Używanie rozszerzonych funkcji serwera historii platformy Apache Spark do debugowania i diagnozowania aplikacji platformy Spark
W tym artykule pokazano, jak używać rozszerzonych funkcji serwera historii platformy Apache Spark do debugowania i diagnozowania ukończonych lub uruchomionych aplikacji platformy Spark. Rozszerzenie zawiera kartę Dane , kartę Grafu i kartę Diagnostyka . Na karcie Dane możesz sprawdzić dane wejściowe i wyjściowe zadania platformy Spark. Na karcie Graf możesz sprawdzić przepływ danych i odtworzyć wykres zadania. Na karcie Diagnostyka można odwoływać się do funkcji Niesymetryczność danych, Niesymetryczność czasu i Analiza użycia funkcji wykonawczej.
Uzyskiwanie dostępu do serwera historii platformy Spark
Serwer historii platformy Spark to internetowy interfejs użytkownika dla ukończonych i uruchomionych aplikacji platformy Spark. Możesz otworzyć go w witrynie Azure Portal lub w adresie URL.
Otwórz internetowy interfejs użytkownika serwera historii platformy Spark w witrynie Azure Portal
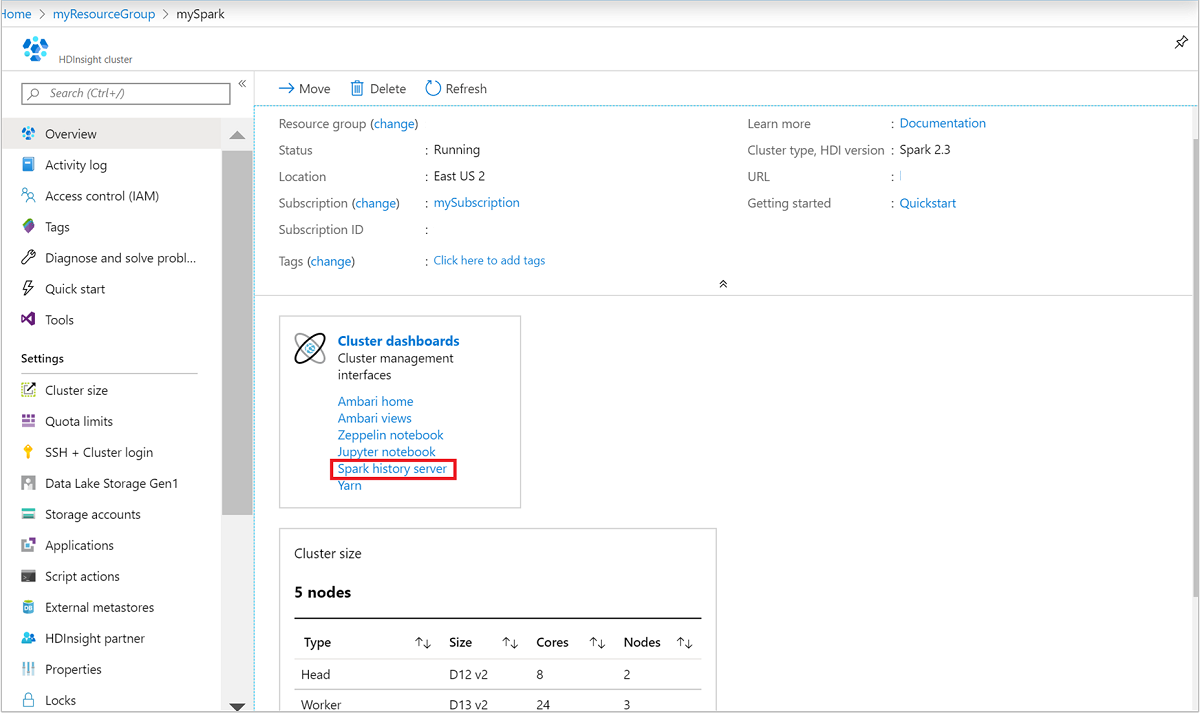
W witrynie Azure Portal otwórz klaster Spark. Aby uzyskać więcej informacji, zobacz Wyświetlanie i wyświetlanie klastrów.
W obszarze Pulpity nawigacyjne klastra wybierz pozycję Serwer historii platformy Spark. Po wyświetleniu monitu wprowadź poświadczenia administratora dla klastra Spark.
 witryna Azure Portal." border="true":::
witryna Azure Portal." border="true":::
Otwórz internetowy interfejs użytkownika serwera historii platformy Spark według adresu URL
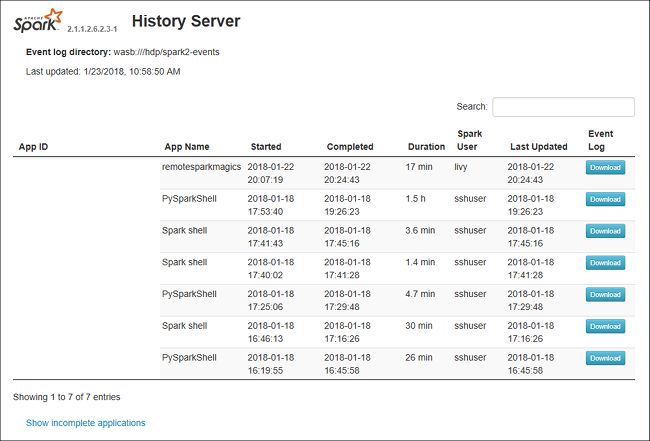
Otwórz serwer historii platformy Spark, przechodząc do https://CLUSTERNAME.azurehdinsight.net/sparkhistorylokalizacji , gdzie CLUSTERNAME jest nazwą klastra Spark.
Internetowy interfejs użytkownika serwera historii platformy Spark może wyglądać podobnie do poniższego obrazu:
Korzystanie z karty Dane na serwerze historii platformy Spark
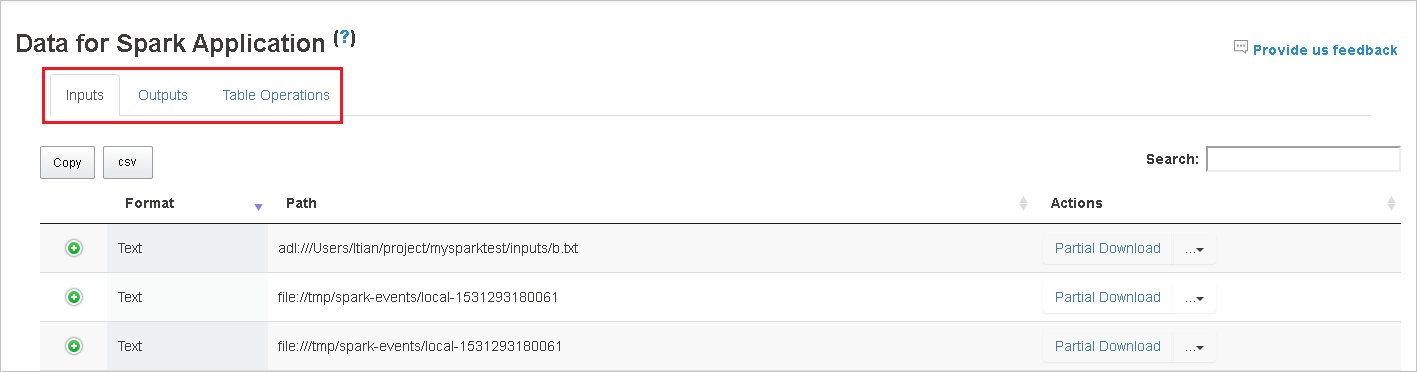
Wybierz identyfikator zadania, a następnie wybierz pozycję Dane w menu narzędzi, aby wyświetlić widok danych.
Przejrzyj dane wejściowe, dane wyjściowe i operacje tabeli, wybierając poszczególne karty.
