Przesyłanie i wykonywanie zadań wsadowych usługi Livy przy użyciu interfejsu API usługi Livy
Uwaga
Interfejs API usługi Livy dla usługi Fabric inżynierowie danych jest w wersji zapoznawczej.
Dotyczy:✅ inżynierowie danych i Nauka o danych w usłudze Microsoft Fabric
Przesyłanie zadań wsadowych platformy Spark przy użyciu interfejsu API usługi Livy for Fabric inżynierowie danych ing.
Wymagania wstępne
Pojemność premium lub wersja próbna sieci szkieletowej z usługą Lakehouse.
Klient zdalny, taki jak Program Visual Studio Code z notesami Jupyter Notebook, PySpark i biblioteką Microsoft Authentication Library (MSAL) dla języka Python.
Token aplikacji Entra firmy Microsoft jest wymagany do uzyskania dostępu do interfejsu API REST sieci szkieletowej. Zarejestruj aplikację w Platforma tożsamości Microsoft.
Niektóre dane w lakehouse, w tym przykładzie użyto NYC Taxi & Limousine Commission green_tripdata_2022_08 plik parquet załadowany do jeziora.
Interfejs API usługi Livy definiuje ujednolicony punkt końcowy dla operacji. Zastąp symbole zastępcze {Entra_TenantID}, {Entra_ClientID}, {Fabric_WorkspaceID} i {Fabric_LakehouseID} odpowiednimi wartościami, korzystając z przykładów w tym artykule.
Konfigurowanie programu Visual Studio Code dla usługi Livy API Batch
Wybierz pozycję Lakehouse Settings (Ustawienia usługi Lakehouse) w usłudze Fabric Lakehouse.

Przejdź do sekcji Punkt końcowy usługi Livy.
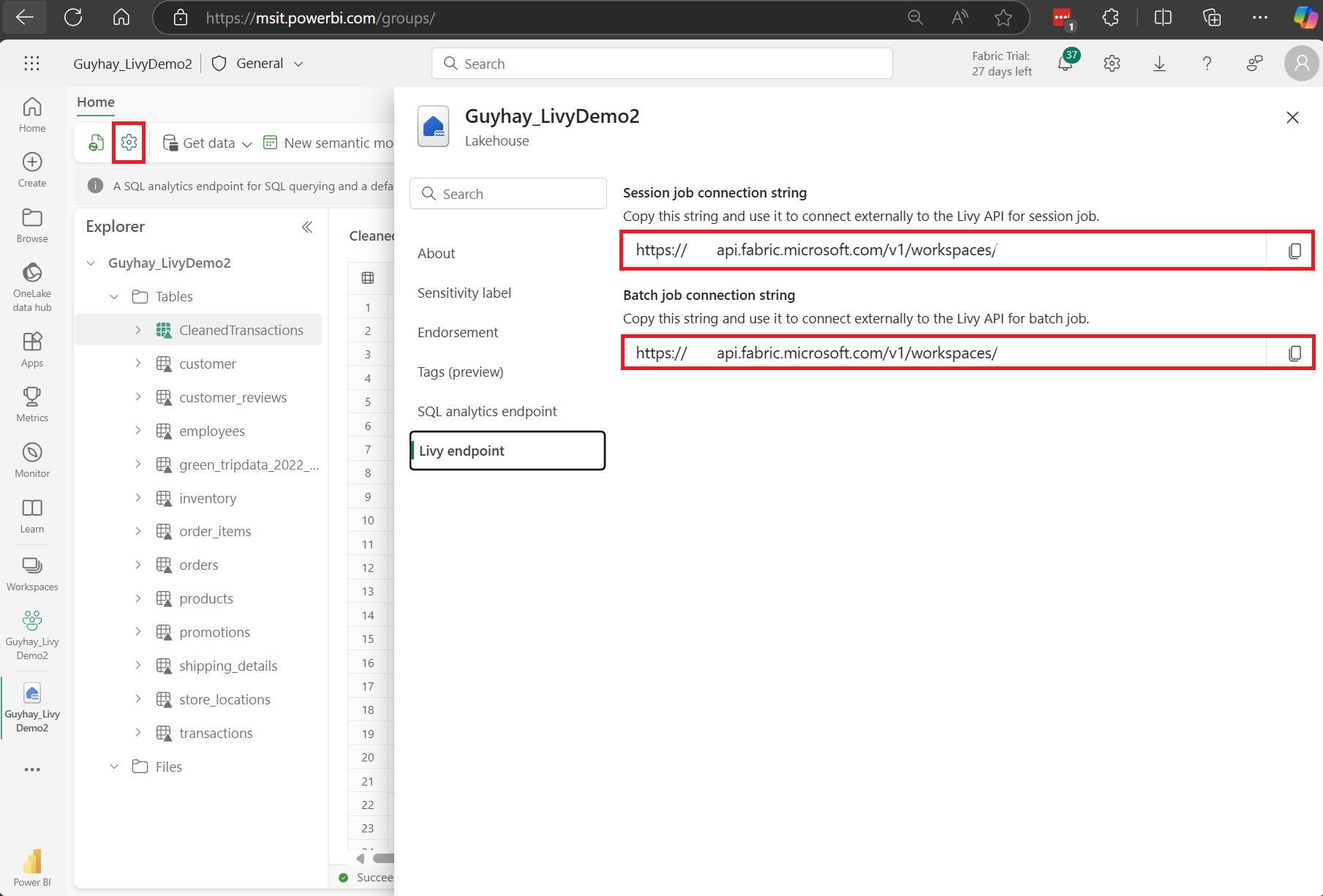
Skopiuj zadanie usługi Batch parametry połączenia (drugie czerwone pole na obrazie) do kodu.
Przejdź do centrum administracyjnego firmy Microsoft Entra i skopiuj identyfikator aplikacji (klienta) i identyfikator katalogu (dzierżawy) do kodu.
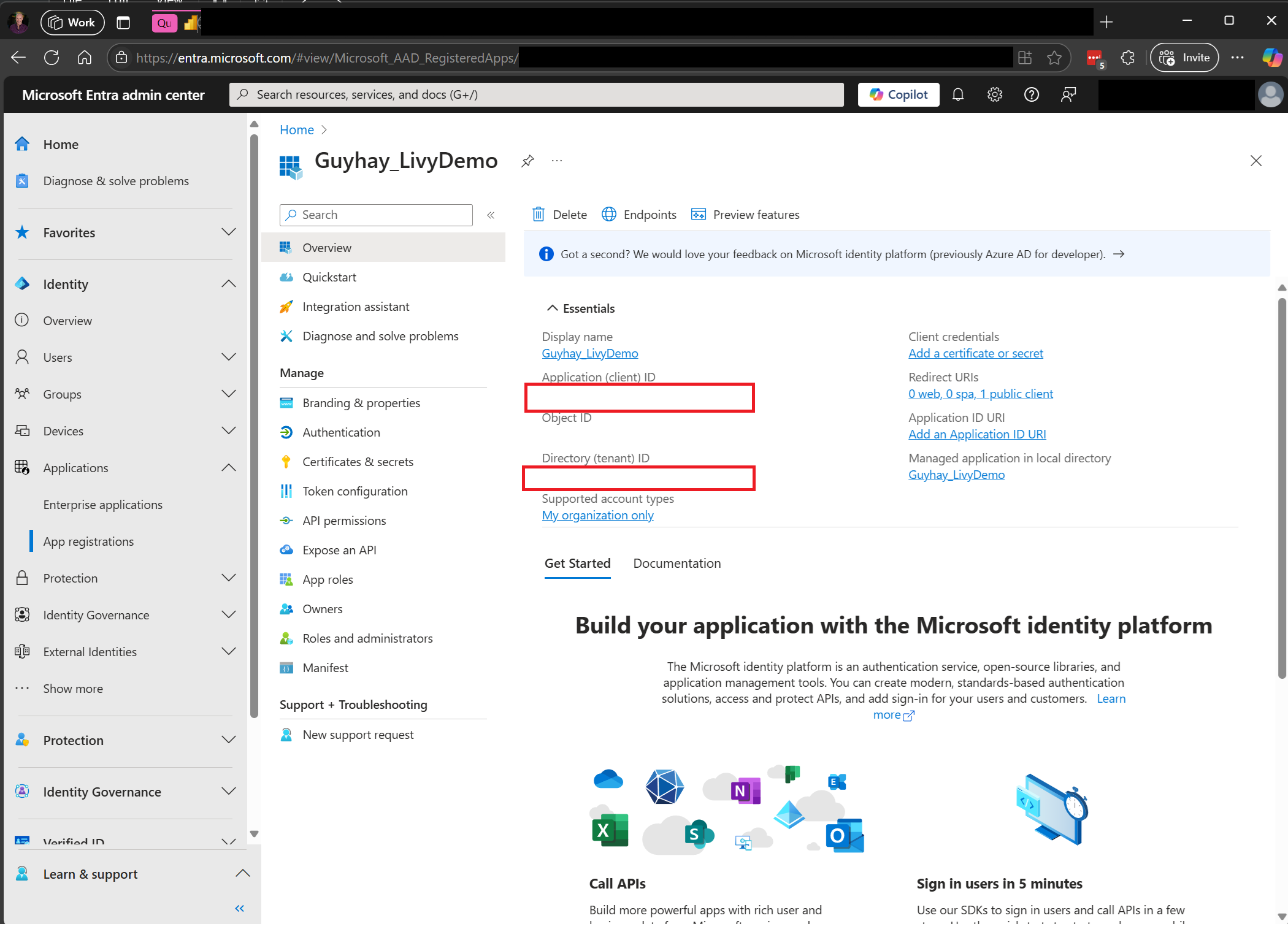



Tworzenie ładunku platformy Spark i przekazywanie go do usługi Lakehouse
Tworzenie notesu
.ipynbw programie Visual Studio Code i wstawianie następującego koduimport sys import os from pyspark.sql import SparkSession from pyspark.conf import SparkConf from pyspark.sql.functions import col if __name__ == "__main__": #Spark session builder spark_session = (SparkSession .builder .appName("livybatchdemo") .getOrCreate()) spark_context = spark_session.sparkContext spark_context.setLogLevel("DEBUG") targetLakehouse = spark_context.getConf().get("spark.targetLakehouse") if targetLakehouse is not None: print("targetLakehouse: " + str(targetLakehouse)) else: print("targetLakehouse is None") df_valid_totalPrice = spark_session.sql("SELECT * FROM <YourLakeHouseDataTableName>.transactions where TotalPrice > 0") df_valid_totalPrice_plus_year = df_valid_totalPrice.withColumn("transaction_year", col("TransactionDate").substr(1, 4)) deltaTablePath = "abfss:<YourABFSSpath>"+str(targetLakehouse)+".Lakehouse/Tables/CleanedTransactions" df_valid_totalPrice_plus_year.write.mode('overwrite').format('delta').save(deltaTablePath)Zapisz plik w języku Python lokalnie. Ten ładunek kodu w języku Python zawiera dwie instrukcje platformy Spark, które działają na danych w usłudze Lakehouse i muszą zostać przekazane do usługi Lakehouse. Ścieżka ABFS danych będzie potrzebna do referencji w zadaniu przetwarzania wsadowego API Livy w programie Visual Studio Code oraz nazwa tabeli Lakehouse w instrukcji SQL SELECT.
