto com o particionamento e instrui o SHIR a fazer chamadas RFC paralelas para o sistema SAP. Por exemplo, se você definir esse parâmetro como 4, o serviço gerará e executará simultaneamente quatro consultas com base na opção e nas configurações de partição especificadas. Cada consulta recupera uma parte dos dados da tabela SAP.Para obter resultados ideais, o número de partições deve ser um múltiplo do número do grau de paralelismo de cópia.
Quando você copia dados da Tabela SAP para coletores binários, a contagem paralela real é ajustada automaticamente com base na quantidade de memória disponível no SHIR. Registre o tamanho da VM SHIR para cada ciclo de teste, o grau de paralelismo de cópia e o número de partições. Observe o desempenho da VM SHIR, o desempenho do sistema SAP de origem e o desejado versus o grau real de paralelismo. Use um processo iterativo para identificar as configurações ideais e o tamanho ideal para a VM SHIR. Considere todos os pipelines de ingestão que carregam dados simultaneamente de um ou vários sistemas SAP.
Observe o número observado de chamadas RFC para SAP em relação ao grau de paralelismo configurado. Se o número de chamadas RFC para SAP for menor que o grau de paralelismo, verifique se a VM SHIR tem memória suficiente e recursos de CPU disponíveis. Escolha uma máquina virtual maior, se necessário. O sistema SAP de origem é configurado para limitar o número de conexões paralelas. Para obter mais informações, consulte a seção Recomendações gerais neste artigo.
Número de arquivos: Quando você copia dados em um armazenamento de dados baseado em arquivo e o coletor de destino é configurado para ser uma pasta, vários arquivos são gerados por padrão. Se você definir a
fileNamepropriedade no coletor, os dados serão gravados em um único arquivo. É recomendável que você grave em uma pasta como vários arquivos porque ela obtém uma taxa de transferência de gravação mais alta em comparação com a gravação em um único arquivo.Parâmetro de comparação de desempenho: É recomendável usar o exercício de benchmarking de desempenho para ingerir grandes quantidades de dados. Esse método varia parâmetros, como particionamento, grau de paralelismo e o número de arquivos para determinar a configuração ideal para a arquitetura, volume e tipo de dados fornecidos. Colete dados de testes no formato a seguir.


Solução de problemas
Para extração lenta ou com falha do sistema SAP, use logs SAP do SM37 e corresponda-os às leituras no Data Factory.
Se apenas um trabalho em lote for disparado, defina as partições de origem sap para que tenham melhoria de desempenho no fluxo de dados de mapeamento no Data Factory. Para obter mais informações, confira a etapa 6 em Mapear propriedades de fluxo de dados.
Se vários trabalhos em lotes forem disparados no sistema SAP e houver uma diferença significativa entre a hora de início de cada trabalho em lote, altere o tamanho do IR do Azure. Quando você aumenta o número de nós de driver no Azure IR, o paralelismo de trabalhos em lote no lado do SAP aumenta.
Observação
O número máximo de nós de driver para o Azure IR é 16. Cada nó de driver só pode disparar um processo em lote.
Verifique os logs no SHIR. Para exibir logs, acesse VM SHIR. Abra Aplicativos do Visualizador > de Eventos e logs > de serviço Runtime de integração de conectores > .
Para enviar logs para o suporte, acesse VM SHIR. Abra os logs de envio de diagnóstico > do gerenciador de configuração > do Integration Runtime. Essa ação envia os logs dos últimos sete dias e fornece uma ID de relatório. Você precisa dessa ID de relatório e runId da sua execução. Documente a ID do relatório para referência futura.
Quando você usa o conector SAP CDC em um cenário de SLT:
Verifique se os pré-requisitos foram atendidos. As funções são necessárias para que o usuário do SAP Landscape Transformation (SLT), por exemplo, ADFSLTUSER em sistemas OLTP ou replicação ECC for SLT funcione. Para obter mais informações, consulte Quais autorizações e funções são necessárias.
Se ocorrerem erros em um cenário de SLT, consulte as recomendações para análise. Isolar e testar o cenário dentro da solução SAP primeiro. Por exemplo, teste-o fora do Data Factory executando o programa de teste fornecido pelo SAP
RODPS_REPL_TESTno SE38. Se o problema estiver no lado do SAP, você receberá o mesmo erro ao usar o relatório. Você pode analisar a extração de dados no SAP usando o códigoODQMONde transação .Se a replicação funcionar quando você usar esse relatório de teste, mas não com o Data Factory, entre em contato com o suporte do Azure ou do Data Factory.
O exemplo a seguir mostra um relatório para
RODPS_REPL_TESTno SE38: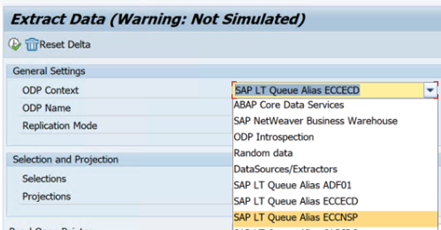
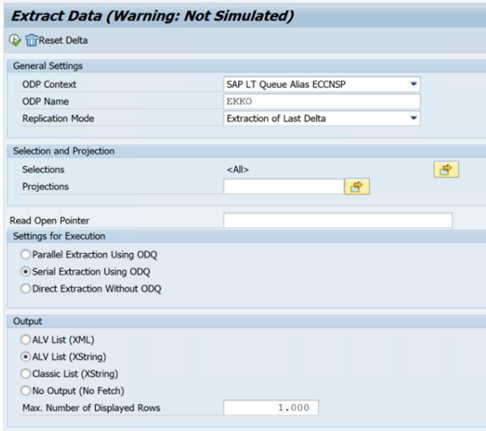

O exemplo a seguir mostra o código
ODQMONda transação :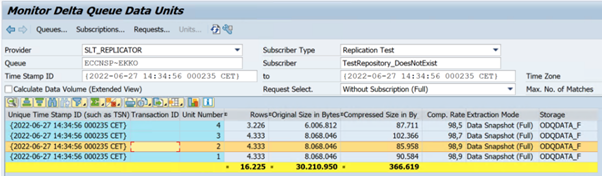
Quando o serviço vinculado do Data Factory se conecta ao sistema SLT, ele não mostra as IDs de transferência em massa SLT quando você atualiza o campo Contexto .
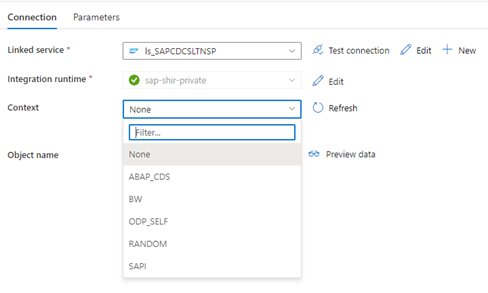
Para executar o cenário de replicação ODP/ODQ para o Servidor de Replicação SAP LT, ative a seguinte implementação de suplemento comercial (BAdI).
Badi:
BADI_ODQ_QUEUE_MODELImplementação de aprimoramento:
ODQ_ENH_SLT_REPLICATIONNa transação LTRC, vá para a guia Função Especialista e selecione Ativar/Desativar Implementação de BAdI para ativar a implementação.
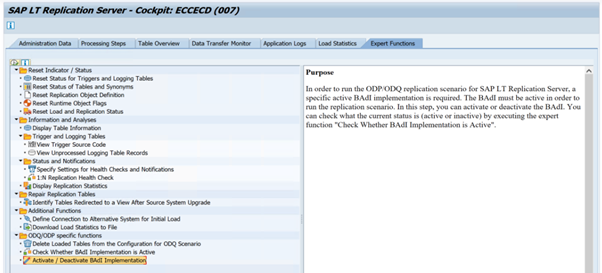
Selecione Sim.
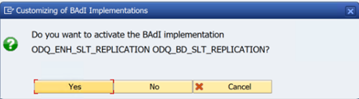
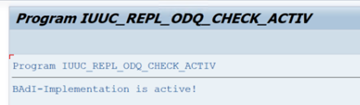
Na pasta funções específicas do ODQ/ODP , selecione Verificar se a implementação do BAdI está ativa.

