Szacowanie pojemności usługi wyszukiwania i zarządzanie nią
W usłudze Azure AI Search pojemność jest oparta na replikach i partycjach, które można skalować do obciążenia. Repliki to kopie aparatu wyszukiwania. Partycje to jednostki magazynu. Każda nowa usługa wyszukiwania rozpoczyna się od jednej z nich, ale można niezależnie dodawać lub usuwać repliki i partycje, aby uwzględnić zmienne obciążenia. Dodanie pojemności zwiększa koszt uruchamiania usługi wyszukiwania.
Cechy fizyczne replik i partycji, takie jak szybkość przetwarzania i operacje we/wy dysku, różnią się w zależności od warstwy usługi. W standardowej usłudze wyszukiwania repliki i partycje są szybsze i większe niż w przypadku usługi podstawowej.
Zmiana pojemności nie jest natychmiastowa. Uruchomienie lub zlikwidowanie partycji może potrwać do godziny, zwłaszcza w przypadku usług z dużą ilością danych.
Podczas skalowania usługi wyszukiwania można wybrać spośród następujących narzędzi i metod:
- Azure Portal
- Azure PowerShell
- Interfejs wiersza polecenia platformy Azure
- Interfejs API REST zarządzania
Uwaga
Wyższe partycje pojemności są dostępne w tej samej stawce rozliczeniowej dla nowszych usług utworzonych po kwietniu i maju 2024 r. Aby uzyskać więcej informacji, zobacz Limity usługi dla uaktualnień rozmiaru partycji.
Pojęcia: jednostki wyszukiwania, repliki, partycje
Pojemność jest wyrażona w jednostkach wyszukiwania, które można przydzielić w kombinacjach partycji i replik.
| Pojęcie | Definicja |
|---|---|
| Jednostka wyszukiwania | Pojedyncza przyrost całkowitej dostępnej pojemności (36 jednostek). Do uruchomienia usługi jest wymagana co najmniej jedna jednostka. Pierwsza para repliki i partycji jest pierwszą jednostką wyszukiwania. Jednak każde dodatkowe wystąpienie repliki lub partycji zużywa dodatkową jednostkę wyszukiwania. Na przykład uruchamiasz jedną replikę i partycję (jedną jednostkę wyszukiwania), dodaj drugą replikę, a teraz korzystasz z dwóch jednostek wyszukiwania. Jednostka wyszukiwania jest również jednostką rozliczeniową dla usługi Azure AI usługa wyszukiwania. |
| Replika | Wystąpienia usługi wyszukiwania używane głównie do równoważenia obciążenia operacji zapytań. Każda replika hostuje jedną kopię indeksu. Jeśli przydzielasz trzy repliki, masz trzy kopie indeksu dostępne na potrzeby obsługi żądań zapytań. |
| Partycja | Magazyn fizyczny i operacje we/wy na potrzeby operacji odczytu/zapisu (na przykład podczas ponownego kompilowania lub odświeżania indeksu). Każda partycja ma wycinek całkowitego indeksu. Jeśli przydzielasz trzy partycje, indeks jest podzielony na trzecie. |
Przejrzyj tabelę partycji i replik, aby uzyskać możliwe kombinacje, które pozostają poniżej limitu 36 jednostek.
Kiedy dodać pojemność
Początkowo usługa jest przydzielana minimalny poziom zasobów składających się z jednej partycji i jednej repliki. Wybrana warstwa określa rozmiar partycji i szybkość, a każda warstwa jest zoptymalizowana pod kątem zestawu cech pasujących do różnych scenariuszy. Jeśli wybierzesz warstwę wyższej klasy, może być potrzebna mniejsza liczba partycji niż w przypadku korzystania z warstwy S1. Jednym z pytań, na które należy odpowiedzieć za pomocą samodzielnego testowania, jest to, czy większa i droższa partycja daje lepszą wydajność niż dwie tańsze partycje w usłudze aprowizowanej w niższej warstwie.
Pojedyncza usługa musi mieć wystarczające zasoby do obsługi wszystkich obciążeń (indeksowania i zapytań). Żadne obciążenie nie jest uruchamiane w tle. Indeksowanie można zaplanować w czasie, gdy żądania zapytań są naturalnie rzadziej spotykane, ale usługa nie będzie określać priorytetu jednego zadania na innym. Ponadto pewna ilość nadmiarowości zapewnia wydajność zapytań, gdy usługi lub węzły są aktualizowane wewnętrznie.
Niektóre wskazówki dotyczące określania, czy dodać pojemność, obejmują:
- Spełnianie kryteriów wysokiej dostępności dla umowy dotyczącej poziomu usług
- Częstotliwość błędów HTTP 503 rośnie
- Duże woluminy zapytań są oczekiwane
Ogólnie rzecz biorąc, aplikacje wyszukiwania zwykle potrzebują większej liczby replik niż partycji, szczególnie gdy operacje usługi są stronnicze w stosunku do obciążeń zapytań. Każda replika jest kopią indeksu, umożliwiając usłudze równoważenie obciążenia żądań względem wielu kopii. Wszystkie równoważenie obciążenia i replikacja indeksu są zarządzane przez usługę Azure AI Search i można zmienić liczbę replik przydzielonych dla usługi w dowolnym momencie. W usłudze wyszukiwania w warstwie Standardowa można przydzielić maksymalnie 12 replik i 3 repliki w usłudze wyszukiwania w warstwie Podstawowa. Alokację repliki można wykonać w witrynie Azure Portal lub w jednej z opcji programowych.
Dodatkowe partycje są przydatne w przypadku intensywnych obciążeń indeksowania. Dodatkowe partycje rozkładają operacje odczytu/zapisu w większej liczbie zasobów obliczeniowych.
Na koniec wykonywanie zapytań o większe indeksy trwa dłużej. W związku z tym może się okazać, że każdy przyrostowy wzrost partycji wymaga mniejszego, ale proporcjonalnego zwiększenia liczby replik. Złożoność zapytań i woluminu zapytań będzie uwzględniać szybkość wykonywania zapytań.
Uwaga
Dodanie większej liczby replik lub partycji zwiększa koszt działania usługi i może wprowadzać niewielkie różnice w sposobie porządkowenia wyników. Pamiętaj, aby sprawdzić kalkulator cen, aby zrozumieć implikacje dotyczące rozliczeń dodawania kolejnych węzłów. Na poniższym wykresie można odwoływać się krzyżowo do liczby jednostek wyszukiwania wymaganych do określonej konfiguracji. Aby uzyskać więcej informacji na temat wpływu dodatkowych replik na przetwarzanie zapytań, zobacz Porządkowanie wyników.
Jak zmienić pojemność
Aby zwiększyć lub zmniejszyć pojemność usługi wyszukiwania, dodaj lub usuń partycje i repliki.
Zaloguj się do witryny Azure Portal i wybierz usługę wyszukiwania.
W obszarze Ustawienia otwórz stronę Skalowanie , aby zmodyfikować repliki i partycje.
Poniższy zrzut ekranu przedstawia usługę Standardowa aprowizowaną z jedną repliką i partycją. Formuła u dołu wskazuje liczbę używanych jednostek wyszukiwania (1). Jeśli cena jednostkowa wynosiła 100 USD (a nie rzeczywista cena), miesięczny koszt działania tej usługi wyniesie średnio 100 USD.
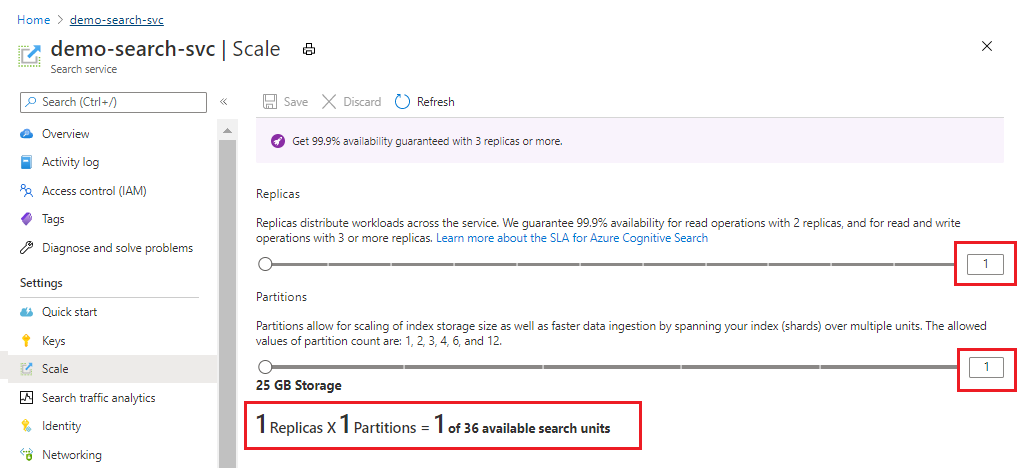
Użyj suwaka, aby zwiększyć lub zmniejszyć liczbę partycji. Wybierz pozycję Zapisz.
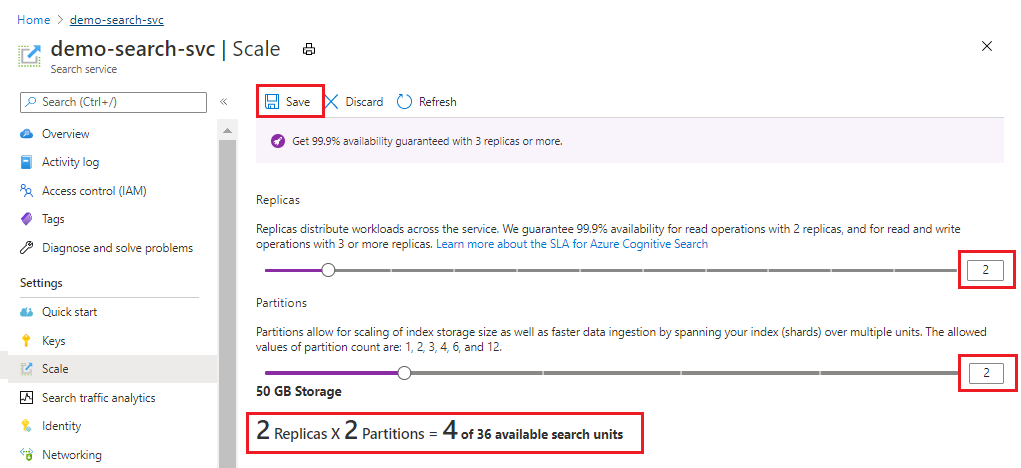
W tym przykładzie dodano drugą replikę i partycję. Zwróć uwagę na liczbę jednostek wyszukiwania; Jest to teraz cztery, ponieważ formuła rozliczeń jest replikami pomnożonymi przez partycje (2 x 2). Podwojenie pojemności ponad dwukrotnie zwiększa koszt działania usługi. Jeśli koszt jednostki wyszukiwania wynosił 100 USD, nowy miesięczny rachunek będzie teraz wynosić 400 USD.
W przypadku bieżących kosztów jednostkowych każdej warstwy odwiedź stronę Cennik.
Po zapisaniu możesz sprawdzić powiadomienia, aby potwierdzić, że akcja zakończyła się pomyślnie.

Zmiany pojemności mogą potrwać od 15 minut do kilku godzin. Nie można anulować po rozpoczęciu procesu i nie ma monitorowania w czasie rzeczywistym na potrzeby korekt repliki i partycji. Jednak następujący komunikat pozostaje widoczny, gdy zmiany są w toku.

Uwaga
Po aprowizacji usługi nie można jej uaktualnić do wyższej warstwy. Musisz utworzyć usługę wyszukiwania w nowej warstwie i ponownie załadować indeksy. Aby uzyskać pomoc dotyczącą aprowizacji usług, zobacz Tworzenie usługa wyszukiwania usługi Azure AI w witrynie Azure Portal.
Sposób obsługi żądań skalowania
Po otrzymaniu żądania skalowania usługa wyszukiwania:
- Sprawdza, czy żądanie jest prawidłowe.
- Rozpoczyna tworzenie kopii zapasowych danych i informacji systemowych.
- Sprawdza, czy usługa jest już w stanie aprowizacji (obecnie dodawanie lub eliminowanie replik lub partycji).
- Rozpoczyna aprowizację.
Skalowanie usługi może potrwać nawet 15 minut lub nieco ponad godzinę, w zależności od rozmiaru usługi i zakresu żądania. Tworzenie kopii zapasowej może potrwać kilka minut, w zależności od ilości danych i liczby partycji i replik.
Powyższe kroki nie są całkowicie kolejne. Na przykład system rozpoczyna aprowizację, gdy można to bezpiecznie zrobić, co może być możliwe podczas tworzenia kopii zapasowej.
Błędy podczas skalowania
Komunikat o błędzie "Operacje aktualizacji usługi nie są obecnie dozwolone, ponieważ przetwarzamy poprzednie żądanie" jest spowodowane powtarzaniem żądania skalowania w dół lub w górę, gdy usługa przetwarza już poprzednie żądanie.
Rozwiąż ten błąd, sprawdzając stan usługi, aby zweryfikować stan aprowizacji:
- Aby uzyskać stan usługi, użyj interfejsu API REST zarządzania, programu Azure PowerShell lub interfejsu wiersza polecenia platformy Azure.
- Wywołaj metodę Get Service (REST) lub równoważną dla programu PowerShell lub interfejsu wiersza polecenia.
- Sprawdź odpowiedź na "provisioningState": "provisioning"
Jeśli stan to "Aprowizowanie", poczekaj na ukończenie żądania. Stan powinien mieć wartość "Powodzenie" lub "Niepowodzenie", zanim zostanie podjęta inna próba. Brak stanu kopii zapasowej. Kopia zapasowa jest operacją wewnętrzną i jest mało prawdopodobne, aby była czynnikiem w każdym ćwiczeniu skalowania.
Jeśli usługa wyszukiwania wydaje się być zatrzymana w stanie aprowizacji, sprawdź, czy indeksy oddzielone są bezużyteczne, z zerowymi woluminami zapytań i bez aktualizacji indeksu. Indeks bezużyteczny może blokować zmiany pojemności usługi. W szczególności poszukaj indeksów zaszyfrowanych za pomocą klucza cmK, których klucze nie są już prawidłowe. Należy usunąć indeks lub przywrócić klucze, aby przywrócić indeks w tryb online i odblokować operację skalowania.
Kombinacje partycji i repliki
Poniższy wykres dotyczy warstwy Standardowa i wyższych. Przedstawia wszystkie możliwe kombinacje partycji i replik, które podlegają maksymalnej 36 jednostkom wyszukiwania na usługę.
| 1 partycja | 2 partycje | 3 partycje | 4 partycje | 6 partycji | 12 partycji | |
|---|---|---|---|---|---|---|
| 1 replika | 1 SU | 2 SU | 3 SU | 4 SU | 6 SU | 12 SU |
| 2 repliki | 2 SU | 4 SU | 6 SU | 8 SU | 12 SU | 24 SU |
| 3 repliki | 3 SU | 6 SU | 9 SU | 12 SU | 18 SU | 36 SU |
| 4 repliki | 4 SU | 8 SU | 12 SU | 16 SU | 24 SU | Nie dotyczy |
| 5 replik | 5 SU | 10 SU | 15 jednostek jednostki organizacyjnej | 20 SU | 30 SU | Nie dotyczy |
| 6 replik | 6 SU | 12 SU | 18 SU | 24 SU | 36 SU | Nie dotyczy |
| 12 replik | 12 SU | 24 SU | 36 SU | Brak | NIE DOTYCZY | Brak |
Podstawowe usługi wyszukiwania mają niższe liczby jednostek wyszukiwania.
W usługach wyszukiwania utworzonych przed 3 kwietnia 2024 r. podstawowa usługa wyszukiwania może mieć dokładnie jedną partycję i maksymalnie trzy repliki w celu uzyskania maksymalnego limitu trzech jednostek SU. Jedynym regulowanym zasobem są repliki.
W przypadku usług wyszukiwania utworzonych po 3 kwietnia 2024 r. w obsługiwanych regionach usługi podstawowe mogą mieć maksymalnie trzy partycje i trzy repliki. Maksymalny limit jednostek jednostki organizacyjnej wynosi dziewięć, aby obsługiwać pełne uzupełnienie partycji i replik.
W przypadku usług wyszukiwania w dowolnej warstwie rozliczanej, niezależnie od daty utworzenia, potrzebujesz co najmniej dwóch replik w celu zapewnienia wysokiej dostępności zapytań.
Aby uzyskać informacje o stawkach rozliczeniowych za warstwę i walutę, zobacz stronę cennika usługi Azure AI Search.
Szacowanie pojemności przy użyciu warstwy rozliczanej
Potrzeby magazynu są określane przez rozmiar indeksów, które mają być tworzone. Nie ma solidnych heurystyki ani uogólnień, które pomagają oszacować. Jedynym sposobem określenia rozmiaru indeksu jest utworzenie jednego. Jego rozmiar jest oparty na tokenizacji i osadzaniu oraz czy włączasz sugestory, filtrowanie i sortowanie, czy też można korzystać z kompresji wektorów.
Zalecamy szacowanie warstwy rozliczanej, Podstawowa lub nowsza. Warstwa Bezpłatna działa na zasobach fizycznych współużytkowanych przez wielu klientów i podlega czynnikom poza Twoją kontrolą. Tylko dedykowane zasoby rozliczanej usługi wyszukiwania mogą pomieścić większe czasy próbkowania i przetwarzania w celu uzyskania bardziej realistycznych szacunków ilości indeksu, rozmiaru i woluminów zapytań podczas opracowywania.
Przejrzyj limity usług w każdej warstwie , aby określić, czy niższe warstwy mogą obsługiwać wymaganą liczbę indeksów. Zastanów się, czy potrzebujesz wielu kopii indeksu do aktywnego programowania, testowania i produkcji.
Usługa wyszukiwania podlega limitom obiektów (maksymalna liczba indeksów, indeksatorów, zestawów umiejętności itp.) i limitach magazynu. Niezależnie od tego, który limit zostanie osiągnięty jako pierwszy, jest obowiązującą granicą.
Tworzenie usługi w warstwie rozliczanej. Warstwy są zoptymalizowane pod kątem niektórych obciążeń. Na przykład warstwa Zoptymalizowana pod kątem magazynu ma limit 10 indeksów, ponieważ jest przeznaczony do obsługi niskiej liczby bardzo dużych indeksów.
Zacznij od niskiego poziomu w warstwie Podstawowa lub S1, jeśli nie masz pewności co do przewidywanego obciążenia.
Rozpocznij od wysokiego poziomu, przy S2 lub nawet S3, jeśli testowanie obejmuje indeksowanie na dużą skalę i obciążenia zapytań.
Zacznij od zoptymalizowanego pod kątem magazynu w warstwie L1 lub L2, jeśli indeksujesz dużą ilość danych i obciążenie zapytań jest stosunkowo niskie, podobnie jak w przypadku wewnętrznej aplikacji biznesowej.
Skompiluj początkowy indeks , aby określić, jak dane źródłowe przekładają się na indeks. Jest to jedyny sposób oszacowania rozmiaru indeksu. Atrybuty definicji pól mają wpływ na wymagania dotyczące magazynu fizycznego:
W przypadku wyszukiwania słów kluczowych oznaczanie pól jako możliwych do filtrowania i sortowania zwiększa rozmiar indeksu.
W przypadku wyszukiwania wektorowego można ustawić parametry w celu zmniejszenia rozmiaru wektora.
Monitorowanie magazynu, limitów usług, woluminu zapytań i opóźnienia w witrynie Azure Portal. W witrynie Azure Portal są wyświetlane zapytania na sekundę, zapytania z ograniczeniami i opóźnienie wyszukiwania. Wszystkie te wartości mogą pomóc w podjęciu decyzji, czy wybrano odpowiednią warstwę.
Dodaj repliki pod kątem wysokiej dostępności lub aby ograniczyć niską wydajność zapytań.
Nie ma żadnych wytycznych dotyczących liczby replik potrzebnych do obsługi obciążeń zapytań. Wydajność zapytań zależy od złożoności zapytania i konkurencyjnych obciążeń. Chociaż dodawanie replik wyraźnie skutkuje lepszą wydajnością, wynik nie jest ściśle liniowy: dodanie trzech replik nie gwarantuje potrójnej przepływności. Aby uzyskać wskazówki dotyczące szacowania QPS dla rozwiązania, zobacz Analizowanie zapytań dotyczących wydajnościi monitorowania.
W przypadku odwróconego indeksu rozmiar i złożoność są określane przez zawartość, a niekoniecznie przez ilość danych, które są do niego wprowadzane. Duże źródło danych o wysokiej nadmiarowości może spowodować mniejszy indeks niż mniejszy zestaw danych zawierający wysoce zmienną zawartość. Dlatego rzadko można wywnioskować rozmiar indeksu na podstawie rozmiaru oryginalnego zestawu danych.
Wymagania dotyczące magazynu można zawyżać, jeśli uwzględnisz dane, które nigdy nie zostaną przeszukane. Najlepiej, aby dokumenty zawierały tylko dane potrzebne do wyszukiwania.
Zagadnienia dotyczące umowy dotyczącej poziomu usług
Funkcje w warstwie Bezpłatna i wersja zapoznawcza nie są objęte umowami dotyczącymi poziomu usług (SLA). W przypadku wszystkich warstw rozliczanych umowy SLA obowiązują podczas aprowizowania wystarczającej nadmiarowości dla usługi.
Co najmniej dwie repliki spełniają wymagania umów SLA zapytań (odczyt).
Trzy lub więcej replik spełnia wymagania umów SLA zapytań i indeksowania (odczytu i zapisu).
Liczba partycji nie ma wpływu na umowy SLA.