Samouczek: odnajdywanie relacji w zestawie danych Synthea przy użyciu linku semantycznego
Ten samouczek pokazuje, jak wykrywać relacje w publicznym zestawie danych Synthea przy pomocy łącza semantycznego.
Podczas pracy z nowymi danymi lub pracy bez istniejącego modelu danych pomocne może być automatyczne odnajdywanie relacji. To wykrywanie relacji może pomóc w:
- zrozumienie modelu na poziomie ogólnym
- uzyskiwanie dodatkowych szczegółowych informacji podczas eksploracyjnej analizy danych,
- weryfikowanie zaktualizowanych danych lub nowych danych przychodzących i
- czyszczenie danych.
Nawet jeśli relacje są znane z wyprzedzeniem, wyszukiwanie relacji może pomóc w lepszym zrozumieniu modelu danych lub identyfikacji problemów z jakością danych.
W tym samouczku zaczniesz od prostego przykładu odniesienia, w którym eksperymentujesz tylko z trzema tabelami, aby połączenia między nimi były łatwe do naśladowania. Następnie przedstawiono bardziej złożony przykład z większym zestawem tabel.
Z tego samouczka dowiesz się, jak wykonywać następujące działania:
- Użyj składników biblioteki języka Python łącza semantycznego (SemPy), które obsługują integrację z usługą Power BI i pomagają zautomatyzować analizę danych. Te składniki obejmują:
- FabricDataFrame — struktura podobna do pandas, wzbogacona o dodatkowe informacje semantyczne.
- Funkcje służące do ściągania modeli semantycznych z obszaru roboczego usługi Fabric do notesu.
- Funkcje, które automatyzują odnajdywanie i wizualizację relacji w modelach semantycznych.
- Rozwiązywanie problemów z procesem odnajdywania relacji dla modeli semantycznych z wieloma tabelami i współzależnościami.
Warunki wstępne
Pobierz subskrypcję usługi Microsoft Fabric . Możesz też utworzyć bezpłatne konto wersji próbnej usługi Microsoft Fabric.
Zaloguj się do usługi Microsoft Fabric.
Użyj przełącznika trybów w lewym dolnym rogu strony głównej, aby przełączyć się na tryb Fabric.

- Wybierz pozycję Obszary robocze w okienku nawigacji po lewej stronie, aby znaleźć i wybrać obszar roboczy. Ten obszar roboczy staje się aktualnym obszarem roboczym.
Śledź w zeszycie
Zeszyt relationships_detection_tutorial.ipynb towarzyszy temu samouczkowi.
Aby otworzyć towarzyszący notatnik do tego samouczka, postępuj zgodnie z instrukcjami w Przygotuj swój system do samouczków z nauki o danych, aby zaimportować notatnik do swojego obszaru roboczego.
Jeśli wolisz skopiować i wkleić kod z tej strony, możesz utworzyć nowy notes.
Przed rozpoczęciem uruchamiania kodu pamiętaj, aby dołączyć magazyn lakehouse do notesu.
Konfigurowanie notesu
W tej sekcji skonfigurujesz środowisko notesu z niezbędnymi modułami i danymi.
Zainstaluj
SemPyz PyPI przy użyciu funkcji instalacji wbudowanej%pipw notesie:%pip install semantic-linkWykonaj niezbędne importy modułów SemPy, które będą potrzebne później:
import pandas as pd from sempy.samples import download_synthea from sempy.relationships import ( find_relationships, list_relationship_violations, plot_relationship_metadata )Zaimportuj bibliotekę pandas do wymuszania opcji konfiguracji, która ułatwia formatowanie danych wyjściowych:
import pandas as pd pd.set_option('display.max_colwidth', None)Ściąganie przykładowych danych. Na potrzeby tego samouczka użyjesz zestawu danych Synthea syntetycznych dokumentacji medycznej (mała wersja dla uproszczenia):
download_synthea(which='small')
Wykrywanie relacji w małym podzestawie tabel Synthea
Wybierz trzy tabele z większego zestawu:
-
patientsokreśla informacje o pacjentach -
encountersokreśla pacjentów, którzy mieli spotkania medyczne (na przykład wizytę lekarską, procedurę) -
providersokreśla, którzy dostawcy usług medycznych opiekowali się pacjentami
Tabela
encountersrozwiązuje relację wiele-do-wielu międzypatientsiprovidersi może być opisana jako jednostka asocjacyjna :patients = pd.read_csv('synthea/csv/patients.csv') providers = pd.read_csv('synthea/csv/providers.csv') encounters = pd.read_csv('synthea/csv/encounters.csv')-
Znajdź relacje między tabelami przy użyciu funkcji
find_relationshipsbiblioteki SemPy:suggested_relationships = find_relationships([patients, providers, encounters]) suggested_relationshipsWizualizowanie ramki danych relacji jako grafu przy użyciu funkcji
plot_relationship_metadatabiblioteki SemPy.plot_relationship_metadata(suggested_relationships)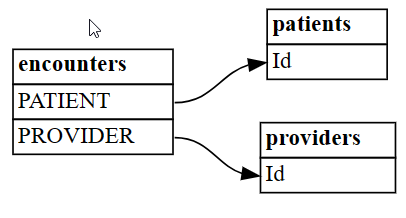
Funkcja określa hierarchię relacji od lewej strony do prawej strony, która odpowiada tabelom "from" i "to" w danych wyjściowych. Innymi słowy, niezależne tabele "from" po lewej stronie używają kluczy obcych, aby wskazać tabele zależności "do" po prawej stronie. Każde pole jednostki zawiera kolumny, które uczestniczą w relacji "od" lub "do".
Domyślnie relacje są generowane jako "m:1" (nie jako "1:m") lub "1:1". Relacje "1:1" można wygenerować na jeden lub oba sposoby, w zależności od tego, czy stosunek wartości zamapowanych do wszystkich wartości przekracza
coverage_thresholdw jednym lub obu kierunkach. W dalszej części tego samouczka omówisz mniej częste przypadki relacji "m:m".

Rozwiązywanie problemów z wykrywaniem relacji
W przykładzie odniesienia pokazano udane wykrywanie relacji na czystych danych Synthea. W praktyce dane są rzadko czyste, co uniemożliwia pomyślne wykrywanie. Istnieje kilka technik, które mogą być przydatne, gdy dane nie są czyste.
Ta sekcja tego samouczka dotyczy wykrywania relacji, gdy model semantyczny zawiera zanieczyszczone dane.
Zacznij od manipulowania oryginalnymi ramkami danych w celu uzyskania "brudnych" danych i wydrukowania rozmiaru zanieczyszczonych danych.
# create a dirty 'patients' dataframe by dropping some rows using head() and duplicating some rows using concat() patients_dirty = pd.concat([patients.head(1000), patients.head(50)], axis=0) # create a dirty 'providers' dataframe by dropping some rows using head() providers_dirty = providers.head(5000) # the dirty dataframes have fewer records than the clean ones print(len(patients_dirty)) print(len(providers_dirty))Dla porównania rozmiary wydruku oryginalnych tabel:
print(len(patients)) print(len(providers))Znajdź relacje między tabelami przy użyciu funkcji
find_relationshipsbiblioteki SemPy:find_relationships([patients_dirty, providers_dirty, encounters])Dane wyjściowe kodu pokazują, że nie wykryto żadnych relacji z powodu błędów, które zostały wprowadzone wcześniej w celu utworzenia modelu semantycznego "brudnego".
Korzystanie z walidacji
Walidacja to najlepsze narzędzie do rozwiązywania problemów z błędami wykrywania relacji, ponieważ:
- Raportuje jasno, dlaczego określona relacja nie jest zgodna z regułami klucza obcego i dlatego nie można jej wykryć.
- Działa szybko z dużymi modelami semantycznymi, ponieważ koncentruje się tylko na zadeklarowanych relacjach i nie wykonuje wyszukiwania.
Walidacja może używać dowolnej ramki danych z kolumnami podobnymi do tej wygenerowanej przez find_relationships. W poniższym kodzie ramka danych suggested_relationships odnosi się do patients, a nie patients_dirty, ale można przypisać aliasy ramkom danych za pomocą słownika.
dirty_tables = {
"patients": patients_dirty,
"providers" : providers_dirty,
"encounters": encounters
}
errors = list_relationship_violations(dirty_tables, suggested_relationships)
errors
Luźne kryteria wyszukiwania
W bardziej mętnych scenariuszach możesz spróbować poluzować kryteria wyszukiwania. Ta metoda zwiększa możliwość fałszywie dodatnich wyników.
Ustaw
include_many_to_many=Truei oceń, czy pomaga:find_relationships(dirty_tables, include_many_to_many=True, coverage_threshold=1)Wyniki pokazują, że wykryto relację z
encountersdopatients, ale występują dwa problemy:- Relacja wskazuje kierunek od
patientsdoencounters, który jest odwrotnością oczekiwanej relacji. Dzieje się tak, ponieważ wszystkiepatientsokazały się objęte przezencounters(Coverage Fromwynosi 1,0), podczas gdyencounterssą objęte tylko częściowo przezpatients(Coverage To= 0,85), ponieważ brakuje wierszy dotyczących pacjentów. - Istnieje przypadkowe dopasowanie w kolumnie
GENDERo niskiej kardynalności, która dopasowuje się nazwą i wartością w obu tabelach, ale nie jest to interesująca relacja "m:1". Niska kardynalność jest wskazywana przez kolumnyUnique Count FromiUnique Count To.
- Relacja wskazuje kierunek od
Ponownie uruchom
find_relationships, aby wyszukiwać tylko relacje "m:1", ale z niższymcoverage_threshold=0.5:find_relationships(dirty_tables, include_many_to_many=False, coverage_threshold=0.5)Wynik przedstawia prawidłowy kierunek relacji z
encountersdoproviders. Jednak relacja zencountersdopatientsnie jest wykrywana, ponieważpatientsnie jest unikalna, więc nie może być po stronie "Jeden" w relacji "m:1".Poluzuj zarówno
include_many_to_many=True, jak icoverage_threshold=0.5:find_relationships(dirty_tables, include_many_to_many=True, coverage_threshold=0.5)Teraz obie relacje zainteresowania są widoczne, ale jest o wiele więcej szumu:
- Dopasowanie o niskiej kardynalności dla
GENDERjest obecne. - Na
ORGANIZATIONpojawiło się dopasowanie o wyższej kardynalności "m:m", co sprawia, że kolumnaORGANIZATIONprawdopodobnie jest zdenormalizowana do obu tabel.
- Dopasowanie o niskiej kardynalności dla
Dopasowywanie nazw kolumn
Domyślnie narzędzie SemPy traktuje jako dopasowania tylko atrybutów, które pokazują podobieństwo nazw, korzystając z faktu, że projektanci baz danych zwykle nazywają powiązane kolumny w taki sam sposób. To zachowanie pomaga uniknąć fałszywych relacji, które występują najczęściej z kluczami liczb całkowitych o niskiej kardynalności. Jeśli na przykład istnieją 1,2,3,...,10 kategorii produktów i 1,2,3,...,10 kod stanu zamówienia, będą one mylić się ze sobą tylko podczas przeglądania mapowań wartości bez uwzględniania nazw kolumn. Pozorne związki nie powinny być problemem z kluczami typu GUID.
Narzędzie SemPy analizuje podobieństwo między nazwami kolumn i nazwami tabel. Dopasowanie jest przybliżone i bez uwzględniania wielkości liter. Ignoruje on najczęściej spotykane podciągy "decorator", takie jak "id", "code", "name", "key", "pk", "fk". W rezultacie najbardziej typowe przypadki dopasowania to:
- atrybut o nazwie "column" w encji "foo" pasuje do atrybutu o nazwie "column" (także "COLUMN" lub "Column") w encji "bar".
- atrybut o nazwie "column" w jednostce "foo" pasuje do atrybutu o nazwie "column_id" w 'bar'.
- atrybut o nazwie "bar" w jednostce "foo" pasuje do atrybutu o nazwie "code" na pasku.
Najpierw dopasowując nazwy kolumn, wykrywanie przebiega szybciej.
Dopasuj nazwy kolumn:
- Aby zrozumieć, które kolumny są wybrane do dalszej oceny, użyj opcji
verbose=2(verbose=1wyświetla tylko przetwarzane jednostki). - Parametr
name_similarity_thresholdokreśla sposób porównywania kolumn. Próg 1 wskazuje, że interesuje Cię tylko 100% dopasowania.
find_relationships(dirty_tables, verbose=2, name_similarity_threshold=1.0);Uruchamianie z podobieństwem 100% nie uwzględnia drobnych różnic między nazwami. W tym przykładzie tabele mają postać mnogią z sufiksem "s", co nie powoduje dokładnego dopasowania. Jest to dobrze obsługiwane z domyślnym
name_similarity_threshold=0.8.- Aby zrozumieć, które kolumny są wybrane do dalszej oceny, użyj opcji
Uruchom ponownie przy użyciu domyślnego
name_similarity_threshold=0.8:find_relationships(dirty_tables, verbose=2, name_similarity_threshold=0.8);Zwróć uwagę, że identyfikator liczby mnogiej
patientsjest teraz porównywany z liczbą pojedyncząpatientbez dodawania zbyt wielu innych niepotrzebnych porównań do czasu wykonywania.Uruchom ponownie przy użyciu domyślnego
name_similarity_threshold=0:find_relationships(dirty_tables, verbose=2, name_similarity_threshold=0);Zmiana
name_similarity_thresholdna 0 jest drugą skrajnością i wskazuje, że chcesz porównać wszystkie kolumny. Rzadko jest to konieczne i skutkuje wydłużonym czasem wykonywania oraz fałszywymi dopasowaniami, które należy przejrzeć. Obserwuj liczbę porównań w pełnych danych wyjściowych.
Podsumowanie porad dotyczących rozwiązywania problemów
- Zacznij od dokładnego dopasowania relacji "m:1" (czyli domyślnych
include_many_to_many=Falseicoverage_threshold=1.0). Jest to zwykle to, co chcesz. - Użyj wąskiego fokusu na mniejszych podzestawach tabel.
- Użyj walidacji, aby wykryć problemy z jakością danych.
- Użyj
verbose=2, jeśli chcesz zrozumieć, które kolumny są brane pod uwagę w kontekście relacji. Może to spowodować dużą ilość danych wyjściowych. - Należy zwrócić uwagę na kompromisy, które mogą wynikać z użycia argumentów wyszukiwania.
include_many_to_many=Trueicoverage_threshold<1.0mogą generować fałszywe relacje, które mogą być trudniejsze do przeanalizowania i muszą być filtrowane.
Wykrywanie relacji w pełnym zestawie danych Synthea
Prosty przykład punktu odniesienia to wygodne narzędzie do uczenia się i rozwiązywania problemów. W praktyce można zacząć od modelu semantycznego, takiego jak pełny zestaw danych Synthea, który zawiera o wiele więcej tabel. Zapoznaj się z pełnym zestawem danych synthea w następujący sposób.
Odczytaj wszystkie pliki z katalogu synthea/csv:
all_tables = { "allergies": pd.read_csv('synthea/csv/allergies.csv'), "careplans": pd.read_csv('synthea/csv/careplans.csv'), "conditions": pd.read_csv('synthea/csv/conditions.csv'), "devices": pd.read_csv('synthea/csv/devices.csv'), "encounters": pd.read_csv('synthea/csv/encounters.csv'), "imaging_studies": pd.read_csv('synthea/csv/imaging_studies.csv'), "immunizations": pd.read_csv('synthea/csv/immunizations.csv'), "medications": pd.read_csv('synthea/csv/medications.csv'), "observations": pd.read_csv('synthea/csv/observations.csv'), "organizations": pd.read_csv('synthea/csv/organizations.csv'), "patients": pd.read_csv('synthea/csv/patients.csv'), "payer_transitions": pd.read_csv('synthea/csv/payer_transitions.csv'), "payers": pd.read_csv('synthea/csv/payers.csv'), "procedures": pd.read_csv('synthea/csv/procedures.csv'), "providers": pd.read_csv('synthea/csv/providers.csv'), "supplies": pd.read_csv('synthea/csv/supplies.csv'), }Znajdź relacje między tabelami przy użyciu funkcji
find_relationshipsbiblioteki SemPy:suggested_relationships = find_relationships(all_tables) suggested_relationshipsWizualizacja relacji:
plot_relationship_metadata(suggested_relationships)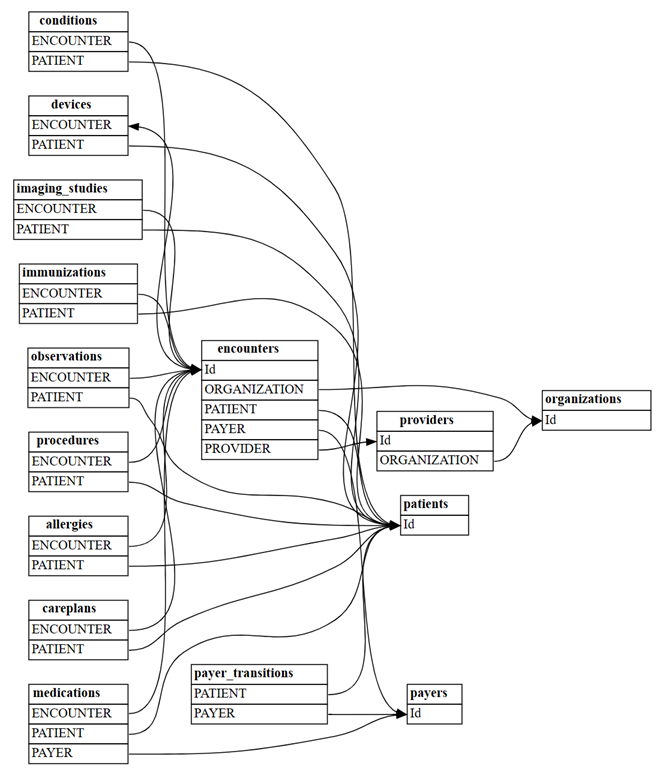
Zlicz, ile nowych relacji "m:m" zostanie odnalezionych przy użyciu
include_many_to_many=True. Te relacje są dodatkiem do poprzednio wyświetlanych relacji "m:1"; w związku z tym należy filtrować wedługmultiplicity:suggested_relationships = find_relationships(all_tables, coverage_threshold=1.0, include_many_to_many=True) suggested_relationships[suggested_relationships['Multiplicity']=='m:m']Dane relacji można sortować według różnych kolumn, aby lepiej zrozumieć ich charakter. Na przykład można wybrać kolejność danych wyjściowych według
Row Count FromiRow Count To, co pomaga zidentyfikować największe tabele.suggested_relationships.sort_values(['Row Count From', 'Row Count To'], ascending=False)W innym modelu semantycznym warto skupić się na liczbie wartości null
Null Count FromlubCoverage To.Ta analiza może pomóc w zrozumieniu, czy którakolwiek z relacji może być nieprawidłowa, a jeśli trzeba je usunąć z listy kandydatów.

Powiązana zawartość
Zapoznaj się z innymi samouczkami dotyczącymi linku semantycznego /SemPy:
- samouczek : czyszczenie danych z zależnościami funkcjonalnymi
- Samouczek: analizowanie zależności funkcjonalnych w przykładowym modelu semantycznym
- Samouczek: odnajdywanie relacji w modelu semantycznym przy użyciu linku semantycznego
- Samouczek : wyodrębnianie i obliczanie miar Power BI z notesu Jupyter