Analizowanie dzienników telemetrycznych usługi Application Insights za pomocą platformy Apache Spark w usłudze HDInsight
Dowiedz się, jak używać platformy Apache Spark w usłudze HDInsight do analizowania danych telemetrycznych usługi Application Insights.
Visual Studio Application Insights to usługa analityczna, która monitoruje aplikacje internetowe. Dane telemetryczne generowane przez usługę Application Insights można eksportować do usługi Azure Storage. Gdy dane są w usłudze Azure Storage, usługa HDInsight może służyć do ich analizowania.
Wymagania wstępne
Aplikacja skonfigurowana do korzystania z usługi Application Insights.
Znajomość tworzenia klastra usługi HDInsight opartego na systemie Linux. Aby uzyskać więcej informacji, zobacz Tworzenie platformy Apache Spark w usłudze HDInsight.
Przeglądarka internetowa.
Następujące zasoby zostały użyte podczas opracowywania i testowania tego dokumentu:
Dane telemetryczne usługi Application Insights zostały wygenerowane przy użyciu aplikacji internetowej Node.js skonfigurowanej do korzystania z usługi Application Insights.
Do analizowania danych użyto platformy Spark opartej na systemie Linux w klastrze usługi HDInsight w wersji 3.5.
Architektura i planowanie
Na poniższym diagramie przedstawiono architekturę usługi w tym przykładzie:
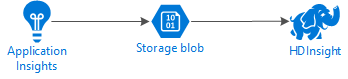
Azure Storage
Usługę Application Insights można skonfigurować do ciągłego eksportowania informacji telemetrycznych do blobów. Usługa HDInsight może następnie odczytywać dane przechowywane w plikach blob. Istnieją jednak pewne wymagania, które należy spełnić:
Lokalizacja: Jeśli konto magazynu i usługa HDInsight znajdują się w różnych lokalizacjach, może to prowadzić do zwiększenia opóźnienia. Zwiększa również koszty, ponieważ opłaty za ruch wychodzący są stosowane do danych przenoszonych między regionami.
Ostrzeżenie
Używanie konta przechowywania w innej lokalizacji niż HDInsight nie jest obsługiwane.
Typ obiektu blob: HDInsight obsługuje tylko blokowe obiekty blob. Usługa Application Insights domyślnie używa blokowych obiektów blob, więc powinna działać domyślnie z usługą HDInsight.
Aby uzyskać informacje na temat dodawania magazynu do istniejącego klastra, zobacz dokument Dodaj dodatkowe konta magazynowe.
Schemat danych
Usługa Application Insights udostępnia informacje o modelu danych eksportu dla formatu danych telemetrycznych wyeksportowanych do obiektów blob. Kroki opisane w tym dokumencie używają usługi Spark SQL do pracy z danymi. Usługa Spark SQL może automatycznie wygenerować schemat struktury danych JSON zarejestrowanej przez usługę Application Insights.
Eksportowanie danych telemetrycznych
Wykonaj kroki opisane w Konfigurowanie ciągłego eksportu, aby skonfigurować usługę Application Insights w celu wyeksportowania informacji telemetrycznych do obiektu blob usługi Azure Storage.
Konfigurowanie usługi HDInsight w celu uzyskania dostępu do danych
Jeśli tworzysz klaster usługi HDInsight, dodaj konto magazynu podczas tworzenia klastra.
Aby dodać konto Azure Storage do istniejącego klastra, skorzystaj z informacji zawartych w dokumencie Dodawanie dodatkowych kont magazynu.
Analizowanie danych: PySpark
W przeglądarce internetowej przejdź do
https://CLUSTERNAME.azurehdinsight.net/jupyter, gdzie CLUSTERNAME to nazwa twojego klastra.W prawym górnym rogu strony Jupyter wybierz Nowy, a następnie PySpark. Zostanie otwarta nowa karta przeglądarki zawierająca notes Jupyter Notebook oparty na języku Python.
W pierwszym polu (nazywanym komórką ) na stronie wprowadź następujący tekst:
sc._jsc.hadoopConfiguration().set('mapreduce.input.fileinputformat.input.dir.recursive', 'true')Ten kod konfiguruje platformę Spark, aby rekursywnie uzyskiwać dostęp do struktury katalogów dla danych wejściowych. Dane telemetryczne usługi Application Insights są rejestrowane w strukturze katalogów podobnej do .
/{telemetry type}/YYYY-MM-DD/{##}/Użyj SHIFT+ENTER , aby uruchomić kod. Po lewej stronie komórki między nawiasami pojawia się '*', aby wskazać, że kod w tej komórce jest wykonywany. Po zakończeniu tekst "*" zmieni się na liczbę, a dane wyjściowe podobne do następującego tekstu zostaną wyświetlone poniżej komórki:
Creating SparkContext as 'sc' ID YARN Application ID Kind State Spark UI Driver log Current session? 3 application_1468969497124_0001 pyspark idle Link Link ✔ Creating HiveContext as 'sqlContext' SparkContext and HiveContext created. Executing user code ...Nowa komórka jest tworzona poniżej pierwszej. Wprowadź następujący tekst w nowej komórce. Zastąp
CONTAINERnazwą konta usługi Azure Storage, aSTORAGEACCOUNTnazwą kontenera obiektów blob, który zawiera dane usługi Application Insights.%%bash hdfs dfs -ls wasbs://CONTAINER@STORAGEACCOUNT.blob.core.windows.net/Użyj SHIFT+ENTER, aby wykonać tę komórkę. Zostanie wyświetlony wynik podobny do następującego tekstu:
Found 1 items drwxrwxrwx - 0 1970-01-01 00:00 wasbs://appinsights@contosostore.blob.core.windows.net/contosoappinsights_2bededa61bc741fbdee6b556571a4831Zwrócona ścieżka Wasbs to miejsce przechowywania danych telemetrycznych usługi Application Insights.
hdfs dfs -lsZmień wiersz w komórce, aby użyć zwróconej ścieżki wasbs, a następnie użyj SHIFT+ENTER, aby ponownie uruchomić komórkę. Tym razem wyniki powinny wyświetlać katalogi zawierające dane telemetryczne.Uwaga
Dla pozostałych kroków w tej sekcji użyto katalogu
wasbs://appinsights@contosostore.blob.core.windows.net/contosoappinsights_{ID}/Requests. Struktura katalogu może być inna.W następnej komórce wprowadź następujący kod: Zastąp
WASB_PATHścieżką z poprzedniego kroku.jsonFiles = sc.textFile('WASB_PATH') jsonData = sqlContext.read.json(jsonFiles)Ten kod tworzy ramkę danych z plików JSON wyeksportowanych przez proces eksportu ciągłego. Użyj SHIFT+ENTER , aby uruchomić tę komórkę.
W następnej komórce wprowadź i uruchom następujące polecenie, aby wyświetlić schemat utworzony przez platformę Spark dla plików JSON:
jsonData.printSchema()Schemat dla każdego typu telemetrii jest inny. Poniższy przykład to schemat generowany dla żądań internetowych (dane przechowywane w podkatalogu
Requests):root |-- context: struct (nullable = true) | |-- application: struct (nullable = true) | | |-- version: string (nullable = true) | |-- custom: struct (nullable = true) | | |-- dimensions: array (nullable = true) | | | |-- element: string (containsNull = true) | | |-- metrics: array (nullable = true) | | | |-- element: string (containsNull = true) | |-- data: struct (nullable = true) | | |-- eventTime: string (nullable = true) | | |-- isSynthetic: boolean (nullable = true) | | |-- samplingRate: double (nullable = true) | | |-- syntheticSource: string (nullable = true) | |-- device: struct (nullable = true) | | |-- browser: string (nullable = true) | | |-- browserVersion: string (nullable = true) | | |-- deviceModel: string (nullable = true) | | |-- deviceName: string (nullable = true) | | |-- id: string (nullable = true) | | |-- osVersion: string (nullable = true) | | |-- type: string (nullable = true) | |-- location: struct (nullable = true) | | |-- city: string (nullable = true) | | |-- clientip: string (nullable = true) | | |-- continent: string (nullable = true) | | |-- country: string (nullable = true) | | |-- province: string (nullable = true) | |-- operation: struct (nullable = true) | | |-- name: string (nullable = true) | |-- session: struct (nullable = true) | | |-- id: string (nullable = true) | | |-- isFirst: boolean (nullable = true) | |-- user: struct (nullable = true) | | |-- anonId: string (nullable = true) | | |-- isAuthenticated: boolean (nullable = true) |-- internal: struct (nullable = true) | |-- data: struct (nullable = true) | | |-- documentVersion: string (nullable = true) | | |-- id: string (nullable = true) |-- request: array (nullable = true) | |-- element: struct (containsNull = true) | | |-- count: long (nullable = true) | | |-- durationMetric: struct (nullable = true) | | | |-- count: double (nullable = true) | | | |-- max: double (nullable = true) | | | |-- min: double (nullable = true) | | | |-- sampledValue: double (nullable = true) | | | |-- stdDev: double (nullable = true) | | | |-- value: double (nullable = true) | | |-- id: string (nullable = true) | | |-- name: string (nullable = true) | | |-- responseCode: long (nullable = true) | | |-- success: boolean (nullable = true) | | |-- url: string (nullable = true) | | |-- urlData: struct (nullable = true) | | | |-- base: string (nullable = true) | | | |-- hashTag: string (nullable = true) | | | |-- host: string (nullable = true) | | | |-- protocol: string (nullable = true)Użyj poniższych instrukcji, aby zarejestrować ramkę danych jako tabelę tymczasową i uruchomić zapytanie względem danych:
jsonData.registerTempTable("requests") df = sqlContext.sql("select context.location.city from requests where context.location.city is not null") df.show()To zapytanie zwraca informacje o mieście dla 20 najlepszych rekordów, w których parametr context.location.city nie ma wartości null.
