Architektura danych i strategie zarządzania w rozwiązaniach do obsługi danych medycznych w programie Microsoft Fabric
Struktura rozwiązań do obsługi danych medycznych wykorzystuje wyspecjalizowaną architekturę medalionów w celu usprawnienia organizacji i przetwarzania danych. Taka konstrukcja zapewnia ciągłą poprawę jakości i struktury danych, umożliwiając bardziej efektywne zarządzanie danymi medycznymi. W tym artykule omówiono kluczowe funkcje i zalety tej architektury, zapewniając kompleksowe omówienie sposobu zarządzania danymi w tej strukturze.
Projekt magazynu lakehouse Medallion
Jak wyjaśniono w architekturze rozwiązania, rozwiązania do obsługi danych medycznych używają architektury magazynu lakehouse medallion do organizowania i przetwarzania danych w wielu warstwach. W miarę jak dane przechodzą przez każdą warstwę, ich struktura i jakość są stale ulepszane. Zasadniczo projekt magazynu lakehouse medalionu w rozwiązaniach do obsługi danych medycznych składa się z następujących kluczowych magazynów lakehouse:
Brązowy magazyn lakehouse: nazywany również strefą surową, brązowy magazyn lakehouse jest pierwszą warstwą, która organizuje dane źródłowe w oryginalnym formacie pliku. Pozyskuje pliki źródłowe do OneLake i/lub tworzy skróty z natywnych źródeł magazynu. Przechowuje również ustrukturyzowane i częściowo ustrukturyzowane dane ze źródła w tabelach różnicowych, nazywanych również tabelami przemieszczania. Te tabele są skompresowane i indeksowane w kolumach w celu obsługi wydajnych przekształceń i przetwarzania danych. Dane w tej warstwie są zazwyczaj tylko dołączane i niezmienne.
Pliki w brązowym magazynie lakehouse (czy to trwałe, czy skróty) służą jako źródło prawdy. Stanowią one podstawę pochodzenia danych w całej infrastrukturze danych w rozwiązaniach do obsługi danych medycznych. Tabele przemieszczania w warstwie brązowej zazwyczaj składają się z kilku kolumn i są przeznaczone do przechowywania każdej modalności i formatu danych w jednej tabeli (na przykład tabele ClinicalFhir i ImagingDicom). Nie należy rozszerzać, dostosowywać ani tworzyć zależności od tych tabel przemieszczania w brązowym magazynie lakehouse z następujących powodów:
- Implementacja wewnętrzna: tabele przemieszczania są wewnętrznie implementowane specyficznie dla rozwiązań do obsługi danych medycznych w Microsoft Fabric. Ich schemat został opracowany specjalnie dla rozwiązań do obsługi danych medycznych i nie jest zgodny z żadnymi standardami danych branżowych ani społecznościowych.
- Magazyn przejściowy: po przetworzeniu i przekształceniu danych z tabel przejściowych brązowego magazynu lakehouse do spłaszczonych i znormalizowanych tabel różnicowych w srebrnym magazynie lakehouse dane tabeli przejściowej z brązowego są uznawane za gotowe do wyczyszczenia. Model ten zapewnia efektywność kosztową i magazynową oraz zmniejsza nadmiarowość danych między plikami źródłowymi a tabelami przejściowymi w brązowego magazynu lakehouse.
Srebrny magazyn lakehouse: nazywany również strefą wzbogaconą, srebrny magazyn lakehouse przetwarza dane z brązowego magazynu lakehouse. Obejmuje ona kontrole weryfikacyjne i techniki wzbogacania w celu poprawy dokładności danych na potrzeby dalszej analizy. W przeciwieństwie do warstwy brązowej dane srebrnego magazynu lakehouse używają reguł opartych na deterministycznych identyfikatorach i sygnaturach czasowych modyfikacji do zarządzania wstawianiem i aktualizowaniem rekordów.
Złoty magazyn lakehouse: nazywany również strefą nadzorowaną, złoty magazyn lakehouse jeszcze bardziej uściśla dane ze srebrnego magazynu lakehouse, aby spełnić określone wymagania biznesowe i analityczne. Ta warstwa służy jako podstawowe źródło wysokiej jakości, zagregowanych zestawów danych gotowych do kompleksowej analizy i wyodrębniania szczegółowych informacji. Podczas gdy rozwiązania do obsługi danych medycznych wdrażają jeden brązowy i jeden srebrny magazyn lakehouse na wdrożenie, możesz mieć wiele złotych magazynów lakehouse do obsługi różnych jednostek biznesowych i osób.
Administracyjny magazyn lakehouse: administracyjny magazyn lakehouse zawiera pliki służące do zarządzania danymi i identyfikowania w warstwach lakehouse, w tym globalne błędy konfiguracji i walidacji przechowywane w tabeli BusinessEvent. Aby dowiedzieć się więcej, zobacz Administracyjny magazyn lakehouse.
Ujednolicona struktura folderów
Klienci z sektora opieki zdrowotnej i nauk przyrodniczych mają do czynienia z ogromnymi ilościami danych z różnych systemów źródłowych, w wielu modalnościach danych i formatach plików, w tym w następujących formatach plików:
- Modalność kliniczna: pliki FHIR NDJSON, pakiety FHIR oraz HL7.
- Metoda obrazowania: DICOM, NIFTI i NDPI.
- Modalność genomiki: BAM, BCL, FASTQ i VCF.
- Roszczenia: CCLF i CSV.
Gdzie:
- FHIR: projekt standardu Fast Healthcare Interoperability Resources
- HL7: siódmy międzynarodowy poziom zdrowia
- DICOM: cyfrowe obrazowanie i komunikacja w medycynie
- NIFTI: Inicjatywa Technologii Informatycznych Neuroobrazowania
- NDPI: nanowymiarowe obrazowanie patologii
- BAM: binarna mapa wyrównania
- BCL: podstawowe wywołanie
- FASTQ: format tekstowy do przechowywania sekwencji biologicznej i odpowiadających jej wyników jakości
- VFC: format komórki wariantu
- CCLF: oświadczenie i kanał informacyjny wiersza oświadczenia
- CSV: wartości rozdzielane przecinkami
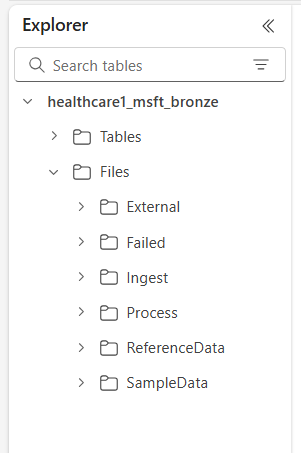
OneLake w Microsoft Fabric oferuje logiczny magazyn data lake dla Twojej organizacji. Rozwiązania do obsługi danych medycznych w Microsoft Fabric zapewniają ujednoliconą strukturę folderów, która ułatwia organizowanie danych w różnych modalnościach i formatach. Ta struktura usprawnia pozyskiwanie i przetwarzanie danych przy jednoczesnym zachowaniu pochodzenia danych na poziomie pliku źródłowego i systemu źródłowego w brązowym magazynie lakehouse.
Sześć folderów najwyższego poziomu to:
- Zewnętrzne
- Zakończone niepowodzeniem
- Pozyskaj
- Przetwarzanie
- ReferenceData
- Przykładowe dane
Foldery podrzędne są zorganizowane w następujący sposób:
Files\Ingest\[DataModality]\[DataFormat]\[Namespace]Files\External\[DataModality]\[DataFormat]\[Namespace]\[BYOSShortcutname]\Files\SampleData\[DataModality]\[DataFormat]\[Namespace]\Files\ReferenceData\[DataModality]\[DataFormat]\[Namespace]\Files\Failed\[DataModality]\[DataFormat]\[Namespace]\YYYY\MM\DDFiles\Process\[DataModality]\[DataFormat]\[Namespace]\YYYY\MM\DD
Opisy folderów
Przestrzeń nazw (wymagane): identyfikuje system źródłowy dla odebranych plików, co ma kluczowe znaczenie dla zapewnienia unikatowości identyfikatora dla każdego systemu źródłowego.
Folder pozyskiwania: działa jako folder upuszczania lub kolejki. Ten folder umożliwia upuszczanie plików, które mają zostać pozyskane w odpowiednich podfolderach modalności i formatu. Po rozpoczęciu pozyskiwania pliki są przesyłane do odpowiedniego folderu Proces lub folderu Niepowodzenie w przypadku błędów.
Folder przetwarzania: końcowe miejsce docelowe dla wszystkich pomyślnie przetworzonych plików w ramach każdej kombinacji modalności i formatu. Ten folder jest zgodny ze wzorcem
YYYY/MM/DDopartym na dacie przetwarzania. Partycjonowanie folderów jest zgodne z najlepszymi rozwiązaniami dotyczącymi korzystania z Azure Data Lake Storage dla ulepszonej organizacji, filtrowanych wyszukiwań, automatyzacji i potencjalnego przetwarzania równoległego.Folder zewnętrzny: służy jako folder nadrzędny dla folderów skrótów Bring Your Own Storage (BYOS). Domyślne wdrożenie zapewnia sugestywną strukturę folderów dla oświadczeń, metod klinicznych, genomicznych i obrazowania. Metody obrazowania i kliniczne mają domyślne formaty i przestrzenie nazw skonfigurowane do obsługi usług DICOM i FHIR w Azure Health Data Services. Ten format ma zastosowanie tylko wtedy, gdy zamierzasz skrócić dane do OneLake. Rozwiązania do obsługi danych medycznych w Microsoft Fabric mają dostęp tylko do odczytu do plików w tych folderach skrótów.
Folder zakończony niepowodzeniem: jeśli wystąpi błąd podczas przenoszenia lub przetwarzania plików w folderach Pozyskiwanie lub Przetwarzanie, pliki, których dotyczy problem, zostaną przeniesione do folderu Niepowodzenie odpowiadającego ich kombinacji modalności i formatu. Błąd jest rejestrowany w tabeli BusinessEvent w administracyjnym magazynie lakehouse. Ten folder używa wzorca
YYYY/MM/DDopartego na dacie przetwarzania/niepowodzenia. Pliki w tym folderze nie są czyszczone i pozostają w tym miejscu, dopóki nie naprawisz ich i nie pozyskasz ponownie przy użyciu tego samego początkowego wzorca pozyskiwania.Przykładowy folder danych: zawiera syntetyczne, referencyjne i/lub publiczne zestawy danych. Wdrożenie domyślne zawiera przykładowe dane dla kilku kombinacji modalności i formatów, aby ułatwić natychmiastowe wykonywanie notesów i potoków po wdrożeniu. Ten folder nie tworzy żadnych folderów podrzędnych
YYYY/MM/DD.Folder danych referencyjnych: zawiera referencyjne i nadrzędne zestawy danych ze źródeł publicznych lub specyficznych dla użytkownika. Ten folder nie tworzy żadnych folderów podrzędnych
YYYY/MM/DD. Domyślne wdrożenie zapewnia sugerowaną strukturę folderów dla słowników OMOP (Observational Medical Outcomes Partnership).
Wzorce pozyskiwania danych
Na podstawie opisanej wcześniej ujednoliconej struktury folderów rozwiązania do obsługi danych medycznych w Microsoft Fabric obsługują dwa różne wzorce pozyskiwania. W obu przypadkach rozwiązania używają przesyłania strumieniowego ze strukturą na platformie Spark do przetwarzania plików przychodzących w odpowiednich folderach.
Wzorzec pozyskiwania
Ten wzorzec jest prostym podejściem, w którym pliki do pozyskania są upuszczane do folderu Pozyskiwanie w odpowiedniej modalności, formacie i przestrzeni nazw. Potoki pozyskiwania monitorują ten folder pod kątem nowo upuszczonych plików i przenoszą je do odpowiedniego folderu Proces w celu przetworzenia. Jeśli pozyskiwanie danych pliku do tabeli przejściowej brązowego magazynu lakehouse zakończy się pomyślnie, plik zostanie skompresowany i zapisany z prefiksem sygnatury czasowej w folderze Proces, zgodnie ze wzorcem YYYY/MM/DD opartym na czasie przetwarzania. Ten prefiks zapewnia unikatowe nazwy plików. W razie potrzeby można skonfigurować lub wyłączyć kompresję.
Jeśli przetwarzanie plików zakończy się niepowodzeniem, pliki, które zakończyły się niepowodzeniem, zostaną przeniesione z folderu Pozyskiwanie do folderu Niepowodzenie dla każdej kombinacji modalności i formatu, a błąd jest rejestrowany w tabeli BusinessEvent w administracyjnym magazynie lakehouse.
Ten wzorzec pozyskiwania jest idealny w przypadku codziennych przyrostowych pozyskiwań lub podczas fizycznego przenoszenia danych do Azure Data Lake Storage lub OneLake.
Wzorzec Bring Your Own Storage (BYOS)
Czasami możesz mieć dane i pliki już obecne w Azure lub innych usługach przechowywania w chmurze, z istniejącymi implementacjami podrzędnymi i zależnościami od tych plików. W opiece zdrowotnej i naukach przyrodniczych ilość danych może sięgać wielu terabajtów, a nawet petabajtów, zwłaszcza w przypadku obrazowania medycznego i genomiki. Z tych powodów wzorzec bezpośredniego pozyskiwania może być niewykonalny.
Zalecamy używanie wzorca BYOS do pozyskiwania danych historycznych, gdy masz już znaczne ilości danych dostępne w Azure lub innym magazynie w chmurze i lokalnym obsługującym protokół S3. Ten wzorzec używa skrótów OneLake w Fabric i folderze zewnętrznym w brązowym magazynie lakehouse, aby umożliwić przetwarzanie w miejscu plików źródłowych. Eliminuje to konieczność przenoszenia lub kopiowania plików oraz pozwala uniknąć naliczania opłat za ruch wychodzący i duplikowanie danych.
Pomimo wydajności oferowanej przez wzorzec pozyskiwania BYOS należy zwrócić uwagę na następujące kwestie:
- Aktualizacje plików w miejscu (aktualizacje zawartości w pliku) nie są monitorowane. Oczekuje się, że utworzysz nowy plik (o innej nazwie) dla wszystkich aktualizacji, ponieważ potok pozyskiwania monitoruje tylko nowe pliki. To ograniczenie jest skojarzone z przesyłaniem strumieniowym ze strukturą na platformie Spark.
- Kompresje danych nie są stosowane.
- Wzorzec BYOS nie tworzy żadnej zoptymalizowanej struktury folderów na podstawie wzorca
YYYY/MM/DD. - Jeśli przetwarzanie plików zakończy się niepowodzeniem, pliki, które zakończyły się niepowodzeniem, nie zostaną przeniesione do folderu Niepowodzenie. Błąd jednakże jest rejestrowany w tabeli BusinessEvent w administracyjnym magazynie lakehouse.
- Zakłada się, że dane źródłowe są tylko do odczytu.
- Nie ma kontroli nad pochodzeniem ani dostępnością danych źródłowych po pozyskaniu.
Kompresja danych
Rozwiązania do obsługi danych medycznych w Microsoft Fabric obsługują kompresję według projektu w całym projekcie magazynu lakehouse medalionu. Dane pozyskane do tabel różnicowych w medalionie magazynu lakehouse są przechowywane w skompresowanym, kolumnowym formacie przy użyciu plików Parquet. We wzorcu pozyskiwania, gdy pliki są przenoszone z folderu Pozyskiwanie do folderu Proces, są one domyślnie kompresowane po pomyślnym przetworzeniu. W razie potrzeby można skonfigurować lub wyłączyć kompresję. W przypadku możliwości obrazowania i oświadczeń potoki pozyskiwania mogą również przetwarzać pliki nieprzetworzone w formacie skompresowanym ZIP.
Model danych opieki zdrowotnej
Zgodnie z opisem w projekcie magazynu lakehouse medalionu, tabele przejściowe magazynu lakehouse wewnętrznie wdrażają specjalnie zaprojektowane stoły dla rozwiązań do obsługi danych medycznych i nie są zgodne z żadnymi standardami danych branżowych ani społecznościowych.
Model danych opieki zdrowotnej w srebrnym magazynie lakehouse jest oparty na standardzie FHIR R4. Zapewnia wspólny język danych dla analityków danych, analityków danych i deweloperów w celu współpracy i tworzenia rozwiązań opartych na danych, które poprawiają wyniki leczenia pacjentów i wydajność biznesową. Obsługuje dane z różnych dziedzin opieki zdrowotnej, takich jak kliniczna, administracyjna, finansowa i społeczna. Model danych opieki zdrowotnej przechwytuje dane zdefiniowane przez standard FHIR i organizuje zasoby FHIR przy użyciu tabel i kolumn w magazynie lakehouse.
Spłaszczając dane FHIR do tabel Parquet delta, można użyć znanych narzędzi, takich jak T-SQL i Spark SQL do eksploracji i analizy danych. W przypadku danych nieklinicznych poza zakresem FHIR używamy schematów z szablonów bazy danych Azure Synapse. Ta implementacja umożliwia integrację informacji nieklinicznych, takich jak dane dotyczące zaangażowania pacjenta, z profilem pacjenta.
Model danych opieki zdrowotnej w srebrnym magazynie lakehouse został zaprojektowany tak, aby reprezentował kompleksowy widok danych dotyczących opieki zdrowotnej w przedsiębiorstwie w różnych jednostkach biznesowych i domenach badawczych.

Pochodzenie danych i śledzenie
Aby zapewnić pochodzenie i śledzenie na poziomie rekordu i pliku, tabele modelu danych opieki zdrowotnej zawierają następujące kolumny:
| Column | Podpis |
|---|---|
msftCreatedDatetime |
Sygnatura czasowa, kiedy rekord został po raz pierwszy utworzony w srebrnym magazynie lakehouse. |
msftModifiedDatetime |
Sygnatura czasowa ostatniej modyfikacji rekordu. |
msftFilePath |
Pełna ścieżka do pliku źródłowego w brązowym magazynie lakehouse, w tym skróty. |
msftSourceSystem |
System źródłowy rekordu, odpowiadający Namespace określonemu w ujednoliconej strukturze folderów. |
Jeśli pole zostanie znormalizowane, spłaszczone lub zmodyfikowane, oryginalna wartość zostanie zachowana w kolumnie {columnName}Orig. Na przykład w tabeli Pacjent srebrnego magazynu lakehouse można znaleźć następujące kolumny:
| Column | Podpis |
|---|---|
meta_lastUpdatedOrig |
Zachowuje oryginalną wartość w nieprzetworzonym formacie (ciąg lub data) i zapisuje ją jako datę i godzinę. |
idOrig i identifierOrig |
Identyfikatory i identyfikatory zharmonizowane w srebrnym magazynie lakehouse. |
birthdateOrig i deceasedDateTimeOrig |
Zachowuje oryginalne wartości dat z innym formatowaniem sygnatury czasowej. |
Jeśli kolumna zostanie spłaszczona (na przykład, meta_lastUpdated) lub przekonwertowana na ciąg (na przykład, meta_string), oznaczymy ją za pomocą sufiksu zaczynającego się od podkreślenia (_).
Aktualizacja obsługi
Gdy nowe dane są pozyskiwane z brązowego do srebrnego magazynu lakehouse, operacja aktualizacji porównuje rekordy przychodzące z tabelami docelowymi w srebrnym magazynie lakehouse dla każdego typu zasobu i tabeli. W przypadku tabel FHIR w srebrnym magazynie lakehouse to porównanie sprawdza wartości {FHIRResource}.id i {FHIRResource}.meta_lastUpdated względem kolumn id i lastUpdated w tabeli przejściowej brązowego magazynu lakehouse ClinicalFhir.
- Jeśli zostanie zidentyfikowane dopasowanie, a przychodzący rekord jest nowy, srebrny rekord zostanie zaktualizowany.
- Jeśli rekord przychodzący jest stary, rekord srebrny jest ignorowany.
- Jeśli nie zostanie znalezione dopasowanie, nowy rekord zostanie wstawiony do srebrnego magazynu lakehouse.
Administracyjny magazyn lakehouse
Administracyjny magazyn lakehouse zarządza konfiguracją między magazynami lakehouse, konfiguracją globalną, raportowaniem stanu i śledzeniem rozwiązań projekt standardu Fast Healthcare Interoperability Resources w Microsoft Fabric.
Konfiguracja globalna
Folder administracyjny magazynu lakehouse system-configurations centralizuje globalne parametry konfiguracji. Trzy pliki konfiguracyjne zawierają wstępnie skonfigurowane wartości domyślnego wdrożenia wszystkich możliwości rozwiązań projekt standardu Fast Healthcare Interoperability Resources. Nie trzeba ponownie konfigurować żadnej z tych wartości, aby uruchomić przykładowe dane lub potoki danych dla dowolnej funkcji.

Plik deploymentParametersConfiguration.json zawiera parametry globalne w obszarze activitiesGlobalParameters i parametry specyficzne dla działań dla notesów i potoków w obszarze activities. Odpowiednie wskazówki dotyczące funkcji obejmują szczegółowe informacje o konfiguracji dla każdej funkcji. Parametry pliku validation_config.json zostały wyjaśnione w sekcji Sprawdzanie poprawności danych.
W poniższej tabeli wymieniono wszystkie globalne parametry konfiguracji.
| Obszar | Konfiguracja parametrów |
|---|---|
activitiesGlobalParameters |
•administration_lakehouse_id: administracyjny identyfikator magazynu lakehouse.• bronze_lakehouse_id: brązowy identyfikator magazynu lakehouse.• silver_lakehouse_id: srebrny identyfikator magazynu lakehouse.• keyvault_name: wartość Azure Key Vault w przypadku wdrożenia z ofertą Azure Marketplace.• enable_hds_logs: włącza rejestrowanie; wartość domyślna ustawiona na true.• movement_config_path: ścieżka do pliku file_orchestration_config.• bronze_imaging_delta_table_path: ścieżka Fabric dla tabeli modalności obrazowania (jeśli została wdrożona).• bronze_imaging_table_schema_path: ścieżka Fabric dla schematu modalności obrazowania (jeśli została wdrożona).• omop_lakehouse_id: identyfikator złotego magazynu lakehouse (jeśli został wdrożony). |
| Działania na rzecz healthcare#_msft_fhir_ndjson_bronze_ingestion | •source_path_pattern: ścieżka OneLake do folderu Proces.• move_failed_files_enabled: flaga określająca, czy plik, który zakończył się niepowodzeniem, powinien zostać przeniesiony z folderu Pozyskiwanie do folderu Niepowodzenie .• compression_enabled: flaga określająca, czy nieprzetworzone pliki NDJSON zostaną skompresowane po przetworzeniu.• target_table_name: nazwa tabeli pozyskiwania klinicznego w brązowym magazynie lakehouse.• target_tables_path: ścieżka OneLake dla wszystkich tabel delta w brązowym magazynie lakehouse.• max_files_per_trigger: liczba plików przetworzonych przy każdym uruchomieniu.• max_structured_streaming_queries: liczba zapytań przetwarzających, które mogą być uruchamiane równolegle.• checkpoint_path: ścieżka OneLake dla folderu punktu kontrolnego.• schema_dir_path: ścieżka OneLake dla folderu brązowego schematu.• validation_config_key: konfiguracja walidacji na poziomie nadrzędnym. Aby uzyskać więcej informacji, zobacz Weryfikacja danych.• file_extension: rozszerzenie nieprzetworzonego pozyskanego pliku. |
| Działania na rzecz healthcare#_msft_bronze_silver_flatten | •source_table_name: nazwa tabeli pozyskiwania klinicznego w brązowym magazynie lakehouse.• config_path: ścieżka OneLake do pliku flattened_config.• source_tables_path: ścieżka OneLake dla źródła tabel delta w brązowym magazynie lakehouse.• target_tables_path: ścieżka OneLake dla celu tabel delta w srebrnym magazynie lakehouse.• checkpoint_path: ścieżka OneLake dla folderu punktu kontrolnego.• schema_dir_path: ścieżka OneLake dla folderu brązowego schematu.• max_files_per_trigger: liczba plików przetworzonych przy każdym uruchomieniu.• max_bytes_per_trigger: liczba bitów przetworzonych przy każdym uruchomieniu.• max_structured_streaming_queries: liczba zapytań przetwarzających, które mogą być uruchamiane równolegle. |
| Działania na rzecz healthcare#_msft_imaging_dicom_extract_bronze_ingestion | •byos_enabled: flaga określająca, czy pozyskiwanie zestawu danych obrazowania DICOM w brązowym magazynie lakehouse pochodzi z zewnętrznej lokalizacji magazynu za pośrednictwem skrótów OneLake. W takim przypadku pliki nie są przenoszone do folderu Proces, tak jak w przeciwnym razie.• external_source_path: ścieżka OneLake dla skrótu folder Zewnętrzny w brązowym magazynie lakehouse.• process_source_path: ścieżka OneLake dla skrótu folder Zewnętrzny w brązowym magazynie lakehouse.• checkpoint_path: ścieżka OneLake dla folderu punktu kontrolnego.• move_failed_files: flaga określająca, czy plik, który został przeniesiony, powinien zostać przeniesiony z folderu Pozyskiwanie do folderu Niepowodzenie .• compression_enabled: flaga określająca, czy nieprzetworzone pliki NDJSON są skompresowane po przetworzeniu.• max_files_per_trigger: liczba plików przetworzonych przy każdym uruchomieniu.• num_retries: liczba ponownych prób dla każdego przetwarzania pliku przed wystąpieniem błędu. |
| Działania na rzecz healthcare#_msft_imaging_dicom_fhir_conversion | •fhir_ndjson_files_root_path: ścieżka OneLake do folderu Proces.• avro_schema_path: ścieżka OneLake dla folderu srebrnego schematu.• dicom_to_fhir_config_path: Ścieżka OneLake do mapowania konfiguracji z metatagów DICOM do zasobu FHIR ImagingStudy.• checkpoint_path: ścieżka OneLake dla folderu punktu kontrolnego.• max_records_per_ndjson: liczba rekordów przetworzonych w ramach jednego pliku NDJSON w każdym przebiegu.• subject_id_type_code: kod wartości numeru medycznego pacjenta w metadanych DICOM. Domyślnie wartość ta jest ustawiona na MR, które odpowiada Medical Record Number w FHIR.• subject_id_type_code_system: system kodu numeru medycznego pacjenta w metadanych DICOM.• subject_id_system: identyfikator obiektu systemu kodu numeru medycznego pacjenta w metadanych DICOM. |
| Działania na rzecz healthcare#_msft_omop_silver_gold_transformation | •vocab_path: ścieżka OneLake do folderu danych referencyjnych w brązowym magazynie lakehouse, w którym są przechowywane zestawy danych słownictwa OMOP.• vocab_checkpoint_path: ścieżka OneLake dla folderu punktu kontrolnego.• omop_config_path: ścieżka OneLake do mapowania konfiguracji ze srebrnego magazynu lakehouse na złoty magazyn lakehouse OMOP. |
Tabela BusinessEvents
Tabela delta BusinessEvents przechwytuje wszystkie błędy walidacji, ostrzeżenia i inne powiadomienia lub wyjątki, które mogą wystąpić podczas procesów pozyskiwania i przekształcania. Ta tabela służy do monitorowania postępu wykonywania pozyskiwania zarówno na poziomie użytkownika, jak i funkcjonalności, a nie tylko na poziomie dziennika systemowego. Na przykład identyfikuje, które pliki nieprzetworzone wprowadziły błędy walidacji lub ostrzeżenia podczas pozyskiwania. W przypadku dzienników na poziomie systemu i monitorowania działań Apache Spark we wszystkich magazynach lakehouse można użyć centrum monitorowania Fabricz opcją integrowania usługi Azure Log Analytics.
W poniższej tabeli wymieniono kolumny w tabeli BusinessEvent:
| Column | Podpis |
|---|---|
id |
Unikatowy identyfikator (GUID) każdego wiersza danych w tabeli. |
activityName |
Nazwa działania/notesu, który wygenerował błąd i/lub błąd weryfikacji lub ostrzeżenie. |
targetTableName |
Tabela docelowa dla działania danych, które wygenerowało zdarzenie. |
targetFilePath |
Ścieżka dla pliku docelowego dla działania danych, które wygenerowało zdarzenie. |
sourceTableName |
Tabela źródłowa dla działania danych, które wygenerowało zdarzenie. |
sourceLakehouseName |
Źródłowy magazyn lakehouse dla działania danych, które wygenerowało zdarzenie. |
targetLakehouseName |
Docelowy magazyn lakehouse dla działania danych, które wygenerowało zdarzenie. |
sourceFilePath |
Ścieżka dla pliku źródłowego dla działania danych, które wygenerowało zdarzenie. |
runId |
Identyfikator uruchamiania dla działania danych, które wygenerowało zdarzenie. |
severity |
Poziom ważności zdarzenia, który może mieć jedną z następujących dwóch wartości: Error lub Warning. Error oznacza, że należy rozwiązać to zdarzenie przed kontynuowaniem działania związanego z danymi. Warning służy jako powiadomienie pasywne, co do zasady nie wymaga natychmiastowego działania. |
eventType |
Rozróżnia zdarzenia generowane przez aparat walidacji i zdarzenia ogólne generowane przez użytkowników lub wyjątki nieobsługiwane/systemowe, które użytkownicy chcą wyświetlić w tabeli BusinessEvent. |
recordIdentifier |
Identyfikator dla rekordu źródłowego. Ta kolumna różni się od kolumny id, ponieważ reprezentuje nowy i unikatowy identyfikator każdego zdarzenia w tabeli BusinessEvents. |
recordIdentifierSource |
System źródłowy dla identyfikatora rekordu źródłowego. Na przykład, jeśli systemem źródłowym jest EMR, nazwa EMR lub adres URL służy jako źródło. |
active |
Flaga wskazująca, czy zdarzenie (błąd lub ostrzeżenie) zostało rozwiązane. |
message |
Komunikat opisowy dotyczący błędu lub ostrzeżenia o zdarzeniu. |
exception |
Komunikat o nieobsłużonym/wyjątku systemowym. |
customDimensions |
Ma zastosowanie, gdy dane źródłowe walidacji lub wyjątku nie są odrębną kolumną w tabeli. Na przykład, gdy dane źródłowe są atrybutem w obiekcie JSON zapisanym jako ciąg w jednej kolumnie, pełny obiekt JSON jest podawany jako wymiar niestandardowy. |
eventDateTime |
Sygnatura czasowa, w której jest generowane zdarzenie lub wyjątek. |
Sprawdzanie poprawności danych
Aparat weryfikacji danych w rozwiązaniach do obsługi danych medycznych w Microsoft Fabric zapewnia, że nieprzetworzone dane spełniają wstępnie zdefiniowane kryteria przed pozyskaniem do brązowego magazynu lakehouse. Reguły sprawdzania poprawności można skonfigurować na poziomie tabeli i kolumny w brązowym magazynie lakehouse. Obecnie te reguły są implementowane wyłącznie podczas procesu pozyskiwania, od plików nieprzetworzonych do tabel różnicowych w brązowym magazynie lakehouse.
Podczas przetwarzania pliku nieprzetworzonego reguły walidacji są stosowane na poziomie pozyskiwania. Istnieją dwa poziomy ważności walidacji: Error i Warning. Jeśli reguła sprawdzania poprawności jest ustawiona na Error, potok zatrzymuje się, gdy reguła zostanie naruszona, a wadliwy plik zostanie przeniesiony do folderu Niepowodzenie. Jeśli ważność jest ustawiona na Warning, potok kontynuuje przetwarzanie, a plik zostanie przeniesiony do folderu Proces. W obu przypadkach wpisy odzwierciedlające błędy lub ostrzeżenia są tworzone w tabeli BusinessEvents w administracyjnym magazynie lakehouse.
Tabela BusinessEvents przechwytuje dzienniki i zdarzenia na poziomie biznesowym we wszystkich magazynach lakehouse dla dowolnego działania, notesu lub potoku danych w rozwiązaniach do obsługi danych medycznych. Jednak bieżąca konfiguracja wymusza reguły walidacji tylko podczas pozyskiwania, co może spowodować, że niektóre kolumny w tabeli BusinessEvents pozostaną niewypełnione pod kątem błędów walidacji i ostrzeżeń.
Reguły sprawdzania poprawności danych można skonfigurować w pliku validation_config.json w administracyjnym magazynie lakehouse. Domyślnie kolumny meta.lastUpdated i id w tabeli ClinicalFhir brązowego magazynu lakehouse są ustawione zgodnie z wymaganiami. Te kolumny mają kluczowe znaczenie dla określenia sposobu zarządzania aktualizacjami i wstawieniami w srebrnym magazynie lakehouse. jak wyjaśniono w temacie Obsługa aktualizacji.
W poniższej tabeli wymieniono parametry konfiguracji dla weryfikacji danych:
| Typ konfiguracji | Parametry |
|---|---|
| Poziom magazynu lakehouse | bronze: zakres walidacji i węzłów identyfikatora rekordu. W tym przypadku wartość jest ustawiana na brązowy magazyn lakehouse. |
| Walidacje | •validationType: typ weryfikacji exists sprawdza, czy wartość skonfigurowanego atrybutu jest podana w pliku nieprzetworzonym (dane źródłowe).• attributeName: nazwa weryfikowanego atrybutu.• validationMessage: komunikat opisujący błąd weryfikacji lub ostrzeżenie.• severity: wskazuje poziom problemu, którym może być Error lub Warning.• tableName: nazwa weryfikowanej tabeli. Gwiazdka (*) oznacza, że ta reguła ma zastosowanie do wszystkich tabel w zakresie tego magazynu lakehouse. |
recordIdentifier |
•attributeName: identyfikator rekordu pliku źródłowego/nieprzetworzonego umieszczonego w kolumnie recordIdentifier w tabeli BusinessEvent.• jsonPath: opcjonalna wartość reprezentująca ścieżkę JSON kolumny lub atrybutu dla wartości, która ma zostać umieszczona w kolumnie recordIdentifier w tabeli BusinessEvent. Ta wartość ma zastosowanie, gdy dane źródłowe walidacji nie są odrębną kolumną w tabeli. Jeśli na przykład dane źródłowe są atrybutem w obiekcie JSON przechowywanym jako ciąg w jednej kolumnie, ścieżka JSON kieruje do określonego atrybutu, który służy jako identyfikator rekordu. |