Korzystanie z funkcji wzbogacania nieustrukturyzowanych notatek klinicznych (wersja zapoznawcza) w rozwiązaniach do obsługi danych medycznych
[Ten artykuł stanowi wstępną wersję dokumentacji i może ulec zmianie.]
Uwaga
Za wartość jest obecnie aktualizowana.
Wzbogacanie nieustrukturyzowanych notatek klinicznych (wersja zapoznawcza) używa Języka platformy Azure AI usługi Text Analytics for Health do wyodrębniania kluczowych jednostek Fast Healthcase Interoperability Resources (FHIR) z nieustrukturyzowanych notatek klinicznych. Tworzy ustrukturyzowane dane na podstawie tych notatek klinicznych. Następnie można analizować te ustrukturyzowane dane, aby uzyskać szczegółowe informacje, prognozy i miary jakości mające na celu poprawę wyników zdrowotnych pacjentów.
Aby dowiedzieć się więcej o tej funkcji oraz dowiedzieć się, jak ją wdrożyć i skonfigurować, zobacz:
- Omówienie wzbogacania notatek klinicznych bez struktury (wersja zapoznawcza)
- Wdrażanie i konfigurowanie wzbogacania notatek klinicznych bez struktury (wersja zapoznawcza)
Wzbogacanie nieustrukturyzowanych notatek klinicznych (wersja zapoznawcza) jest bezpośrednio zależne od możliwości podstaw danych medycznych. Upewnij się, że najpierw pomyślnie skonfigurowano i wykonano potoki podstaw danych medycznych.
Wymagania wstępne
- Wdrażanie rozwiązań do obsługi danych medycznych w programie w Microsoft Fabric
- Zainstaluj podstawowe notesy i potoki w temacie Wdrażanie podstaw danych medycznych.
- Skonfiguruj usługę językową Azure zgodnie z opisem w temacie Konfigurowanie usługi językowej Azure.
- Wdrażanie i konfigurowanie wzbogacania notatek klinicznych bez struktury (wersja zapoznawcza)
- Wdrażanie i konfigurowanie przekształcania OMOP. To krok jest opcjonalny.
Usługa pozyskiwania NLP
Notes healthcare#_msft_ta4h_silver_ingestion wykonuje moduł NLPIngestionService w bibliotece rozwiązań do obsługi danych medycznych w celu wywołania analizy Text Analytics for Health. Ta usługa wyodrębnia nieustrukturyzowane notatki kliniczne z zasobu FHIR DocumentReference.Content w celu utworzenia spłaszczonych danych wyjściowych. Aby dowiedzieć się więcej, zobacz Przeglądanie konfiguracji notesu.
Przechowywanie danych w warstwie srebrnej
Po analizie interfejsu API przetwarzania języka naturalnego (NLP) ustrukturyzowane i spłaszczone dane wyjściowe są przechowywane w następujących tabelach natywnych w magazynie lakehouse healthcare#_msft_silver:
- nlpentity: zawiera spłaszczone jednostki wyodrębnione z nieustrukturyzowanych notatek klinicznych. Każdy wiersz jest pojedynczym terminem wyodrębnionym z tekstu bez struktury po przeprowadzeniu analizy tekstu.
- nlprelationship: zapewnia relację między wyodrębnionymi jednostkami.
- nlpfhir: zawiera pakiet wyjściowy FHIR jako ciąg JSON.
Aby śledzić ostatnią zaktualizowaną sygnaturę czasową, NLPIngestionService pola parent_meta_lastUpdated we wszystkich trzech tabelach srebrnego magazynu lakehouse. To śledzenie gwarantuje, że dokument źródłowy DocumentReference, który jest zasobem nadrzędnym, jest najpierw przechowywany w celu zachowania integralności referencyjnej. Ten proces pomaga zapobiegać niespójnościom danych i oddzielonym zasobom.
Ważne
Obecnie Text Analytics for Health zwraca słownictwo wymienione w Dokumentacji słownictwa metatezaurusa UMLS. Aby uzyskać wskazówki dotyczące tych słowników, zobacz Importowanie danych z UMLS.
W wersji zapoznawczej używamy terminologii SNOMED-CT (Systematized Nomenclature of Medicine - Clinical Terms), LOINC (Logical Observation Identifiers, Names, and Codes) i RxNorm, które są dołączone do przykładowego zestawu danych OMOP na podstawie wytycznych z Observational Health Data Sciences and Informatics (OHDSI).