Uwaga
Struktura kontekstu jest obecna we wszystkich danych telemetrycznych rejestrowanych przez usługę Application Insights. Element miasta może nie zostać wypełniony w dziennikach. Użyj schematu, aby zidentyfikować inne elementy, o które można pytać, które mogą zawierać dane do twoich dzienników.
To zapytanie zwraca informacje podobne do następującego tekstu:
+---------+ | city| +---------+ | Bellevue| | Redmond| | Seattle| |Charlotte| ... +---------+
Analizowanie danych: Scala
W przeglądarce internetowej przejdź do
https://CLUSTERNAME.azurehdinsight.net/jupyter, gdzie CLUSTERNAME to nazwa twojego klastra.W prawym górnym rogu strony Jupyter wybierz pozycję Nowy, a następnie scala. Zostanie wyświetlona nowa karta przeglądarki zawierająca notatnik Jupyter w języku Scala.
W pierwszym polu (nazywanym komórką ) na stronie wprowadź następujący tekst:
sc.hadoopConfiguration.set("mapreduce.input.fileinputformat.input.dir.recursive", "true")Ten kod konfiguruje platformę Spark, aby rekursywnie uzyskiwać dostęp do struktury katalogów dla danych wejściowych. Dane telemetryczne usługi Application Insights są rejestrowane w strukturze katalogów podobnej do
/{telemetry type}/YYYY-MM-DD/{##}/.Użyj SHIFT+ENTER , aby uruchomić kod. Po lewej stronie komórki między nawiasami pojawia się '*', aby wskazać, że kod w tej komórce jest wykonywany. Po zakończeniu tekst "*" zmieni się na liczbę, a dane wyjściowe podobne do następującego tekstu zostaną wyświetlone poniżej komórki:
Creating SparkContext as 'sc' ID YARN Application ID Kind State Spark UI Driver log Current session? 3 application_1468969497124_0001 spark idle Link Link ✔ Creating HiveContext as 'sqlContext' SparkContext and HiveContext created. Executing user code ...Nowa komórka jest tworzona poniżej pierwszej. Wprowadź następujący tekst w nowej komórce. Zamień
CONTAINERna nazwę konta usługi Azure Storage iSTORAGEACCOUNTna nazwę kontenera obiektów blob, które zawiera dzienniki usługi Application Insights.%%bash hdfs dfs -ls wasbs://CONTAINER@STORAGEACCOUNT.blob.core.windows.net/Użyj SHIFT+ENTER, aby wykonać tę komórkę. Zostanie wyświetlony wynik podobny do następującego tekstu:
Found 1 items drwxrwxrwx - 0 1970-01-01 00:00 wasbs://appinsights@contosostore.blob.core.windows.net/contosoappinsights_2bededa61bc741fbdee6b556571a4831Zwrócona ścieżka wasbs wskazuje lokalizację danych telemetrycznych usługi Application Insights.
hdfs dfs -lsZmień wiersz w komórce, aby użyć zwróconej ścieżki wasbs, a następnie użyj SHIFT+ENTER, aby ponownie uruchomić komórkę. Tym razem wyniki powinny wyświetlać katalogi zawierające dane telemetryczne.Uwaga
W tej sekcji do pozostałych kroków użyto katalogu
wasbs://appinsights@contosostore.blob.core.windows.net/contosoappinsights_{ID}/Requests. Ten katalog może nie istnieć, chyba że dane telemetryczne są przeznaczone dla aplikacji internetowej.W następnej komórce wprowadź następujący kod: Zastąp
WASB\_PATHścieżką z poprzedniego kroku.var jsonFiles = sc.textFile('WASB_PATH') val sqlContext = new org.apache.spark.sql.SQLContext(sc) var jsonData = sqlContext.read.json(jsonFiles)Ten kod tworzy ramkę danych z plików JSON wyeksportowanych przez proces eksportu ciągłego. Użyj SHIFT+ENTER , aby uruchomić tę komórkę.