A caixa de diálogo mostra a atividade do programa.
Redefinir assinaturas. Para começar com uma nova extração ou interromper os dados de replicação, remova a assinatura no ODQMON. Essa ação também remove entradas do LTRC. Depois de redefinir a assinatura, pode levar alguns minutos até que você veja o efeito no LTRC. Agendar trabalhos de limpeza do ODP (Provisionamento de Dados Operacionais) para manter as filas delta limpo, por exemplo
ODQ_CLEANUP_CLIENT_004CDS_VIEW (transação DHCDCMON). A partir do S/4HANA 1909, o SAP replica dados de exibições de CDS que usam gatilhos baseados em dados em vez de colunas de data. O conceito é semelhante ao SLT, mas em vez de usar a transação LTRC para monitorá-lo, você usa a transação DHCDCMON.
Solução de problemas de SLT
O Servidor de Replicação de SLT fornece replicação de dados em tempo real de fontes SAP e/ou fontes não SAP para destinos SAP e/ou destinos não SAP. Há três tipos de conjuntos de ferramentas para monitorar a extração do SLT para o Azure.
- ODQMON é a ferramenta de monitoramento geral para extração de dados. Inicie a análise com o ODQMON para acompanhar inconsistências de dados, análise de desempenho inicial e solicitações de assinatura e extração abertas.
- LTRC é a transação a ser usada para marcar análise de desempenho. Será útil se você tiver problemas de replicação de dados do sistema de origem para o ODP, pois poderá monitorar o fluxo de dados e encontrar inconsistências.
- O SM37 fornece monitoramento detalhado de cada etapa de extração de SLT.
A limpeza normal deve ser feita usando o ODQMON em que você pode gerenciar a assinatura diretamente e não deve usar LTRC para o mesmo.
Você pode encontrar problemas ao extrair dados do SLT, como:
A extração não é executada. Verifique se a conexão SAP CDC criou uma conexão no ODQMON e marcar se a assinatura existe.
Inconsistências de dados. Verifique o ODQMON para ver a solicitação individual de dados e confirme se você pode ver os dados lá. Se você puder ver os dados no ODQMON, mas não no Azure Synapse ou no Data Factory, a investigação deverá ocorrer no lado do Azure. Se você não conseguir ver os dados no ODQMON, execute uma análise da estrutura SLT usando LTRC.
Problemas de desempenho. A extração de dados é uma abordagem de duas etapas. Primeiro, o SLT lê dados do sistema de origem e os transfere para o ODP. Em segundo lugar, o conector SAP CDC coleta os dados do ODP e os transfere para o armazenamento de dados escolhido. A transação LTRC permite analisar a primeira parte do processo de extração. Para analisar a extração de dados do ODP para o Azure, use as ferramentas de monitoramento do ODQMON e do Data Factory ou do Synapse.
Observação
Para obter mais informações, consulte estes recursos:
Desempenho de SLT
No ODPSLT (modo de carga inicial), há três etapas para extrair dados do SLT para o ODP:
- Criar objetos de migração. Esse processo leva apenas alguns segundos.
- Acesse o cálculo do plano que divide a tabela de origem em partes menores. Esta etapa depende do modo de carga inicial que você seleciona durante a configuração do SLT e do tamanho da tabela. A opção otimizada para recursos é recomendada.
- A carga de dados transfere os dados do sistema de origem para o ODP.
Cada etapa é controlada pelos trabalhos em segundo plano. Você pode usar as transações SM37 e LTRC para monitorar a duração. Se o sistema estiver em uso excessivo, os trabalhos em segundo plano poderão ser iniciados mais tarde porque não há processos de trabalho em lotes gratuitos suficientes. Quando as tarefas estão ociosas, o desempenho sofre.
Se o cálculo do plano de acesso levar muito tempo e o modo de carga inicial estiver definido como "otimizado para desempenho", altere-o para "otimizado para recursos" e execute novamente a extração. Se a carga de dados levar muito tempo, aumente o número de threads paralelos na configuração.