Przekształcenie OMOP
Rozwiązania do obsługi danych medycznych w Microsoft Fabric zapewniają również kolejną możliwość transformacji partnerstwa na rzecz obserwacyjnych wyników medycznych (OMOP). Gdy wykonujesz tę funkcję, podstawowa transformacja ze srebrnego magazynu lakehouse do złotego magazynu lakehouse OMOP przekształca również ustrukturyzowane i spłaszczone dane wyjściowe analizy nieustrukturyzowanych notatek klinicznych. Przekształcenie odczytuje z tabeli nlpentity w srebrnym magazynie lakehouse i mapuje dane wyjściowe na tabelę NOTE_NLP w złotym magazynie lakehouse OMOP.
Aby uzyskać więcej informacji, zobacz Omówienie przekształceń OMOP.
Oto schemat ustrukturyzowanych danych wyjściowych NLP z odpowiednim mapowaniem kolumny NOTE_NLP na wspólny model danych OMOP:
| Odwołanie do spłaszczonego dokumentu | Podpis | Mapowanie Note_NLP | Dane próbki |
|---|---|---|---|
| id | Identyfikator unikatowy jednostki. Klucz złożony z parent_id, offset i length. |
note_nlp_id |
1380 |
| parent_id | Klucz obcy do spłaszczonego tekstu documentreferencecontent, z którego termin został wyodrębniony. | note_id |
625 |
| text | Tekst encji widoczny w dokumencie. | lexical_variant |
Brak znanych alergii |
| Przesunięcie | Przesunięcie znaku wyodrębnionego terminu w tekście wejściowym documentreferencecontent. | offset |
294 |
| data_source_entity_id | Identyfikator encji w danym wykazie źródłowym. | note_nlp_concept_id i note_nlp_source_concept_id |
37396387 |
| nlp_last_executed | Data przetwarzania analizy tekstu documentreferencecontent. | nlp_date_time i nlp_date |
2023-05-17T00:00:00.0000000 |
| model | Nazwa i wersja systemu NLP (nazwa systemu NLP i wersja Text Analytics for Health). | nlp_system |
MSFT TA4H |

Ograniczenia usługi dla Text Analytics for Health
- Maksymalna liczba znaków w dokumencie jest ograniczona do 125 000.
- Maksymalny rozmiar dokumentów zawartych w całym zgłoszeniu jest ograniczony do 1 MB.
- Maksymalna liczba dokumentów na żądanie jest ograniczona do:
- 25 dla internetowego interfejsu API.
- 1000 dla kontenera.
Włącz dzienniki
Wykonaj następujące kroki, aby włączyć rejestrowanie żądań i odpowiedzi dla interfejsu API Text Analytics for Health:
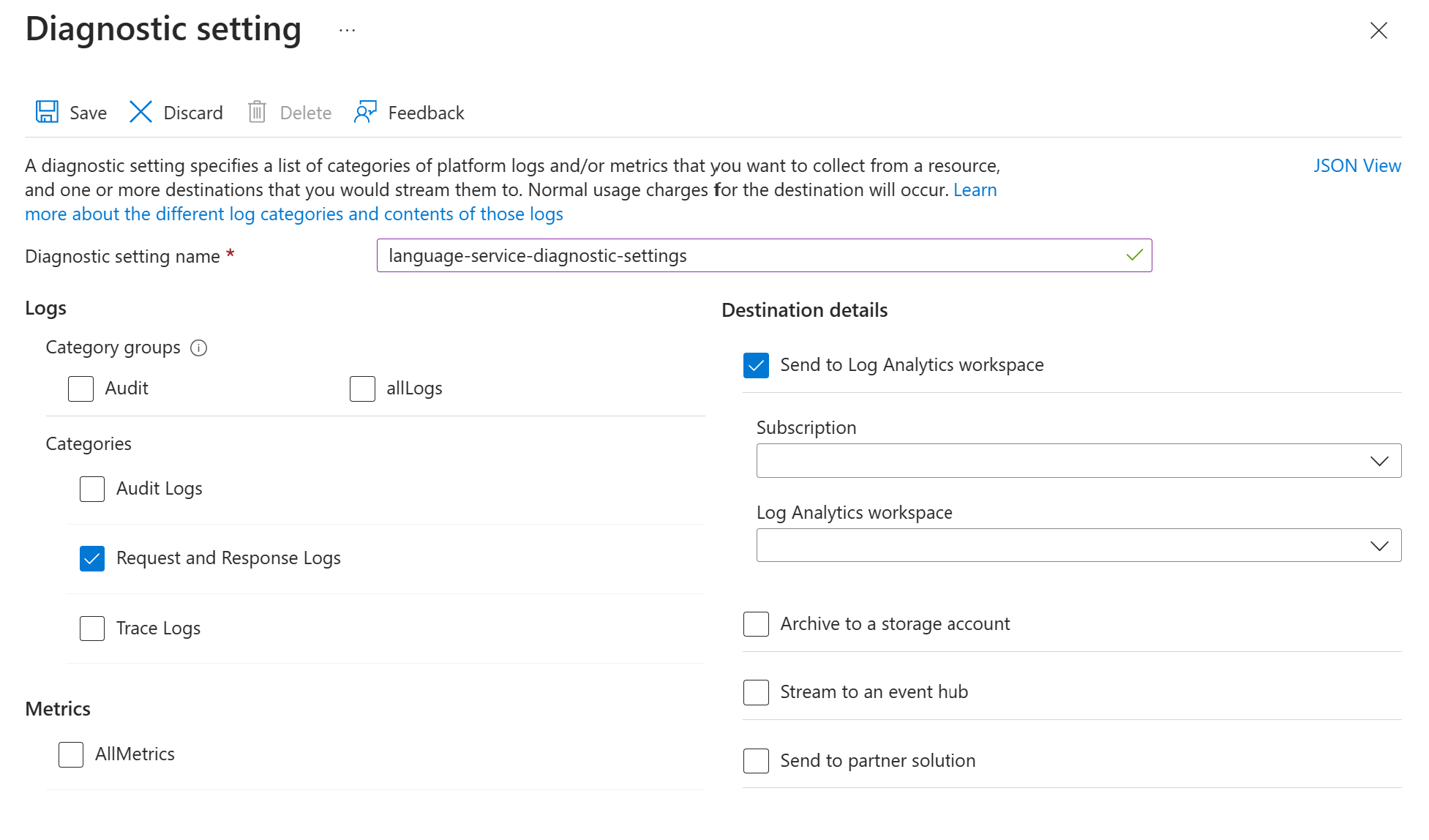
Włącz ustawienia diagnostyczne dla zasobu usługi językowej Azure, korzystając z instrukcji w temacie Włączanie rejestrowania diagnostycznego dla usług Azure AI. Ten zasób jest tą samą usługą językową, która została utworzona podczas kroku Konfigurowanie Azure wdrażania usługi językowej.
- Wprowadź nazwę ustawienia diagnostycznego.
- Ustaw kategorię na Dzienniki żądań i odpowiedzi.
- Aby uzyskać szczegółowe informacje o miejscu docelowym, wybierz pozycję Wyślij do obszaru roboczego Log Analytics, a następnie wybierz wymagany obszar roboczy usługi Log Analytics. Jeśli nie masz obszaru roboczego, postępuj zgodnie z monitami, aby go utworzyć.
- Zapisz ustawienia.
Przejdź do sekcji Konfiguracja NLP w notesie usługi pozyskiwania NLP. Zaktualizuj wartość parametru konfiguracji
enable_text_analytics_logsnaTrue. Aby uzyskać więcej informacji na temat tego notesu, zobacz Przeglądanie konfiguracji notesu.

Wyświetlanie dzienników w usłudze Azure Log Analytics
Aby eksplorować dane usługi Log Analytics:
- Przejdź do obszaru roboczego Log Analytics.
- Znajdź i wybierz pozycję Dzienniki. Na tej stronie można uruchamiać zapytania dotyczące dzienników.
Przykładowe zapytanie
Poniżej przedstawiono podstawowe zapytanie Kusto, którego można użyć do eksplorowania danych dziennika. To przykładowe zapytanie pobiera wszystkie żądania, które zakończyły się niepowodzeniem od dostawcy zasobów Azure Cognitive Services w ciągu ostatniego dnia, pogrupowane według typu błędu:
AzureDiagnostics
| where TimeGenerated > ago(1d)
| where Category == "RequestResponse"
| where ResourceProvider == "MICROSOFT.COGNITIVESERVICES"
| where tostring(ResultSignature) startswith "4" or tostring(ResultSignature) startswith "5"
| summarize NumberOfFailedRequests = count() by ResultSignature