Rozmiar indeksu wektorowego i pozostawanie w granicach
Dla każdego pola wektorowego usługa Azure AI Search konstruuje indeks wektorów wewnętrznych przy użyciu parametrów algorytmu określonych w polu. Ponieważ usługa Azure AI Search nakłada limity przydziału na rozmiar indeksu wektorowego, musisz wiedzieć, jak oszacować i monitorować rozmiar wektora, aby upewnić się, że nie przekraczasz limitów.
Uwaga
Uwaga dotycząca terminologii. Wewnętrznie fizyczne struktury danych indeksu wyszukiwania obejmują nieprzetworzone treści (używane do pobierania wzorców wymagających nie tokenizowanej zawartości), odwróconych indeksów (używanych do wyszukiwania pól tekstowych) i indeksów wektorów (używanych do wyszukiwania pól wektorów). W tym artykule wyjaśniono limity indeksów wektorów wewnętrznych, które są z powrotem dla każdego pola wektora.
Napiwek
Techniki optymalizacji wektorów są teraz ogólnie dostępne. Korzystaj z funkcji, takich jak wąskie typy danych, kwantyzację skalarną i binarną oraz eliminację nadmiarowego magazynu, aby pozostać w ramach limitu przydziału wektorów i limitu przydziału magazynu.
Kluczowe punkty dotyczące rozmiaru limitu przydziału i indeksu wektorowego
Rozmiar indeksu wektorowego jest mierzony w bajtach.
Przydziały wektorów są oparte na ograniczeniach pamięci. W przypadku indeksów wektorów utworzonych przy użyciu algorytmu Hierarchiczny mały świat (HNSW) indeksy wektorów z możliwością wyszukiwania znajdują się w pamięci. Jednocześnie musi istnieć wystarczająca ilość pamięci dla innych operacji środowiska uruchomieniowego. Limity przydziału wektorów istnieją, aby zapewnić, że ogólny system pozostanie stabilny i zrównoważony dla wszystkich obciążeń. Jeśli używasz wyczerpującego algorytmu KNN, indeksy są ładowane do pamięci tylko w czasie wykonywania zapytania.
Indeksy wektorowe podlegają również limitowi przydziału dysku, w tym sensie, że wszystkie indeksy podlegają przydziałowi dysku. Brak oddzielnego limitu przydziału dysku dla indeksów wektorów.
Przydziały wektorów są wymuszane w usłudze wyszukiwania jako całość na partycję, co oznacza, że w przypadku dodawania partycji limit przydziału wektorów wzrasta. Przydziały wektorów partycji są wyższe w przypadku nowszych usług. Aby uzyskać więcej informacji, zobacz Vector index size limits (Limity rozmiaru indeksu wektorowego).
Jak sprawdzić rozmiar partycji i ilość
Jeśli nie masz pewności, jakie są limity usługi wyszukiwania, oto dwa sposoby uzyskiwania tych informacji:
W witrynie Azure Portal na stronie Przegląd usługi wyszukiwania na karcie Właściwości i karcie Użycie są wyświetlane rozmiar partycji i magazyn, a także wektorowy przydział i rozmiar indeksu wektorowego.
W witrynie Azure Portal na stronie Skalowanie możesz przejrzeć liczbę i rozmiar partycji.
Jak sprawdzić datę utworzenia usługi
Nowsze usługi utworzone po 3 kwietnia 2024 r. oferują pięć do dziesięciu razy więcej miejsca do magazynowania wektorowego co starsze usługi w tej samej warstwie. Jeśli twoja usługa jest starsza, rozważ utworzenie nowej usługi i migrację zawartości.
W witrynie Azure Portal otwórz grupę zasobów zawierającą usługę wyszukiwania.
W okienku po lewej stronie w obszarze Ustawienia wybierz pozycję Wdrożenia.
Znajdź wdrożenie usługi wyszukiwania. Jeśli istnieje wiele wdrożeń, użyj filtru, aby wyszukać frazę "wyszukaj".
Wybierz wdrożenie. Jeśli masz więcej niż jeden, kliknij, aby sprawdzić, czy jest rozpoznawana w usłudze wyszukiwania.
Rozwiń szczegóły wdrożenia. Powinna zostać wyświetlona wartość Utworzono i data utworzenia.
