Samouczek: analizowanie zależności funkcjonalnych w modelu semantycznym
W tym samouczku przedstawiono wcześniejsze prace wykonywane przez analityka usługi Power BI i przechowywane w postaci modeli semantycznych (zestawów danych usługi Power BI). Korzystając z biblioteki SemPy (wersja zapoznawcza) w środowisku nauki o danych usługi Synapse w usłudze Microsoft Fabric, analizujesz zależności funkcjonalne, które istnieją w kolumnach ramki danych. Ta analiza ułatwia identyfikację nieniestandardowych problemów z jakością danych, aby uzyskać dokładniejsze informacje.
Z tego samouczka dowiesz się, jak wykonywać następujące działania:
- Zastosuj wiedzę na temat domeny, aby sformułować hipotezy dotyczące zależności funkcjonalnych w modelu semantycznym.
- Zapoznaj się z elementami biblioteki Python linku semantycznego (SemPy), które wspierają integrację z Power BI i pomagają zautomatyzować analizę jakości danych. Te składniki obejmują:
- FabricDataFrame — struktura przypominająca pandas, wzbogacona o dodatkowe informacje semantyczne.
- Przydatne funkcje ściągania modeli semantycznych z obszaru roboczego usługi Fabric do notesu.
- Przydatne funkcje automatyzujące ocenę hipotez dotyczących zależności funkcjonalnych i identyfikujące naruszenia relacji w modelach semantycznych.
Warunki wstępne
Pobierz subskrypcję usługi Microsoft Fabric . Możesz też utworzyć bezpłatne konto wersji próbnej usługi Microsoft Fabric.
Zaloguj się do usługi Microsoft Fabric.
Użyj przełącznika środowiska w lewym dolnym rogu strony głównej, aby przełączyć się na Fabric.

Wybierz pozycję Obszary robocze w okienku nawigacji po lewej stronie, aby znaleźć i wybrać obszar roboczy. To środowisko pracy staje się bieżącym środowiskiem pracy.
Pobierz Customer Profitability Sample.pbix semantyczny model z repozytorium GitHub fabric-samples.
W obszarze roboczym wybierz pozycję Importuj raport>lub raport podzielony na strony>Z tego komputera, aby przekazać plik Customer Profitability Sample.pbix do obszaru roboczego.
Śledź w zeszycie
Notatnik powerbi_dependencies_tutorial.ipynb towarzyszy temu samouczkowi.
Aby otworzyć dołączony zeszyt do tego samouczka, postępuj zgodnie z instrukcjami w Przygotuj swój system do samouczków z nauki o danych, w celu zaimportowania zeszytu do obszaru roboczego.
Jeśli wolisz skopiować i wkleić kod z tej strony, możesz utworzyć nowy notes.
Przed rozpoczęciem uruchamiania kodu, upewnij się, że dołączysz lakehouse do notesu.
Skonfiguruj notebooka
W tej sekcji skonfigurujesz środowisko notesu z niezbędnymi modułami i danymi.
Zainstaluj
SemPyz PyPI przy użyciu funkcji instalacji wbudowanej%pipw notesie:%pip install semantic-linkWykonaj niezbędne importy modułów, które będą potrzebne później:
import sempy.fabric as fabric from sempy.dependencies import plot_dependency_metadata
Ładowanie i wstępne przetwarzanie danych
W tym samouczku użyto standardowego przykładowego modelu semantycznego Customer Profitability Sample.pbix. Aby zapoznać się z opisem modelu semantycznego, zobacz Przykład Customer Profitability dla usługi Power BI.
Załaduj dane usługi Power BI do fabricDataFrames przy użyciu funkcji
read_tablebiblioteki SemPy:dataset = "Customer Profitability Sample" customer = fabric.read_table(dataset, "Customer") customer.head()Załaduj tabelę
Statedo elementu FabricDataFrame:state = fabric.read_table(dataset, "State") state.head()Chociaż dane wyjściowe tego kodu wyglądają jak ramka danych biblioteki pandas, w rzeczywistości zainicjowano strukturę danych o nazwie
FabricDataFrame, która obsługuje niektóre przydatne operacje na bibliotece pandas.Sprawdź typ danych
customer:type(customer)Dane wyjściowe potwierdzają, że
customerjest typusempy.fabric._dataframe._fabric_dataframe.FabricDataFrame.Dołącz do
customeristateDataFrame:customer_state_df = customer.merge(state, left_on="State", right_on="StateCode", how='left') customer_state_df.head()
Identyfikowanie zależności funkcjonalnych
Zależność funkcjonalna manifestuje się jako relacja jeden do wielu między wartościami w dwóch (lub więcej) kolumnach w ramce danych. Te relacje mogą służyć do automatycznego wykrywania problemów z jakością danych.
Uruchom funkcję
find_dependenciesSemPy na scalonej ramce danych, aby zidentyfikować wszelkie istniejące zależności funkcjonalne między wartościami w kolumnach:dependencies = customer_state_df.find_dependencies() dependenciesWizualizowanie zidentyfikowanych zależności przy użyciu funkcji
plot_dependency_metadatabiblioteki SemPy:plot_dependency_metadata(dependencies)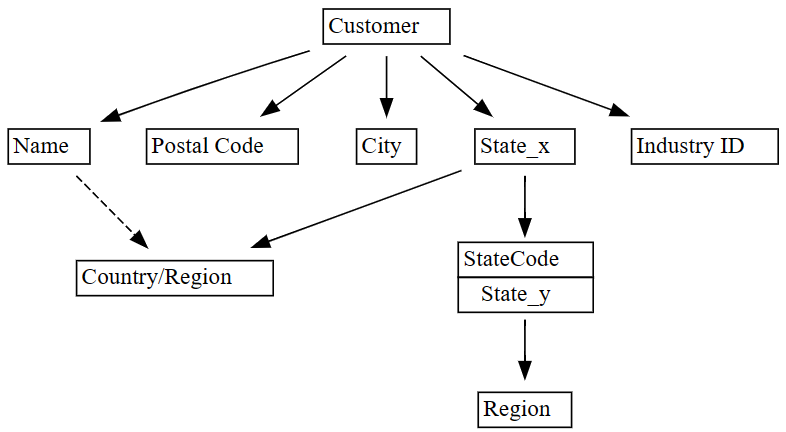
Zgodnie z oczekiwaniami wykres zależności funkcjonalnych pokazuje, że kolumna
Customerokreśla niektóre kolumny, takie jakCity,Postal CodeiName.Co zaskakujące, wykres nie pokazuje zależności funkcjonalnej między
CityaPostal Code, prawdopodobnie dlatego, że istnieje wiele naruszeń relacji między kolumnami. Funkcjaplot_dependency_violationsSemPy umożliwia wizualizowanie naruszeń zależności między określonymi kolumnami.

Eksplorowanie danych pod kątem problemów z jakością
Rysuj graf za pomocą funkcji wizualizacji
plot_dependency_violationsSemPy.customer_state_df.plot_dependency_violations('Postal Code', 'City')
Wykres naruszeń zależności przedstawia wartości dla
Postal Codepo lewej stronie i wartości dlaCitypo prawej stronie. Krawędź łączyPostal Codepo lewej stronie zCitypo prawej stronie, jeśli istnieje wiersz zawierający te dwie wartości. Krawędzie są oznaczone adnotacjami z liczbą takich wierszy. Na przykład są dwa wiersze z kodem pocztowym 20004: jeden z miastem "North Tower" i drugi z miastem "Waszyngton".Ponadto wykres przedstawia kilka naruszeń i wiele pustych wartości.
Potwierdź liczbę pustych wartości dla
Postal Code:customer_state_df['Postal Code'].isna().sum()50 wierszy ma wartość NA dla kodu pocztowego.
Usuwanie wierszy z pustymi wartościami. Następnie znajdź zależności przy użyciu funkcji
find_dependencies. Zwróć uwagę na dodatkowy parametrverbose=1, który oferuje wgląd w wewnętrzne działania SemPy:customer_state_df2=customer_state_df.dropna() customer_state_df2.find_dependencies(verbose=1)Entropia warunkowa dla
Postal CodeiCitywynosi 0,049. Ta wartość wskazuje, że istnieją naruszenia zależności funkcjonalnych. Przed naprawieniem naruszeń podnieś próg dla entropii warunkowej z wartości domyślnej0.01do0.05, aby zobaczyć zależności. Niższe progi powodują zmniejszenie zależności (lub wyższą selektywność).Podnieś próg entropii warunkowej z wartości domyślnej
0.01do0.05:plot_dependency_metadata(customer_state_df2.find_dependencies(threshold=0.05))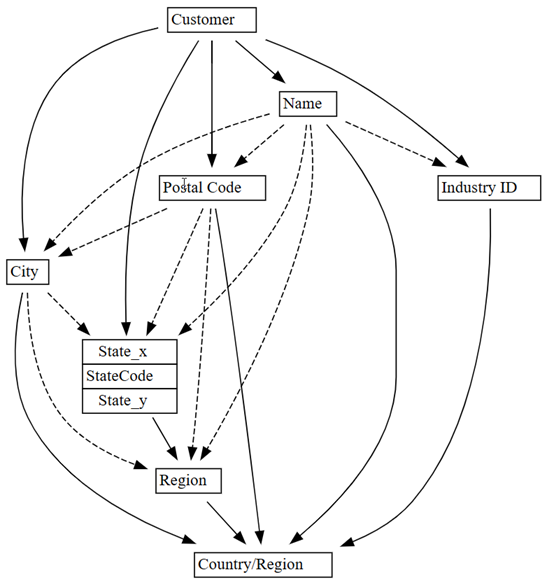
Jeśli zastosujesz wiedzę o domenie, która jednostka określa wartości innych jednostek, ten wykres zależności wydaje się dokładny.
Poznaj więcej wykrytych problemów z jakością danych. Na przykład strzałka przerywana łączy
CityiRegion, co wskazuje, że zależność jest jedynie przybliżona. Przybliżona relacja może oznaczać, że istnieje częściowa zależność funkcjonalna.customer_state_df.list_dependency_violations('City', 'Region')Przyjrzyj się bliżej każdemu z przypadków, w których niepusta wartość
Regionpowoduje naruszenie.customer_state_df[customer_state_df.City=='Downers Grove']Wynik pokazuje Downers Grove, miasto, znajdujące się w Illinois i Nebrasce. Jednak Downer's Grove jest miastem w Illinois, a nie w Nebrasce.
Przyjrzyj się miastu Fremont:
customer_state_df[customer_state_df.City=='Fremont']Istnieje miasto o nazwie Fremont w Kalifornii. Jednak w przypadku Teksasu wyszukiwarka zwraca Premont, a nie Fremont.
Podejrzane jest również widzieć naruszenia zależności między
NameiCountry/Region, oznaczone linią przerywaną w oryginalnym wykresie naruszeń zależności (przed usunięciem wierszy z brakującymi wartościami).customer_state_df.list_dependency_violations('Name', 'Country/Region')Wydaje się, że jeden klient, SDI Design jest obecny w dwóch regionach — Stany Zjednoczone i Kanada. To zdarzenie może nie być naruszeniem semantycznym, ale może być po prostu rzadkim przypadkiem. Mimo to warto przyjrzeć się bliżej:
Przyjrzyj się bliżej projektowi SDIklienta:
customer_state_df[customer_state_df.Name=='SDI Design']Dalsza kontrola pokazuje, że w rzeczywistości są to dwaj różni klienci (z różnych branż) o tym samym imieniu.

Eksplorowanie danych to ekscytujący proces, podobnie jak czyszczenie danych. Zawsze jest coś, co ukrywa dane, w zależności od tego, jak patrzysz na to, co chcesz zapytać itd. Link semantyczny dostarcza nowe narzędzia, których można użyć, aby osiągnąć więcej dzięki posiadanym danym.
Powiązana zawartość
Zapoznaj się z innymi samouczkami dotyczącymi linku semantycznego /SemPy:
- samouczek : czyszczenie danych z zależnościami funkcjonalnymi
- samouczek : wyodrębnianie i obliczanie miar usługi Power BI z notesu Jupyter
- Samouczek: odnajdywanie relacji w modelu semantycznym przy użyciu linku semantycznego
- samouczek
: odnajdywanie relacji w zestawie danych Synthea przy użyciu linku semantycznego - Samouczek : Weryfikowanie danych przy użyciu bibliotek SemPy i Great Expectations (GX)