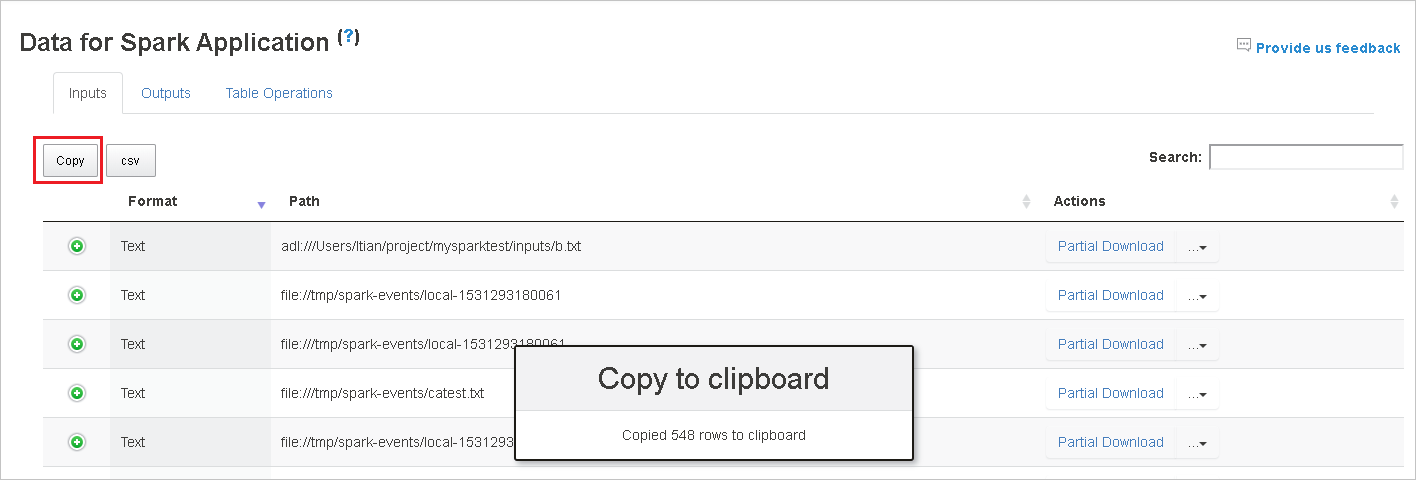
Skopiuj wszystkie wiersze, wybierając przycisk Kopiuj .
Zapisz wszystkie dane jako . Plik CSV, wybierając przycisk csv .
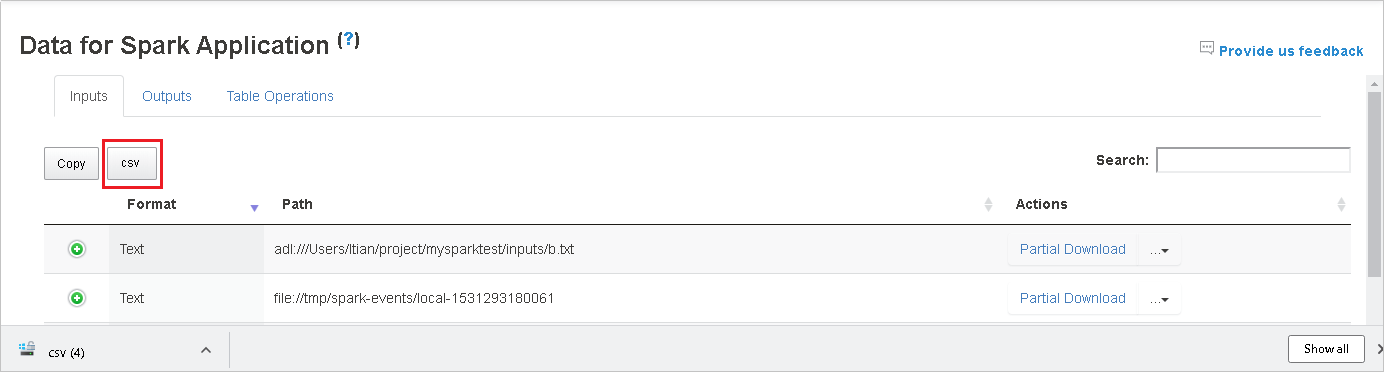
Przeszukaj dane, wprowadzając słowa kluczowe w polu Wyszukaj . Wyniki wyszukiwania będą wyświetlane natychmiast.
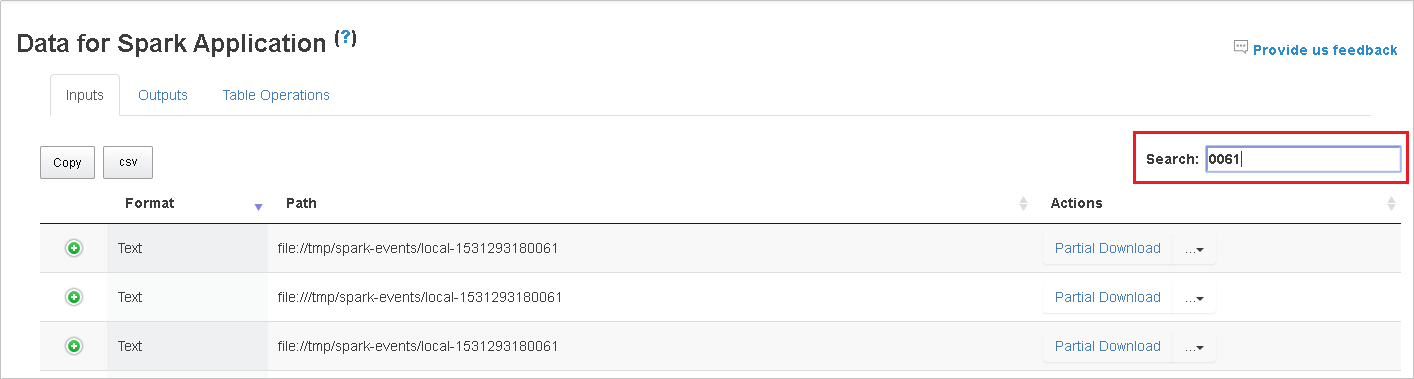
Wybierz nagłówek kolumny, aby posortować tabelę. Wybierz znak plus, aby rozwinąć wiersz, aby wyświetlić więcej szczegółów. Wybierz znak minus, aby zwinąć wiersz.
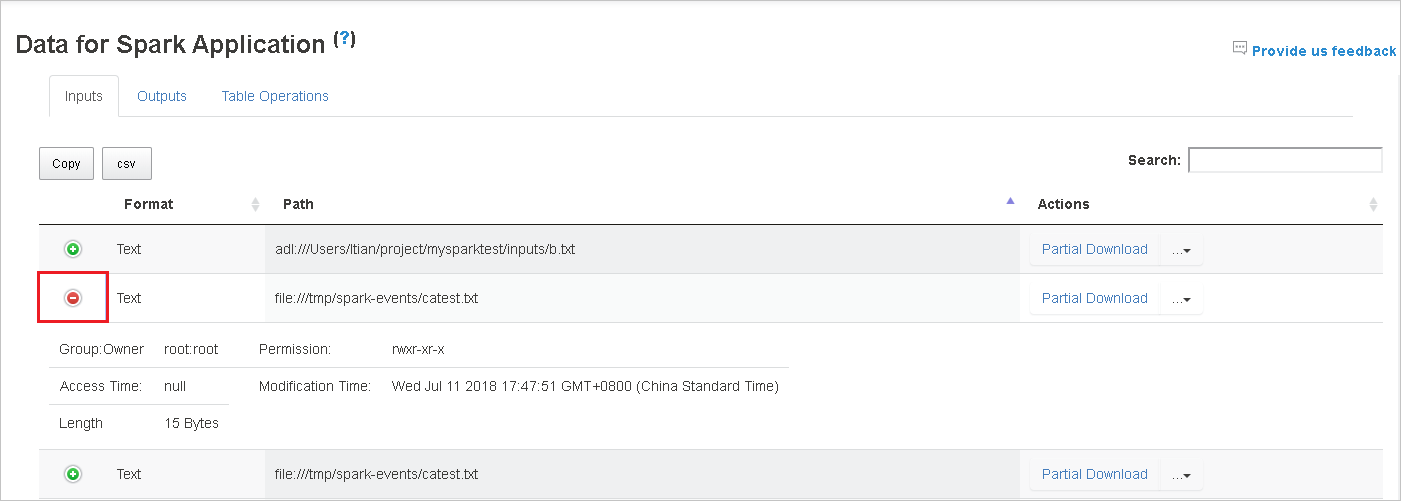
Pobierz pojedynczy plik, wybierając przycisk Pobierz częściowe po prawej stronie. Wybrany plik zostanie pobrany lokalnie. Jeśli plik już nie istnieje, spowoduje to otwarcie nowej karty w celu wyświetlenia komunikatów o błędach.
