Uzyskiwanie dostępu do usługi Azure Data Lake Storage przy użyciu przekazywania poświadczeń identyfikatora entra firmy Microsoft (starsza wersja)
Ważne
Ta dokumentacja została wycofana i może nie zostać zaktualizowana.
Przekazywanie poświadczeń jest przestarzałe, począwszy od środowiska Databricks Runtime 15.0 i zostanie usunięte w przyszłych wersjach środowiska Databricks Runtime. Databricks zaleca uaktualnienie do Unity Catalog. Katalog Unity upraszcza zabezpieczenia i nadzór nad danymi, zapewniając centralne miejsce do administrowania i inspekcji dostępu do danych w wielu obszarach roboczych na Twoim koncie. Sprawdź temat Co to jest wykaz Unity?.
Aby uzyskać zwiększone bezpieczeństwo i poziom ładu, skontaktuj się z zespołem konta usługi Azure Databricks, aby wyłączyć przekazywanie poświadczeń na koncie usługi Azure Databricks.
Uwaga
Ten artykuł zawiera odwołania do terminu na liście dozwolonych, termin, którego usługa Azure Databricks nie używa. Po usunięciu tego terminu z oprogramowania usuniemy go również z artykułu.
Możesz uwierzytelnić się automatycznie w celu uzyskania dostępu do usługi Azure Data Lake Storage Gen1 z usług Azure Databricks (ADLS Gen1) i ADLS Gen2 z klastrów usługi Azure Databricks przy użyciu tej samej tożsamości identyfikatora Entra firmy Microsoft używanej do logowania się do usługi Azure Databricks. Po włączeniu przekazywania poświadczeń usługi Azure Data Lake Storage dla klastra polecenia uruchamiane w tym klastrze mogą odczytywać i zapisywać dane w usłudze Azure Data Lake Storage bez konieczności konfigurowania poświadczeń jednostki usługi na potrzeby dostępu do magazynu.
Przekazywanie poświadczeń w usłudze Azure Data Lake Storage jest obsługiwane tylko w przypadku usług Azure Data Lake Storage Gen1 i Gen2. Usługa Azure Blob Storage nie obsługuje przekazywania poświadczeń.
Ten artykuł dotyczy:
- Włączanie przekazywania poświadczeń dla klastrów standardowych i o wysokiej współbieżności.
- Konfigurowanie przekazywania poświadczeń i inicjowanie zasobów magazynu na kontach usługi ADLS.
- Uzyskiwanie dostępu do zasobów usługi ADLS bezpośrednio po włączeniu przekazywania poświadczeń.
- Uzyskiwanie dostępu do zasobów usługi ADLS za pośrednictwem punktu instalacji po włączeniu przekazywania poświadczeń.
- Obsługiwane funkcje i ograniczenia podczas korzystania z przekazywania poświadczeń.
Notesy są dołączone do przykładów użycia przekazywania poświadczeń z kontami magazynu usług ADLS Gen1 i ADLS Gen2.
Wymagania
- Plan Premium. Aby uzyskać szczegółowe informacje na temat podwyższania planu standardowego do planu Premium, zobacz Podwyższanie lub obniżanie planu obszaru roboczego usługi Azure Databricks.
- Konto magazynu usługi Azure Data Lake Storage Gen1 lub Gen2. Konta magazynu w usłudze Azure Data Lake Storage Gen2 muszą używać hierarchicznej przestrzeni nazw, aby działały z przekazywaniem poświadczeń w usłudze Azure Data Lake Storage. Zobacz Tworzenie konta magazynu, aby uzyskać instrukcje dotyczące tworzenia nowego konta usługi ADLS Gen2, w tym sposobu włączania hierarchicznej przestrzeni nazw.
- Prawidłowo skonfigurowane uprawnienia użytkownika do usługi Azure Data Lake Storage. Administrator usługi Azure Databricks musi upewnić się, że użytkownicy mają odpowiednie role, na przykład Współautor danych obiektu blob usługi Storage, aby odczytywać i zapisywać dane przechowywane w usłudze Azure Data Lake Storage. Zobacz Przypisywanie roli platformy Azure na potrzeby dostępu do danych obiektów blob i kolejek za pomocą witryny Azure Portal.
- Zapoznaj się z uprawnieniami administratorów obszaru roboczego w obszarach roboczych, które są włączone do przekazywania, i przejrzyj istniejące przypisania administratora obszaru roboczego. Administratorzy obszaru roboczego mogą zarządzać operacjami dla swojego obszaru roboczego, w tym dodawać użytkowników i jednostki usług, tworzyć klastry i delegować innych użytkowników jako administratorów obszaru roboczego. Zadania zarządzania obszarami roboczymi, takie jak zarządzanie własnością zadań i wyświetlanie notesów, mogą zapewnić pośredni dostęp do danych zarejestrowanych w usłudze Azure Data Lake Storage. Administrator obszaru roboczego to rola uprzywilejowana, którą należy dokładnie dystrybuować.
- Nie można użyć klastra skonfigurowanego przy użyciu poświadczeń usługi ADLS, na przykład poświadczeń jednostki usługi, z przekazywaniem poświadczeń.
Ważne
Nie można uwierzytelnić się w usłudze Azure Data Lake Storage przy użyciu poświadczeń identyfikatora Entra firmy Microsoft, jeśli znajdujesz się za zaporą, która nie została skonfigurowana do zezwalania na ruch do identyfikatora Entra firmy Microsoft. Usługa Azure Firewall domyślnie blokuje dostęp do usługi Active Directory. Aby zezwolić na dostęp, skonfiguruj tag usługi AzureActiveDirectory. Równoważne informacje dotyczące wirtualnych urządzeń sieciowych można znaleźć pod tagiem AzureActiveDirectory w pliku JSON zakresów adresów IP platformy Azure i tagów usług. Aby uzyskać więcej informacji, zobacz Tagi usługi Azure Firewall.
Zalecenia dotyczące rejestrowania
Tożsamości przekazywane do magazynu usługi ADLS można rejestrować w dziennikach diagnostycznych usługi Azure Storage. Tożsamości rejestrowania umożliwiają powiązanie żądań usługi ADLS z poszczególnymi użytkownikami z klastrów usługi Azure Databricks. Włącz rejestrowanie diagnostyczne na koncie magazynu, aby rozpocząć odbieranie następujących dzienników:
- Azure Data Lake Storage Gen1: postępuj zgodnie z instrukcjami w artykule Włączanie rejestrowania diagnostycznego dla konta usługi Data Lake Storage Gen1.
- Azure Data Lake Storage Gen2: konfigurowanie przy użyciu programu PowerShell za
Set-AzStorageServiceLoggingPropertypomocą polecenia . Określ wersję 2.0, ponieważ format wpisu dziennika 2.0 zawiera główną nazwę użytkownika w żądaniu.
Włączanie przekazywania poświadczeń usługi Azure Data Lake Storage dla klastra o wysokiej współbieżności
Klastry o wysokiej współbieżności mogą być współużytkowane przez wielu użytkowników. Obsługują tylko języki Python i SQL z przekazywaniem poświadczeń usługi Azure Data Lake Storage.
Ważne
Włączenie przekazywania poświadczeń usługi Azure Data Lake Storage dla klastra o wysokiej współbieżności blokuje wszystkie porty w klastrze z wyjątkiem portów 44, 53 i 80.
- Podczas tworzenia klastra ustaw opcję Tryb klastra na wysoką współbieżność.
- W obszarze Opcje zaawansowane wybierz pozycję Włącz przekazywanie poświadczeń dla dostępu do danych na poziomie użytkownika i zezwalaj tylko na polecenia języka Python i SQL.

Włączanie przekazywania poświadczeń usługi Azure Data Lake Storage dla klastra w warstwie Standardowa
Klastry w warstwie Standardowa z przekazywaniem poświadczeń są ograniczone do jednego użytkownika. Klastry w warstwie Standardowa obsługują języki Python, SQL, Scala i R. W środowisku Databricks Runtime 10.4 LTS i nowszym obsługiwany jest interfejs sparklyr.
Musisz przypisać użytkownika podczas tworzenia klastra, ale klaster może być edytowany przez użytkownika z uprawnieniami CAN MANAGE w dowolnym momencie, aby zastąpić oryginalnego użytkownika.
Ważne
Użytkownik przypisany do klastra musi mieć co najmniej uprawnienie CAN ATTACH TO dla klastra, aby można było uruchamiać polecenia w klastrze. Administratorzy obszaru roboczego i twórca klastra mogą zarządzać uprawnieniami, ale nie mogą uruchamiać poleceń w klastrze, chyba że są wyznaczonym użytkownikiem klastra.
- Podczas tworzenia klastra ustaw tryb klastra na Standardowa.
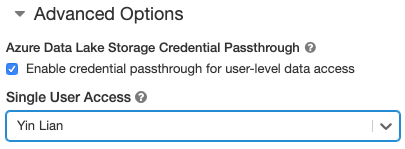
- W obszarze Opcje zaawansowane wybierz pozycję Włącz przekazywanie poświadczeń dla dostępu do danych na poziomie użytkownika i wybierz nazwę użytkownika z listy rozwijanej Dostęp do pojedynczego użytkownika.
Tworzenie kontenera
Kontenery umożliwiają organizowanie obiektów na koncie usługi Azure Storage.
Uzyskiwanie dostępu do usługi Azure Data Lake Storage bezpośrednio przy użyciu przekazywania poświadczeń
Po skonfigurowaniu przekazywania poświadczeń usługi Azure Data Lake Storage i utworzeniu kontenerów magazynu można uzyskać dostęp do danych bezpośrednio w usłudze Azure Data Lake Storage Gen1 przy użyciu ścieżki i usługi Azure Data Lake Storage Gen2 przy użyciu adl://abfss:// ścieżki.
Azure Data Lake Storage Gen1
Python
spark.read.format("csv").load("adl://<storage-account-name>.azuredatalakestore.net/MyData.csv").collect()
R
# SparkR
library(SparkR)
sparkR.session()
collect(read.df("adl://<storage-account-name>.azuredatalakestore.net/MyData.csv", source = "csv"))
# sparklyr
library(sparklyr)
sc <- spark_connect(method = "databricks")
sc %>% spark_read_csv("adl://<storage-account-name>.azuredatalakestore.net/MyData.csv") %>% sdf_collect()
- Zastąp
<storage-account-name>ciąg nazwą konta magazynu usługi ADLS Gen1.
Usługa Azure Data Lake Storage 2. generacji
Python
spark.read.format("csv").load("abfss://<container-name>@<storage-account-name>.dfs.core.windows.net/MyData.csv").collect()
R
# SparkR
library(SparkR)
sparkR.session()
collect(read.df("abfss://<container-name>@<storage-account-name>.dfs.core.windows.net/MyData.csv", source = "csv"))
# sparklyr
library(sparklyr)
sc <- spark_connect(method = "databricks")
sc %>% spark_read_csv("abfss://<container-name>@<storage-account-name>.dfs.core.windows.net/MyData.csv") %>% sdf_collect()
- Zastąp
<container-name>ciąg nazwą kontenera na koncie magazynu usługi ADLS Gen2. - Zastąp
<storage-account-name>ciąg nazwą konta magazynu usługi ADLS Gen2.
Instalowanie usługi Azure Data Lake Storage w systemie plików DBFS przy użyciu przekazywania poświadczeń
Możesz zainstalować konto usługi Azure Data Lake Storage lub folder wewnątrz niego w obszarze Co to jest system DBFS?. Instalacja wskazuje magazyn data lake, więc dane nigdy nie są synchronizowane lokalnie.
Podczas instalowania danych przy użyciu klastra z włączonym przekazywaniem poświadczeń usługi Azure Data Lake Storage wszystkie operacje odczytu lub zapisu w punkcie instalacji używają poświadczeń identyfikatora Entra firmy Microsoft. Ten punkt instalacji będzie widoczny dla innych użytkowników, ale jedynymi użytkownikami, którzy będą mieli dostęp do odczytu i zapisu, są ci, którzy:
- Mieć dostęp do bazowego konta magazynu usługi Azure Data Lake Storage
- Używasz klastra włączonego dla przekazywania poświadczeń usługi Azure Data Lake Storage
Azure Data Lake Storage Gen1
Aby zainstalować w nim zasób usługi Azure Data Lake Storage Gen1 lub folder, użyj następujących poleceń:
Python
configs = {
"fs.adl.oauth2.access.token.provider.type": "CustomAccessTokenProvider",
"fs.adl.oauth2.access.token.custom.provider": spark.conf.get("spark.databricks.passthrough.adls.tokenProviderClassName")