Se você usar uma arquitetura autônoma para replicação SLT (servidor de replicação SLT dedicado), a taxa de transferência de rede entre o sistema de origem e o servidor de replicação poderá afetar o desempenho da extração.
Para replicação:
- Verifique se você tem trabalhos de transferência de dados suficientes que não estão reservados para a carga inicial.
- Verifique se você não tem um registro de tabela de log não processado nas estatísticas de carga.
- Verifique se a opção de replicação está definida como em tempo real.
As configurações avançadas de replicação estão disponíveis no LTRS. Para obter mais informações, consulte o guia de solução de problemas de SLT.
Diferentes versões do SAP têm interfaces de usuário LTRC diferentes. As capturas de tela a seguir mostram a mesma página para duas versões diferentes.
SAP S/4HANA:
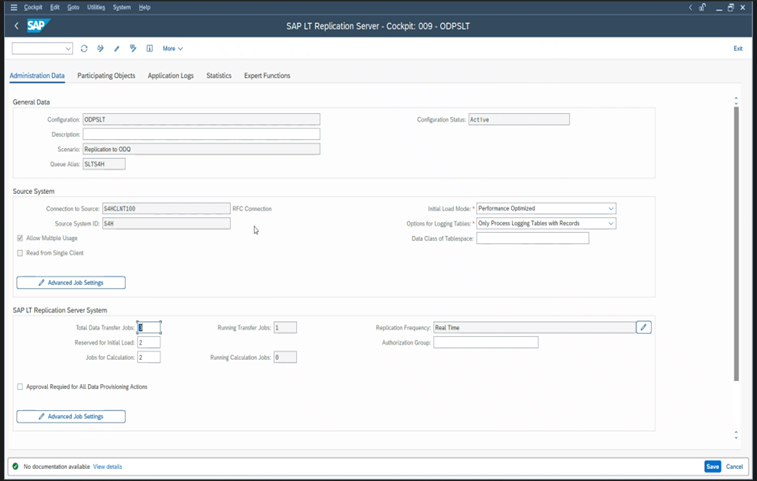
SAP ECC:
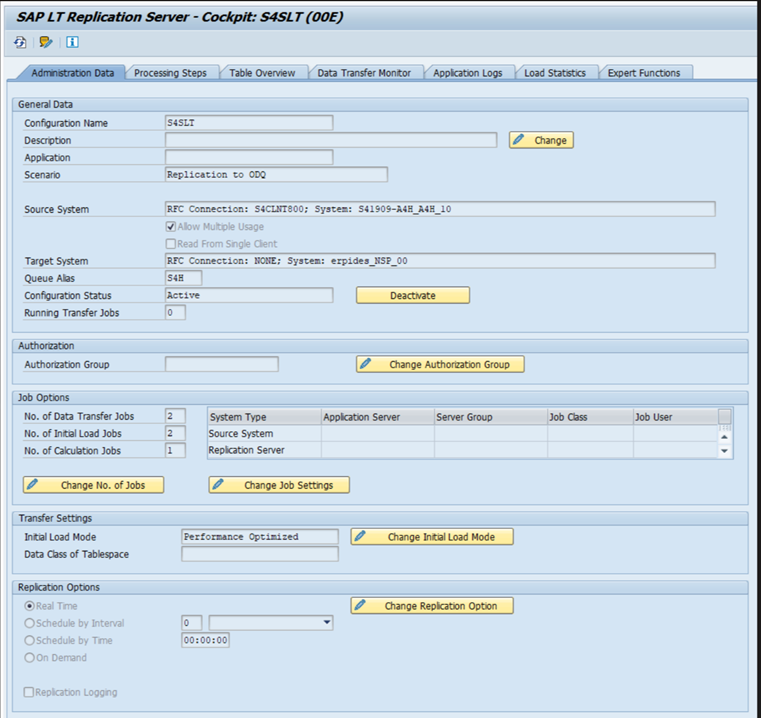


Monitor
Para obter informações sobre como monitorar a extração de dados SAP, consulte estes recursos: