Przesyłanie i wykonywanie zadań platformy Spark przy użyciu interfejsu API usługi Livy
Uwaga
Interfejs API usługi Livy dla usługi Fabric inżynierowie danych jest w wersji zapoznawczej.
Dotyczy:✅ inżynierowie danych i Nauka o danych w usłudze Microsoft Fabric
Rozpocznij pracę z usługą Livy API for Fabric inżynierowie danych, tworząc usługę Lakehouse, uwierzytelniając się przy użyciu tokenu aplikacji Microsoft Entra, przesyłając zadania wsadowe lub sesji z klienta zdalnego do obliczeń platformy Spark w usłudze Fabric. Odkryjesz punkt końcowy interfejsu API usługi Livy, przesyłasz zadania i monitorujesz wyniki.
Wymagania wstępne
Pojemność premium lub wersja próbna sieci szkieletowej z usługą LakeHouse
Włączanie ustawienia administratora dzierżawy dla interfejsu API usługi Livy (wersja zapoznawcza)
Klient zdalny, taki jak Program Visual Studio Code z obsługą notesów Jupyter, PySpark i Microsoft Authentication Library (MSAL) dla języka Python
Token aplikacji Entra firmy Microsoft jest wymagany do uzyskania dostępu do interfejsu API REST sieci szkieletowej. Rejestrowanie aplikacji za pomocą platformy tożsamości firmy Microsoft
Wybieranie klienta interfejsu API REST
Do interakcji z punktami końcowymi interfejsu API REST można używać różnych języków programowania lub klientów graficznego interfejsu UŻYTKOWNIKA. W tym artykule użyjemy programu Visual Studio Code. Program Visual Studio Code musi być skonfigurowany przy użyciu notesów Jupyter Notebook, PySpark i biblioteki Microsoft Authentication Library (MSAL) dla języka Python
Jak autoryzować żądania interfejsu API usługi Livy
Aby pracować z interfejsami API sieci Szkieletowej, w tym interfejsem API usługi Livy, musisz najpierw utworzyć aplikację Firmy Microsoft Entra i uzyskać token. Aplikacja musi być zarejestrowana i skonfigurowana odpowiednio do wykonywania wywołań interfejsu API w usłudze Fabric. Aby uzyskać więcej informacji, zobacz Rejestrowanie aplikacji przy użyciu Platforma tożsamości Microsoft.
Istnieje wiele uprawnień zakresu entra firmy Microsoft wymaganych do wykonywania zadań usługi Livy. W tym przykładzie użyto prostego kodu Spark i dostępu do magazynu + SQL:
- Code.AccessAzureDataExplorer.All
- Code.AccessAzureDataLake.All
- Code.AccessAzureKeyvault.All
- Code.AccessFabric.All
- Code.AccessStorage.All
- Item.ReadWrite.All
- Lakehouse.Execute.All
- Lakehouse.Read.All
- Workspace.ReadWrite.All

Uwaga
W publicznej wersji zapoznawczej dodamy kilka dodatkowych szczegółowych zakresów. Jeśli używasz tej metody, po dodaniu tych dodatkowych zakresów aplikacja Livy zostanie przerwana. Sprawdź tę listę, ponieważ zostanie ona zaktualizowana o dodatkowe zakresy.
Niektórzy klienci chcą mieć bardziej szczegółowe uprawnienia niż poprzednia lista. Możesz usunąć element Item.ReadWrite.All i zastąpić tymi bardziej szczegółowymi uprawnieniami zakresu:
- Code.AccessAzureDataExplorer.All
- Code.AccessAzureDataLake.All
- Code.AccessAzureKeyvault.All
- Code.AccessFabric.All
- Code.AccessStorage.All
- Lakehouse.Execute.All
- Lakehouse.ReadWrite.All
- Workspace.ReadWrite.All
- Notebook.ReadWrite.All
- SparkJobDefinition.ReadWrite.All
- MLModel.ReadWrite.All
- MLExperiment.ReadWrite.All
- Dataset.ReadWrite.All
Po zarejestrowaniu aplikacji będziesz potrzebować zarówno identyfikatora aplikacji (klienta), jak i identyfikatora katalogu (dzierżawy).
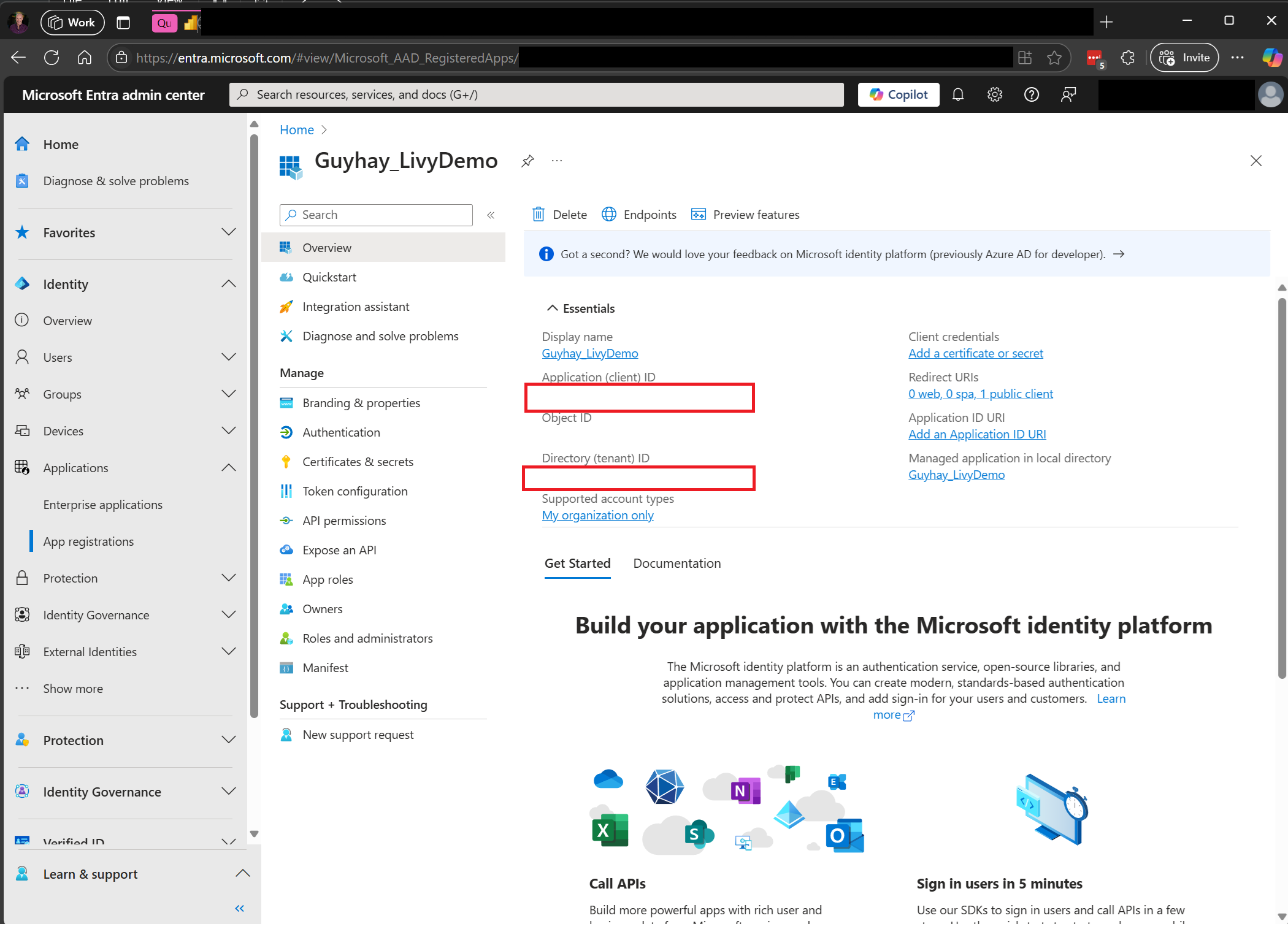
Uwierzytelniony użytkownik wywołujący interfejs API usługi Livy musi być członkiem obszaru roboczego, w którym znajdują się zarówno elementy interfejsu API, jak i źródła danych z rolą Współautor. Aby uzyskać więcej informacji, zobacz Przyznawanie użytkownikom dostępu do obszarów roboczych.
Jak odnaleźć punkt końcowy interfejsu API usługi Livy usługi Fabric
Artefakt usługi Lakehouse jest wymagany do uzyskania dostępu do punktu końcowego usługi Livy. Po utworzeniu usługi Lakehouse punkt końcowy interfejsu API usługi Livy może znajdować się w panelu ustawień.

Punkt końcowy interfejsu API usługi Livy będzie postępować zgodnie z tym wzorcem:
https://api.fabric.microsoft.com/v1/workspaces/ < >ws_id/lakehouses/<lakehouse_id>/livyapi/versions/2023-12-01/
Adres URL jest dołączany do <sesji lub >partii<> w zależności od wybranej opcji.
Integracja ze środowiskami sieci szkieletowej
Dla każdego obszaru roboczego sieć szkieletowa jest aprowizowana domyślna pula początkowa, wykonanie całego kodu platformy Spark domyślnie używa tej puli startowej. Za pomocą środowisk sieci szkieletowej można dostosować zadania platformy Spark interfejsu API usługi Livy.
Pobierz pliki Swagger interfejsu API Livy
Pełne pliki programu Swagger dla interfejsu API usługi Livy są dostępne tutaj.
Przesyłanie zadań interfejsu API usługi Livy
Po zakończeniu konfiguracji API Livy możesz przesyłać zadania jako wsadowe lub sesyjne.