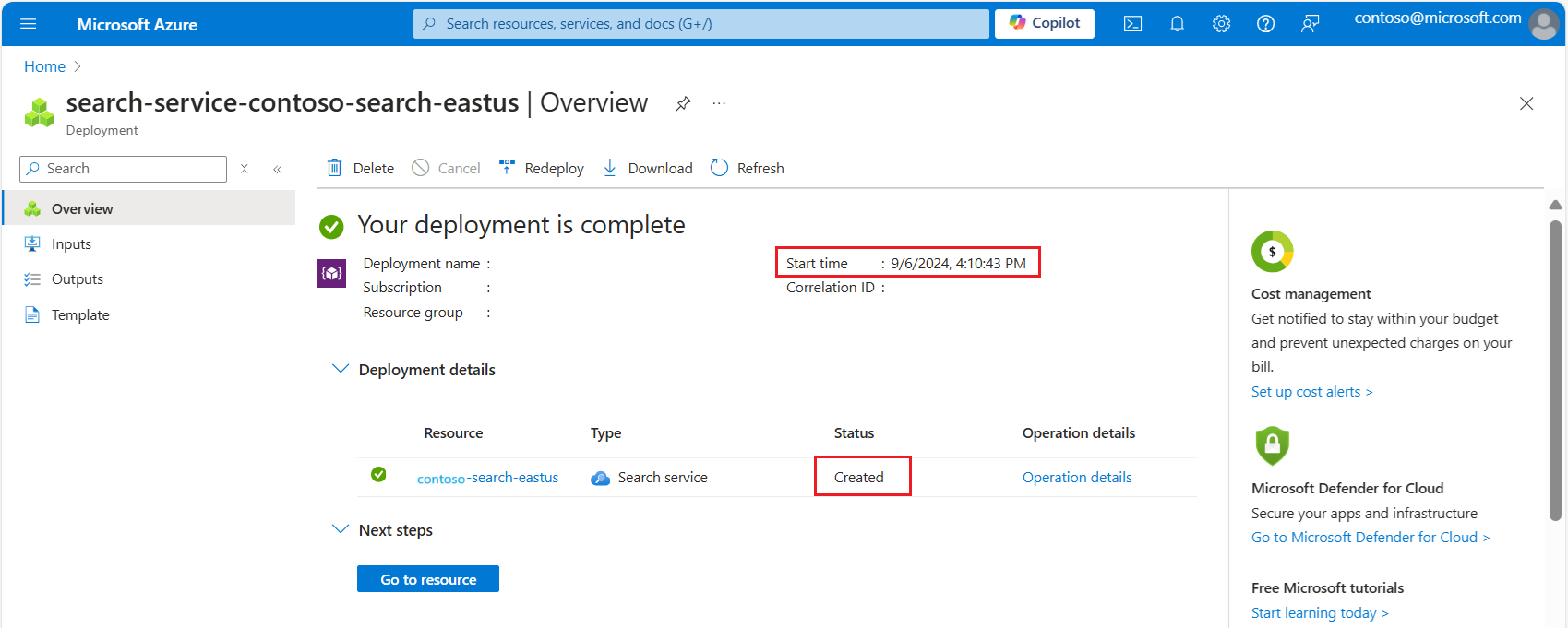
Teraz, gdy znasz wiek usługi wyszukiwania, przejrzyj limity przydziałów wektorów na podstawie tworzenia usługi: limity rozmiaru indeksu wektora.


Jak uzyskać rozmiar indeksu wektorowego
Żądanie metryk wektorów to operacja płaszczyzny danych. Możesz użyć witryny Azure Portal, interfejsów API REST lub zestawów SDK platformy Azure, aby uzyskać użycie wektorów na poziomie usługi za pośrednictwem statystyk usługi i poszczególnych indeksów.
Rozmiar wektora na indeks
Aby uzyskać rozmiar indeksu wektorowego na indeks, wybierz pozycję Indeksy zarządzania wyszukiwaniami>, aby wyświetlić listę indeksów i liczbę dokumentów, rozmiar indeksów wektorów w pamięci i całkowity rozmiar indeksu przechowywany na dysku.
Pamiętaj, że limit przydziału wektorów jest oparty na ograniczeniach pamięci. W przypadku indeksów wektorów utworzonych przy użyciu algorytmu HNSW wszystkie indeksy wektorów z możliwością wyszukiwania są trwale ładowane do pamięci. W przypadku indeksów utworzonych przy użyciu wyczerpującego algorytmu KNN indeksy wektorów są ładowane we fragmentach sekwencyjnie w czasie wykonywania zapytania. Nie ma wymogu rezydencji pamięci dla wyczerpujących indeksów KNN. Okres istnienia załadowanych stron w pamięci jest podobny do wyszukiwania tekstu i nie ma żadnych innych metryk mających zastosowanie do wyczerpujących indeksów KNN innych niż łączny magazyn.