}
# Optionally, you can add <directory-name> to the source URI of your mount point.
dbutils.fs.mount(
source = "adl://<storage-account-name>.azuredatalakestore.net/<directory-name>",
mount_point = "/mnt/<mount-name>",
extra_configs = configs)
Scala
val configs = Map(
"fs.adl.oauth2.access.token.provider.type" -> "CustomAccessTokenProvider",
"fs.adl.oauth2.access.token.custom.provider" -> spark.conf.get("spark.databricks.passthrough.adls.tokenProviderClassName")
)
// Optionally, you can add <directory-name> to the source URI of your mount point.
dbutils.fs.mount(
source = "adl://<storage-account-name>.azuredatalakestore.net/<directory-name>",
mountPoint = "/mnt/<mount-name>",
extraConfigs = configs)
- Zastąp
<storage-account-name>ciąg nazwą konta magazynu usługi ADLS Gen2. - Zastąp
<mount-name>ciąg nazwą zamierzonego punktu instalacji w systemie plików DBFS.
Usługa Azure Data Lake Storage 2. generacji
Aby zainstalować system plików usługi Azure Data Lake Storage Gen2 lub folder w nim, użyj następujących poleceń:
Python
configs = {
"fs.azure.account.auth.type": "CustomAccessToken",
"fs.azure.account.custom.token.provider.class": spark.conf.get("spark.databricks.passthrough.adls.gen2.tokenProviderClassName")
}
# Optionally, you can add <directory-name> to the source URI of your mount point.
dbutils.fs.mount(
source = "abfss://<container-name>@<storage-account-name>.dfs.core.windows.net/",
mount_point = "/mnt/<mount-name>",
extra_configs = configs)
Scala
val configs = Map(
"fs.azure.account.auth.type" -> "CustomAccessToken",
"fs.azure.account.custom.token.provider.class" -> spark.conf.get("spark.databricks.passthrough.adls.gen2.tokenProviderClassName")
)
// Optionally, you can add <directory-name> to the source URI of your mount point.
dbutils.fs.mount(
source = "abfss://<container-name>@<storage-account-name>.dfs.core.windows.net/",
mountPoint = "/mnt/<mount-name>",
extraConfigs = configs)
- Zastąp
<container-name>ciąg nazwą kontenera na koncie magazynu usługi ADLS Gen2. - Zastąp
<storage-account-name>ciąg nazwą konta magazynu usługi ADLS Gen2. - Zastąp
<mount-name>ciąg nazwą zamierzonego punktu instalacji w systemie plików DBFS.
Ostrzeżenie
Nie należy podawać kluczy dostępu do konta magazynu ani poświadczeń jednostki usługi w celu uwierzytelnienia w punkcie instalacji. Umożliwiłoby to innym użytkownikom dostęp do systemu plików przy użyciu tych poświadczeń. Celem przekazywania poświadczeń usługi Azure Data Lake Storage jest uniemożliwienie używania tych poświadczeń i zapewnienie, że dostęp do systemu plików jest ograniczony do użytkowników, którzy mają dostęp do bazowego konta usługi Azure Data Lake Storage.
Bezpieczeństwo
Udostępnianie klastrów przekazywania poświadczeń usługi Azure Data Lake Storage innym użytkownikom jest bezpieczne. Będziesz odizolowany od siebie i nie będzie można odczytywać ani używać poświadczeń.
Obsługiwane funkcje
| Funkcja | Minimalna wersja środowiska uruchomieniowego usługi Databricks | Uwagi |
|---|---|---|
| Python i SQL | 5,5 | |
| Usługa Azure Data Lake Storage 1. generacji | 5,5 | |
%run |
5,5 | |
| DBFS | 5,5 | Poświadczenia są przekazywane tylko wtedy, gdy ścieżka systemu plików DBFS zostanie rozpoznana w lokalizacji w usłudze Azure Data Lake Storage Gen1 lub Gen2. W przypadku ścieżek systemu plików DBFS, które są rozpoznawane w innych systemach magazynowania, użyj innej metody, aby określić poświadczenia. |
| Azure Data Lake Storage Gen2 | 5,5 | |
| buforowanie dysku | 5,5 | |
| Interfejs API uczenia maszynowego PySpark | 5,5 |
Następujące klasy uczenia maszynowego nie są obsługiwane: - org/apache/spark/ml/classification/RandomForestClassifier- org/apache/spark/ml/clustering/BisectingKMeans- org/apache/spark/ml/clustering/GaussianMixture- org/spark/ml/clustering/KMeans- org/spark/ml/clustering/LDA- org/spark/ml/evaluation/ClusteringEvaluator- org/spark/ml/feature/HashingTF- org/spark/ml/feature/OneHotEncoder- org/spark/ml/feature/StopWordsRemover- org/spark/ml/feature/VectorIndexer- org/spark/ml/feature/VectorSizeHint- org/spark/ml/regression/IsotonicRegression- org/spark/ml/regression/RandomForestRegressor- org/spark/ml/util/DatasetUtils |
| Zmienne emisji | 5,5 | W programie PySpark istnieje limit rozmiaru zdefiniowanych przez użytkownika języka Python, ponieważ duże funkcje zdefiniowane przez użytkownika są wysyłane jako zmienne emisji. |
| Biblioteki o zakresie notesu | 5,5 | |
| Scala | 5,5 | |
| SparkR | 6.0 | |
| sparklyr | 10.1 | |
| Orkiestracja notatników i modularyzowanie kodu w notatnikach | 6.1 | |
| Interfejs API uczenia maszynowego PySpark | 6.1 | Obsługiwane są wszystkie klasy uczenia maszynowego PySpark. |
| Metryki klastra | 6.1 | |
| Databricks Connect | 7.3 | Przekazywanie jest obsługiwane w klastrach w warstwie Standardowa. |
Ograniczenia
Następujące funkcje nie są obsługiwane w przypadku przekazywania poświadczeń usługi Azure Data Lake Storage:
-
%fs(zamiast tego użyj równoważnego polecenia dbutils.fs ). - Zadania usługi Databricks.
- Dokumentacja interfejsu API REST usługi Databricks.
- Wykaz aparatu Unity.
-
Kontrola dostępu do tabeli. Uprawnienia przyznane przez przekazywanie poświadczeń usługi Azure Data Lake Storage mogą służyć do pomijania precyzyjnych uprawnień list ACL tabeli, podczas gdy dodatkowe ograniczenia list ACL tabeli ograniczają niektóre korzyści wynikające z przekazywania poświadczeń. Nowy rok:
- Jeśli masz uprawnienie Microsoft Entra ID do uzyskiwania dostępu do plików danych, które znajdują się pod określoną tabelą, będziesz mieć pełne uprawnienia do tej tabeli za pośrednictwem interfejsu API RDD, niezależnie od ograniczeń nakładanych na nie za pośrednictwem list ACL tabeli.
- Uprawnienia list ACL tabeli będą ograniczone tylko w przypadku korzystania z interfejsu API ramki danych. Jeśli spróbujesz odczytać pliki bezpośrednio za pomocą interfejsu API ramki danych, zostaną wyświetlone ostrzeżenia dotyczące braku uprawnień
SELECTdo żadnego pliku, nawet jeśli te pliki można odczytać bezpośrednio za pośrednictwem interfejsu API RDD. - Nie będzie można odczytać z tabel wspieranych przez systemy plików innych niż usługa Azure Data Lake Storage, nawet jeśli masz uprawnienie listy ACL tabeli do odczytywania tabel.
- Następujące metody w obiektach SparkContext (
sc) i SparkSession (spark):- Przestarzałe metody.
- Metody takie jak
addFile()iaddJar()umożliwiają użytkownikom niebędącym administratorami wywoływanie kodu Scala. - Każda metoda, która uzyskuje dostęp do systemu plików innego niż usługa Azure Data Lake Storage Gen1 lub Gen2 (aby uzyskać dostęp do innych systemów plików w klastrze z włączonym przekazywaniem poświadczeń usługi Azure Data Lake Storage, użyj innej metody, aby określić poświadczenia i wyświetlić sekcję dotyczącą zaufanych systemów plików w obszarze Rozwiązywanie problemów).
- Stare interfejsy API usługi Hadoop (
hadoopFile()ihadoopRDD()). - Interfejsy API przesyłania strumieniowego, ponieważ przekazywane poświadczenia wygasną, gdy strumień był nadal uruchomiony.
-
Instalacja systemu PLIKÓW DBFS (
/dbfs) jest dostępna tylko w środowisku Databricks Runtime 7.3 LTS i nowszym. Punkty instalacji ze skonfigurowanym przekazywaniem poświadczeń nie są obsługiwane przez tę ścieżkę. - Azure Data Factory.
- MLflow w klastrach o wysokiej współbieżności.
- pakiet azureml-sdk języka Python w klastrach o wysokiej współbieżności.
- Nie można przedłużyć okresu istnienia tokenów przekazywania identyfikatora entra firmy Microsoft przy użyciu zasad okresu istnienia tokenu identyfikatora entra firmy Microsoft. W związku z tym jeśli wyślesz polecenie do klastra, które trwa dłużej niż godzinę, nie powiedzie się, jeśli po 1 godzinie zostanie wyświetlony dostęp do zasobu usługi Azure Data Lake Storage.
- W przypadku korzystania z programu Hive 2.3 lub nowszego nie można dodać partycji w klastrze z włączonym przekazywaniem poświadczeń. Aby uzyskać więcej informacji, zobacz odpowiednią sekcję rozwiązywania problemów.
Przykładowe notesy
W poniższych notesach przedstawiono przekazywanie poświadczeń usługi Azure Data Lake Storage dla usługi Azure Data Lake Storage Gen1 i Gen2.
Notes przekazywania usługi Azure Data Lake Storage Gen1
Notes przekazywania usługi Azure Data Lake Storage Gen2
Rozwiązywanie problemów
py4j.security.Py4JSecurityException: ... nie znajduje się na liście dozwolonych
Ten wyjątek jest zgłaszany podczas uzyskiwania dostępu do metody, której usługa Azure Databricks nie oznaczyła jawnie jako bezpieczną dla klastrów usługi Azure Data Lake Storage przekazujących poświadczenia. W większości przypadków oznacza to, że ta metoda mogłaby pozwolić użytkownikowi klastra usługi Azure Data Lake Storage przekazującego poświadczenia na dostęp do poświadczeń innego użytkownika.
org.apache.spark.api.python.PythonSecurityException: Ścieżka ... używa niezaufanego systemu plików
Ten wyjątek jest zgłaszany po próbie uzyskania dostępu do systemu plików, który nie jest uznawany za bezpieczny przez klaster z przekazywaniem poświadczeń usługi Azure Data Lake Storage. Użycie niezaufanego systemu plików może umożliwić użytkownikowi w klastrze przekazywania poświadczeń usługi Azure Data Lake Storage dostęp do poświadczeń innego użytkownika, dlatego nie zezwalamy na bezpieczne używanie wszystkich systemów plików.
Aby skonfigurować zestaw zaufanych systemów plików w klastrze z przekazywaniem poświadczeń usługi Azure Data Lake Storage, ustaw klucz konfiguracji platformy Spark spark.databricks.pyspark.trustedFilesystems w tym klastrze na listę rozdzielanych przecinkami nazw klas, które są zaufanymi implementacjami elementu org.apache.hadoop.fs.FileSystem.
Dodawanie partycji kończy się niepowodzeniem z AzureCredentialNotFoundException powodu włączenia przekazywania poświadczeń
W przypadku korzystania z programu Hive 2.3-3.1 próba dodania partycji w klastrze z włączonym przekazywaniem poświadczeń spowoduje wystąpienie następującego wyjątku:
org.apache.spark.sql.AnalysisException: org.apache.hadoop.hive.ql.metadata.HiveException: MetaException(message:com.databricks.backend.daemon.data.client.adl.AzureCredentialNotFoundException: Could not find ADLS Gen2 Token
Aby obejść ten problem, dodaj partycje w klastrze bez włączonego przekazywania poświadczeń.