- Przesyłanie zadań sesji przy użyciu interfejsu API usługi Livy
- Przesyłanie zadań usługi Batch przy użyciu interfejsu API usługi Livy
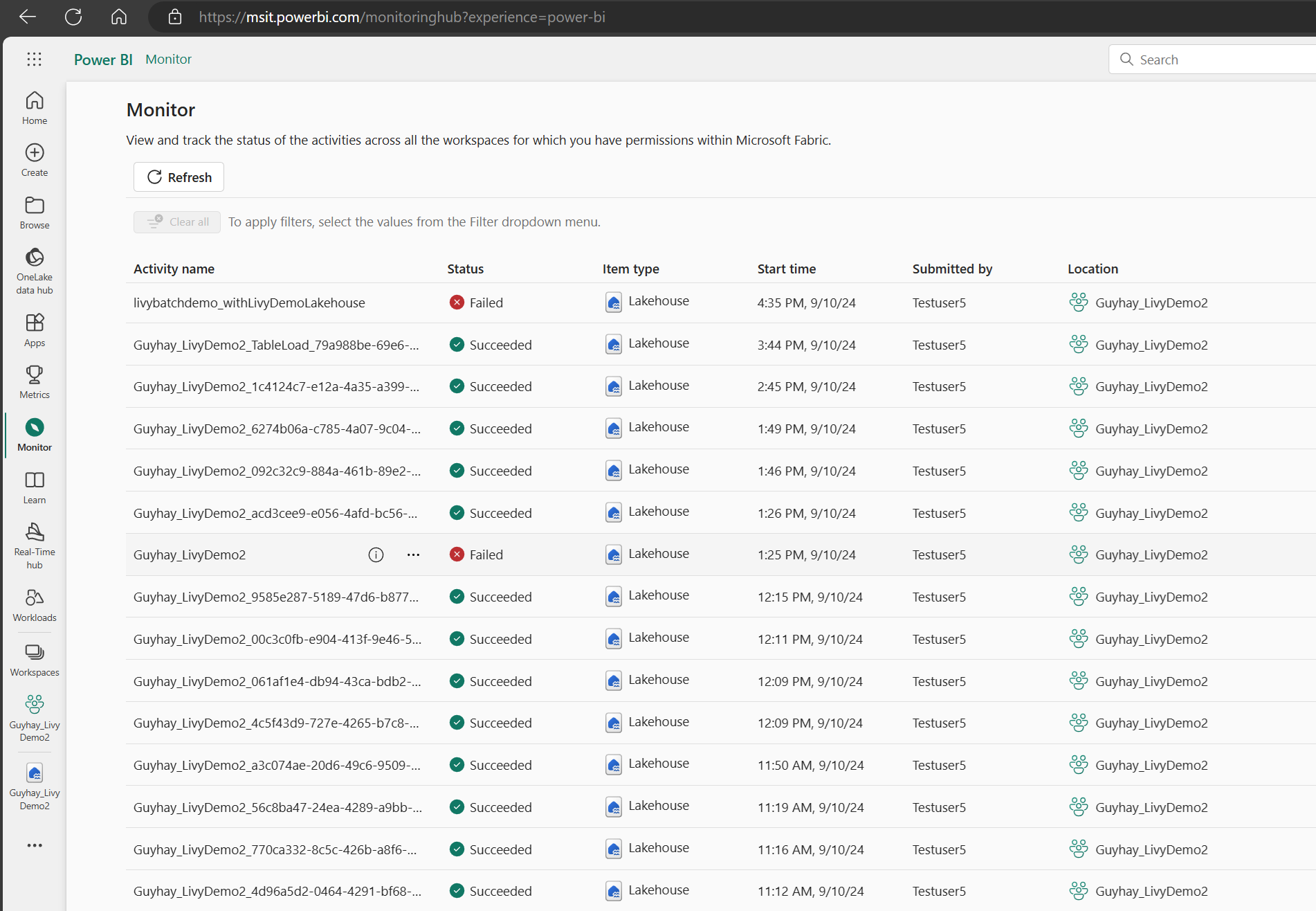
Jak monitorować historię żądań
Możesz użyć centrum monitorowania, aby wyświetlić wcześniejsze przesyłanie interfejsu API usługi Livy i debugować wszelkie błędy przesyłania.
Powiązana zawartość
- Dokumentacja interfejsu API REST usługi Apache Livy
- Wprowadzenie do ustawień administratora dla pojemności sieci szkieletowej
- Ustawienia administracyjne obszaru roboczego platformy Apache Spark w usłudze Microsoft Fabric
- Rejestrowanie aplikacji za pomocą platformy tożsamości firmy Microsoft
- Omówienie uprawnień i zgody firmy Microsoft
- Zakresy interfejsu API REST sieci szkieletowej
- Omówienie monitorowania platformy Apache Spark
- Szczegóły aplikacji platformy Apache Spark