Magazyn wektorowy w usłudze Azure AI Search
Usługa Azure AI Search udostępnia magazyn wektorów i konfiguracje wyszukiwania wektorów i wyszukiwania hybrydowego. Obsługa jest implementowana na poziomie pola, co oznacza, że można połączyć pola wektorowe i niewektorowe w tym samym korpusie wyszukiwania.
Wektory są przechowywane w indeksie wyszukiwania. Użyj interfejsu API REST tworzenia indeksu lub równoważnej metody zestawu Azure SDK, aby utworzyć magazyn wektorów.
Zagadnienia dotyczące magazynu wektorów obejmują następujące kwestie:
- Zaprojektuj schemat, aby dopasować przypadek użycia na podstawie zamierzonego wzorca pobierania wektorów.
- Szacowanie rozmiaru indeksu i sprawdzanie pojemności usługi wyszukiwania.
- Zarządzanie magazynem wektorów
- Zabezpieczanie magazynu wektorów
Wzorce pobierania wektorów
W usłudze Azure AI Search istnieją dwa wzorce pracy z wynikami wyszukiwania.
Wyszukiwanie generowania. Modele językowe formułują odpowiedź na zapytanie użytkownika przy użyciu danych z usługi Azure AI Search. Ten wzorzec zawiera warstwę aranżacji, aby koordynować monity i obsługiwać kontekst. W tym wzorcu wyniki wyszukiwania są przekazywane do przepływów monitów, odbieranych przez modele czatów, takie jak GPT i Text-Davinci. Takie podejście jest oparte na architekturze rozszerzonej generacji pobierania (RAG), w której indeks wyszukiwania udostępnia dane uziemienia.
Wyszukiwanie klasyczne przy użyciu paska wyszukiwania, ciągu wejściowego zapytania i renderowanych wyników. Aparat wyszukiwania akceptuje i wykonuje zapytanie wektorowe, formułuje odpowiedź i renderuje te wyniki w aplikacji klienckiej. W usłudze Azure AI Search wyniki są zwracane w spłaszczonego zestawu wierszy i można wybrać pola do uwzględnienia wyników wyszukiwania. Ponieważ nie ma modelu czatu, należy oczekiwać, że wypełnisz magazyn wektorów (indeks wyszukiwania) zawartością niewektora, która jest czytelna dla człowieka w odpowiedzi. Mimo że wyszukiwarka pasuje do wektorów, należy użyć wartości niewektorów, aby wypełnić wyniki wyszukiwania. Zapytania wektorowe i zapytania hybrydowe obejmują typy żądań zapytań, które można sformułować dla klasycznych scenariuszy wyszukiwania.
Schemat indeksu powinien odzwierciedlać podstawowy przypadek użycia. W poniższej sekcji przedstawiono różnice w kompozycji pól dla rozwiązań utworzonych na potrzeby generowania sztucznej inteligencji lub wyszukiwania klasycznego.
Schemat magazynu wektorów
Schemat indeksu dla magazynu wektorów wymaga nazwy, pola klucza (ciągu), co najmniej jednego pola wektora i konfiguracji wektora. Pola niewektorowe są zalecane w przypadku zapytań hybrydowych lub zwracania pełnej zawartości czytelnej dla człowieka, która nie musi przechodzić przez model językowy. Aby uzyskać instrukcje dotyczące konfiguracji wektorów, zobacz Tworzenie magazynu wektorów.
Podstawowa konfiguracja pola wektora
Pola wektorowe są rozróżniane przez ich typ danych i właściwości specyficzne dla wektorów. Oto, jak wygląda pole wektorowe w kolekcji pól:
{
"name": "content_vector",
"type": "Collection(Edm.Single)",
"searchable": true,
"retrievable": true,
"dimensions": 1536,
"vectorSearchProfile": "my-vector-profile"
}
Pola wektorowe mają określone typy danych. Obecnie jest to najbardziej typowe, Collection(Edm.Single) ale użycie wąskich typów danych może zaoszczędzić w magazynie.
Pola wektorowe muszą być przeszukiwalne i możliwe do pobrania, ale nie mogą być filtrowalne, aspektowe lub sortowalne albo mają analizatory, normalizacje lub przypisania mapy synonimów.
Pola wektorowe muszą mieć dimensions ustawioną liczbę osadzonych elementów wygenerowanych przez model osadzania. Na przykład osadzanie tekstu-ada-002 generuje 1536 osadzania dla każdego fragmentu tekstu.