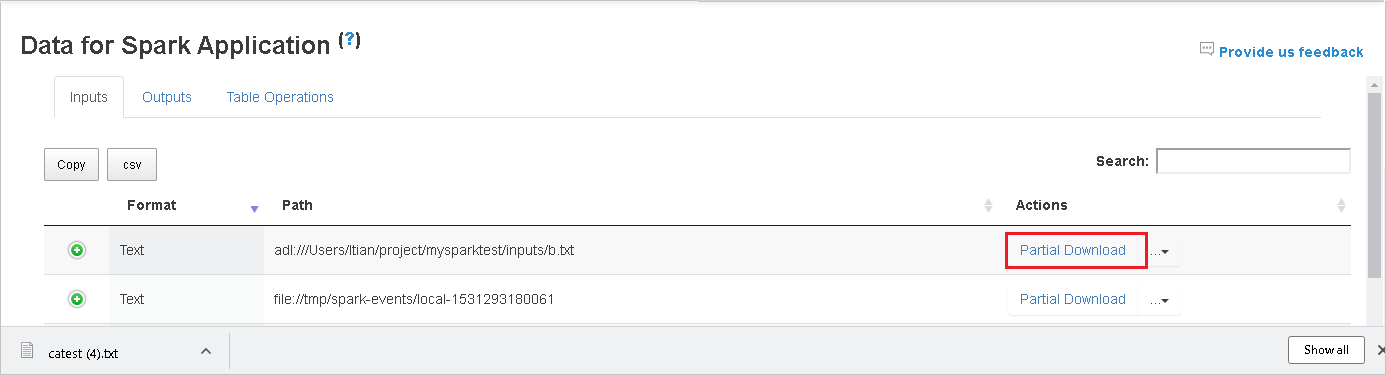
Skopiuj pełną ścieżkę lub ścieżkę względną, wybierając opcję Kopiuj pełną ścieżkę lub Kopiuj ścieżkę względną, która rozwija się z menu pobierania. W przypadku plików usługi Azure Data Lake Storage wybierz pozycję Otwórz w Eksplorator usługi Azure Storage, aby uruchomić Eksplorator usługi Azure Storage i zlokalizować folder po zalogowaniu.
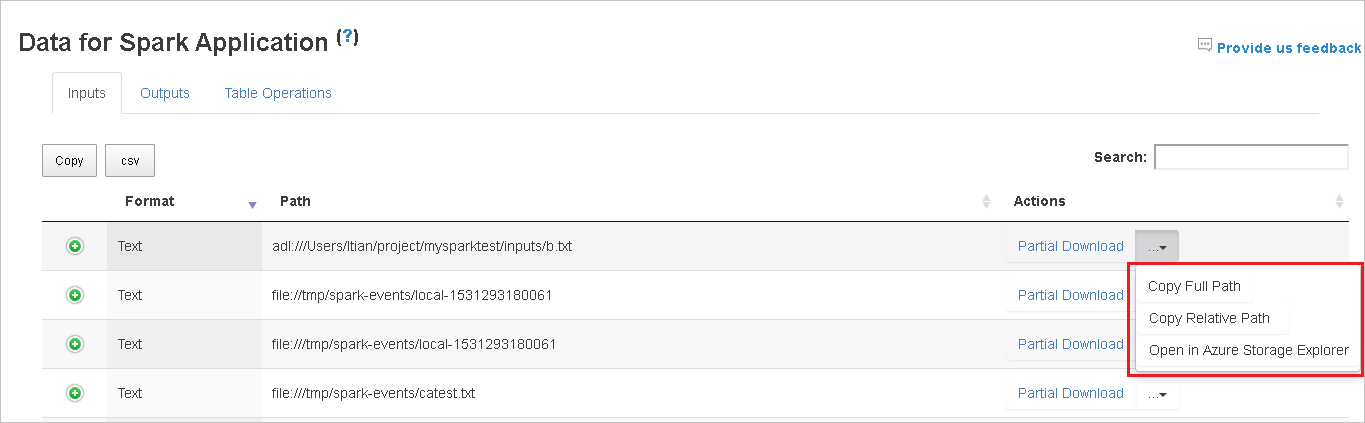
Jeśli na jednej stronie jest wyświetlanych zbyt wiele wierszy, wybierz numery stron w dolnej części tabeli, aby przejść.

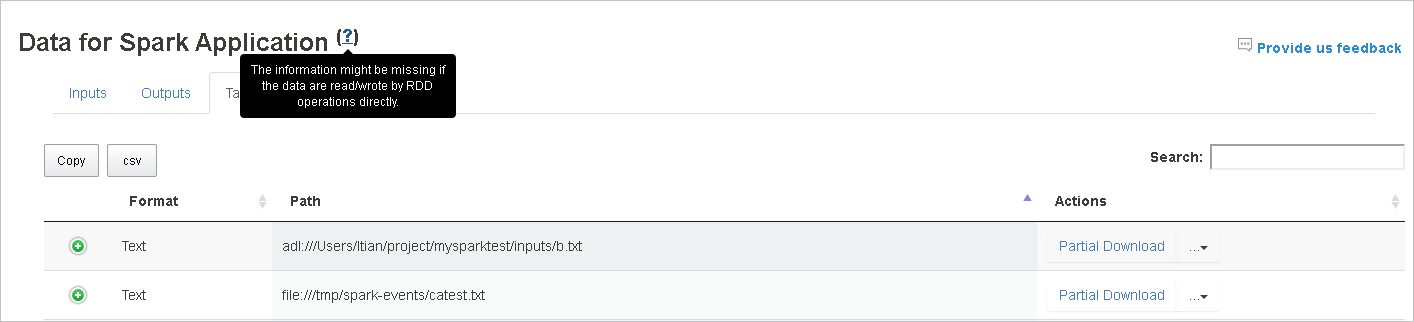
Aby uzyskać więcej informacji, umieść kursor na lub wybierz znak zapytania obok pozycji Dane aplikacji spark, aby wyświetlić etykietkę narzędzia.
Aby wysłać opinię na temat problemów, wybierz pozycję Przekaż nam opinię.
Korzystanie z karty Graph na serwerze historii platformy Spark
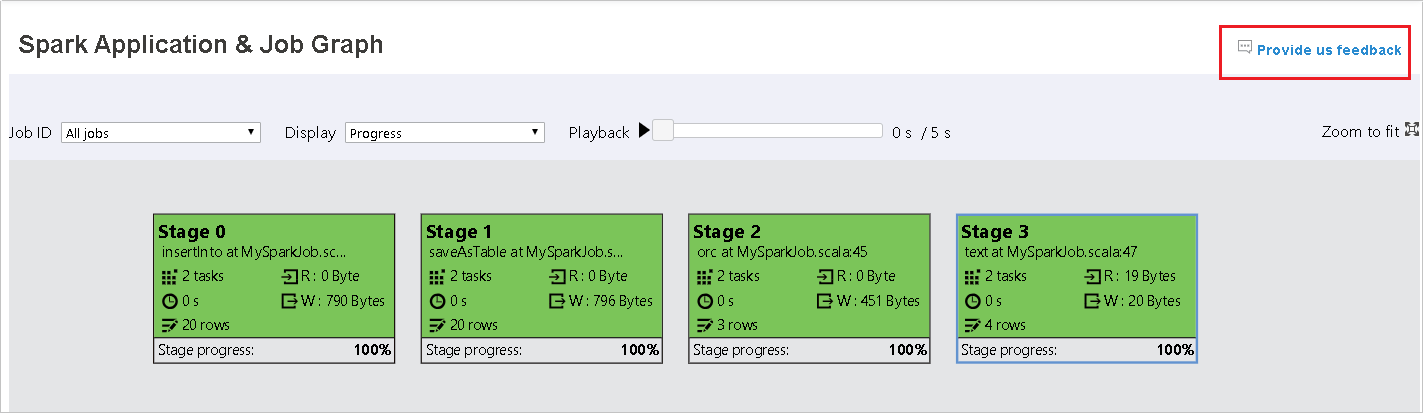
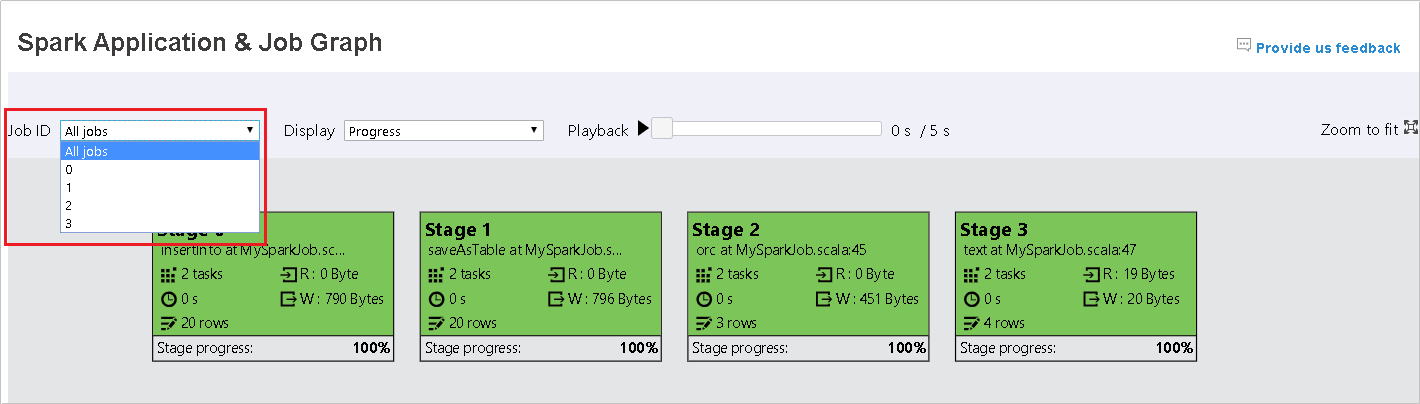
Wybierz identyfikator zadania, a następnie wybierz pozycję Graph w menu narzędzi, aby wyświetlić wykres zadania. Domyślnie na wykresie będą wyświetlane wszystkie zadania. Filtruj wyniki przy użyciu menu rozwijanego Identyfikator zadania.
Postęp jest domyślnie wybierany. Sprawdź przepływ danych, wybierając pozycję Odczyt lub Zapis w menu rozwijanym Wyświetlanie .
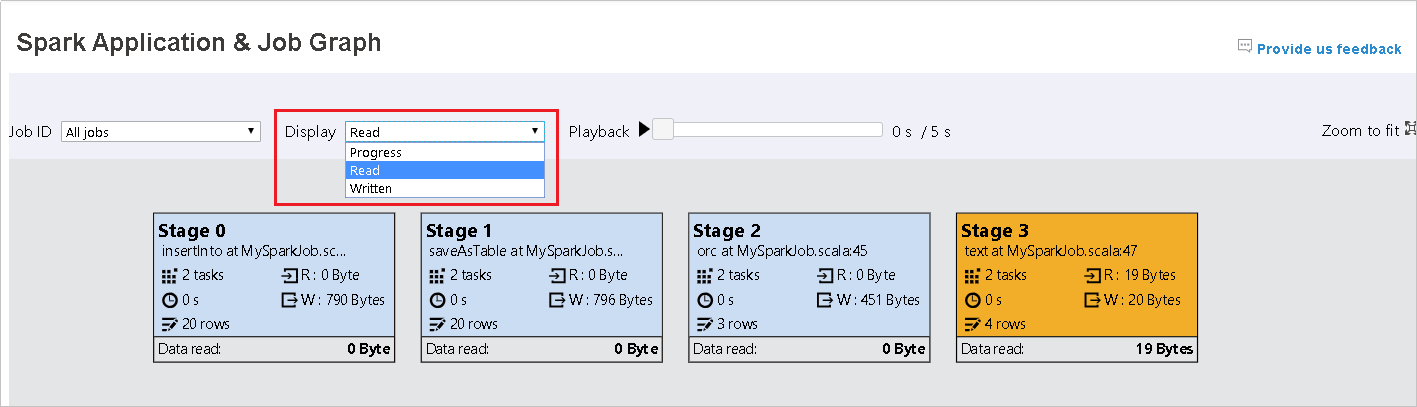
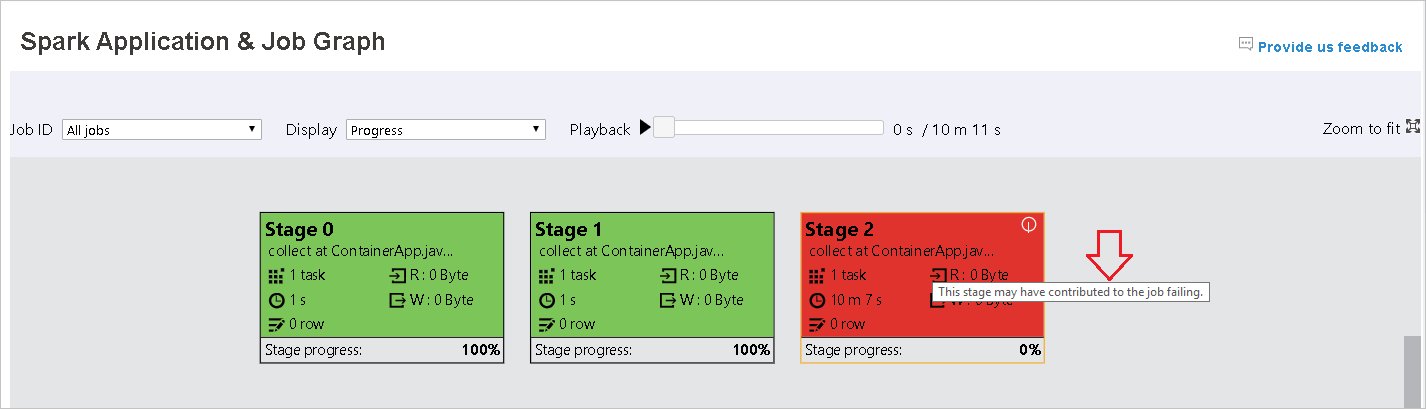
Kolor tła każdego zadania odpowiada mapie cieplnej.

Color opis Green (Zielony) Zadanie zostało ukończone pomyślnie. Orange Zadanie nie powiodło się, ale nie ma to wpływu na ostateczny wynik zadania. Te zadania mają zduplikowane lub ponawiane próby wystąpienia, które mogą zakończyć się powodzeniem później. Niebieskie Zadanie jest uruchomione. Biała Zadanie czeka na uruchomienie lub etap został pominięty. Czerwony Zadanie nie powiodło się. 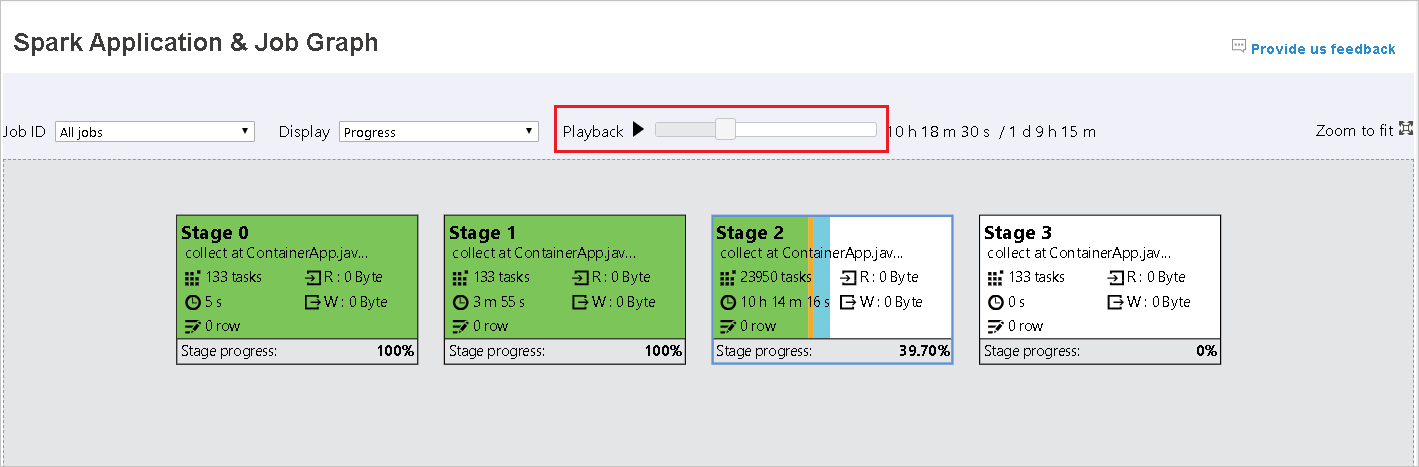
Pominięte etapy są wyświetlane w kolorze białym.
Uwaga
Odtwarzanie jest dostępne dla ukończonych zadań. Wybierz przycisk Odtwarzanie, aby odtworzyć zadanie z powrotem. Zatrzymaj zadanie w dowolnym momencie, wybierając przycisk Zatrzymaj. Gdy zadanie zostanie odtworzona, każde zadanie wyświetli jego stan według koloru. Odtwarzanie nie jest obsługiwane w przypadku zadań niekompletnych.
Przewiń w celu powiększenia lub powiększenia wykresu zadania lub wybierz pozycję Powiększ, aby dopasować go do ekranu.
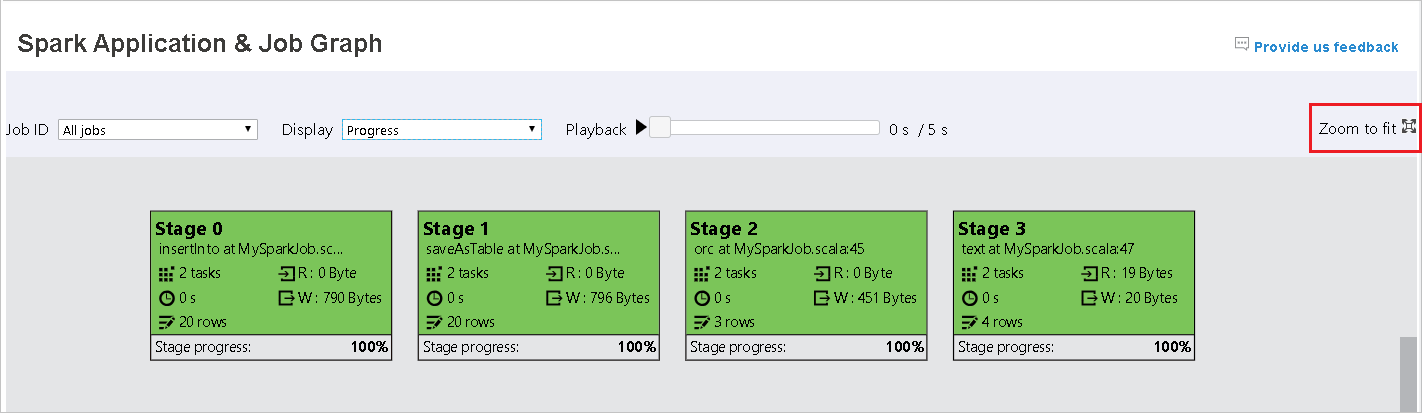
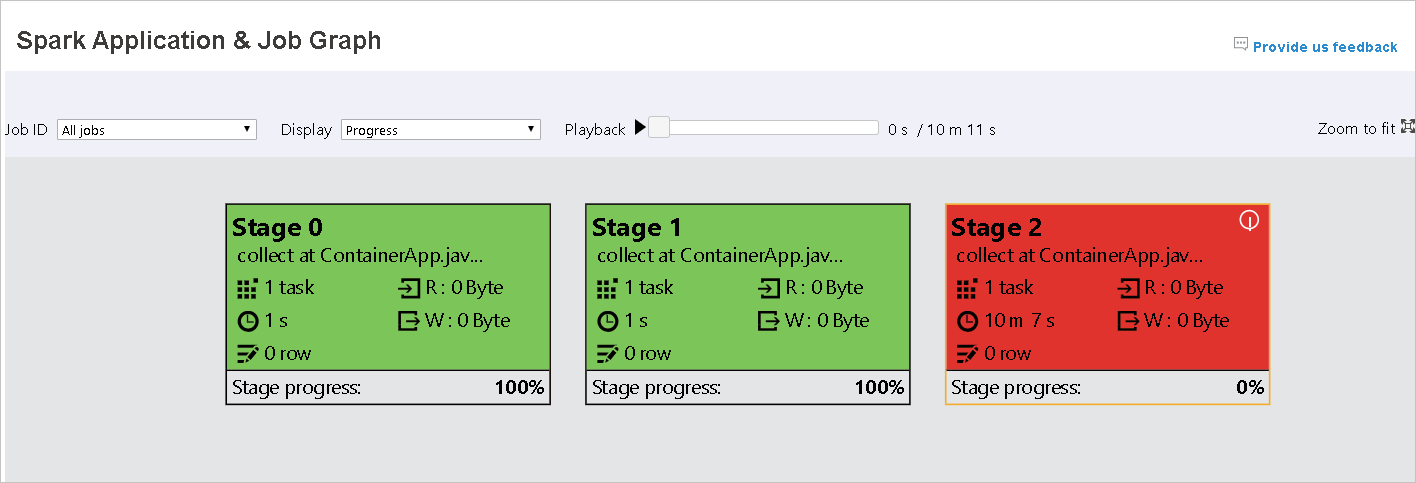
Gdy zadania kończą się niepowodzeniem, umieść kursor na węźle grafu, aby wyświetlić etykietkę narzędzia, a następnie wybierz etap, aby otworzyć go na nowej stronie.
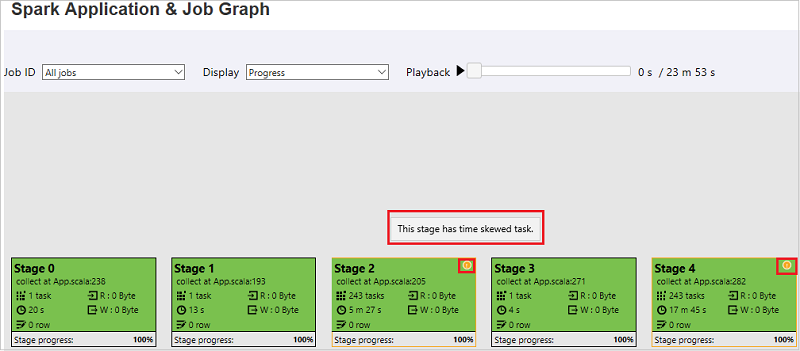
Na stronie Wykres aplikacji i zadań platformy Spark etapy będą wyświetlać etykietki narzędzi i małe ikony, jeśli zadania spełniają następujące warunki:
Niesymetryczność danych: średni rozmiar odczytu danych rozmiar > wszystkich zadań w tym etapie * 2 i rozmiar > odczytu danych 10 MB.
Niesymetryczność czasu>: Średni czas wykonywania wszystkich zadań w tym etapie * 2 i czas > wykonywania 2 minuty.
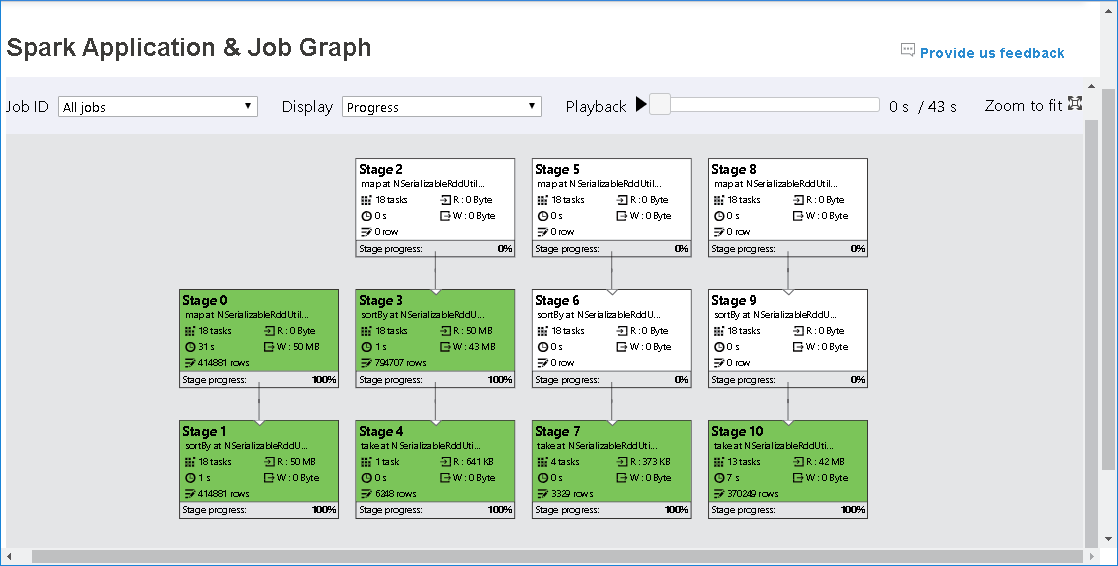
Węzeł grafu zadania wyświetli następujące informacje o każdym etapie:
ID
Nazwa lub opis
Łączna liczba zadań
Odczyt danych: suma rozmiaru danych wejściowych i rozmiaru odczytu mieszania
Zapis danych: suma rozmiaru danych wyjściowych i rozmiaru zapisu mieszania
Czas wykonywania: czas między godziną rozpoczęcia pierwszej próby a czasem zakończenia ostatniej próby
Liczba wierszy: suma rekordów wejściowych, rekordów wyjściowych, mieszania rekordów odczytu i mieszania rekordów zapisu
Postęp
Uwaga
Domyślnie węzeł wykresu zadania wyświetli informacje z ostatniej próby każdego etapu (z wyjątkiem czasu wykonywania etapu). Jednak podczas odtwarzania węzeł grafu zadań wyświetli informacje o każdej próbie.
Uwaga
W przypadku rozmiarów odczytu i zapisu danych używamy 1 MB = 1000 KB = 1000 * 1000 bajtów.
Prześlij opinię o problemach, wybierając pozycję Przekaż nam opinię.
Korzystanie z karty Diagnostyka na serwerze historii platformy Spark
Wybierz identyfikator zadania, a następnie wybierz pozycję Diagnoza w menu narzędzi, aby wyświetlić widok diagnostyki zadania. Karta Diagnostyka zawiera niesymetryczność danych, niesymetryczność czasu i analizę użycia funkcji wykonawczej.
Przejrzyj opcje Niesymetryczność danych, Niesymetryczność czasu i Analiza użycia funkcji wykonawczej, wybierając odpowiednio karty.
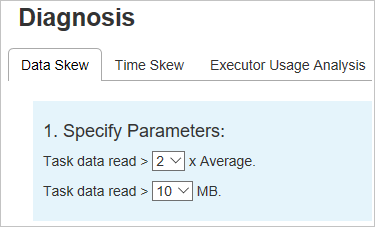
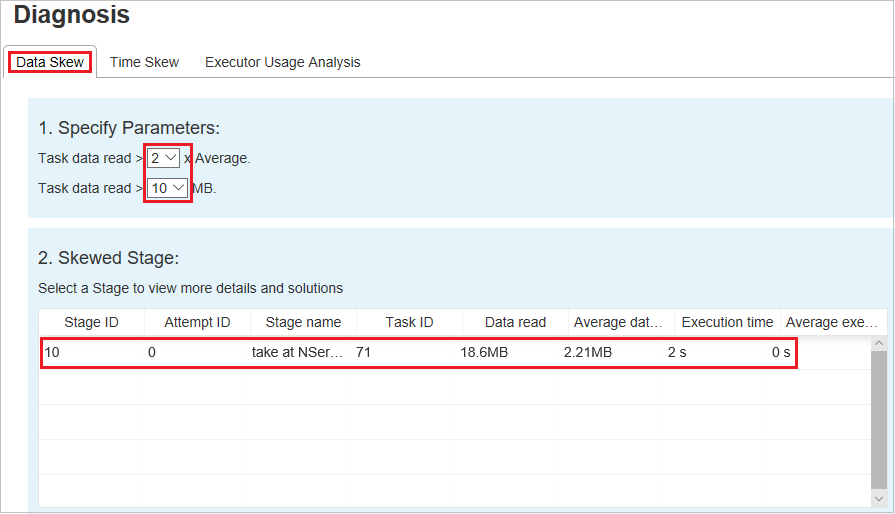
Niesymetryczność danych
Wybierz kartę Niesymetryczność danych. Odpowiednie niesymetryczne zadania są wyświetlane na podstawie określonych parametrów.
Określanie parametrów
W sekcji Określanie parametrów są wyświetlane parametry, które są używane do wykrywania niesymetryczności danych. Reguła domyślna to: Odczyt danych zadania jest większy niż trzy razy w przypadku odczytywania średnich danych zadania, a odczyt danych zadania wynosi ponad 10 MB. Jeśli chcesz zdefiniować własną regułę dla niesymetrycznych zadań, możesz wybrać parametry. Sekcje Niesymetryczne etapy i Wykres niesymetryczny zostaną odpowiednio zaktualizowane.
Etap niesymetryczny
W sekcji Niesymetryczne etapy są wyświetlane etapy, które mają niesymetryczne zadania spełniające określone kryteria. Jeśli na etapie znajduje się więcej niż jedno niesymetryczne zadanie, sekcja Niesymetryczne etapy wyświetla tylko najbardziej niesymetryczne zadanie (czyli największe dane dotyczące niesymetryczności danych).
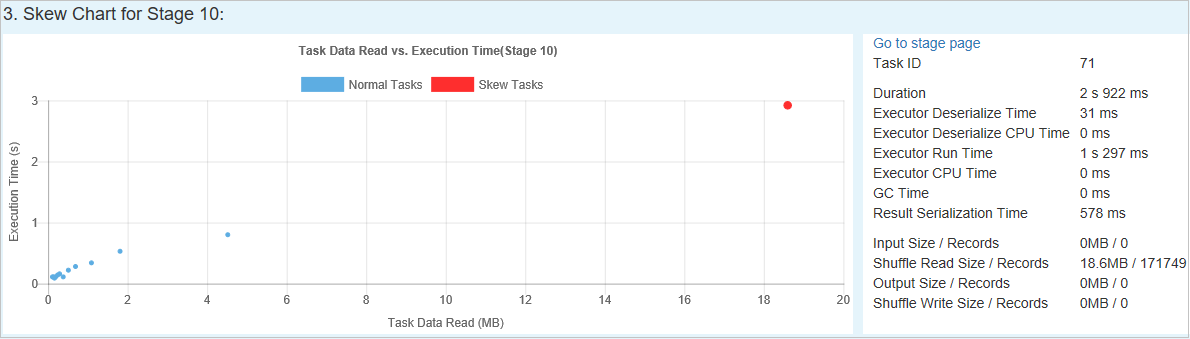
Wykres niesymetryczny
Po wybraniu wiersza w tabeli Etap niesymetryczności wykres niesymetryczny wyświetla więcej szczegółów dystrybucji zadań na podstawie czasu odczytu i wykonywania danych. Zadania niesymetryczne są oznaczone kolorem czerwonym, a normalne zadania są oznaczone kolorem niebieskim. W celu rozważenia wydajności wykres wyświetla maksymalnie 100 przykładowych zadań. Szczegóły zadania są wyświetlane w prawym dolnym panelu.
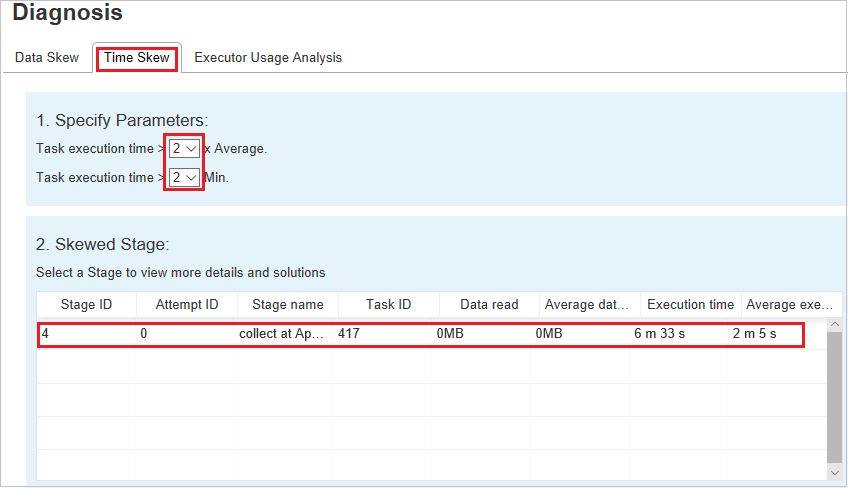
Niesymetryczność czasu
Karta Niesymetryczność czasu wyświetla niesymetryczne zadania na podstawie czasu wykonywania zadania.
Określanie parametrów
W sekcji Określanie parametrów są wyświetlane parametry, które są używane do wykrywania niesymetryczności czasu. Reguła domyślna to: Czas wykonywania zadania jest większy niż trzy razy w średnim czasie wykonywania, a czas wykonywania zadania jest dłuższy niż 30 sekund. Parametry można zmienić na podstawie Twoich potrzeb. Wykres niesymetryczny etapu i niesymetryczności wyświetla odpowiednie informacje o etapach i zadaniach, podobnie jak na karcie Niesymetryczność danych.
Po wybraniu pozycji Niesymetryczność czasu filtrowany wynik zostanie wyświetlony w sekcji Etap niesymetryczny zgodnie z parametrami ustawionymi w sekcji Określanie parametrów. Po wybraniu jednego elementu w sekcji Etap niesymetryczny odpowiedni wykres jest opracowywany w trzeciej sekcji, a szczegóły zadania są wyświetlane w prawym dolnym panelu.
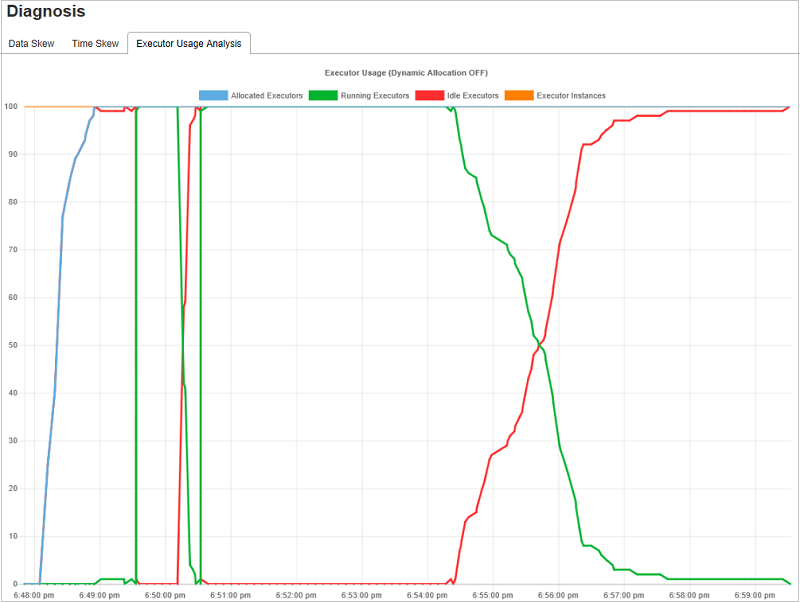
Wykresy analizy użycia funkcji wykonawczej
Wykres użycia funkcji wykonawczej wyświetla rzeczywistą alokację funkcji wykonawczej i stan uruchomienia zadania.
Po wybraniu opcji Analiza użycia funkcji wykonawczej są tworzone cztery różne krzywe dotyczące użycia funkcji wykonawczej: Przydzielone funkcje wykonawcze, Uruchomione funkcje wykonawcze, bezczynne funkcje wykonawcze i Maksymalna liczba wystąpień funkcji wykonawczych. Każde zdarzenie funkcji wykonawczej dodane lub usunięte funkcji wykonawczej spowoduje zwiększenie lub zmniejszenie przydzielonych funkcji wykonawczych. Oś czasu zdarzenia można sprawdzić na karcie Zadania, aby uzyskać więcej porównań.
Wybierz ikonę koloru, aby wybrać lub usunąć zaznaczenie odpowiedniej zawartości we wszystkich wersjach roboczych.

Często zadawane pytania
Jak mogę przywrócić wersję społeczności?
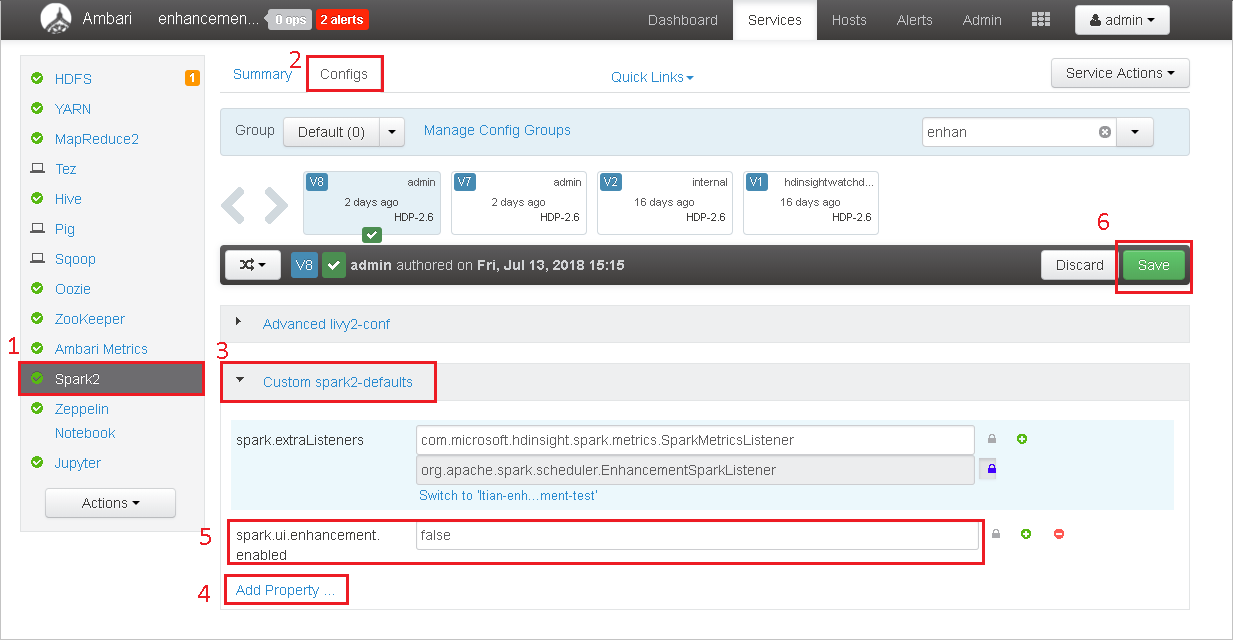
Aby przywrócić wersję społeczności, wykonaj następujące kroki.
Otwórz klaster w systemie Ambari.
Przejdź do pozycji Spark2 Configs (Konfiguracje platformy Spark2>).
Wybierz pozycję Niestandardowe spark2-defaults.
Wybierz pozycję Dodaj właściwość ....
Dodaj wartość spark.ui.enhancement.enabled=false, a następnie zapisz ją.
Właściwość ustawia wartość false teraz.
Wybierz Zapisz, aby zapisać konfigurację.
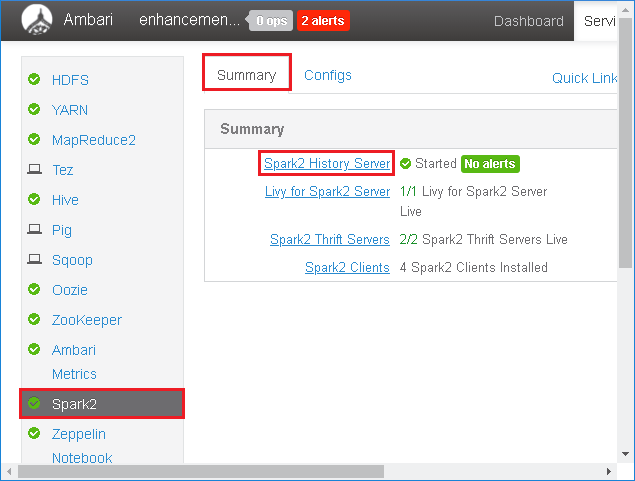
Wybierz pozycję Spark2 w panelu po lewej stronie. Następnie na karcie Podsumowanie wybierz pozycję Serwer historii Platformy Spark2.
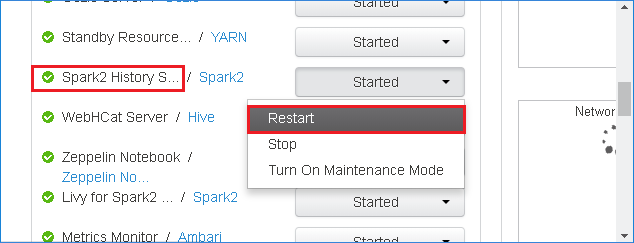
Aby ponownie uruchomić serwer historii platformy Spark, wybierz przycisk Uruchomiono po prawej stronie serwera historii Spark2, a następnie wybierz pozycję Uruchom ponownie z menu rozwijanego.
Odśwież internetowy interfejs użytkownika serwera historii platformy Spark. Nastąpi przywrócenie wersji community.
Jak mogę przekazać zdarzenie serwera historii platformy Spark, aby zgłosić go jako problem?
Jeśli wystąpi błąd na serwerze historii platformy Spark, wykonaj następujące kroki, aby zgłosić zdarzenie.
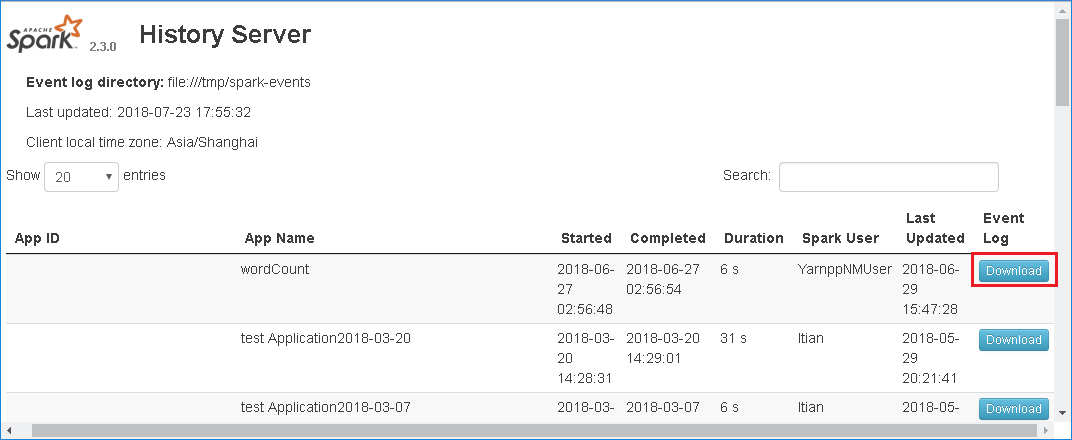
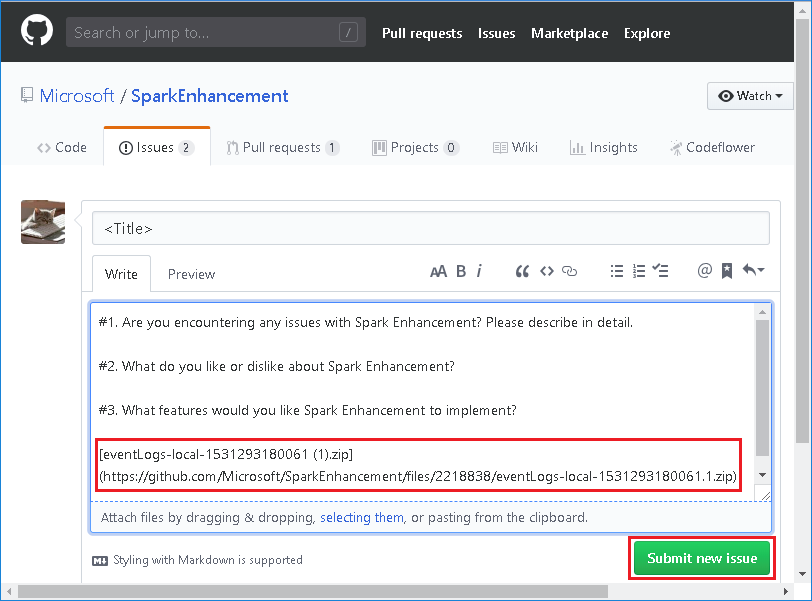
Pobierz zdarzenie, wybierając pozycję Pobierz w internetowym interfejsie użytkownika serwera historii platformy Spark.
Wybierz pozycję Przekaż nam opinię na stronie Wykres aplikacji i zadań platformy Spark.
Podaj tytuł i opis błędu. Następnie przeciągnij plik .zip do pola edycji i wybierz pozycję Prześlij nowy problem.
Jak mogę uaktualnić plik .jar w scenariuszu poprawki?
Jeśli chcesz uaktualnić poprawkę, użyj następującego skryptu, który uaktualni program spark-enhancement.jar*.
upgrade_spark_enhancement.sh:
#!/usr/bin/env bash
# Copyright (C) Microsoft Corporation. All rights reserved.
# Arguments:
# $1 Enhancement jar path
if [ "$#" -ne 1 ]; then
>&2 echo "Please provide the upgrade jar path."
exit 1
fi
install_jar() {
tmp_jar_path="/tmp/spark-enhancement-hotfix-$( date +%s )"
if wget -O "$tmp_jar_path" "$2"; then
for FILE in "$1"/spark-enhancement*.jar
do
back_up_path="$FILE.original.$( date +%s )"
echo "Back up $FILE to $back_up_path"
mv "$FILE" "$back_up_path"
echo "Copy the hotfix jar file from $tmp_jar_path to $FILE"
cp "$tmp_jar_path" "$FILE"
"Hotfix done."
break
done
else
>&2 echo "Download jar file failed."
exit 1
fi
}
jars_folder="/usr/hdp/current/spark2-client/jars"
jar_path=$1
if ls ${jars_folder}/spark-enhancement*.jar 1>/dev/null 2>&1; then
install_jar "$jars_folder" "$jar_path"
else
>&2 echo "There is no target jar on this node. Exit with no action."
exit 0
fi
Użycie
upgrade_spark_enhancement.sh https://${jar_path}
Przykład
upgrade_spark_enhancement.sh https://${account_name}.blob.core.windows.net/packages/jars/spark-enhancement-${version}.jar
Używanie pliku powłoki bash z witryny Azure Portal
Uruchom witrynę Azure Portal, a następnie wybierz klaster.
Ukończ akcję skryptu przy użyciu następujących parametrów.
Właściwości Wartość Typ skryptu -Niestandardowe Nazwisko UpgradeJar Identyfikator URI skryptu powłoki Bash https://hdinsighttoolingstorage.blob.core.windows.net/shsscriptactions/upgrade_spark_enhancement.shTypy węzłów Kierownik, Pracownik Parametry https://${account_name}.blob.core.windows.net/packages/jars/spark-enhancement-${version}.jar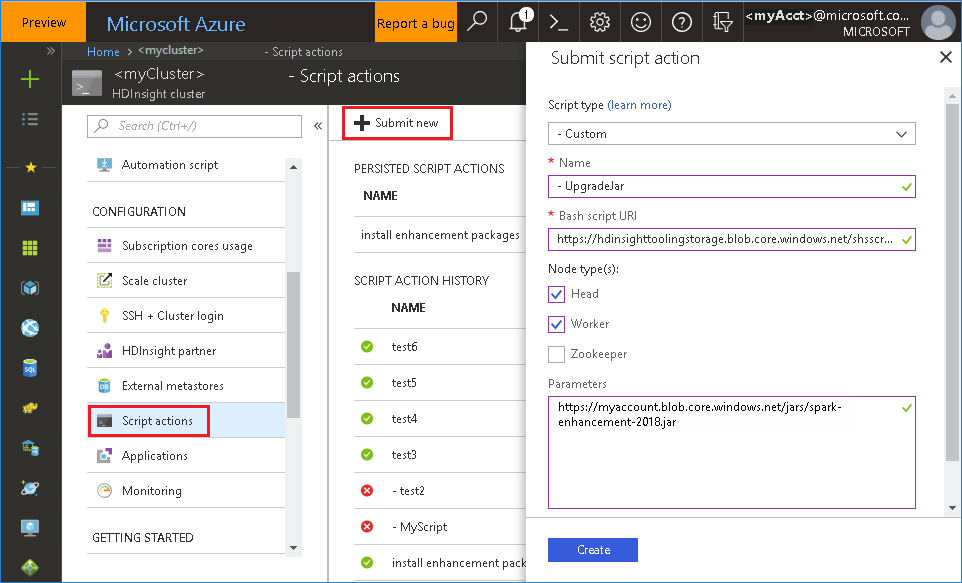
Znane problemy
Obecnie serwer historii platformy Spark działa tylko dla platformy Spark 2.3 i 2.4.
Dane wejściowe i wyjściowe korzystające z rdD nie będą wyświetlane na karcie Dane .
Następne kroki
- Zarządzanie zasobami dla klastra Apache Spark w usłudze HDInsight
- Konfigurowanie ustawień platformy Apache Spark
Sugestie
Jeśli masz jakiekolwiek opinie lub napotkasz jakiekolwiek problemy podczas korzystania z tego narzędzia, wyślij wiadomość e-mail na adres (hdivstool@microsoft.com).