W następnej komórce wprowadź i uruchom następujące polecenie, aby wyświetlić schemat utworzony przez platformę Spark dla plików JSON:
jsonData.printSchemaSchemat dla każdego typu telemetrii jest inny. Poniższy przykład to schemat generowany dla żądań internetowych (dane przechowywane w podkatalogu
Requests):root |-- context: struct (nullable = true) | |-- application: struct (nullable = true) | | |-- version: string (nullable = true) | |-- custom: struct (nullable = true) | | |-- dimensions: array (nullable = true) | | | |-- element: string (containsNull = true) | | |-- metrics: array (nullable = true) | | | |-- element: string (containsNull = true) | |-- data: struct (nullable = true) | | |-- eventTime: string (nullable = true) | | |-- isSynthetic: boolean (nullable = true) | | |-- samplingRate: double (nullable = true) | | |-- syntheticSource: string (nullable = true) | |-- device: struct (nullable = true) | | |-- browser: string (nullable = true) | | |-- browserVersion: string (nullable = true) | | |-- deviceModel: string (nullable = true) | | |-- deviceName: string (nullable = true) | | |-- id: string (nullable = true) | | |-- osVersion: string (nullable = true) | | |-- type: string (nullable = true) | |-- location: struct (nullable = true) | | |-- city: string (nullable = true) | | |-- clientip: string (nullable = true) | | |-- continent: string (nullable = true) | | |-- country: string (nullable = true) | | |-- province: string (nullable = true) | |-- operation: struct (nullable = true) | | |-- name: string (nullable = true) | |-- session: struct (nullable = true) | | |-- id: string (nullable = true) | | |-- isFirst: boolean (nullable = true) | |-- user: struct (nullable = true) | | |-- anonId: string (nullable = true) | | |-- isAuthenticated: boolean (nullable = true) |-- internal: struct (nullable = true) | |-- data: struct (nullable = true) | | |-- documentVersion: string (nullable = true) | | |-- id: string (nullable = true) |-- request: array (nullable = true) | |-- element: struct (containsNull = true) | | |-- count: long (nullable = true) | | |-- durationMetric: struct (nullable = true) | | | |-- count: double (nullable = true) | | | |-- max: double (nullable = true) | | | |-- min: double (nullable = true) | | | |-- sampledValue: double (nullable = true) | | | |-- stdDev: double (nullable = true) | | | |-- value: double (nullable = true) | | |-- id: string (nullable = true) | | |-- name: string (nullable = true) | | |-- responseCode: long (nullable = true) | | |-- success: boolean (nullable = true) | | |-- url: string (nullable = true) | | |-- urlData: struct (nullable = true) | | | |-- base: string (nullable = true) | | | |-- hashTag: string (nullable = true) | | | |-- host: string (nullable = true) | | | |-- protocol: string (nullable = true)Użyj poniższych instrukcji, aby zarejestrować ramkę danych jako tabelę tymczasową i uruchomić zapytanie względem danych:
jsonData.registerTempTable("requests") var city = sqlContext.sql("select context.location.city from requests where context.location.city isn't null limit 10").show()To zapytanie zwraca informacje o mieście dla 20 najlepszych rekordów, w których parametr context.location.city nie ma wartości null.
Uwaga
Struktura kontekstu jest obecna we wszystkich danych telemetrycznych rejestrowanych przez usługę Application Insights. Element miasta może nie zostać wypełniony w Twoich logach. Użyj schematu, aby zidentyfikować inne elementy, na które można wykonywać zapytania i które mogą zawierać dane dla twoich dzienników.
To zapytanie zwraca informacje podobne do następującego tekstu:
+---------+ | city| +---------+ | Bellevue| | Redmond| | Seattle| |Charlotte| ... +---------+
Następne kroki
Aby uzyskać więcej przykładów korzystania z platformy Apache Spark do pracy z danymi i usługami na platformie Azure, zobacz następujące dokumenty:
- Platforma Apache Spark z usługą BI: wykonywanie interaktywnej analizy danych przy użyciu platformy Spark w usłudze HDInsight z narzędziami analizy biznesowej
- Platforma Apache Spark z usługą Machine Learning: używanie platformy Spark w usłudze HDInsight do analizowania temperatury budynku przy użyciu danych HVAC
- Platforma Apache Spark z usługą Machine Learning: przewidywanie wyników inspekcji żywności przy użyciu platformy Spark w usłudze HDInsight
- Analiza dzienników witryn internetowych przy użyciu platformy Apache Spark w usłudze HDInsight
Aby uzyskać informacje na temat tworzenia i uruchamiania aplikacji platformy Spark, zobacz następujące dokumenty: