Zarządzanie zasobami dla klastra Apache Spark w usłudze Azure HDInsight
Dowiedz się, jak uzyskać dostęp do interfejsów, takich jak interfejsy użytkownika apache Ambari , interfejs użytkownika usługi Apache Hadoop YARN i serwer historii platformy Spark skojarzony z klastrem Apache Spark , oraz jak dostosować konfigurację klastra w celu uzyskania optymalnej wydajności.
Otwieranie serwera historii platformy Spark
Serwer historii platformy Spark to internetowy interfejs użytkownika dla ukończonych i uruchomionych aplikacji platformy Spark. Jest to rozszerzenie internetowego interfejsu użytkownika platformy Spark. Aby uzyskać pełne informacje, zobacz Serwer historii platformy Spark.
Otwieranie interfejsu użytkownika usługi Yarn
Interfejs użytkownika usługi YARN umożliwia monitorowanie aplikacji, które są obecnie uruchomione w klastrze Spark.
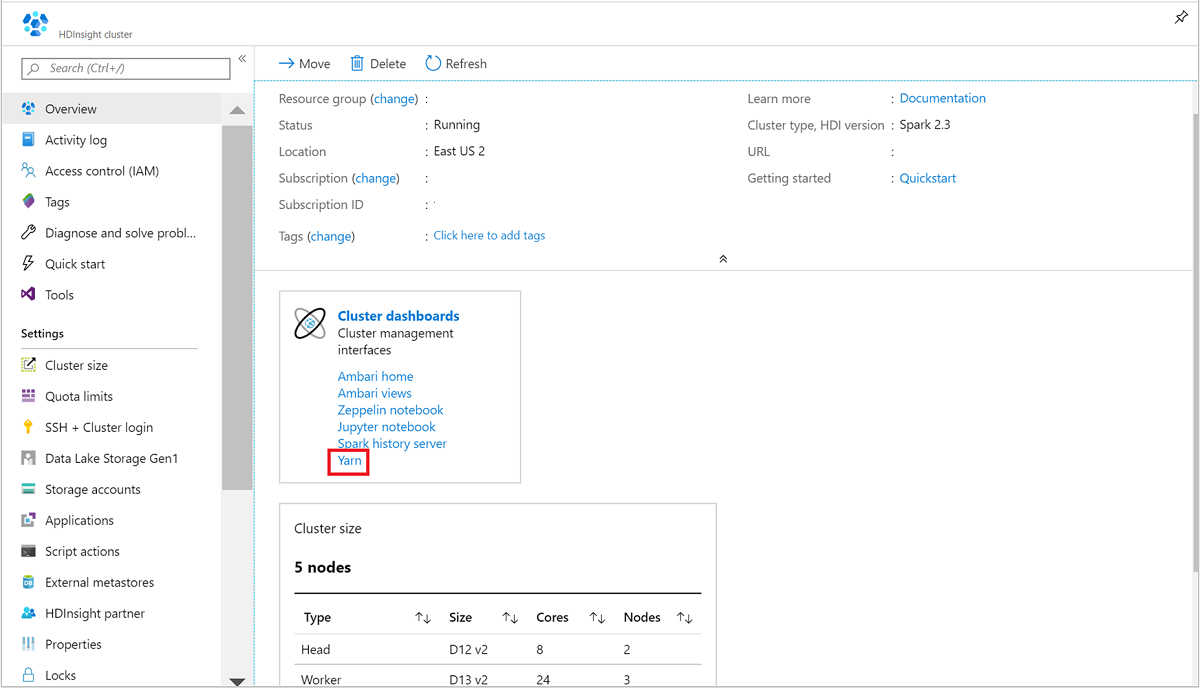
W witrynie Azure Portal otwórz klaster Spark. Aby uzyskać więcej informacji, zobacz Wyświetlanie i wyświetlanie klastrów.
W obszarze Pulpity nawigacyjne klastra wybierz pozycję Yarn. Po wyświetleniu monitu wprowadź poświadczenia administratora dla klastra Spark.
Napiwek
Alternatywnie możesz również uruchomić interfejs użytkownika usługi YARN z poziomu interfejsu użytkownika systemu Ambari. W interfejsie użytkownika systemu Ambari przejdź do interfejsu użytkownika usługi YARN>Quick Links>Active>Resource Manager.
Optymalizowanie klastrów dla aplikacji platformy Spark
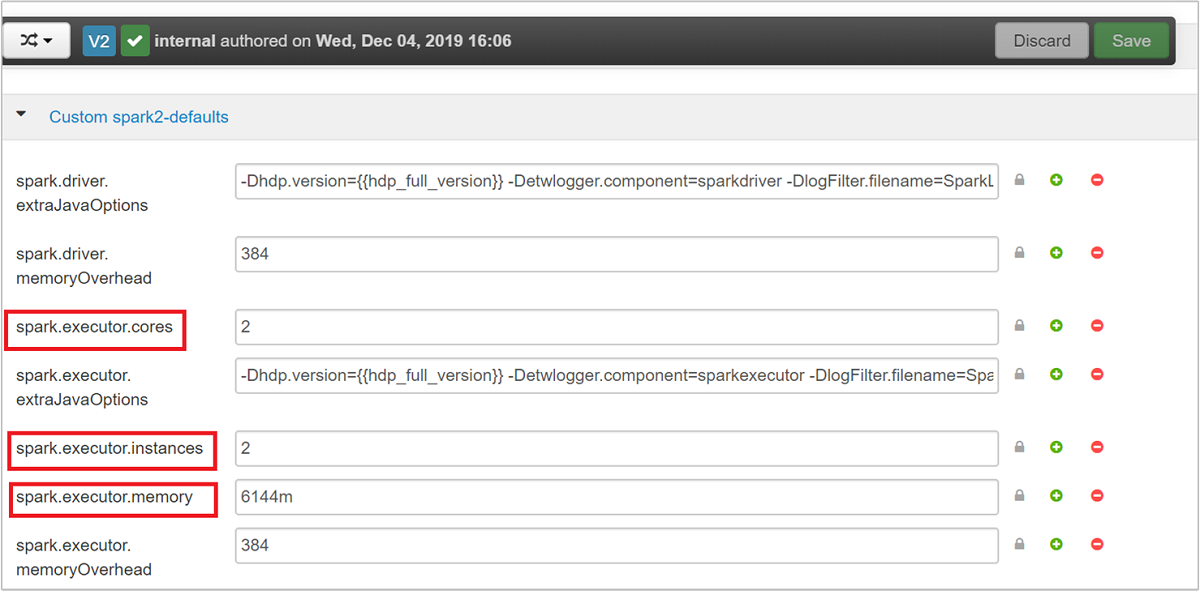
Trzy kluczowe parametry, które mogą być używane do konfiguracji platformy Spark w zależności od wymagań aplikacji, to spark.executor.instances, spark.executor.coresi spark.executor.memory. Funkcja wykonawcza to proces uruchamiany dla aplikacji Spark. Jest on uruchamiany w węźle roboczym i jest odpowiedzialny za wykonywanie zadań dla aplikacji. Domyślna liczba funkcji wykonawczych i rozmiarów funkcji wykonawczej dla każdego klastra jest obliczana na podstawie liczby węzłów procesu roboczego i rozmiaru węzła roboczego. Te informacje są przechowywane w spark-defaults.conf węzłach głównych klastra.
Trzy parametry konfiguracji można skonfigurować na poziomie klastra (dla wszystkich aplikacji uruchamianych w klastrze) lub można również określić dla każdej aplikacji.
Zmienianie parametrów przy użyciu interfejsu użytkownika systemu Ambari
W interfejsie użytkownika systemu Ambari przejdź do pozycji Platforma Spark 2 Konfiguracje>niestandardowe spark2-defaults.>
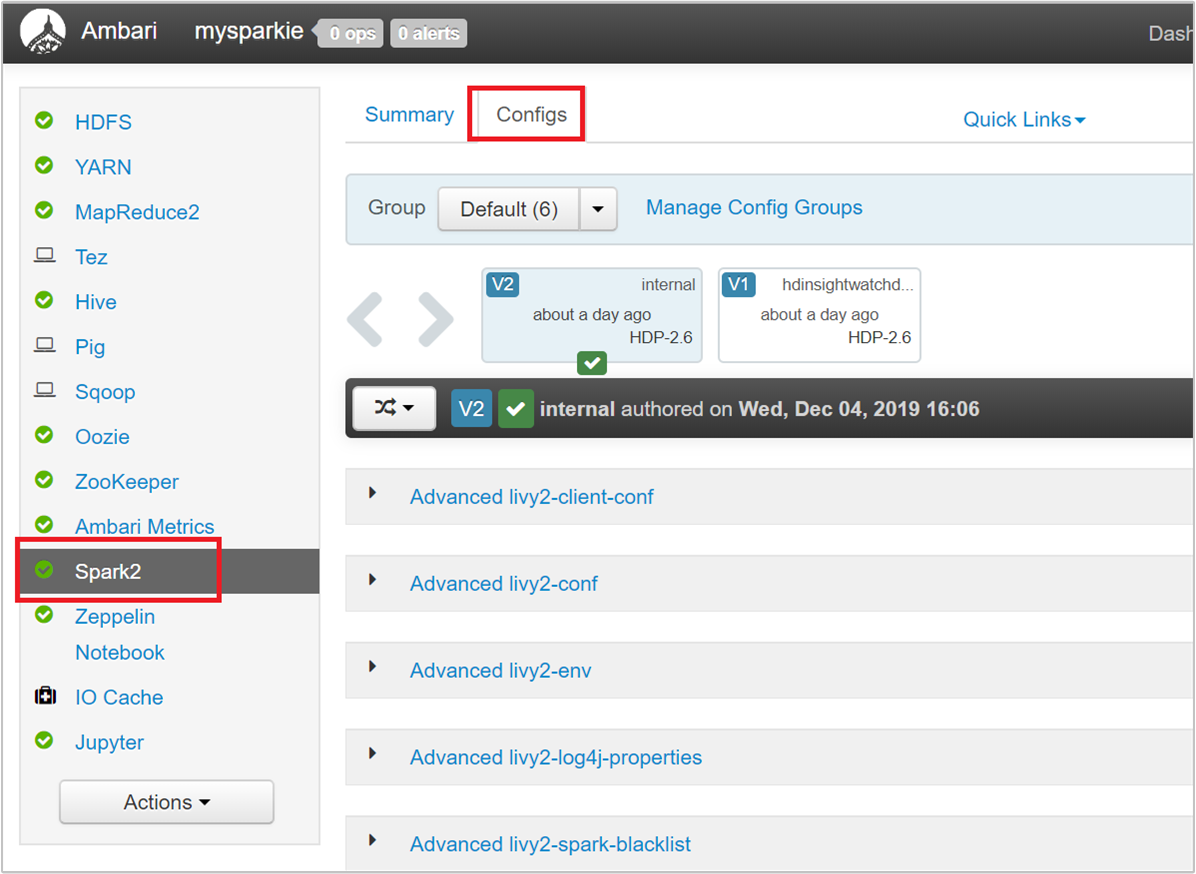
Wartości domyślne są dobre, aby cztery aplikacje Platformy Spark działały współbieżnie w klastrze. Możesz zmienić te wartości z interfejsu użytkownika, jak pokazano na poniższym zrzucie ekranu:
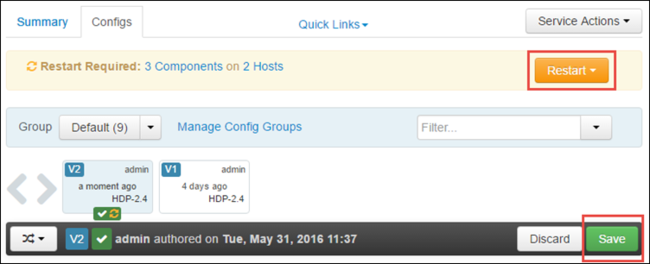
Wybierz pozycję Zapisz , aby zapisać zmiany konfiguracji. W górnej części strony zostanie wyświetlony monit o ponowne uruchomienie wszystkich usług, których dotyczy problem. Wybierz Uruchom ponownie.
Zmienianie parametrów aplikacji uruchomionej w notesie Jupyter Notebook
W przypadku aplikacji działających w notesie Jupyter Notebook możesz użyć %%configure magii, aby wprowadzić zmiany konfiguracji. W idealnym przypadku należy wprowadzić takie zmiany na początku aplikacji, zanim uruchomisz pierwszą komórkę kodu. Dzięki temu konfiguracja zostanie zastosowana do sesji usługi Livy po jej utworzeniu. Jeśli chcesz zmienić konfigurację na późniejszym etapie w aplikacji, musisz użyć parametru -f . Jednak dzięki temu cały postęp w aplikacji zostanie utracony.
Poniższy fragment kodu pokazuje, jak zmienić konfigurację aplikacji uruchomionej w programie Jupyter.
%%configure
{"executorMemory": "3072M", "executorCores": 4, "numExecutors":10}
Parametry konfiguracji muszą być przekazywane jako ciąg JSON i muszą znajdować się w następnym wierszu po magii, jak pokazano w przykładowej kolumnie.
Zmienianie parametrów przesłanej aplikacji przy użyciu funkcji spark-submit
Poniższe polecenie to przykład zmiany parametrów konfiguracji dla aplikacji wsadowej przesłanej przy użyciu polecenia spark-submit.
spark-submit --class <the application class to execute> --executor-memory 3072M --executor-cores 4 –-num-executors 10 <location of application jar file> <application parameters>
Zmienianie parametrów aplikacji przesłanej przy użyciu biblioteki cURL
Poniższe polecenie to przykład zmiany parametrów konfiguracji dla aplikacji wsadowej przesłanej przy użyciu biblioteki cURL.
curl -k -v -H 'Content-Type: application/json' -X POST -d '{"file":"<location of application jar file>", "className":"<the application class to execute>", "args":[<application parameters>], "numExecutors":10, "executorMemory":"2G", "executorCores":5' localhost:8998/batches
Uwaga
Skopiuj plik JAR na konto magazynu klastra. Nie należy kopiować pliku JAR bezpośrednio do węzła głównego.
Zmienianie tych parametrów na serwerze Spark Thrift
Serwer Spark Thrift Server zapewnia dostęp JDBC/ODBC do klastra Spark i służy do obsługi zapytań Spark SQL. Narzędzia, takie jak Power BI, Tableau i tak dalej, używają protokołu ODBC do komunikowania się z serwerem Spark Thrift Server w celu wykonywania zapytań Spark SQL jako aplikacji spark. Po utworzeniu klastra Spark uruchamiane są dwa wystąpienia serwera Spark Thrift, po jednym w każdym węźle głównym. Każdy serwer Spark Thrift jest widoczny jako aplikacja Spark w interfejsie użytkownika usługi YARN.
Serwer Spark Thrift używa dynamicznej alokacji funkcji wykonawczej platformy Spark, dlatego spark.executor.instances nie jest używany. Zamiast tego program Spark Thrift Server używa spark.dynamicAllocation.maxExecutors funkcji i spark.dynamicAllocation.minExecutors określa liczbę funkcji wykonawczej. Parametry spark.executor.coreskonfiguracji i spark.executor.memory służą do modyfikowania rozmiaru funkcji wykonawczej. Te parametry można zmienić, jak pokazano w następujących krokach:
Rozwiń kategorię Advanced spark2-thrift-sparkconf, aby zaktualizować parametry i .
spark.dynamicAllocation.minExecutorsspark.dynamicAllocation.maxExecutors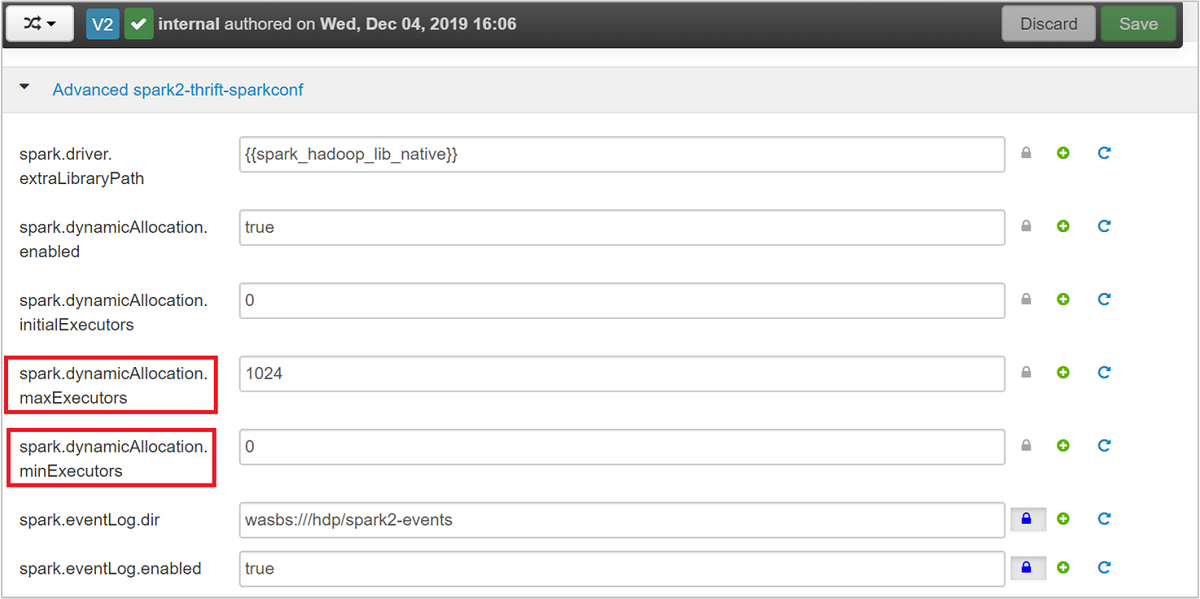
Rozwiń kategorię Custom spark2-thrift-sparkconf, aby zaktualizować parametry i .
spark.executor.memoryspark.executor.cores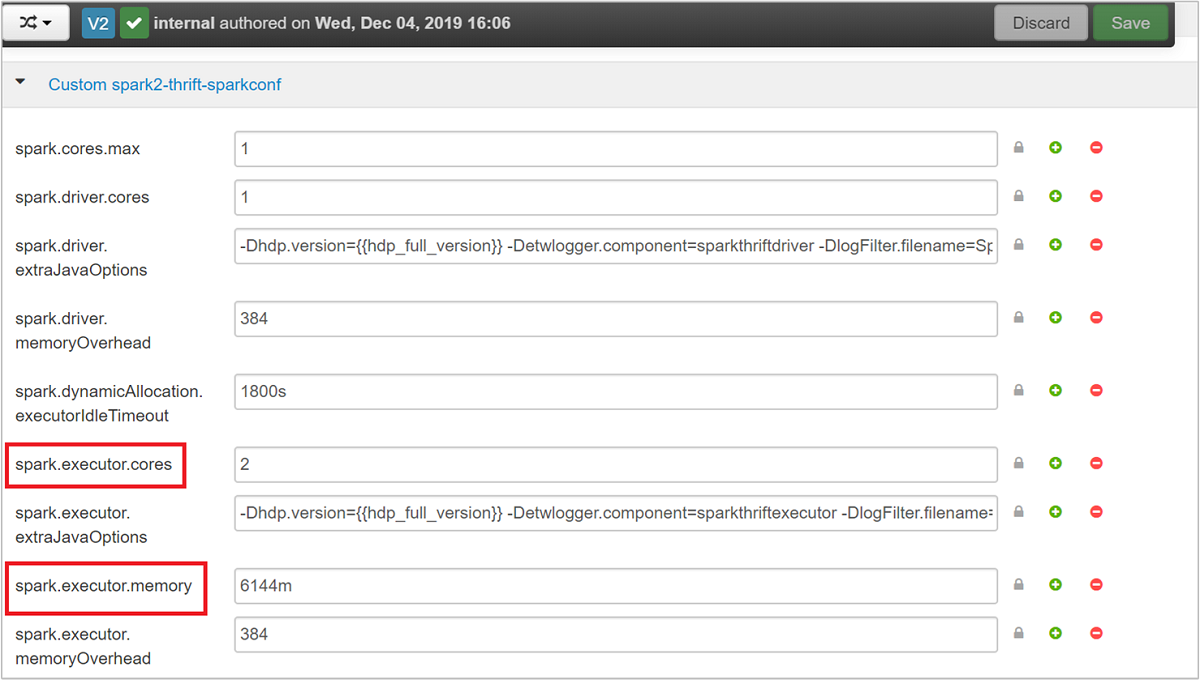
Zmienianie pamięci sterownika serwera Spark Thrift
Pamięć sterownika spark Thrift Server jest skonfigurowana do 25% rozmiaru pamięci RAM węzła głównego, pod warunkiem, że łączny rozmiar pamięci RAM węzła głównego jest większy niż 14 GB. Interfejs użytkownika systemu Ambari umożliwia zmianę konfiguracji pamięci sterownika, jak pokazano na poniższym zrzucie ekranu:
W interfejsie użytkownika systemu Ambari przejdź do pozycji Spark2 Configs>Advanced spark2-env>. Następnie podaj wartość spark_thrift_cmd_opts.
Odzyskiwanie zasobów klastra Spark
Ze względu na dynamiczną alokację platformy Spark jedynymi zasobami, które są używane przez serwer thrift, są zasoby dla dwóch wzorców aplikacji. Aby odzyskać te zasoby, należy zatrzymać usługi Thrift Server uruchomione w klastrze.
W interfejsie użytkownika systemu Ambari w okienku po lewej stronie wybierz pozycję Spark2.
Na następnej stronie wybierz pozycję Spark 2 Thrift Servers (Serwery thrift platformy Spark 2).
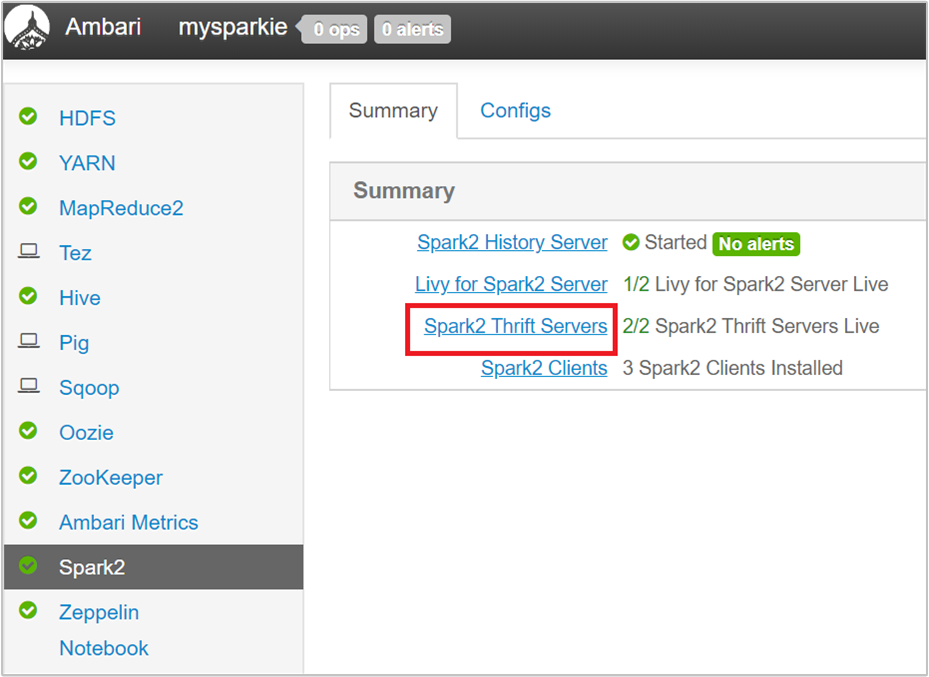
Powinny zostać wyświetlone dwa węzły główne, na których działa serwer Spark 2 Thrift. Wybierz jeden z węzłów głównych.
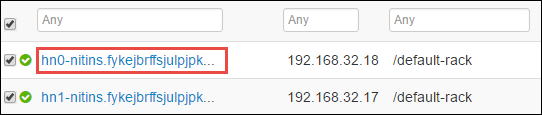
Następna strona zawiera listę wszystkich usług uruchomionych w tym węźle głównym. Z listy wybierz przycisk listy rozwijanej obok pozycji Spark 2 Thrift Server, a następnie wybierz pozycję Zatrzymaj.
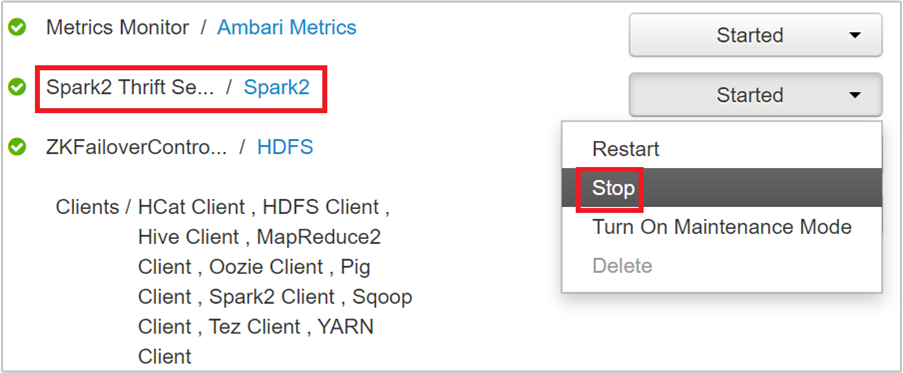
Powtórz te kroki również w innym węźle głównym.
Uruchom ponownie usługę Jupyter
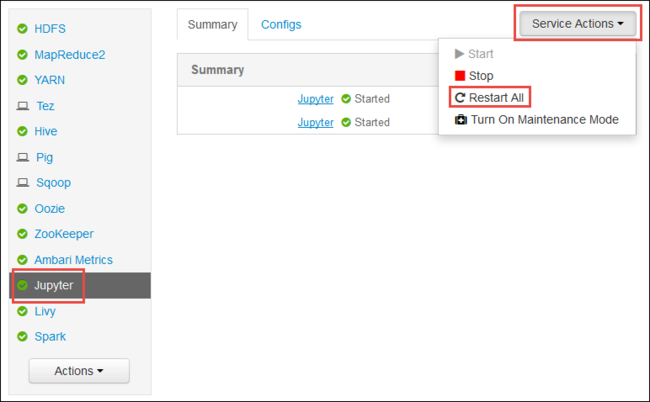
Uruchom internetowy interfejs użytkownika systemu Ambari, jak pokazano na początku artykułu. W okienku nawigacji po lewej stronie wybierz pozycję Jupyter, wybierz pozycję Akcje usługi, a następnie wybierz pozycję Uruchom ponownie wszystko. Spowoduje to uruchomienie usługi Jupyter we wszystkich węzłach głównych.
Monitorowanie zasobów
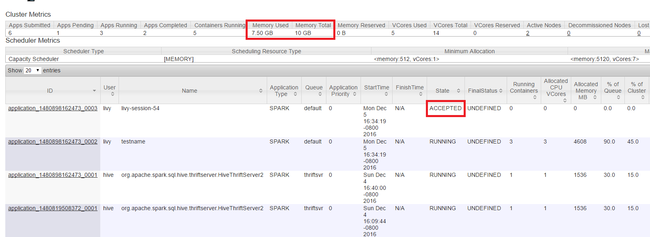
Uruchom interfejs użytkownika usługi Yarn, jak pokazano na początku artykułu. W tabeli Cluster Metrics (Metryki klastra) na górze ekranu sprawdź wartości kolumn Memory Used (Używane ) i Memory Total (Łączna ilość pamięci). Jeśli dwie wartości są bliskie, może być za mało zasobów, aby uruchomić następną aplikację. To samo dotyczy kolumn Używanych rdzeni wirtualnych i Łączna liczba rdzeni wirtualnych. Ponadto w widoku głównym, jeśli aplikacja pozostanie w stanie ZAAKCEPTOWANE i nie przechodzi do stanu URUCHOMIONO lub NIEPOWODZENIE , może to być również wskazanie, że nie ma wystarczającej ilości zasobów do uruchomienia.
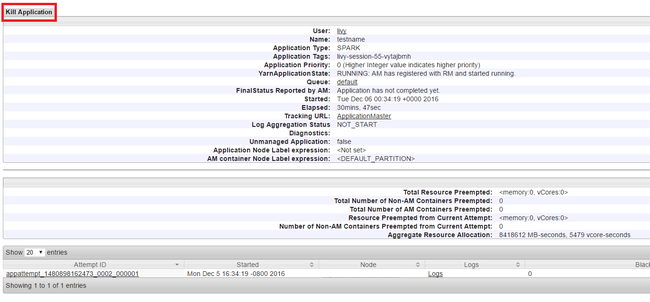
Zabij uruchomione aplikacje
W interfejsie użytkownika usługi Yarn w panelu po lewej stronie wybierz pozycję Uruchomiono. Z listy uruchomionych aplikacji określ aplikację, która ma zostać zabita, a następnie wybierz identyfikator.
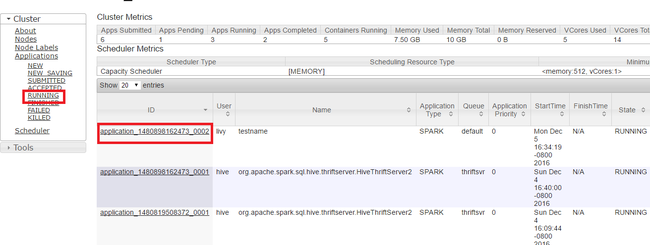
Wybierz pozycję Kill Application (Zabij aplikację ) w prawym górnym rogu, a następnie wybierz przycisk OK.
Zobacz też
Dla analityków danych
- Platforma Apache Spark z usługą Machine Learning: używanie platformy Spark w usłudze HDInsight do analizowania temperatury budynku przy użyciu danych HVAC
- Platforma Apache Spark z usługą Machine Learning: przewidywanie wyników inspekcji żywności przy użyciu platformy Spark w usłudze HDInsight
- Analiza dzienników witryn internetowych przy użyciu platformy Apache Spark w usłudze HDInsight
- Analiza danych telemetrycznych usługi Application Insights przy użyciu platformy Apache Spark w usłudze HDInsight
Dla deweloperów platformy Apache Spark
- Tworzenie autonomicznych aplikacji przy użyciu języka Scala
- Zdalne uruchamianie zadań w klastrze Apache Spark przy użyciu programu Apache Livy
- Tworzenie i przesyłanie aplikacji Spark Scala przy użyciu dodatku HDInsight Tools Plugin for IntelliJ IDEA
- Zdalne debugowanie aplikacji Platformy Apache Spark za pomocą wtyczki HDInsight Tools dla środowiska IntelliJ IDEA
- Używanie notesów Apache Zeppelin z klastrem Apache Spark w usłudze HDInsight
- Jądra dostępne dla notesu Jupyter w klastrze Apache Spark dla usługi HDInsight
- Używanie pakietów zewnętrznych z notesami Jupyter Notebook
- Instalacja oprogramowania Jupyter na komputerze i nawiązywanie połączenia z klastrem Spark w usłudze HDInsight