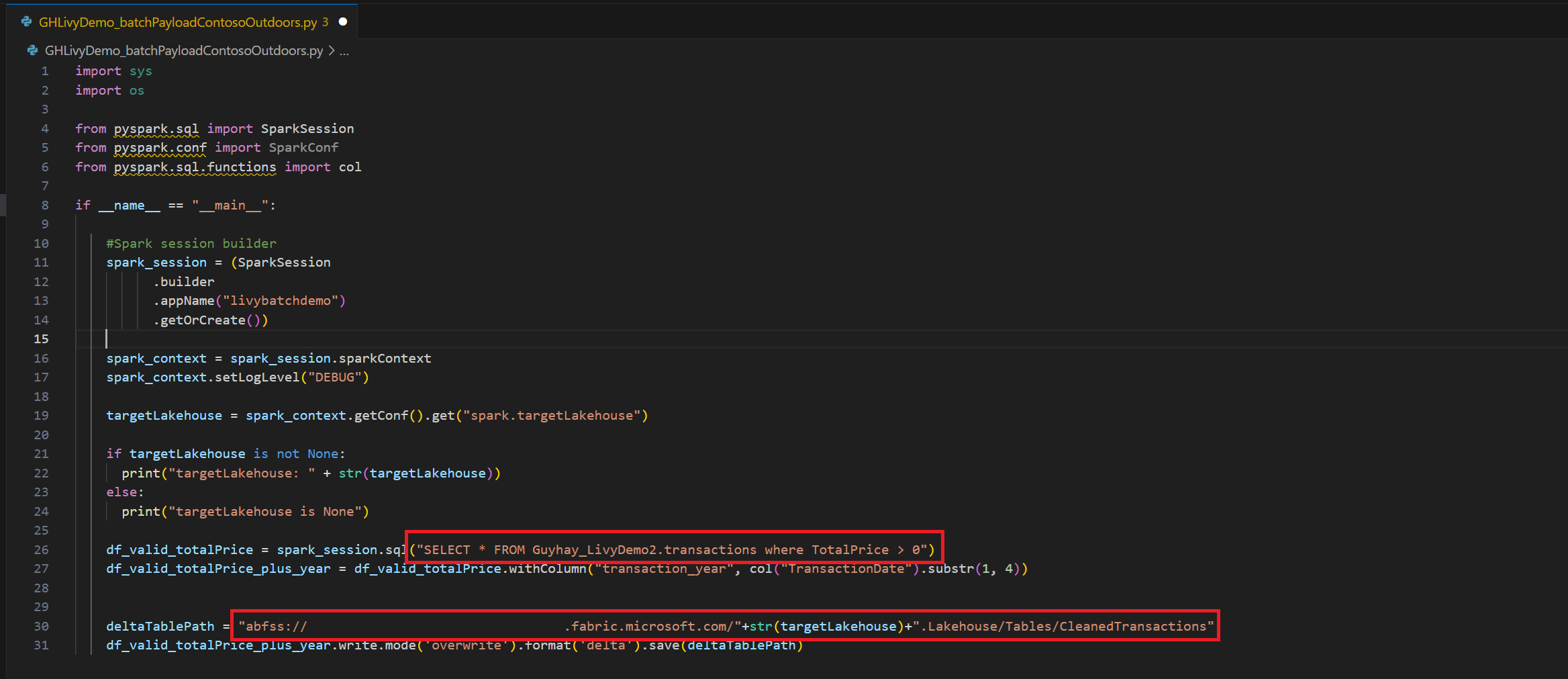
Przekaż ładunek języka Python do sekcji plików usługi Lakehouse. > Pobierz dane > Przekaż pliki > kliknij w polu Pliki/dane wejściowe.

Gdy plik znajduje się w sekcji Pliki usługi Lakehouse, kliknij trzy kropki po prawej stronie nazwy pliku ładunku i wybierz pozycję Właściwości.
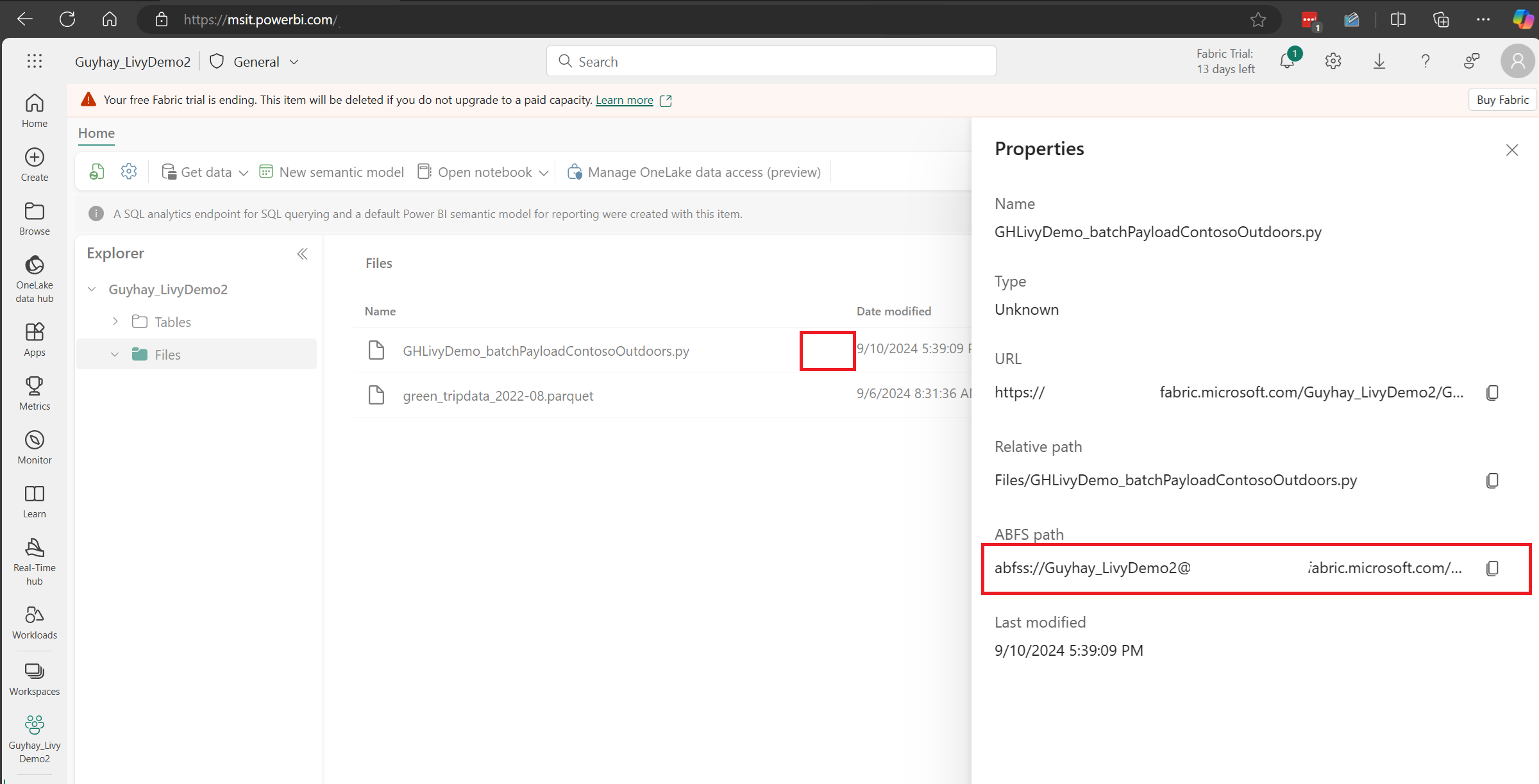
Skopiuj tę ścieżkę ABFS do komórki notesu w kroku 1.



Tworzenie sesji wsadowej interfejsu API usługi Livy Spark
.ipynbUtwórz notes w programie Visual Studio Code i wstaw następujący kod.from msal import PublicClientApplication import requests import time tenant_id = "<Entra_TenantID>" client_id = "<Entra_ClientID>" workspace_id = "<Fabric_WorkspaceID>" lakehouse_id = "<Fabric_LakehouseID>" app = PublicClientApplication( client_id, authority="https://login.microsoftonline.com/43a26159-4e8e-442a-9f9c-cb7a13481d48" ) result = None # If no cached tokens or user interaction needed, acquire tokens interactively if not result: result = app.acquire_token_interactive(scopes=["https://api.fabric.microsoft.com/Lakehouse.Execute.All", "https://api.fabric.microsoft.com/Lakehouse.Read.All", "https://api.fabric.microsoft.com/Item.ReadWrite.All", "https://api.fabric.microsoft.com/Workspace.ReadWrite.All", "https://api.fabric.microsoft.com/Code.AccessStorage.All", "https://api.fabric.microsoft.com/Code.AccessAzureKeyvault.All", "https://api.fabric.microsoft.com/Code.AccessAzureDataExplorer.All", "https://api.fabric.microsoft.com/Code.AccessAzureDataLake.All", "https://api.fabric.microsoft.com/Code.AccessFabric.All"]) # Print the access token (you can use it to call APIs) if "access_token" in result: print(f"Access token: {result['access_token']}") else: print("Authentication failed or no access token obtained.") if "access_token" in result: access_token = result['access_token'] api_base_url_mist='https://api.fabric.microsoft.com/v1' livy_base_url = api_base_url_mist + "/workspaces/"+workspace_id+"/lakehouses/"+lakehouse_id +"/livyApi/versions/2023-12-01/batches" headers = {"Authorization": "Bearer " + access_token}Uruchom komórkę notesu. W przeglądarce powinno pojawić się okno podręczne umożliwiające wybranie tożsamości do zalogowania się.
Po wybraniu tożsamości do logowania się zostanie również wyświetlony monit o zatwierdzenie uprawnień interfejsu API rejestracji aplikacji Firmy Microsoft Entra.

Zamknij okno przeglądarki po zakończeniu uwierzytelniania.

W programie Visual Studio Code powinien zostać zwrócony token Entra firmy Microsoft.
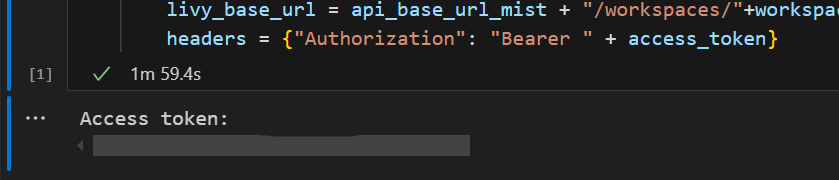
Dodaj kolejną komórkę notesu i wstaw ten kod.
# call get batch API get_livy_get_batch = livy_base_url get_batch_response = requests.get(get_livy_get_batch, headers=headers) if get_batch_response.status_code == 200: print("API call successful") print(get_batch_response.json()) else: print(f"API call failed with status code: {get_batch_response.status_code}") print(get_batch_response.text)Uruchom komórkę notesu. Powinny zostać wyświetlone dwa wiersze wydrukowane podczas tworzenia zadania wsadowego usługi Livy.
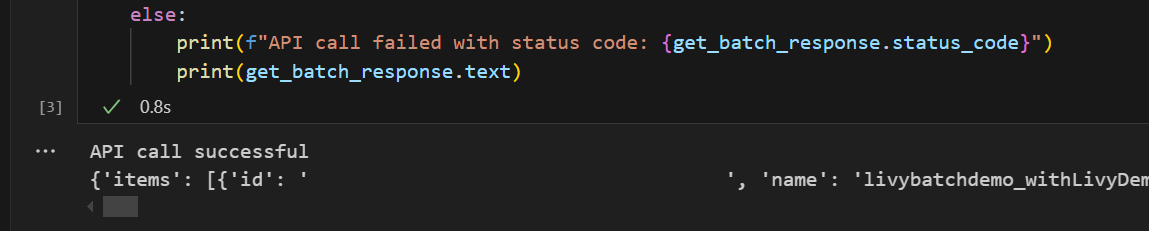





Przesyłanie instrukcji spark.sql przy użyciu sesji wsadowej interfejsu API usługi Livy
Dodaj kolejną komórkę notesu i wstaw ten kod.
# submit payload to existing batch session print('Submit a spark job via the livy batch API to ') newlakehouseName = "YourNewLakehouseName" create_lakehouse = api_base_url_mist + "/workspaces/" + workspace_id + "/items" create_lakehouse_payload = { "displayName": newlakehouseName, "type": 'Lakehouse' } create_lakehouse_response = requests.post(create_lakehouse, headers=headers, json=create_lakehouse_payload) print(create_lakehouse_response.json()) payload_data = { "name":"livybatchdemo_with"+ newlakehouseName, "file":"abfss://YourABFSPathToYourPayload.py", "conf": { "spark.targetLakehouse": "Fabric_LakehouseID" } } get_batch_response = requests.post(get_livy_get_batch, headers=headers, json=payload_data) print("The Livy batch job submitted successful") print(get_batch_response.json())Uruchom komórkę notesu. Po utworzeniu i uruchomieniu zadania usługi Livy Batch powinno zostać wyświetlonych kilka wierszy.

Wróć do usługi Lakehouse, aby zobaczyć zmiany.

Wyświetlanie zadań w centrum monitorowania
Aby wyświetlić różne działania platformy Apache Spark, możesz uzyskać dostęp do centrum monitorowania, wybierając pozycję Monitoruj w linkach nawigacji po lewej stronie.
Po zakończeniu zadania wsadowego możesz wyświetlić stan sesji, przechodząc do pozycji Monitor.
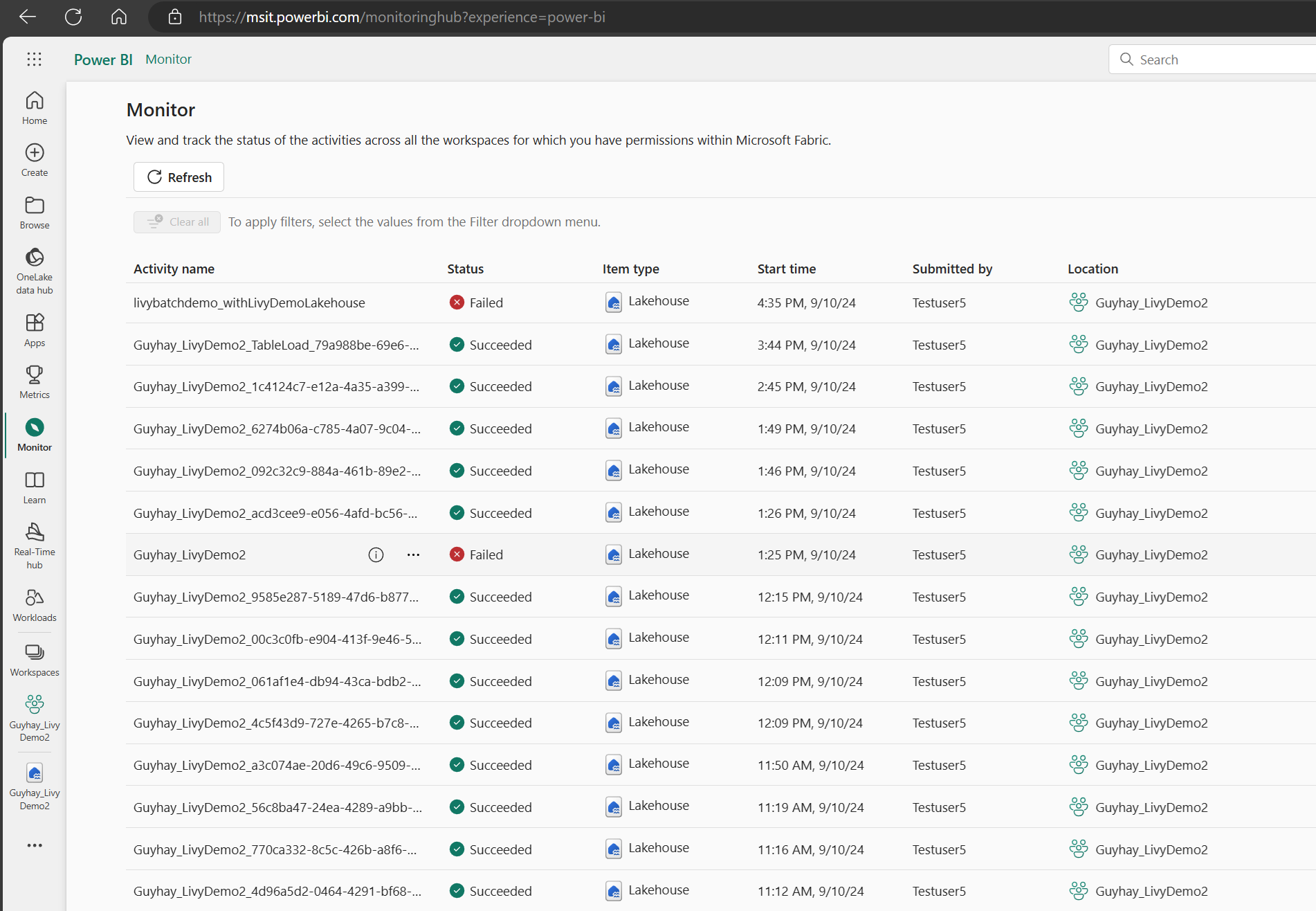
Wybierz i otwórz najnowszą nazwę działania.
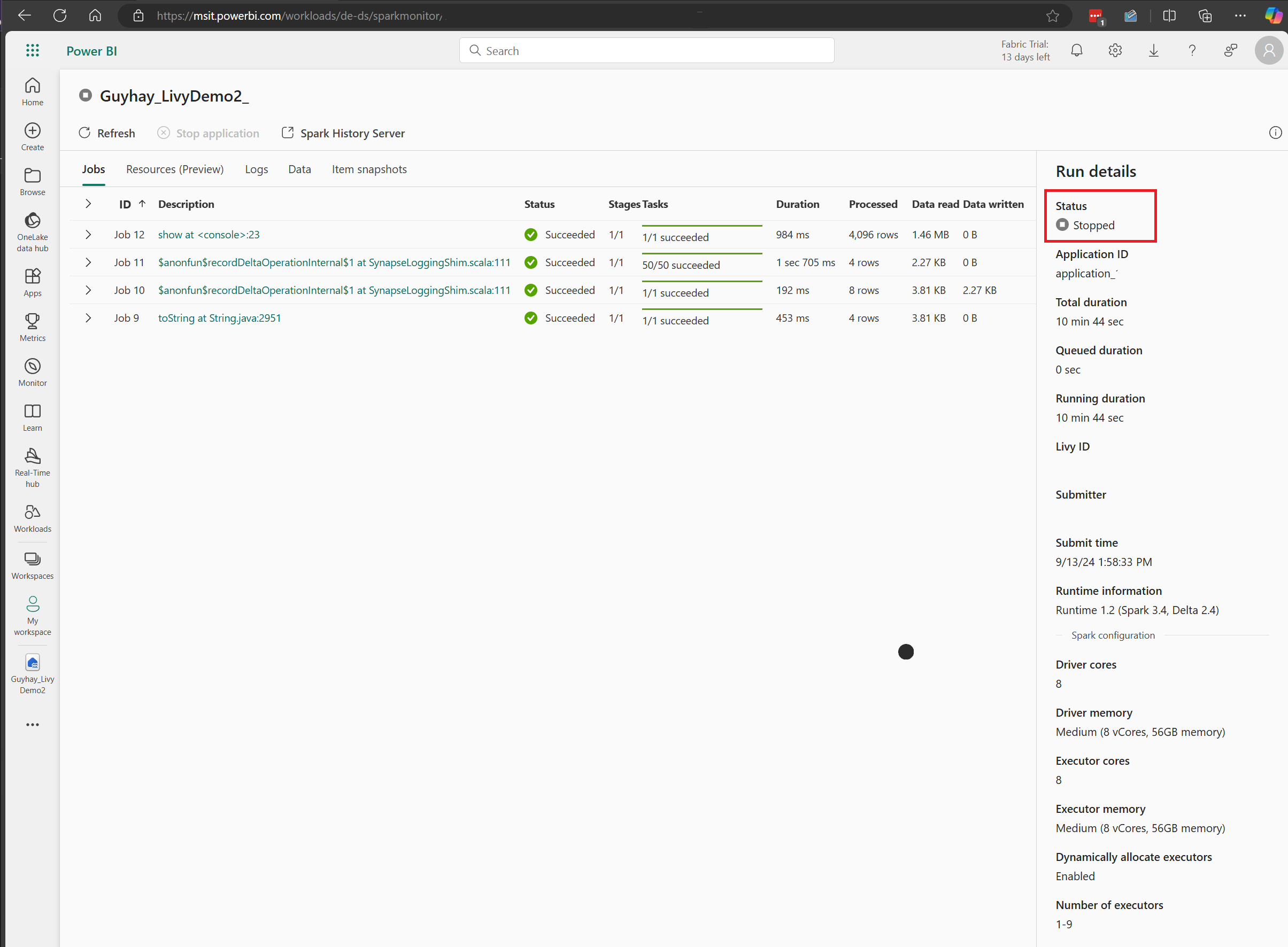
W tym przypadku sesji interfejsu API usługi Livy możesz zobaczyć poprzednie przesyłanie wsadowe, szczegóły uruchomienia, wersje platformy Spark i konfigurację. Zwróć uwagę na zatrzymany stan w prawym górnym rogu.



Aby podsumować cały proces, potrzebny jest klient zdalny, taki jak Visual Studio Code, token aplikacji Microsoft Entra, adres URL punktu końcowego interfejsu API usługi Livy, uwierzytelnianie względem usługi Lakehouse, ładunek spark w usłudze Lakehouse, a na koniec sesja interfejsu API usługi Livy w usłudze Batch.