Transformar dados de uma fonte SAP ODP usando o conector SAP CDC no Azure Data Factory ou no Azure Synapse Analytics
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dica
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange desde movimentação de dados até ciência de dados, análise em tempo real, business intelligence e relatórios. Saiba como iniciar uma avaliação gratuita!
Este artigo descreve como usar o fluxo de dados de mapeamento para transformar os dados de uma origem SAP ODP usando o conector SAP CDC. Para saber mais, leia o artigo introdutório do Azure Data Factory ou do Azure Synapse Analytics. Para obter uma introdução à transformação de dados com o Azure Data Factory e o Azure Synapse Analytics, leia o fluxo de dados de mapeamento ou o tutorial sobre fluxo de dados de mapeamento.
Dica
Para saber mais sobre o suporte geral no cenário de integração de dados do SAP, confira o artigo técnico Integração de dados do SAP usando o Azure Data Factory com introdução detalhada sobre cada conector SAP, comparações e orientações.
Funcionalidades com suporte
Há suporte para esse conector SAP CDC para as seguintes funcionalidades:
| Funcionalidades com suporte | IR |
|---|---|
| Fluxo de dados de mapeamento (origem/-) | ①, ② |
① Runtime de integração do Azure ② Runtime de integração auto-hospedada
Esse conector SAP CDC usa a estrutura de SAP ODP para extrair os dados de sistemas de origem SAP. Para obter uma introdução à arquitetura da solução, leia Introdução e arquitetura para CDC (captura de dados de alterações) SAP em nosso Centro de conhecimento SAP.
A estrutura SAP ODP está contida em todos os sistemas atualizados baseados em SAP NetWeaver, incluindo SAP ECC, SAP S/4HANA, SAP BW, SAP BW/4HANA, SAP LT Replication Server (SLT). Para obter os pré-requisitos e as versões mínimas necessárias, consulte Pré-requisitos e configurações.
O conector SAP CDC dará suporte para autenticação básica ou SNC (Comunicações de Redes Seguras), se o SNC estiver configurado. Para obter mais informações sobre o SNC, veja Introdução ao SAP SNC para integrações RFC – blog do SAP.
Limitações atuais
Aqui estão as limitações atuais do conector de CDA da SAP no Data Factory:
- Você pode redefinir ou deletar a assinatura ODQ no Data Factory (use a transação ODQMON no sistema SAP conectado para essa finalidade).
- Você não pode usar hierarquias SAP com a solução.
Pré-requisitos
Para usar esse conector SAP CDC, consulte Pré-requisitos e configuração para o conector SAP CDC.
Introdução
Para executar a atividade de Cópia com um pipeline, será possível usar as ferramentas ou os SDKs abaixo:
- A ferramenta Copiar Dados
- O portal do Azure
- O SDK do .NET
- O SDK do Python
- PowerShell do Azure
- A API REST
- O modelo do Azure Resource Manager
Criar um serviço vinculado para o conector SAP CDC usando a interface do usuário
Siga as etapas descritas em Preparar o serviço vinculado para SAP CDC para criar um serviço vinculado do conector SAP CDC na interface do usuário do portal do Azure.
Propriedades do conjunto de dados
Para preparar um conjunto de dados SAP CDC, siga Preparar o conjunto de dados de origem de SAP CDC.
Transformar dados com o conector SAP CDC
O feed de alterações bruto do SAP ODP é difícil de interpretar e atualizá-lo corretamente para um coletor pode ser um desafio. Por exemplo, atributos técnicos associados a cada linha (como ODQ_CHANGEMODE) precisam ser compreendidos para aplicar as alterações ao coletor corretamente. Além disso, um extrato de dados de alteração do ODP pode conter várias alterações na mesma chave (por exemplo, a mesma ordem de venda). Portanto, é importante respeitar a ordem das alterações e, ao mesmo tempo, otimizar o desempenho processando as alterações em paralelo. Além disso, o gerenciamento de um feed de captura de dados de alterações também requer o controle do estado, por exemplo, para fornecer mecanismos internos para recuperação de erros. Os fluxos de dados de mapeamento do Azure Data Factory cuidam de todos esses aspectos. Portanto, a conectividade do SAP CDC faz parte da experiência de fluxo de dados de mapeamento. Assim, os usuários podem se concentrar na lógica de transformação necessária sem precisar se preocupar com os detalhes técnicos da extração de dados.
Para começar, crie um pipeline com um fluxo de dados de mapeamento.
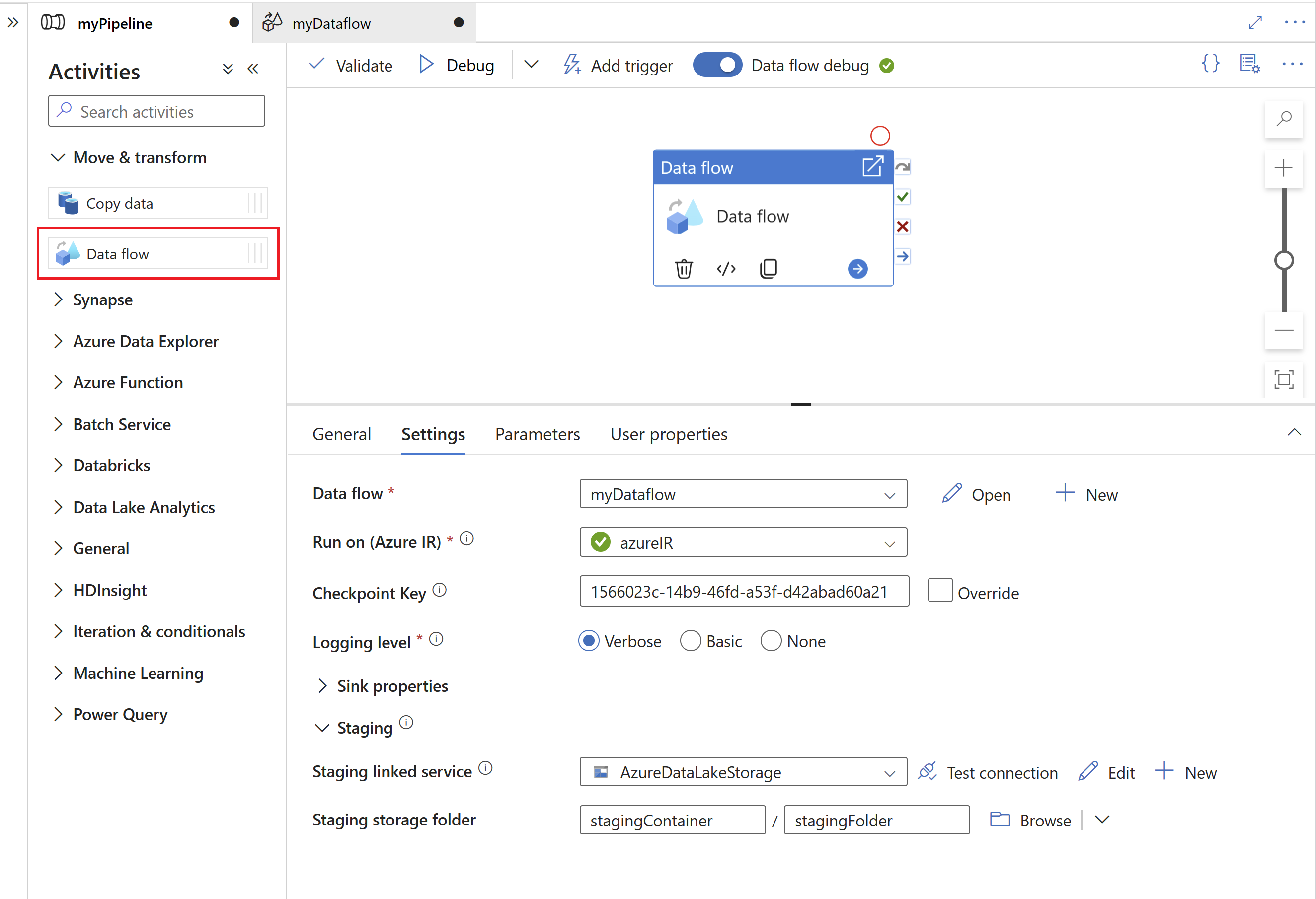
Em seguida, especifique um serviço vinculado de preparo e uma pasta de preparo no Azure Data Lake Gen2, que serve como um armazenamento intermediário para os dados extraídos do SAP.
Observação
- O serviço vinculado de preparo não pode usar um runtime de integração auto-hospedada.
- A pasta de preparo deve ser considerada um armazenamento interno do conector de CDA do SAP. Para otimizações adicionais do runtime de CDA do SAP, os detalhes da implementação, como o formato de arquivo usado para os dados de preparo, podem ser alterados. Portanto, recomendamos não usar a pasta de preparo para outras finalidades, por exemplo, como fonte para outras atividades de cópia ou fluxos de dados de mapeamento.
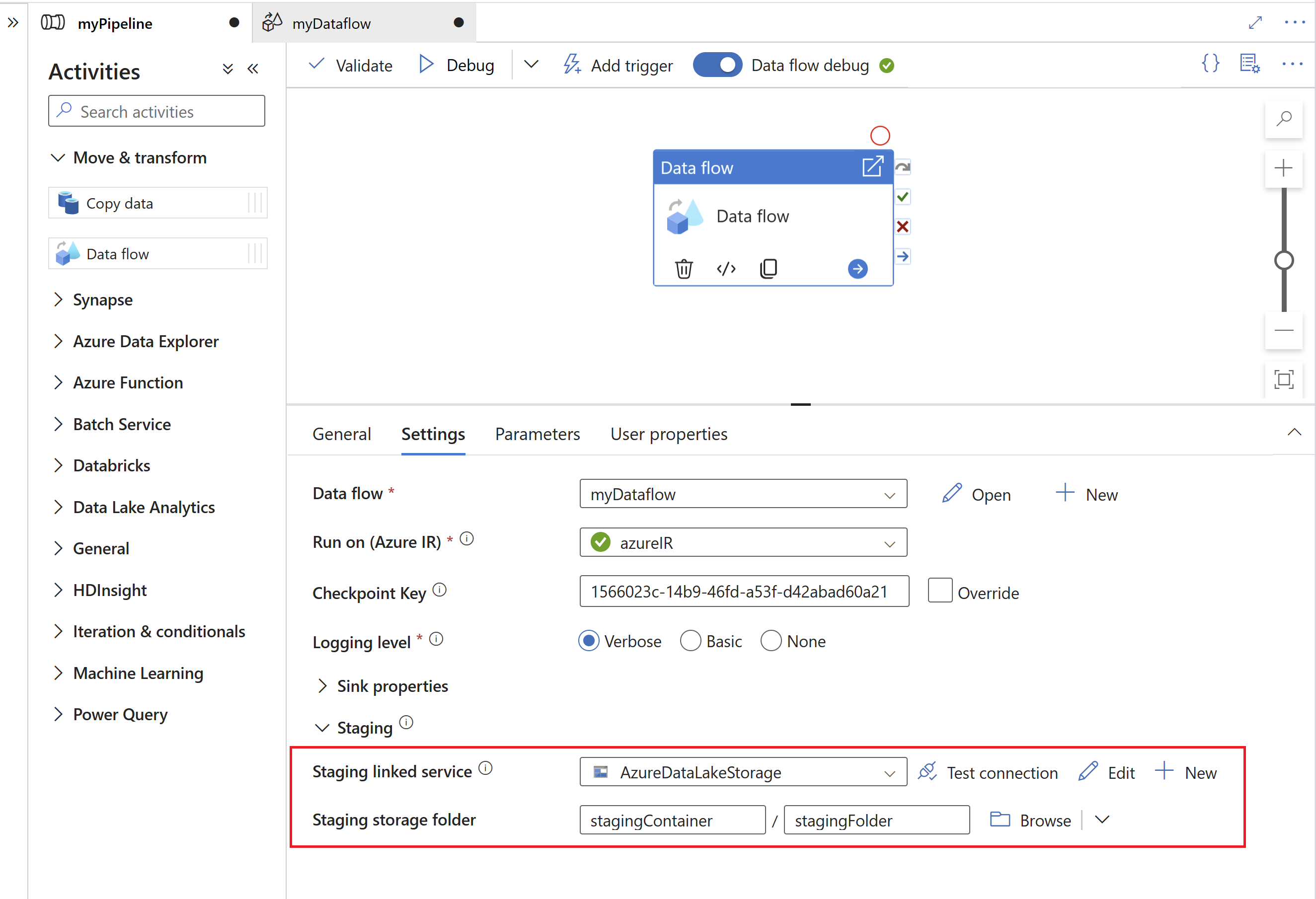
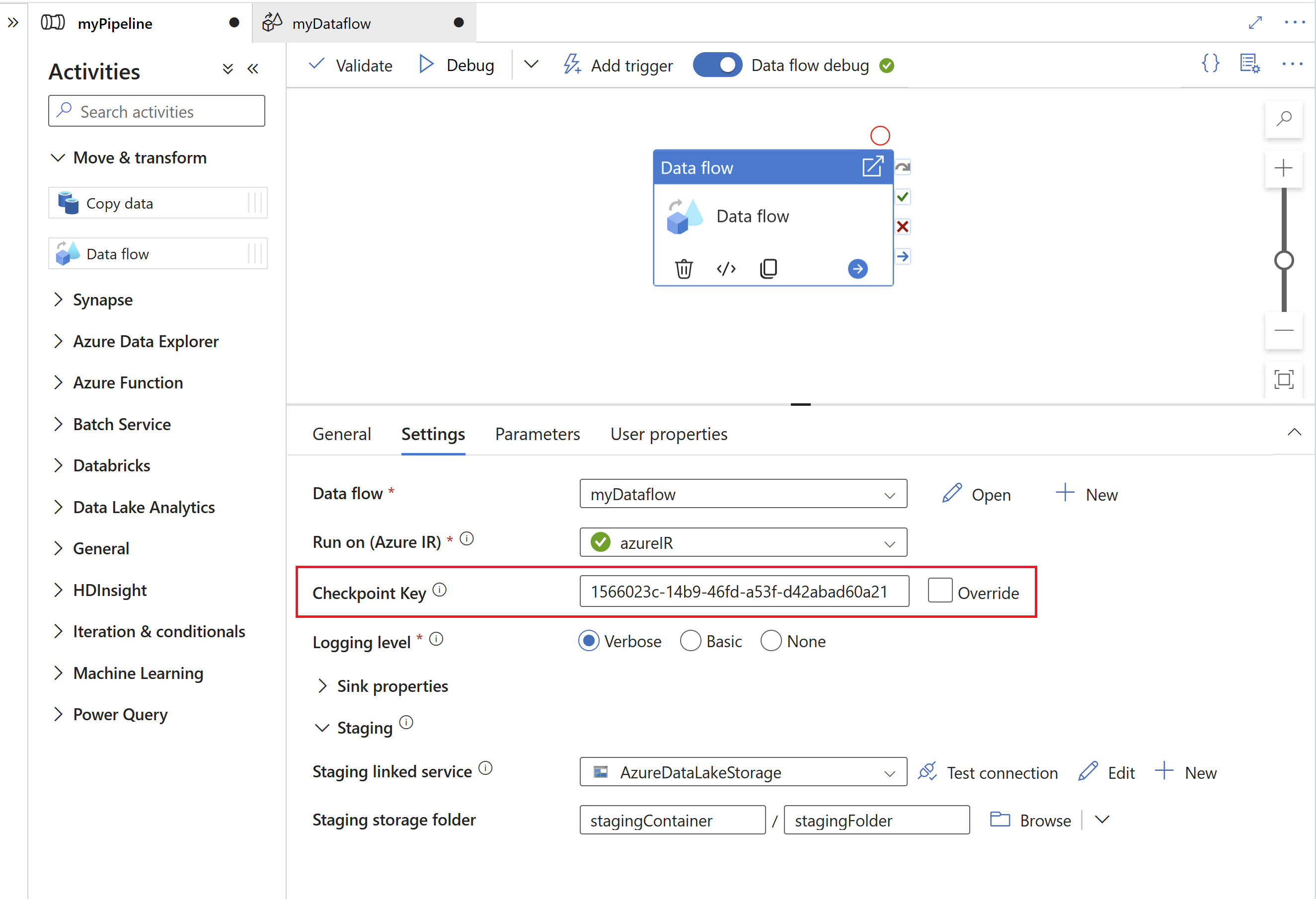
A Chave de ponto de verificação é usada pelo runtime da CDC do SAP para armazenar informações de status sobre o processo de captura de dados de alterações. Isso, por exemplo, permite que os fluxos de dados de mapeamento do SAP CDC se recuperem automaticamente de situações de erro ou saibam se um processo de captura de dados de alterações para um determinado fluxo de dados já foi estabelecido. Portanto, é importante usar uma chave de ponto de verificação exclusiva para cada origem. Caso contrário, informações de status de uma fonte serão substituídas por outra fonte.
Observação
- Para evitar conflitos, uma ID exclusiva é gerada como Chave de ponto de verificação por padrão.
- Ao usar parâmetros para aproveitar o mesmo fluxo de dados para várias fontes, certifique-se de parametrizar a Chave de ponto de verificação com valores exclusivos por origem.
- A propriedade Chave de ponto de verificação não será mostrada se o modo Executar dentro da origem da CDC do SAP estiver definido como Completo em cada execução (confira a próxima seção), pois, nesse caso, nenhum processo de captura de dados de alteração é estabelecido.
Chaves de ponto de verificação parametrizadas
As chaves de ponto de verificação são necessárias para gerenciar o status dos processos de captura de dados de alteração. Para um gerenciamento eficiente, você pode parametrizar a chave de ponto de verificação para permitir conexões com diferentes fontes. Veja como você pode implementar uma chave de ponto de verificação parametrizada:
Crie um parâmetro global para armazenar a chave do ponto de verificação no nível do pipeline para garantir a consistência entre as execuções:
"parameters": { "checkpointKey": { "type": "string", "defaultValue": "YourStaticCheckpointKey" } }Definir programaticamente a chave do ponto de verificação para invocar o pipeline com o valor desejado sempre que ele for executado. Aqui está um exemplo de uma chamada REST usando a chave de ponto de verificação parametrizada:
PUT https://management.azure.com/subscriptions/{subscriptionId}/resourceGroups/{resourceGroupName}/providers/Microsoft.DataFactory/factories/{factoryName}/pipelines/{pipelineName}?api-version=2018-06-01 Content-Type: application/json { "properties": { "activities": [ // Your activities here ], "parameters": { "checkpointKey": { "type": "String", "defaultValue": "YourStaticCheckpointKey" } } } }
Para obter informações mais detalhadas, consulte Tópicos avançados para o conector SAP CDC.
Propriedades do fluxo de dados de mapeamento
Para criar um fluxo de dados de mapeamento usando o conector SAP CDC como origem, conclua as etapas a seguir:
No ADF Studio, vá para a seção Fluxo de Dados do hub Autor, selecione o botão ... para abrir o menu Ações do fluxo de dados e selecione o item Novo fluxo de dados. Ative o modo de depuração usando o botão Depuração de fluxo de dados na barra superior da tela de fluxo de dados.
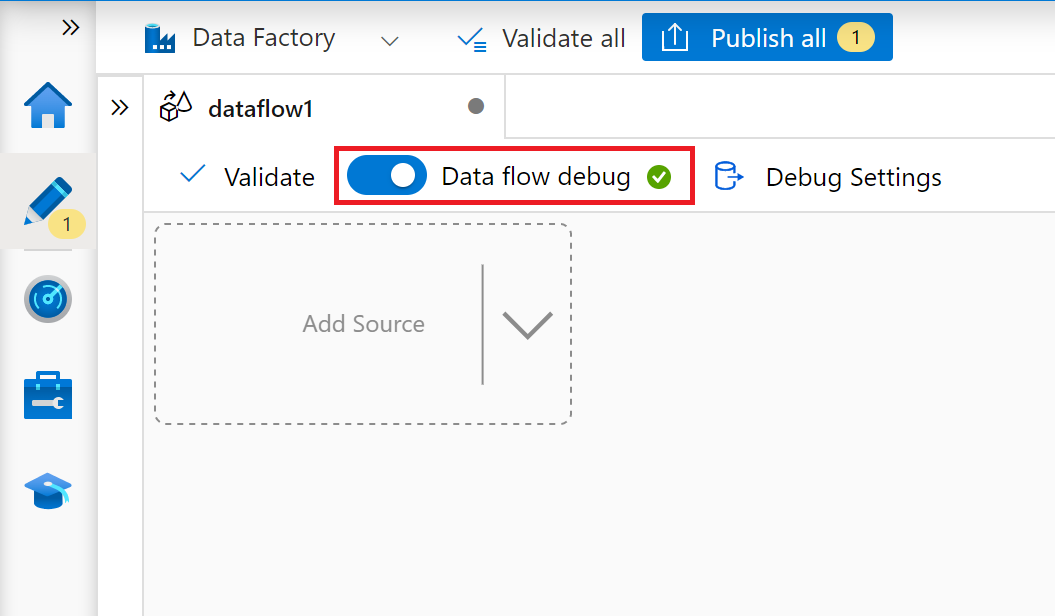
No editor de fluxo de dados de mapeamento, selecione Adicionar Origem.
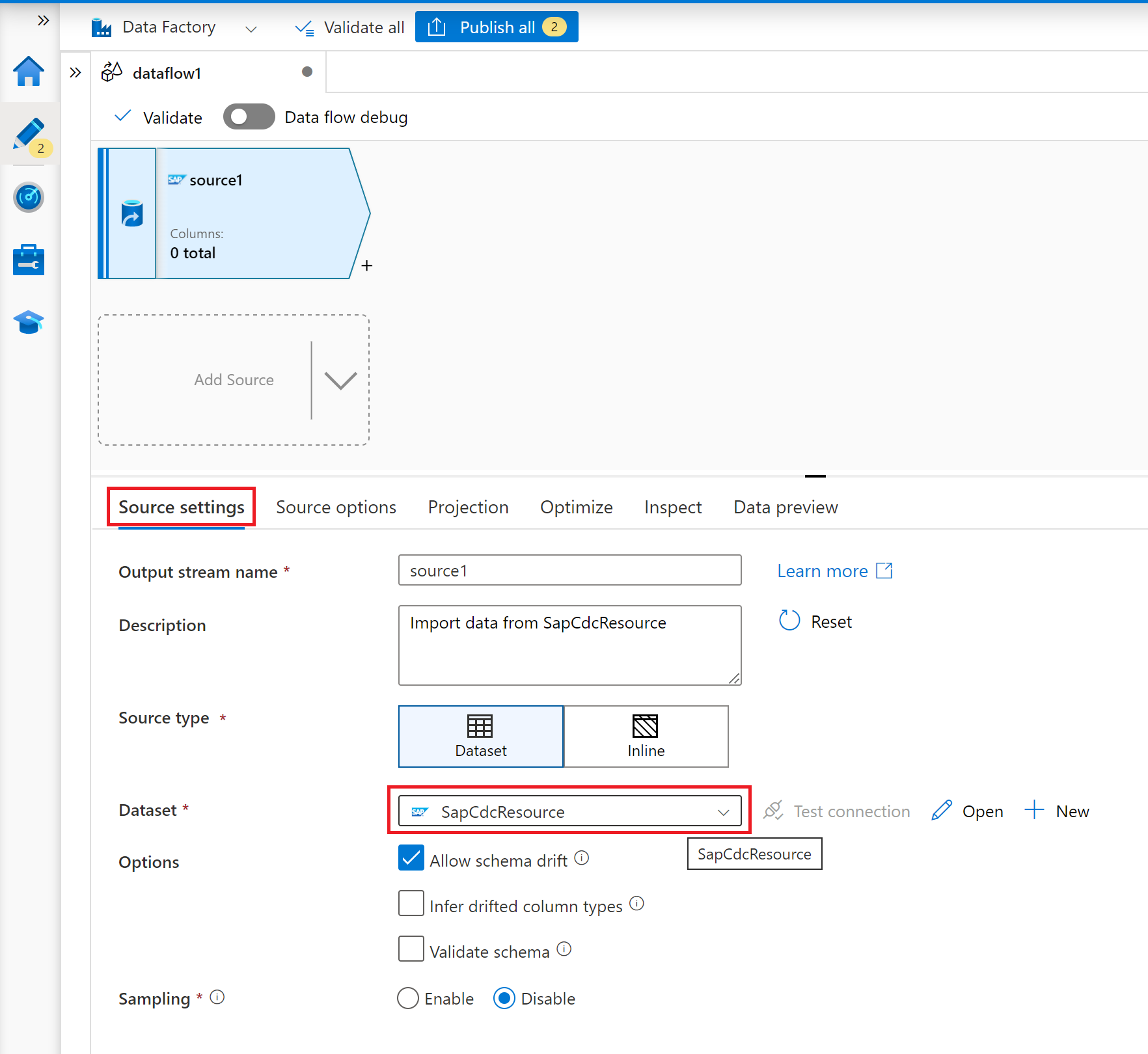
Na guia Configurações de origem, selecione um conjunto de dados SAP CDC preparado ou selecione o botão Novo para criar um novo. Como alternativa, também é possível selecionar Embutido na propriedade Tipo de origem e continuar sem definir um conjunto de dados explícito.
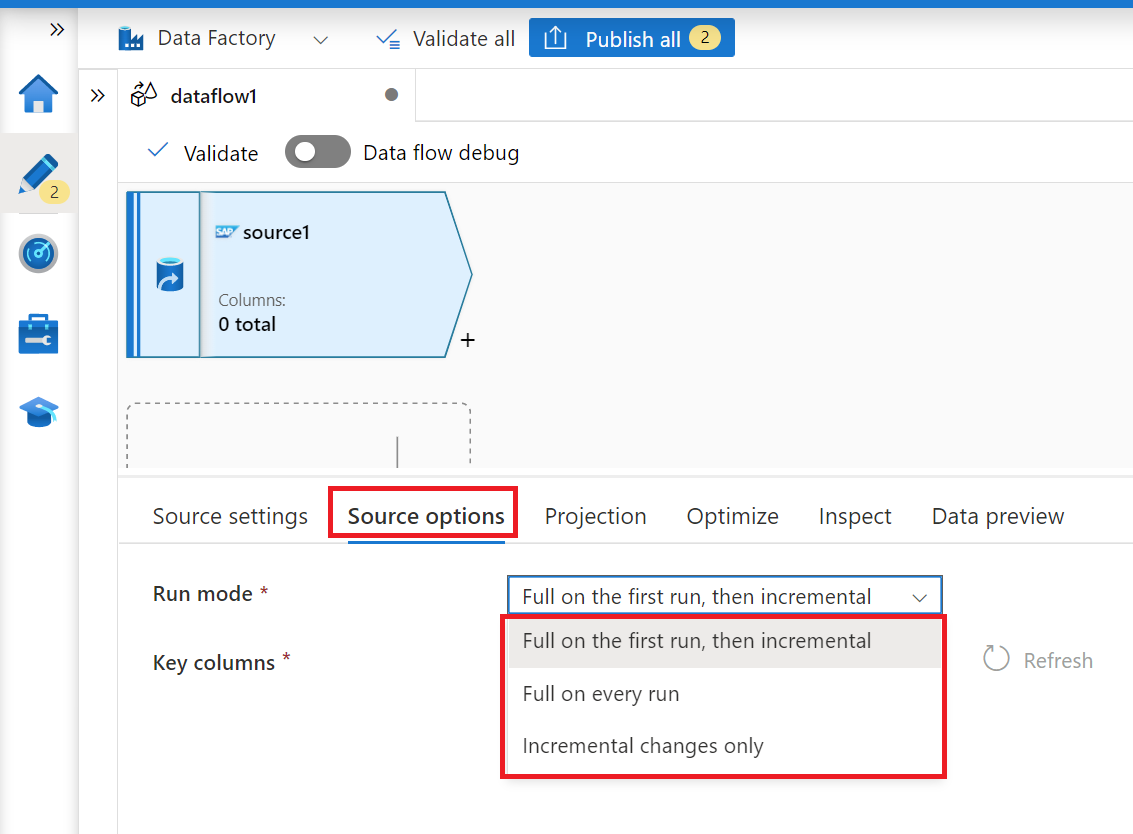
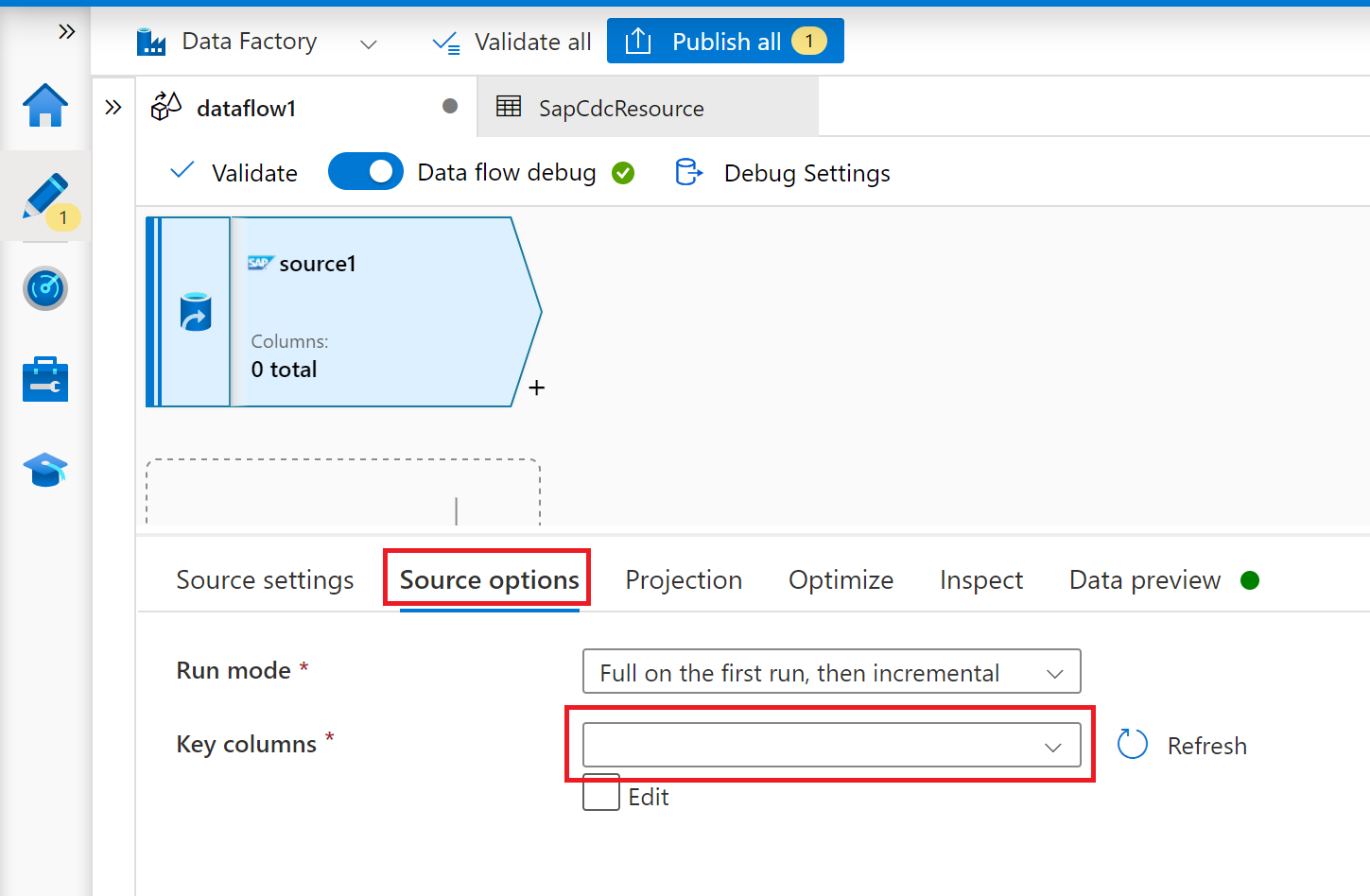
Na guia Opções de origem, selecione a opção Completo em todas as execuções se quiser carregar instantâneos completos em cada execução do fluxo de dados de mapeamento. Selecione Completo na primeira execução e, em seguida, incremental se você quiser assinar um feed de alterações do sistema de origem SAP, incluindo um instantâneo de dados completo inicial. Nesse caso, a primeira execução do pipeline executa uma inicialização delta, o que significa que ele cria uma assinatura delta ODP no sistema de origem e retorna um instantâneo de dados completo atual. As execuções de pipeline subsequentes retornam apenas alterações incrementais desde a execução anterior. A opção apenas alterações incrementais cria uma assinatura delta do ODP sem retornar um instantâneo de dados completo inicial na primeira execução. Novamente, as execuções subsequentes retornam alterações incrementais desde a execução anterior apenas. Ambas as opções de cargas incrementais requerem a especificação de chaves do objeto de origem ODP na propriedade Colunas de chaves.
Para as guias Projeção, Otimizar e Inspecionar, siga o fluxo de dados de mapeamento.
Otimizando o desempenho de cargas completas ou iniciais com particionamento de origem
Se o Modo de execução estiver definido como Completo em todas as execuções ou Completo na primeira execução e, em seguida, incremental, a guiaOtimizar oferecerá uma seleção e tipo de particionamento chamado Origem. Essa opção permite que você especifique várias condições de partição (ou seja, filtro) para dividir um conjunto de dados de origem grande em várias partes menores. Para cada partição, o conector SAP CDC dispara um processo de extração separado no sistema de origem SAP.
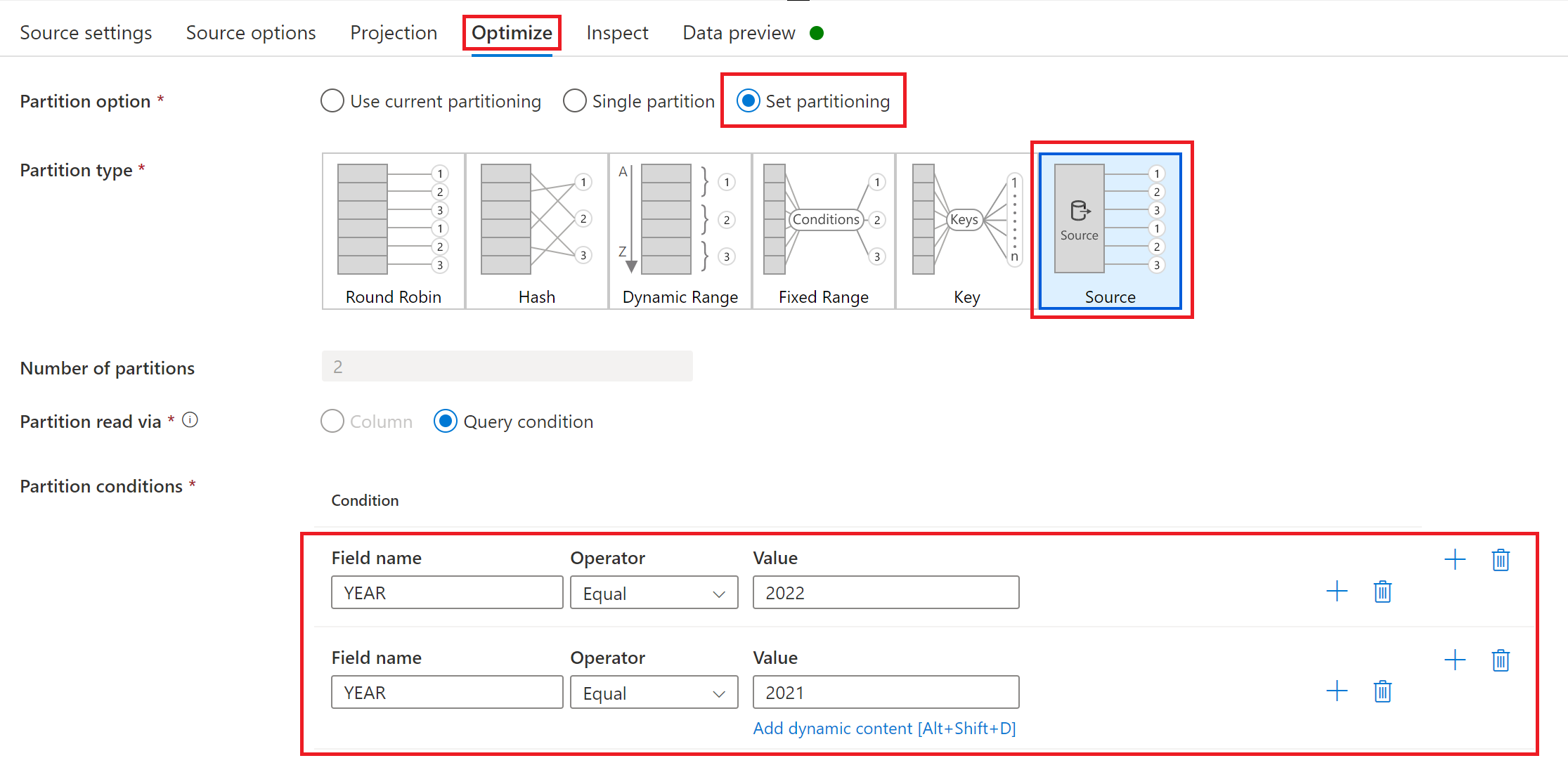
Se as partições forem igualmente dimensionadas, o particionamento de origem poderá aumentar linearmente a taxa de transferência da extração de dados. Para obter essas melhorias de desempenho, recursos suficientes são necessários no sistema de origem SAP, na máquina virtual que hospeda o runtime de integração auto-hospedada e no runtime de integração do Azure.