Jądra notesu Jupyter Notebook w klastrach Apache Spark w usłudze Azure HDInsight
Klastry HDInsight Spark udostępniają jądra, których można używać z notesem Jupyter Notebook na platformie Apache Spark na potrzeby testowania aplikacji. Jądro to program, który uruchamia i interpretuje kod. Trzy jądra to:
- PySpark — dla aplikacji napisanych w języku Python2. (Dotyczy tylko klastrów platformy Spark w wersji 2.4)
- PySpark3 — dla aplikacji napisanych w języku Python3.
- Spark — dla aplikacji napisanych w języku Scala.
Z tego artykułu dowiesz się, jak używać tych jąder i korzyści z ich używania.
Wymagania wstępne
Klaster Apache Spark w usłudze HDInsight. Aby uzyskać instrukcje, zobacz Tworzenie klastra platformy Apache Spark w usłudze Azure HDInsight.
Tworzenie notesu Jupyter w usłudze Spark HDInsight
W witrynie Azure Portal wybierz klaster Spark. Aby uzyskać instrukcje, zobacz Wyświetlanie listy i pokazywanie klastrów . Zostanie otwarty widok Przegląd .
W widoku Przegląd w polu Pulpity nawigacyjne klastra wybierz pozycję Notes Jupyter Notebook. Jeśli zostanie wyświetlony monit, wprowadź poświadczenia administratora klastra.
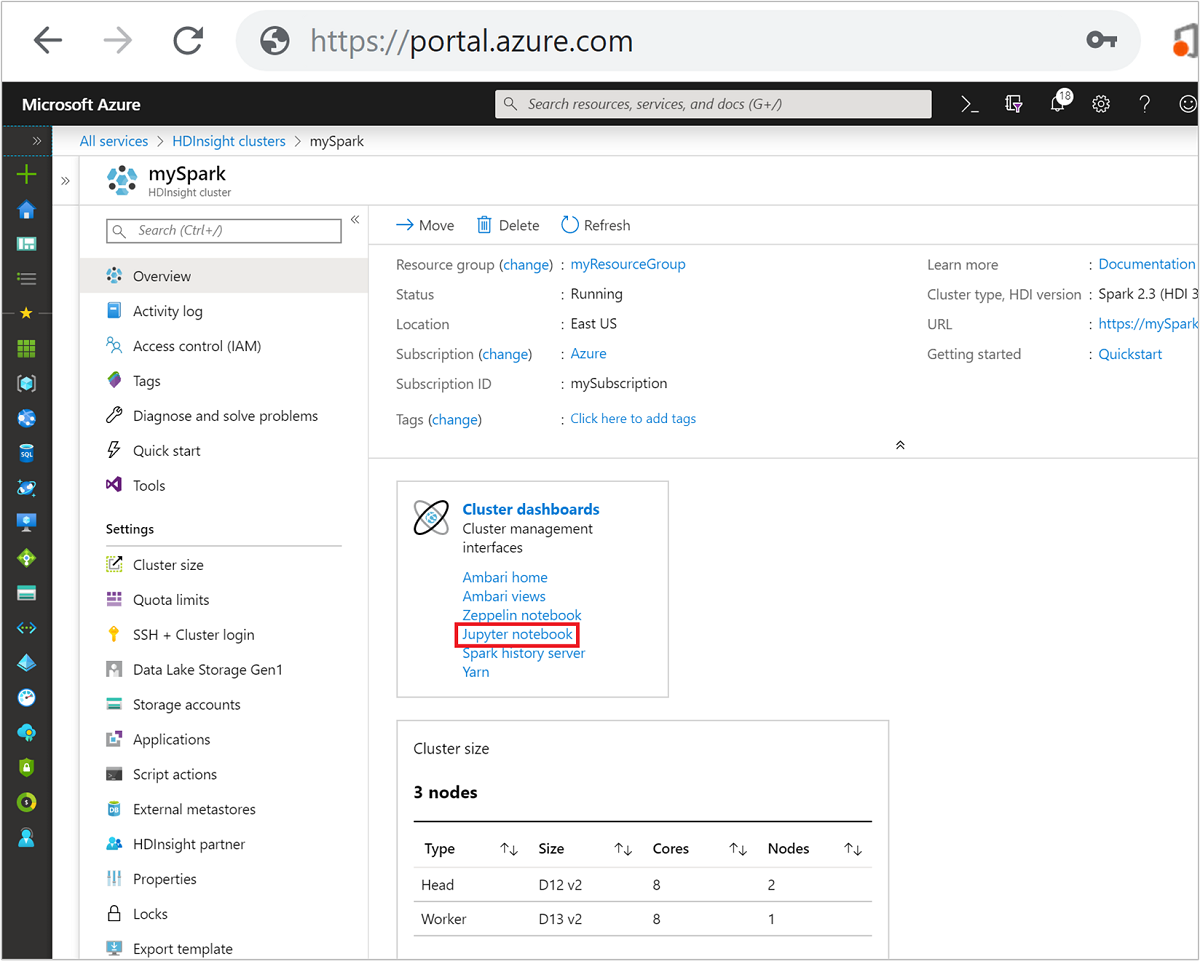
Uwaga
Możesz również uzyskać dostęp do notesu Jupyter Notebook w klastrze Spark, otwierając następujący adres URL w przeglądarce. Zastąp ciąg CLUSTERNAME nazwą klastra:
https://CLUSTERNAME.azurehdinsight.net/jupyterWybierz pozycję Nowy, a następnie wybierz pozycję Pyspark, PySpark3 lub Spark, aby utworzyć notes. Użyj jądra Spark dla aplikacji Scala, jądra PySpark dla aplikacji języka Python2 i jądra PySpark3 dla aplikacji języka Python3.
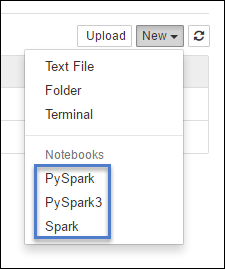
Uwaga
W przypadku platformy Spark 3.1 będzie dostępna tylko platforma PySpark3 lub Spark .
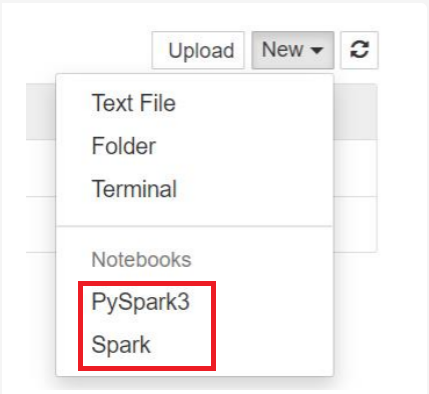
- Zostanie otwarty notes z wybranym jądrem.
Zalety korzystania z jąder
Poniżej przedstawiono kilka zalet używania nowych jąder z notesem Jupyter Notebook w klastrach Spark HDInsight.
Konteksty wstępne. W przypadku platformy PySpark, PySpark3 lub jąder Spark nie trzeba jawnie ustawiać kontekstów Platformy Spark lub Hive przed rozpoczęciem pracy z aplikacjami. Te konteksty są domyślnie dostępne. Te konteksty to:
sc — dla kontekstu platformy Spark
sqlContext — dla kontekstu programu Hive
Dlatego nie musisz uruchamiać instrukcji, takich jak następujące, aby ustawić konteksty:
sc = SparkContext('yarn-client') sqlContext = HiveContext(sc)Zamiast tego można bezpośrednio użyć kontekstów wstępnych w aplikacji.
Magie komórek. Jądra PySpark udostępnia wstępnie zdefiniowane "magie", które są specjalnymi poleceniami, które można wywołać za pomocą
%%polecenia (na przykład%%MAGIC<args>). Magiczne polecenie musi być pierwszym słowem w komórce kodu i zezwalać na wiele wierszy zawartości. Słowo magiczne powinno być pierwszym słowem w komórce. Dodanie czegokolwiek przed magią, nawet komentarze, powoduje błąd. Aby uzyskać więcej informacji na temat magii, zobacz tutaj.W poniższej tabeli wymieniono różne magie dostępne za pośrednictwem jąder.
Magia Przykład opis pomoc %%helpGeneruje tabelę wszystkich dostępnych magii z przykładem i opisem informacje o %%infoZwraca informacje o sesji dla bieżącego punktu końcowego usługi Livy konfigurowanie %%configure -f{"executorMemory": "1000M","executorCores": 4}Konfiguruje parametry tworzenia sesji. Flaga wymuszania ( -f) jest obowiązkowa, jeśli sesja została już utworzona, co gwarantuje, że sesja zostanie porzucona i utworzona ponownie. Zapoznaj się z treścią żądania POST /sessions usługi Livy, aby uzyskać listę prawidłowych parametrów. Parametry muszą być przekazywane jako ciąg JSON i muszą znajdować się w następnym wierszu po magii, jak pokazano w przykładowej kolumnie.sql %%sql -o <variable name>
SHOW TABLESWykonuje zapytanie Programu Hive względem elementu sqlContext. -oJeśli parametr zostanie przekazany, wynik zapytania zostanie utrwalone w kontekście %%local Python jako ramka danych biblioteki Pandas.local %%locala=1Cały kod w późniejszych wierszach jest wykonywany lokalnie. Kod musi być prawidłowym kodem języka Python2 niezależnie od używanego jądra. Tak więc, nawet jeśli podczas tworzenia notesu wybrano jądro PySpark3 lub Spark , jeśli używasz %%localmagii w komórce, komórka musi mieć prawidłowy kod języka Python2.dzienniki %%logsZwraca dzienniki bieżącej sesji usługi Livy. delete %%delete -f -s <session number>Usuwa określoną sesję bieżącego punktu końcowego usługi Livy. Nie można usunąć sesji uruchomionej dla samego jądra. oczyszczanie %%cleanup -fUsuwa wszystkie sesje bieżącego punktu końcowego usługi Livy, w tym sesję tego notesu. Flaga wymuszania -f jest obowiązkowa. Uwaga
Oprócz magii dodanych przez jądro PySpark można również użyć wbudowanych magii IPython, w tym
%%sh. Możesz użyć%%shfunkcji magic do uruchamiania skryptów i bloku kodu w węźle głównym klastra.Automatyczna wizualizacja. Jądro Pyspark automatycznie wizualizuje dane wyjściowe zapytań Hive i SQL. Możesz wybrać między kilkoma różnymi typami wizualizacji, w tym tabelą, kołem, wierszem, obszarem, paskiem.
Parametry obsługiwane za pomocą magii %%sql
Magia %%sql obsługuje różne parametry, których można użyć do kontrolowania rodzaju danych wyjściowych otrzymywanych podczas uruchamiania zapytań. W poniższej tabeli wymieniono dane wyjściowe.
| Parametr | Przykład | opis |
|---|---|---|
| -o | -o <VARIABLE NAME> |
Użyj tego parametru, aby utrwał wynik zapytania w kontekście %%local Python jako ramkę danych biblioteki Pandas . Nazwa zmiennej ramki danych to określona nazwa zmiennej. |
| -q | -q |
Użyj tego parametru, aby wyłączyć wizualizacje dla komórki. Jeśli nie chcesz automatycznie wizualizować zawartości komórki i po prostu chcesz przechwycić ją jako ramkę danych, użyj polecenia -q -o <VARIABLE>. Jeśli chcesz wyłączyć wizualizacje bez przechwytywania wyników (na przykład w przypadku uruchamiania zapytania SQL, takiego jak CREATE TABLE instrukcja), użyj bez -q określania argumentu -o . |
| -m | -m <METHOD> |
Gdzie metoda jest pobierana lub próbka (wartość domyślna to take). Jeśli metoda to take, jądro wybiera elementy z góry zestawu danych wynikowych określonych przez MAXROWS (opisane w dalszej części tej tabeli). Jeśli metoda jest przykładowa, jądro losowo próbkuje elementy zestawu danych zgodnie z -r parametrem opisanym w następnej tabeli. |
| -r | -r <FRACTION> |
Tutaj FUNKCJA FRACTION jest liczbą zmiennoprzecinkową z zakresu od 0,0 do 1,0. Jeśli przykładowa metoda zapytania SQL to sample, jądro losowo próbkuje określony ułamek elementów zestawu wyników. Jeśli na przykład uruchamiasz zapytanie SQL z argumentami -m sample -r 0.01, 1% wierszy wyników jest losowo próbkowanych. |
| -n | -n <MAXROWS> |
MAXROWS jest wartością całkowitą. Jądro ogranicza liczbę wierszy wyjściowych do MAXROWS. Jeśli parametr MAXROWS jest liczbą ujemną, taką jak -1, liczba wierszy w zestawie wyników nie jest ograniczona. |
Przykład:
%%sql -q -m sample -r 0.1 -n 500 -o query2
SELECT * FROM hivesampletable
W powyższej instrukcji są wykonane następujące akcje:
- Wybiera wszystkie rekordy z elementu hivesampletable.
- Ponieważ używamy -q, wyłącza autovisualization.
- Ponieważ używamy
-m sample -r 0.1 -n 500metody , losowo próbkuje 10% wierszy w tabeli hivesampletable i ogranicza rozmiar zestawu wyników do 500 wierszy. - Na koniec, ponieważ użyliśmy
-o query2go również zapisuje dane wyjściowe w ramce danych o nazwie query2.
Zagadnienia dotyczące korzystania z nowych jąder
Niezależnie od używanego jądra, pozostawiając uruchomione notesy zużywają zasoby klastra. W przypadku tych jąder, ponieważ konteksty są wstępnie ustawione, po prostu wyjście z notesów nie powoduje zabicia kontekstu. A więc zasoby klastra nadal są używane. Dobrym rozwiązaniem jest użycie opcji Zamknij i zatrzymaj z menu Plik notesu po zakończeniu korzystania z notesu. Zamknięcie zabija kontekst, a następnie zamyka notes.
Gdzie są przechowywane notesy?
Jeśli klaster używa usługi Azure Storage jako domyślnego konta magazynu, notesy Jupyter Notebook są zapisywane na koncie magazynu w folderze /HdiNotebooks . Notesy, pliki tekstowe i foldery utworzone z poziomu programu Jupyter są dostępne z poziomu konta magazynu. Jeśli na przykład używasz programu Jupyter do tworzenia folderu myfolder i notesu myfolder/mynotebook.ipynb, możesz uzyskać dostęp do tego notesu na /HdiNotebooks/myfolder/mynotebook.ipynb koncie magazynu. Odwrotnie jest również prawdą, czyli jeśli przekażesz notes bezpośrednio do konta magazynu w witrynie /HdiNotebooks/mynotebook1.ipynb, notes będzie widoczny również w programie Jupyter. Notesy pozostają na koncie magazynu nawet po usunięciu klastra.
Uwaga
Klastry usługi HDInsight z usługą Azure Data Lake Storage jako magazyn domyślny nie przechowują notesów w skojarzonym magazynie.
Sposób zapisywania notesów na koncie magazynu jest zgodny z systemem plików HDFS platformy Apache Hadoop. W przypadku korzystania z protokołu SSH w klastrze można użyć poleceń zarządzania plikami:
| Polecenie | opis |
|---|---|
hdfs dfs -ls /HdiNotebooks |
# Wyświetl wszystko w katalogu głównym — wszystko w tym katalogu jest widoczne dla programu Jupyter ze strony głównej |
hdfs dfs –copyToLocal /HdiNotebooks |
# Pobierz zawartość folderu HdiNotebooks |
hdfs dfs –copyFromLocal example.ipynb /HdiNotebooks |
# Przekaż plik example.ipynb notesu do folderu głównego, aby był widoczny w programie Jupyter |
Niezależnie od tego, czy klaster używa usługi Azure Storage, czy usługi Azure Data Lake Storage jako domyślnego konta magazynu, notesy są również zapisywane w węźle głównym klastra pod adresem /var/lib/jupyter.
Obsługiwana przeglądarka
Notesy Jupyter Notebook w klastrach Spark HDInsight są obsługiwane tylko w przeglądarce Google Chrome.
Sugestie
Nowe jądra są w zmieniającym się etapie i dojrzały wraz z upływem czasu. Dzięki temu interfejsy API mogą ulec zmianie w miarę dojrzewania tych jąder. Dziękujemy za wszelkie opinie, które masz podczas korzystania z tych nowych jąder. Opinie są przydatne podczas kształtowania końcowej wersji tych jąder. Komentarze/opinie możesz pozostawić w sekcji Opinie w dolnej części tego artykułu.
Następne kroki
- Przegląd: platforma Apache Spark w usłudze Azure HDInsight
- Używanie notesów Apache Zeppelin z klastrem Apache Spark w usłudze HDInsight
- Używanie pakietów zewnętrznych z notesami Jupyter Notebook
- Instalacja oprogramowania Jupyter na komputerze i nawiązywanie połączenia z klastrem Spark w usłudze HDInsight