Pola wektorowe są indeksowane przy użyciu algorytmów wskazywanych przez profil wyszukiwania wektorowego, który jest zdefiniowany gdzie indziej w indeksie, a tym samym nie jest wyświetlany w przykładzie. Aby uzyskać więcej informacji, zobacz Konfiguracja wyszukiwania wektorów.
Kolekcja pól dla obciążeń wektorów podstawowych
Magazyny wektorów wymagają większej liczby pól oprócz pól wektorów. Na przykład pole klucza ("id" w tym przykładzie) jest wymaganiem indeksu.
"name": "example-basic-vector-idx",
"fields": [
{ "name": "id", "type": "Edm.String", "searchable": false, "filterable": true, "retrievable": true, "key": true },
{ "name": "content_vector", "type": "Collection(Edm.Single)", "searchable": true, "retrievable": true, "dimensions": 1536, "vectorSearchProfile": null },
{ "name": "content", "type": "Edm.String", "searchable": true, "retrievable": true, "analyzer": null },
{ "name": "metadata", "type": "Edm.String", "searchable": true, "filterable": true, "retrievable": true, "sortable": true, "facetable": true }
]
Inne pola, takie jak "content" pole, zapewniają czytelny dla człowieka odpowiednik "content_vector" pola. Jeśli używasz modeli językowych wyłącznie do formułowania odpowiedzi, możesz pominąć pola zawartości niewektorów, ale rozwiązania, które wypychają wyniki wyszukiwania bezpośrednio do aplikacji klienckich, powinny mieć zawartość niewektora.
Pola metadanych są przydatne w przypadku filtrów, zwłaszcza jeśli metadane zawierają informacje o pochodzeniu dokumentu źródłowego. Nie można filtrować bezpośrednio w polu wektorowym, ale można ustawić tryby filtrowania wstępnego lub postfiltru, aby filtrować przed wykonaniem zapytania wektorowego lub po nim.
Schemat wygenerowany przez kreatora importu i wektoryzacji danych
Zalecamy kreator importowania i wektoryzacji danych na potrzeby testowania oceny i weryfikacji koncepcji. Kreator generuje przykładowy schemat w tej sekcji.
Stronniczość tego schematu polega na tym, że dokumenty wyszukiwania są kompilowane wokół fragmentów danych. Jeśli model językowy formułuje odpowiedź, co jest typowe dla aplikacji RAG, potrzebujesz schematu zaprojektowanego wokół fragmentów danych.
Fragmentowanie danych jest niezbędne do pozostanenia w granicach wejściowych modeli językowych, ale zwiększa również precyzję wyszukiwania podobieństwa, gdy zapytania mogą być dopasowywane do mniejszych fragmentów zawartości pobieranej z wielu dokumentów nadrzędnych. Na koniec, jeśli używasz semantycznego rankera, semantyczny ranga ma również limity tokenów, które są łatwiejsze do spełnienia, jeśli fragmentowanie danych jest częścią podejścia.
W poniższym przykładzie dla każdego dokumentu wyszukiwania istnieje jeden identyfikator fragmentu, fragment, tytuł i pole wektorowe. Identyfikator fragmentu i identyfikator nadrzędny są wypełniane przez kreatora przy użyciu podstawowego 64 kodowania metadanych obiektu blob (ścieżka). Fragment i tytuł pochodzą z zawartości obiektów blob i nazwy obiektów blob. Tylko pole wektorowe jest w pełni generowane. Jest to wektoryzowana wersja pola fragmentu. Osadzanie jest generowane przez wywołanie podanego modelu osadzania usługi Azure OpenAI.
"name": "example-index-from-import-wizard",
"fields": [
{"name": "chunk_id", "type": "Edm.String", "key": true, "searchable": true, "filterable": true, "retrievable": true, "sortable": true, "facetable": true, "analyzer": "keyword"},
{ "name": "parent_id", "type": "Edm.String", "searchable": true, "filterable": true, "retrievable": true, "sortable": true},
{ "name": "chunk", "type": "Edm.String", "searchable": true, "filterable": false, "retrievable": true, "sortable": false},
{ "name": "title", "type": "Edm.String", "searchable": true, "filterable": true, "retrievable": true, "sortable": false},
{ "name": "vector", "type": "Collection(Edm.Single)", "searchable": true, "retrievable": true, "dimensions": 1536, "vectorSearchProfile": "vector-1707768500058-profile"}
]
Schemat aplikacji RAG i aplikacji w stylu czatu
Jeśli projektujesz magazyn na potrzeby wyszukiwania generowania, możesz utworzyć oddzielne indeksy dla zawartości statycznej indeksowanej i wektoryzowanej oraz drugi indeks konwersacji, które mogą być używane w przepływach monitów. Następujące indeksy są tworzone na podstawie akceleratora chat-with-your-data-solution-accelerator .
Pola z indeksu czatu, które obsługują środowisko wyszukiwania generowania:
"name": "example-index-from-accelerator",
"fields": [
{ "name": "id", "type": "Edm.String", "searchable": false, "filterable": true, "retrievable": true },
{ "name": "content", "type": "Edm.String", "searchable": true, "filterable": false, "retrievable": true },
{ "name": "content_vector", "type": "Collection(Edm.Single)", "searchable": true, "retrievable": true, "dimensions": 1536, "vectorSearchProfile": "my-vector-profile"},
{ "name": "metadata", "type": "Edm.String", "searchable": true, "filterable": false, "retrievable": true },
{ "name": "title", "type": "Edm.String", "searchable": true, "filterable": true, "retrievable": true, "facetable": true },
{ "name": "source", "type": "Edm.String", "searchable": true, "filterable": true, "retrievable": true },
{ "name": "chunk", "type": "Edm.Int32", "searchable": false, "filterable": true, "retrievable": true },
{ "name": "offset", "type": "Edm.Int32", "searchable": false, "filterable": true, "retrievable": true }
]
Pola z indeksu konwersacji obsługującego aranżację i historię czatów:
"fields": [
{ "name": "id", "type": "Edm.String", "key": true, "searchable": false, "filterable": true, "retrievable": true, "sortable": false, "facetable": false },
{ "name": "conversation_id", "type": "Edm.String", "searchable": false, "filterable": true, "retrievable": true, "sortable": false, "facetable": true },
{ "name": "content", "type": "Edm.String", "searchable": true, "filterable": false, "retrievable": true },
{ "name": "content_vector", "type": "Collection(Edm.Single)", "searchable": true, "retrievable": true, "dimensions": 1536, "vectorSearchProfile": "default-profile" },
{ "name": "metadata", "type": "Edm.String", "searchable": true, "filterable": false, "retrievable": true },
{ "name": "type", "type": "Edm.String", "searchable": false, "filterable": true, "retrievable": true, "sortable": false, "facetable": true },
{ "name": "user_id", "type": "Edm.String", "searchable": false, "filterable": true, "retrievable": true, "sortable": false, "facetable": true },
{ "name": "sources", "type": "Collection(Edm.String)", "searchable": false, "filterable": true, "retrievable": true, "sortable": false, "facetable": true },
{ "name": "created_at", "type": "Edm.DateTimeOffset", "searchable": false, "filterable": true, "retrievable": true },
{ "name": "updated_at", "type": "Edm.DateTimeOffset", "searchable": false, "filterable": true, "retrievable": true }
]
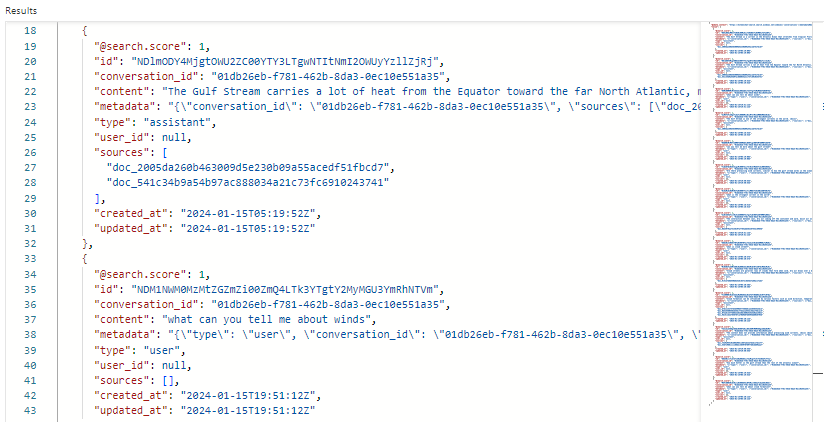
Oto zrzut ekranu przedstawiający wyniki wyszukiwania w Eksploratorze wyszukiwania dla indeksu konwersacji. Wynik wyszukiwania wynosi 1,00, ponieważ wyszukiwanie było niekwalifikowane. Zwróć uwagę na pola, które istnieją do obsługi orkiestracji i monitowania przepływów. Identyfikator konwersacji identyfikuje określony czat. "type" wskazuje, czy zawartość pochodzi od użytkownika, czy asystenta. Daty są używane do starzenia się czatów z historii.
Struktura fizyczna i rozmiar
W usłudze Azure AI Search fizyczna struktura indeksu jest w dużej mierze implementacją wewnętrzną. Możesz uzyskać dostęp do jego schematu, ładowania i wykonywania zapytań dotyczących jego zawartości, monitorować jego rozmiar i zarządzać pojemnością, ale same klastry (indeksy odwrócone i wektorowe), a inne pliki i foldery są zarządzane wewnętrznie przez firmę Microsoft.
Rozmiar i substancja indeksu są określane przez:
- Ilość i kompozycja dokumentów
- Atrybuty w poszczególnych polach. Na przykład do filtrowania pól jest wymagana większa ilość miejsca do magazynowania.
- Konfiguracja indeksu, w tym konfiguracja wektora, która określa sposób tworzenia wewnętrznych struktur nawigacji na podstawie tego, czy wybierasz HNSW, czy wyczerpującą nazwę KNN na potrzeby wyszukiwania podobieństwa.
Usługa Azure AI Search nakłada limity na magazyn wektorowy, co pomaga zachować zrównoważony i stabilny system dla wszystkich obciążeń. Aby ułatwić utrzymanie limitów, użycie wektorów jest śledzone i zgłaszane oddzielnie w witrynie Azure Portal oraz programowo za pomocą statystyk usług i indeksów.
Poniższy zrzut ekranu przedstawia usługę S1 skonfigurowaną z jedną partycją i jedną repliką. Ta konkretna usługa ma 24 małe indeksy, z jednym polem wektorowym średnio, każde pole składające się z 1536 osadzonych. Drugi kafelek przedstawia limit przydziału i użycie indeksów wektorów. Indeks wektorowy to wewnętrzna struktura danych utworzona dla każdego pola wektora. W związku z tym magazyn indeksów wektorów jest zawsze ułamkiem magazynu używanego przez indeks. Inne pola niewektorowe i struktury danych zużywają resztę.
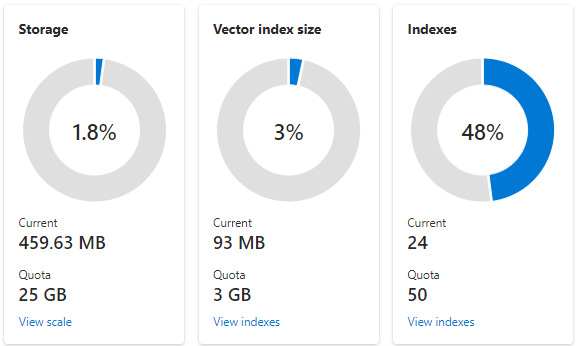
Limity indeksów wektorów i szacowania zostały omówione w innym artykule, ale dwa punkty, które należy podkreślić z góry, jest to, że maksymalny rozmiar magazynu różni się w zależności od warstwy usługi, a także od momentu utworzenia usługi wyszukiwania. Nowsze usługi tej samej warstwy mają znacznie większą pojemność dla indeksów wektorów. Z tych powodów wykonaj następujące czynności:
Sprawdź datę wdrożenia usługi wyszukiwania. Jeśli została utworzona przed 3 kwietnia 2024 r., rozważ utworzenie nowej usługi wyszukiwania w celu zwiększenia pojemności.
Wybierz skalowalną warstwę , jeśli przewidujesz wahania wymagań magazynu wektorowego. Warstwa Podstawowa jest stała na jednej partycji w starszych usługach wyszukiwania. Rozważ użycie warstwy Standardowa 1 (S1) i nowszych, aby uzyskać większą elastyczność i szybszą wydajność, lub utworzyć nową usługę wyszukiwania, która używa wyższych limitów i większej liczby partycji w każdej warstwie z możliwością zabezpieczeń.
Podstawowe operacje i interakcja
W tej sekcji przedstawiono wektorowe operacje czasu wykonywania, w tym nawiązywanie połączenia z pojedynczym indeksem i zabezpieczanie go.
Uwaga
Podczas zarządzania indeksem należy pamiętać, że nie ma żadnej obsługi portalu ani interfejsu API do przenoszenia lub kopiowania indeksu. Zamiast tego klienci zazwyczaj wskazują swoje rozwiązanie wdrażania aplikacji w innej usłudze wyszukiwania (jeśli używasz tej samej nazwy indeksu) lub popraw nazwę, aby utworzyć kopię w bieżącej usłudze wyszukiwania, a następnie skompilować ją.
Stale dostępne
Indeks jest natychmiast dostępny dla zapytań, gdy tylko pierwszy dokument jest indeksowany, ale nie będzie w pełni operacyjny, dopóki wszystkie dokumenty nie zostaną zindeksowane. Wewnętrznie indeks jest dystrybuowany między partycjami i wykonywany na replikach. Indeks fizyczny jest zarządzany wewnętrznie. Indeks logiczny jest zarządzany przez Użytkownika.
Indeks jest stale dostępny, bez możliwości wstrzymania ani przełączenie go w tryb offline. Ponieważ jest ona przeznaczona do ciągłej operacji, wszelkie aktualizacje zawartości lub dodatki do samego indeksu są wykonywane w czasie rzeczywistym. W związku z tym zapytania mogą tymczasowo zwracać niekompletne wyniki, jeśli żądanie zbiega się z aktualizacją dokumentu.
Zwróć uwagę, że ciągłość zapytań istnieje dla operacji dokumentu (odświeżanie lub usuwanie) oraz modyfikacji, które nie mają wpływu na istniejącą strukturę i integralność bieżącego indeksu (na przykład dodawanie nowych pól). Jeśli konieczne jest wprowadzenie aktualizacji strukturalnych (zmiana istniejących pól), są one zwykle zarządzane przy użyciu przepływu pracy upuszczania i ponownego kompilowania w środowisku deweloperskim lub przez utworzenie nowej wersji indeksu w usłudze produkcyjnej.
Aby uniknąć ponownego kompilowania indeksu, niektórzy klienci, którzy wprowadzą niewielkie zmiany, zdecydują się na "wersję" pola, tworząc nowe, które współistnieją obok poprzedniej wersji. Z czasem prowadzi to do oddzielonej zawartości w postaci przestarzałych pól lub przestarzałych definicji analizatora niestandardowego, zwłaszcza w indeksie produkcyjnym, który jest kosztowny do replikacji. Te problemy można rozwiązać w przypadku planowanych aktualizacji indeksu w ramach zarządzania cyklem życia indeksu.
Połączenie punktu końcowego
Wszystkie indeksowanie wektorów i żądania zapytań są kierowane do indeksu. Punkty końcowe są zwykle jednym z następujących elementów:
| Punkt końcowy | Połączenie i kontrola dostępu |
|---|---|
<your-service>.search.windows.net/indexes |
Obiekt docelowy kolekcji indeksów. Używany podczas tworzenia, wyświetlania listy lub usuwania indeksu. Uprawnienia administratora są wymagane dla tych operacji, dostępne za pośrednictwem kluczy interfejsu API administratora lub roli Współautor wyszukiwania. |
<your-service>.search.windows.net/indexes/<your-index>/docs |
Obiekt docelowy kolekcji dokumentów pojedynczego indeksu. Używane podczas wykonywania zapytań dotyczących indeksu lub odświeżania danych. W przypadku zapytań prawa odczytu są wystarczające i dostępne za pośrednictwem kluczy interfejsu API zapytań lub roli czytnika danych. W przypadku odświeżania danych wymagane są prawa administratora. |
Jak nawiązać połączenie z usługą Azure AI Search
Upewnij się, że masz uprawnienia lub klucz dostępu interfejsu API. Jeśli nie wysyłasz zapytań dotyczących istniejącego indeksu, potrzebujesz uprawnień administratora lub przypisania roli współautora do zarządzania zawartością i wyświetlania jej w usłudze wyszukiwania.
Zacznij od witryny Azure Portal. Osoba, która utworzyła usługę wyszukiwania, może wyświetlać usługę wyszukiwania i zarządzać nią, w tym udzielać dostępu innym osobom za pośrednictwem strony Kontrola dostępu (IAM).
Przejdź do innych klientów w celu uzyskania dostępu programowego. Zalecamy przewodniki Szybki start i przykłady dla pierwszych kroków:
Bezpieczny dostęp do danych wektorowych
Usługa Azure AI Search implementuje szyfrowanie danych, połączenia prywatne dla scenariuszy bez Internetu i przypisania ról w celu zapewnienia bezpiecznego dostępu za pośrednictwem identyfikatora Entra firmy Microsoft. Pełny zakres funkcji zabezpieczeń przedsiębiorstwa przedstawiono w temacie Zabezpieczenia w usłudze Azure AI Search.
Zarządzanie magazynami wektorów
Platforma Azure udostępnia platformę monitorowania, która obejmuje rejestrowanie diagnostyczne i alerty. Zalecamy następujące najlepsze rozwiązania: