Wdrażanie i konfigurowanie z funkcji wzbogacania nieustrukturyzowanych notatek klinicznych (wersja zapoznawcza) w rozwiązaniach do obsługi danych medycznych
[Ten artykuł stanowi wstępną wersję dokumentacji i może ulec zmianie.]
Uwaga
Za wartość jest obecnie aktualizowana.
Wzbogacanie nieustrukturyzowanych notatek klinicznych (wersja zapoznawcza) używa usługi Text Analytics for Health Azure AI Language, aby wyodrębnić i dodać strukturę do nieustrukturyzowanych notatek klinicznych na potrzeby analizy. Możliwość można wdrożyć i skonfigurować po wdrożeniu rozwiązań do obsługi danych medycznych i funkcji podstawy danych medycznych w obszarze roboczym Fabric.
Wzbogacanie nieustrukturyzowanych notatek klinicznych (wersja zapoznawcza) jest opcjonalne w rozwiązaniach do obsługi danych medycznych w Microsoft Fabric. Masz swobodę decydowania, czy chcesz go używać, w zależności od konkretnych potrzeb lub scenariuszy.
Wymagania wstępne
- Wdrażanie rozwiązań do obsługi danych medycznych w programie Microsoft Fabric.
- Zainstaluj podstawowe notesy i potoki w temacie Wdrażanie podstaw danych medycznych.
Konfigurowanie usługi języka platformy Azure
Przejdź do portalu Azure Portal.
Na stronie głównej wybierz pozycję Utwórz zasób, wyszukaj pozycję Grupa zasobów i utwórz nową grupę zasobów Azure.
Upewnij się, że masz rolę kontroli dostępu na podstawie ról platformy Azure (RBAC) Właściciel lub Administrator dostępu użytkownika w grupie zasobów. Aby przypisać uprawnienia, wykonaj kroki opisane w temacie Udzielanie dostępu.
Po utworzeniu grupy zasobów wróć do strony głównej, wybierz pozycję Utwórz zasób, wyszukaj Usługę językową i wdróż nową usługę językową Azure w grupie zasobów. Użyj ustawień domyślnych.
Ważne
Wdrożenie usługi językowej wymaga zaakceptowania warunków Powiadomienia dotyczącego odpowiedzialnego AI w portalu Azure. Upewnij się, że zapoznano się z tymi warunkami podczas dodawania usługi językowej do grupy zasobów. Aby uzyskać więcej informacji, zobacz następujące uwagi dotyczące przejrzystości:
Wdrażanie wzbogacania notatek klinicznych bez struktury (wersja zapoznawcza)
Funkcję można wdrożyć przy użyciu modułu konfiguracji opisanego w temacie Rozwiązania do obsługi danych medycznych: wdrażanie podstaw danych opieki zdrowotnej. Na stronie ustawień podaj wartość Azure Key Vault, aby połączyć dane w magazynie kluczy.
Jeśli moduł instalacyjny nie został użyty do wdrożenia funkcji, a zamiast tego chcesz użyć kafelka funkcji, wykonaj następujące kroki:
Przejdź do strony głównej rozwiązań w zakresie danych opieki zdrowotnej w usłudze Fabric.
Wybierz kafelek wzbogacania notatek klinicznych bez struktury (wersja zapoznawcza).
Na stronie funkcji wybierz pozycję Wdróż w obszarze roboczym.
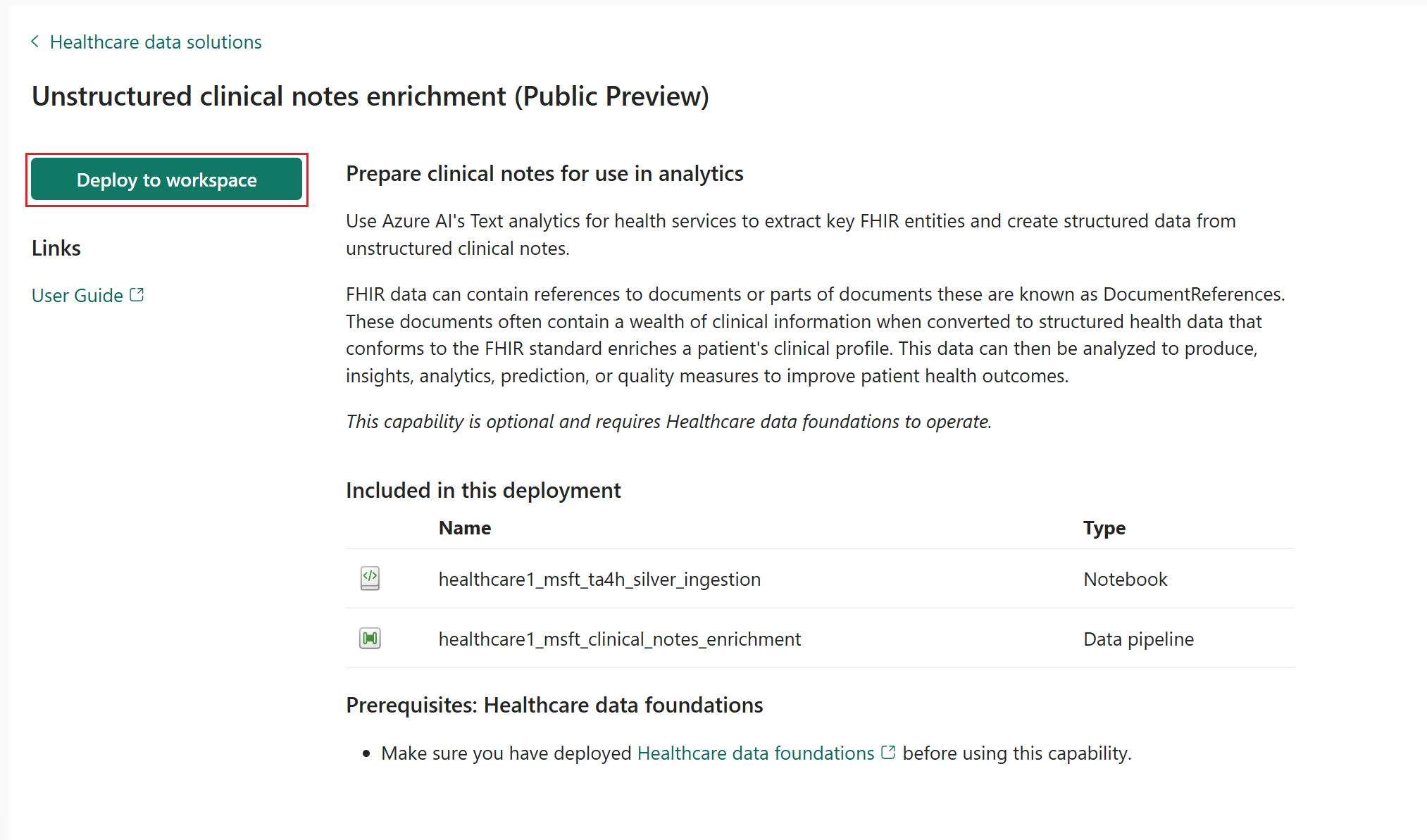
Zakończenie wdrożenia może potrwać kilka minut. Nie zamykaj karty ani przeglądarki, gdy wdrażanie jest w toku. Czekając, możesz pracować na innej karcie.
Po zakończeniu wdrażania na pasku komunikatów będzie widoczne powiadomienie.
Wybierz pozycję Zarządzaj możliwościami na pasku komunikatów, aby przejść do strony Zarządzanie możliwościami.
W tym miejscu można wyświetlać i konfigurować artefakty wdrożone za pomocą tej funkcji oraz zarządzać nimi.


Artefakty
Ta funkcja instaluje notes i potok danych w środowisku rozwiązań do obsługi danych medycznych.
| Artefakt | Type | Podpis |
|---|---|---|
| healthcare#_msft_ta4h_silver_ingestion | Notes | Używa interfejsu API Azure dla Text Analytics for Health NLP do przetwarzania i analizowania danych tekstowych bez struktury. |
| healthcare#_msft_clinical_notes_enrichment | Potok danych | Sekwencyjnie uruchamia serię notesów w celu wyodrębnienia kluczowych encji Fast Healthcare Interoperability Resources (FHIR) z nieustrukturyzowanych notatek klinicznych, ustrukturyzowania danych i przechowywania wyników w srebrnym magazynie lakehouse. |
Przejrzyj konfigurację notatnika
Notes healthcare#_msft_ta4h_silver_ingestion wykonuje moduł NLPIngestionService w bibliotece rozwiązań do obsługi danych medycznych w celu wywołania i używa usługi Azure Text Analytics for Health. Ta usługa to interfejs API przetwarzania języka naturalnego (NLP) służący do przetwarzania i analizowania nieustrukturyzowanych danych tekstowych. Wyniki są przechowywane w magazynie lakehouse healthcare#_msft_silver.
Poniżej przedstawiono kluczowe parametry konfiguracji tego notesu:
Konfiguracja NLP: umożliwia dostosowanie ustawień NLP w celu dostosowania ich do określonych wymagań użytkownika.
enable_text_analytics_logs: przełącz wartość naTruelubFalsedo aktywacji lub dezaktywacji dzienników interfejsu API. Wartość domyślna jest ustawiona naFalse. Aby dowiedzieć się więcej sposobie włączania rejestrowania, zobacz Włączanie dzienników.nlp_source_table_name: identyfikuje tabelę źródłową dla usługi Text Analytics for Health do przetwarzania.nlp_document_limit: ustawia limit liczby dokumentów, które może przetwarzać Text Analytics for Health. Wartość domyślna jest ustawiona na10i maksymalnie 1000 dokumentów. W razie potrzeby można dostosować tę wartość. Należy jednak pamiętać o konsekwencjach związanych z kosztami, jak wyjaśniono w temacie Model cenowy.
Ten notes jest wdrażany ze wstępnie skonfigurowanymi wartościami wymaganymi do uruchomienia skojarzonego potoku danych. Niektóre parametry konfiguracji dziedziczą z konfiguracji globalnej. Domyślnie nie trzeba wprowadzać żadnych zmian w plikach konfiguracji notesu. W razie potrzeby możesz otworzyć notes i przejrzeć konfigurację.