Samouczek: czyszczenie danych przy użyciu zależności funkcjonalnych
W tym samouczku użyjesz zależności funkcjonalnych do czyszczenia danych. Zależność funkcjonalna istnieje, gdy jedna kolumna w modelu semantycznym (zestaw danych usługi Power BI) jest funkcją innej kolumny. Na przykład kolumna kodu pocztowego może określić wartości w kolumnie miasta. Zależność funkcjonalna manifestuje się jako relacja jeden do wielu między wartościami w co najmniej dwóch kolumnach w ramce danych. W tym samouczku użyto zestawu danych Synthea, aby pokazać, jak funkcjonalne relacje mogą pomóc wykrywać problemy z jakością danych.
Z tego samouczka dowiesz się, jak wykonywać następujące działania:
- Zastosuj wiedzę na temat domeny, aby sformułować hipotezy dotyczące zależności funkcjonalnych w modelu semantycznym.
- Zapoznaj się ze składnikami biblioteki języka Python linku semantycznego (SemPy), które pomagają zautomatyzować analizę jakości danych. Te składniki obejmują:
- FabricDataFrame — struktura podobna do pandas rozszerzona o dodatkowe informacje semantyczne.
- Przydatne funkcje automatyzujące ocenę hipotez dotyczących zależności funkcjonalnych i identyfikujące naruszenia relacji w modelach semantycznych.
Warunki wstępne
Pobierz subskrypcję usługi Microsoft Fabric . Możesz też utworzyć bezpłatne konto wersji próbnej usługi Microsoft Fabric.
Zaloguj się do usługi Microsoft Fabric.
Użyj przełącznika środowiska w lewej dolnej części strony głównej, aby przełączyć się na Fabric.

- Wybierz pozycję Obszary robocze w okienku nawigacji po lewej stronie, aby znaleźć i wybrać obszar roboczy. Ten obszar roboczy staje się aktualnym obszarem roboczym.
Podążaj za treścią w notesie
W ramach tego samouczka towarzyszy notes data_cleaning_functional_dependencies_tutorial.ipynb.
Aby otworzyć towarzyszący notatnik do tego samouczka, postępuj zgodnie z instrukcjami w Prepare your system for data science tutorials (Przygotuj swój system do samouczków data science), aby zaimportować notatnik do obszaru roboczego.
Jeśli wolisz skopiować i wkleić kod z tej strony, możesz utworzyć nowy notes.
Zanim rozpoczniesz uruchamianie kodu, pamiętaj, aby dołączyć lakehouse do notatnika.
Konfigurowanie notesu
W tej sekcji skonfigurujesz środowisko notesu z niezbędnymi modułami i danymi.
- W przypadku platformy Spark w wersji 3.4 lub nowszej link semantyczny jest dostępny w domyślnym środowisku uruchomieniowym podczas korzystania z Fabric i nie ma potrzeby jego instalowania. Jeśli używasz platformy Spark 3.3 lub nowszej lub chcesz zaktualizować do najnowszej wersji narzędzia Semantic Link, możesz uruchomić polecenie:
python %pip install -U semantic-link
Wykonaj niezbędne importy modułów, które będą potrzebne później:
import pandas as pd import sempy.fabric as fabric from sempy.fabric import FabricDataFrame from sempy.dependencies import plot_dependency_metadata from sempy.samples import download_syntheaŚciąganie przykładowych danych. Na potrzeby tego samouczka użyjesz syntetycznego zestawu danych medycznych Synthea (, mała wersja dla uproszczenia):
download_synthea(which='small')
Eksplorowanie danych
Zainicjuj
FabricDataFrameza pomocą zawartości pliku providers.csv.providers = FabricDataFrame(pd.read_csv("synthea/csv/providers.csv")) providers.head()Sprawdź, czy występują problemy z jakością danych z funkcją
find_dependenciesSemPy, wykreślijąc wykres automatycznie wykrywanych zależności funkcjonalnych:deps = providers.find_dependencies() plot_dependency_metadata(deps)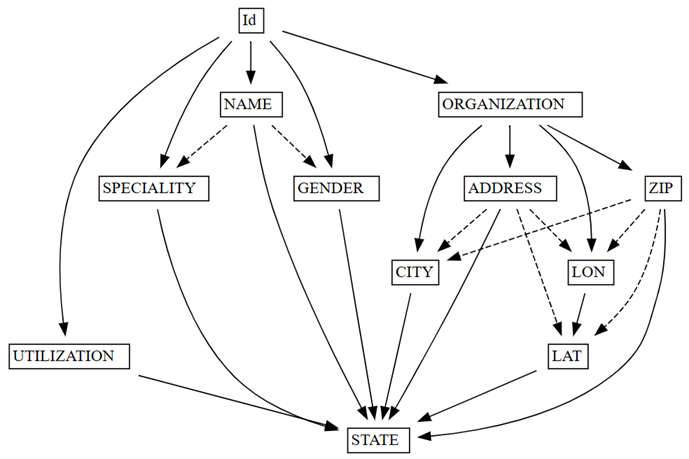
Wykres zależności funkcjonalnych pokazuje, że
IdokreślaNAMEiORGANIZATION(wskazywane przez stałe strzałki), które są oczekiwane, ponieważIdjest unikatowa:Upewnij się, że
Idjest unikatowa:providers.Id.is_uniqueKod zwraca
True, aby potwierdzić, żeIdjest unikatowa.

Analizowanie zależności funkcjonalnych wnikliwie
Wykres zależności funkcjonalnych pokazuje również, że ORGANIZATION określa ADDRESS i ZIP, zgodnie z oczekiwaniami. Można jednak oczekiwać, że ZIP może również określić CITY, ale strzałka kreskowana wskazuje, że zależność jest jedynie przybliżona, co wskazuje na problem z jakością danych.
Na wykresie istnieją inne osobliwości. Na przykład NAME nie określa GENDER, Id, SPECIALITYlub ORGANIZATION. Każda z tych osobliwości może być warta zbadania.
Przyjrzyj się bliżej przybliżonej relacji między
ZIPiCITYprzy użyciu funkcjilist_dependency_violationsSemPy, aby wyświetlić tabelaryczny wykaz naruszeń:providers.list_dependency_violations('ZIP', 'CITY')Rysuj graf za pomocą funkcji wizualizacji
plot_dependency_violationsSemPy. Ten wykres jest przydatny, jeśli liczba naruszeń jest mała:providers.plot_dependency_violations('ZIP', 'CITY')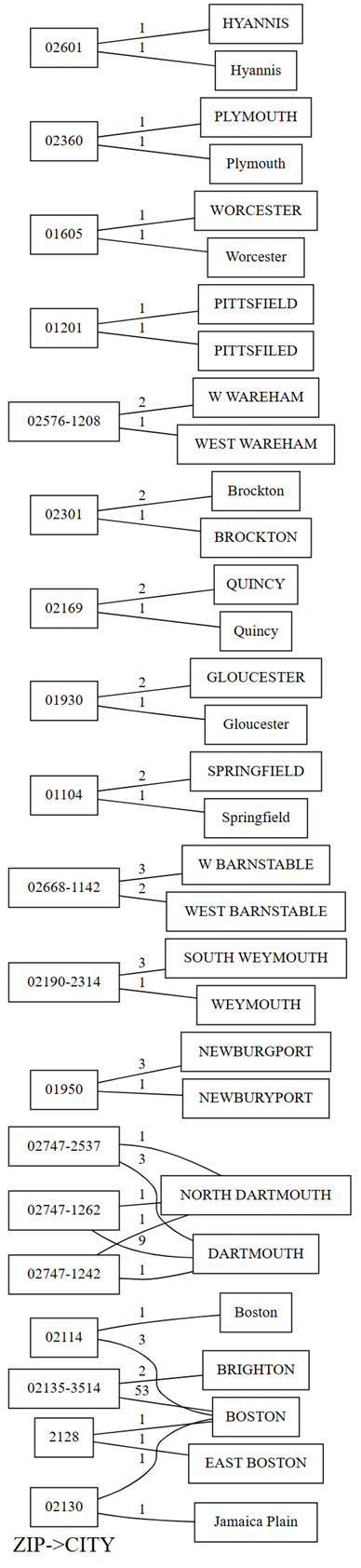
Wykres naruszeń zależności przedstawia wartości dla
ZIPpo lewej stronie i wartości dlaCITYpo prawej stronie. Krawędź łączy kod pocztowy po lewej stronie wykresu z miastem po prawej stronie, jeśli istnieje wiersz zawierający te dwie wartości. Krawędzie są oznaczone adnotacjami z liczbą takich wierszy. Na przykład istnieją dwa wiersze z kodem pocztowym 02747-1242, jeden wiersz z miastem "NORTH DARTHMOUTH", a drugi z miastem "DARTHMOUTH", jak pokazano na poprzednim wykresie i następującym kodzie:Potwierdź poprzednie obserwacje dokonane przy użyciu wykresu naruszeń zależności, uruchamiając następujący kod:
providers[providers.ZIP == '02747-1242'].CITY.value_counts()Wykres pokazuje również, że wśród wierszy, które mają
CITYjako "DARTHMOUTH", dziewięć wierszy maZIP02747-1262; jeden wiersz maZIP02747-1242; a jeden wiersz maZIP02747-2537. Potwierdza te obserwacje przy użyciu następującego kodu:providers[providers.CITY == 'DARTMOUTH'].ZIP.value_counts()Istnieją inne kody pocztowe skojarzone z "DARTMOUTH", ale te kody pocztowe nie są wyświetlane na wykresie naruszeń zależności, ponieważ nie wskazują na problemy z jakością danych. Na przykład kod pocztowy "02747-4302" jest jednoznacznie skojarzony z "DARTMOUTH" i nie jest wyświetlany na wykresie naruszeń zależności. Potwierdź, uruchamiając następujący kod:
providers[providers.ZIP == '02747-4302'].CITY.value_counts()
Podsumowywanie problemów z jakością danych wykrytych za pomocą rozwiązania SemPy
Wracając do wykresu naruszeń zależności, widać, że w tym modelu semantycznym występuje kilka interesujących problemów z jakością danych:
- Niektóre nazwy miast są pisane wielkimi literami. Ten problem jest łatwy do rozwiązania przy użyciu metod ciągów.
- Niektóre nazwy miast mają kwalifikatory (lub prefiksy), takie jak "Północ" i "Wschód". Na przykład kod pocztowy "2128" jest odwzorowany raz jako "EAST BOSTON" i raz jako "BOSTON". Podobny problem występuje między "NORTH DARTHMOUTH" i "DARTHMOUTH". Możesz spróbować usunąć te kwalifikatory lub przyporządkować kody pocztowe miastu, w którym występują najczęściej.
- W niektórych miastach istnieją literówki, takie jak „PITTSFIELD” a „PITTSFILED” oraz „NEWBURGPORT” a „NEWBURYPORT”. W przypadku "NEWBURGPORT" tę literówkę można poprawić, używając najczęściej używanej wersji. W przypadku "PITTSFIELD" posiadanie tylko jednego wystąpienia sprawia, że znacznie trudniej jest dokonać automatycznego rozróżniania bez wiedzy zewnętrznej lub użycia modelu językowego.
- Czasami prefiksy takie jak "Zachód" są skracane do pojedynczej litery "W". Ten problem może być potencjalnie rozwiązany za pomocą prostego zastąpienia, jeśli wszystkie wystąpienia litery "W" oznaczają "Zachód".
- Kod pocztowy "02130" odnosi się raz do "BOSTON" i raz do "Jamaica Plain." Ten problem nie jest łatwy do rozwiązania, ale gdyby było więcej danych, mapowanie na najbardziej typowe wystąpienie mogłoby być potencjalnym rozwiązaniem.
Czyszczenie danych
Rozwiąż problemy z wielkością liter, zmieniając wszystkie litery na format tytułowy.
providers['CITY'] = providers.CITY.str.title()Uruchom ponownie wykrywanie naruszeń, aby zobaczyć, że niektóre niejednoznaczności znikną (liczba naruszeń jest mniejsza):
providers.list_dependency_violations('ZIP', 'CITY')W tym momencie można bardziej ręcznie udoskonalić dane, ale jednym z potencjalnych zadań oczyszczania danych jest usunięcie wierszy naruszających ograniczenia funkcjonalne między kolumnami w danych przy użyciu funkcji
drop_dependency_violationsSemPy.Dla każdej wartości zmiennej decydującej
drop_dependency_violationsdziała, wybierając najbardziej typową wartość zmiennej zależnej i usuwając wszystkie wiersze z innymi wartościami. Należy zastosować tę operację tylko wtedy, gdy masz pewność, że ta statystyczna heurystyka doprowadzi do poprawnych wyników dla danych. W przeciwnym razie należy napisać własny kod, aby obsłużyć wykryte naruszenia zgodnie z potrzebami.Uruchom funkcję
drop_dependency_violationsw kolumnachZIPiCITY:providers_clean = providers.drop_dependency_violations('ZIP', 'CITY')Wyświetl wszystkie naruszenia zależności między
ZIPaCITY:providers_clean.list_dependency_violations('ZIP', 'CITY')Kod zwraca pustą listę wskazującą, że nie ma więcej naruszeń ograniczenia funkcjonalnego CITY —> ZIP.
Powiązana zawartość
Zapoznaj się z innymi samouczkami dotyczącymi linku semantycznego /SemPy:
- Samouczek: analizowanie zależności funkcjonalnych w przykładowym modelu semantycznym
- Samouczek : Wyodrębnianie i obliczanie miar Power BI z notesu Jupyter
- Samouczek: odnajdywanie relacji w modelu semantycznym przy użyciu linku semantycznego
- Samouczek : Odkrywanie relacji w zestawie danych Synthea, przy użyciu linku semantycznego
- samouczek : weryfikowanie danych przy użyciu bibliotekI SemPy i wielkich oczekiwań (GX)