Poniższy zrzut ekranu przedstawia dwie wersje tego samego indeksu wektora. Jedna wersja jest tworzona przy użyciu algorytmu HNSW, gdzie graf wektorowy jest rezydentem pamięci. Inna wersja jest tworzona przy użyciu wyczerpującego algorytmu KNN. W przypadku wyczerpującej nazwy KNN nie ma wyspecjalizowanego indeksu wektora pamięci, dlatego w portalu jest wyświetlany rozmiar indeksu wektorowego o rozmiarze 0 MB. Te wektory nadal istnieją i są liczone w ogólnym rozmiarze magazynu, ale nie zajmują zasobu w pamięci, który metryka rozmiaru indeksu wektorowego jest śledzona.

Rozmiar wektora na usługę
Aby uzyskać rozmiar indeksu wektorowego dla całej usługi wyszukiwania, wybierz kartę Użycie strony Przegląd. Strony portalu są odświeżane co kilka minut, więc jeśli ostatnio zaktualizowano indeks, poczekaj chwilę przed sprawdzeniem wyników.
Poniższy zrzut ekranu dotyczy starszej usługi wyszukiwania w warstwie Standardowa 1 (S1), skonfigurowanej dla jednej partycji i jednej repliki.
Limit przydziału magazynu jest ograniczeniem dysku i obejmuje wszystkie indeksy (wektor i niewektor) w usłudze wyszukiwania.
Limit przydziału rozmiaru indeksu wektorowego jest ograniczeniem pamięci. Jest to ilość pamięci wymaganej do załadowania wszystkich indeksów wektorów wewnętrznych utworzonych dla każdego pola wektora w usłudze wyszukiwania.
Zrzut ekranu wskazuje, że indeksy (wektor i niewektor) zużywają prawie 460 megabajtów dostępnego magazynu dyskowego. Indeksy wektorowe zużywają prawie 93 megabajty pamięci na poziomie usługi.

Limity przydziału zarówno rozmiaru magazynu, jak i indeksu wektorowego zwiększają się lub zmniejszają podczas dodawania lub usuwania partycji. Jeśli zmienisz liczbę partycji, na kafelku zostanie wyświetlona odpowiednia zmiana przydziału magazynu i wektora.
Uwaga
Na dysku indeksy wektorów nie są 93 megabajty. Indeksy wektorów na dysku zajmują około trzy razy więcej miejsca niż indeksy wektorów w pamięci. Aby uzyskać szczegółowe informacje, zobacz Jak pola wektorów wpływają na magazyn dysków.
Czynniki wpływające na rozmiar indeksu wektorowego
Istnieją trzy główne składniki wpływające na rozmiar indeksu wektora wewnętrznego:
- Nieprzetworzone rozmiary danych
- Obciążenie z wybranego algorytmu
- Obciążenie związane z usuwaniem lub aktualizowaniem dokumentów w indeksie
Nieprzetworzone rozmiary danych
Każdy wektor jest zwykle tablicą liczb zmiennoprzecinkowych o pojedynczej precyzji w polu typu Collection(Edm.Single).
Struktury danych wektorowych wymagają magazynu reprezentowanego w następujących obliczeniach jako "nieprzetworzonego rozmiaru" danych. Użyj tego nieprzetworzonego rozmiaru , aby oszacować wymagania dotyczące rozmiaru indeksu wektorowego pól wektorów.
Rozmiar magazynu jednego wektora zależy od jego wymiarowości. Mnożenie rozmiaru jednego wektora przez liczbę dokumentów zawierających to pole wektora w celu uzyskania rozmiaru pierwotnego:
raw size = (number of documents) * (dimensions of vector field) * (size of data type)
| Typ danych EDM | Rozmiar typu danych |
|---|---|
Collection(Edm.Single) |
4 bajty |
Collection(Edm.Half) |
2 bajty |
Collection(Edm.Int16) |
2 bajty |
Collection(Edm.SByte) |
1 bajt |
Obciążenie pamięcią z wybranego algorytmu
Każdy przybliżony algorytm najbliższego sąsiada (ANN) generuje dodatkowe struktury danych w pamięci w celu umożliwienia wydajnego wyszukiwania. Te struktury zużywają dodatkowe miejsce w pamięci.
W przypadku algorytmu HNSW obciążenie pamięci mieści się w zakresie od 1% do 20%.
Obciążenie pamięci jest mniejsze w przypadku wyższych wymiarów, ponieważ zwiększa się rozmiar pierwotny wektorów, podczas gdy dodatkowe struktury danych pozostają stałym rozmiarem, ponieważ przechowują informacje o łączności w grafie. W związku z tym wkład dodatkowych struktur danych stanowi mniejszą część ogólnego rozmiaru.
Obciążenie pamięci jest wyższe w przypadku większych wartości parametru mHNSW, który określa liczbę łączy dwukierunkowych utworzonych dla każdego nowego wektora podczas budowy indeksu. Jest to spowodowane tym, że m współtworzy około 8 bajtów do 10 bajtów na dokument pomnożony przez m.
W poniższej tabeli przedstawiono podsumowanie wartości procentowych narzutów obserwowanych w testach wewnętrznych:
| Wymiary | Parametr HNSW (m) | Procent narzut |
|---|---|---|
| 96 | 100 | 20% |
| 200 | 100 | 8% |
| 768 | 100 | 2% |
| 1536 | 100 | 1% |
| 3072 | 100 | 0,5% |
Te wyniki pokazują relację między wymiarami, parametrem mHNSW i obciążeniem pamięci dla algorytmu HNSW.
Obciążenie związane z usuwaniem lub aktualizowaniem dokumentów w indeksie
Gdy dokument z polem wektorowym zostanie usunięty lub zaktualizowany (aktualizacje są wewnętrznie reprezentowane jako operacja usuwania i wstawiania), dokument źródłowy jest oznaczony jako usunięty i pomijany podczas kolejnych zapytań. Gdy nowe dokumenty są indeksowane i rośnie indeks wektorów wewnętrznych, system czyści te usunięte dokumenty i odzyskuje zasoby. Oznacza to, że prawdopodobnie zauważysz opóźnienie między usuwaniem dokumentów a zwalnianiem bazowych zasobów.
Nazywamy to współczynnikiem usuniętych dokumentów. Ponieważ współczynnik usuniętych dokumentów zależy od właściwości indeksowania usługi, nie ma uniwersalnej heurystyki do oszacowania tego parametru i nie ma interfejsu API ani skryptu, który zwraca stosunek w mocy dla usługi. Zauważamy, że połowa naszych klientów ma współczynnik usuniętych dokumentów mniejszy niż 10%. Jeśli zwykle wykonujesz usunięcia lub aktualizacje o wysokiej częstotliwości, może być obserwowany wyższy współczynnik usuniętych dokumentów.
Jest to kolejny czynnik wpływający na rozmiar indeksu wektorowego. Niestety, nie mamy mechanizmu uwidoślenia bieżącego współczynnika usuniętych dokumentów.
Szacowanie całkowitego rozmiaru danych w pamięci
Biorąc pod uwagę wcześniej opisane czynniki, aby oszacować całkowity rozmiar indeksu wektorowego, użyj następującego obliczenia:
(raw_size) * (1 + algorithm_overhead (in percent)) * (1 + deleted_docs_ratio (in percent))
Na przykład aby obliczyć raw_size, załóżmy, że używasz popularnego modelu Azure OpenAI z text-embedding-ada-002 wymiarami 1536. Oznacza to, że jeden dokument będzie używać 1536 Edm.Single (zmiennoprzecinkowych) lub 6144 bajtów, ponieważ każdy z nich Edm.Single wynosi 4 bajty. 1000 dokumentów z pojedynczym, 1536-wymiarowym polem wektorowym zużywa łącznie 1000 dokumentów x 1536 floats/doc = 1,536 000 zmiennoprzecinków lub 6144 000 bajtów.
Jeśli masz wiele pól wektorowych, musisz wykonać to obliczenie dla każdego pola wektora w indeksie i dodać je razem. Na przykład 1000 dokumentów z dwoma polami wektorów 1536-wymiarowych zużywa 1000 dokumentów x 2 pól x 1536 zmiennoprzecinkowych/dokumentów x 4 bajty/zmiennoprzecinkowe = 12 288 000 bajtów.
Aby uzyskać rozmiar indeksu wektorowego, należy pomnożyć tę raw_size przez obciążenie algorytmu i usunięty współczynnik dokumentów. Jeśli obciążenie algorytmu dla wybranych parametrów HNSW wynosi 10%, a usunięty stosunek dokumentu wynosi 10%, otrzymujemy: 6.144 MB * (1 + 0.10) * (1 + 0.10) = 7.434 MB.
Wpływ pól wektorów na magazyn dyskowy
Większość tego artykułu zawiera informacje o rozmiarze wektorów w pamięci. Jeśli chcesz wiedzieć o rozmiarze wektora na dysku, użycie dysku dla danych wektorowych wynosi mniej więcej trzy razy więcej niż rozmiar indeksu wektorowego w pamięci. Jeśli na przykład vectorIndexSize użycie wynosi 100 megabajtów (10 milionów bajtów), użyjesz co najmniej 300 megabajtów przydziału storageSize , aby uwzględnić indeksy wektorowe.