Organizowanie notesów i modularyzowanie kodu w notesach
Dowiedz się, jak organizować notesy i modularyzować kod w notesach. Zobacz przykłady i dowiedz się, kiedy używać alternatywnych metod aranżacji notesu.
Metody modularyzacji orkiestracji i kodu
W poniższej tabeli porównaliśmy metody dostępne do organizowania notesów i modułyzacji kodu w notesach.
| Metoda | Przypadek użycia | Notatki |
|---|---|---|
| zadania usługi Databricks | Orkiestracja notatnika (zalecane) | Zalecana metoda organizowania notesów. Obsługuje złożone przepływy pracy z zależnościami zadań, planowaniem i wyzwalaczami. Zapewnia niezawodne i skalowalne podejście do obciążeń produkcyjnych, ale wymaga ustawień i konfiguracji. |
| dbutils.notebook.run() | Aranżacja notesu | Użyj dbutils.notebook.run(), jeśli Jobs nie obsługuje twojego przypadku użycia, na przykład zapętlania notebooków w dynamicznym zestawie parametrów.Uruchamia nowe, tymczasowe zadanie przy każdym wywołaniu, co może zwiększyć obciążenie wydajnościowe i nie zapewnia zaawansowanych funkcji harmonogramowania. |
| pliki obszaru roboczego | Modułyzacja kodu (zalecane) | Zalecana metoda modułyzacji kodu. Modularyzowanie kodu w plikach kodu wielokrotnego użytku przechowywanych w obszarze roboczym. Obsługuje kontrolę wersji z repozytoriami i integracją z środowiskami IDE w celu lepszego debugowania i testowania jednostkowego. Wymaga dodatkowej konfiguracji do zarządzania ścieżkami plików i zależnościami. |
| %run | Modułyzacja kodu | Użyj %run, jeśli nie możesz uzyskać dostępu do plików obszaru roboczego.Po prostu zaimportuj funkcje lub zmienne z innych notebooków, wykonując je w tym samym miejscu. Przydatne do tworzenia prototypów, ale może prowadzić do ściśle powiązanego kodu, który jest trudniejszy do utrzymania. Nie obsługuje przekazywania parametrów ani kontroli wersji. |
%run a dbutils.notebook.run()
Polecenie %run umożliwia dołączenie innego notesu do notesu. Za pomocą %run można modularyzować kod, umieszczając funkcje pomocnicze w osobnym notesie. Można go również użyć do łączenia notesów, które implementują kroki w analizie. Gdy używasz %runmetody , wywoływany notes jest natychmiast wykonywany, a funkcje i zmienne zdefiniowane w nim stają się dostępne w notesie wywołującym.
Interfejs API dbutils.notebook uzupełnia %run, ponieważ umożliwia przekazywanie parametrów do i zwracanie wartości z notesu. Dzięki temu można tworzyć złożone przepływy pracy i potoki z zależnościami. Można na przykład uzyskać listę plików w katalogu i przekazać nazwy do innego notesu, co jest niemożliwe w przypadku %run. Możesz również utworzyć przepływy pracy if-then-else na podstawie wartości zwracanych.
%run W przeciwieństwie do dbutils.notebook.run()metody metoda uruchamia nowe zadanie uruchamiania notesu.
Podobnie jak wszystkie interfejsy API dbutils, te metody są dostępne tylko w językach Python i Scala. Można jednak użyć dbutils.notebook.run() polecenia , aby wywołać notes języka R.
Użyj %run polecenia , aby zaimportować notes
W tym przykładzie pierwszy notes definiuje funkcję , reversektóra jest dostępna w drugim notesie po użyciu %run funkcji magic do wykonania shared-code-notebook.
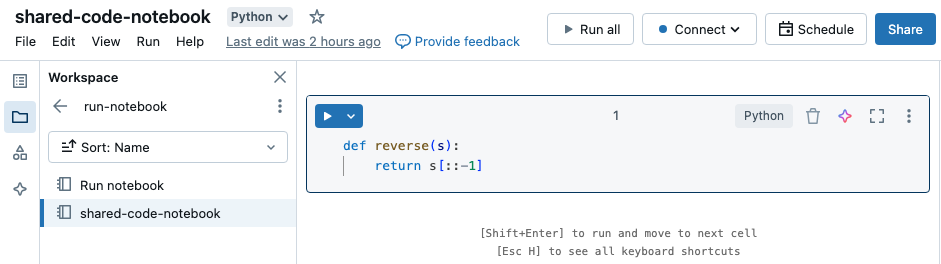
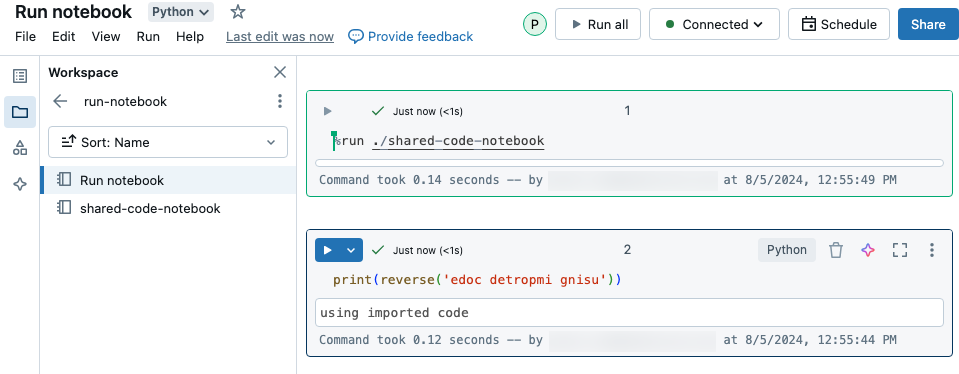
Ponieważ oba notesy znajdują się w tym samym katalogu w obszarze roboczym, użyj prefiksu ./ w ./shared-code-notebook, aby wskazać, że ścieżka powinna zostać rozpoznana względem aktualnie uruchomionego notesu. Notesy można organizować w katalogach, takich jak , lub używać ścieżki bezwzględnej, takiej jak %run ./dir/notebook%run /Users/username@organization.com/directory/notebook.
Uwaga
-
%runmusi znajdować się w komórce, ponieważ uruchamia cały notes w tekście. - Nie można użyć
%runpolecenia , aby uruchomić plik języka Python iimportjednostki zdefiniowane w tym pliku w notesie. Aby zaimportować z pliku w języku Python, zobacz Modularyzowanie kodu przy użyciu plików. Możesz też spakować plik do biblioteki języka Python, utworzyć bibliotekę usługi Azure Databricks z tej biblioteki języka Python i zainstalować bibliotekę w klastrze używanym do uruchamiania notesu. - Jeśli używasz
%rundo uruchamiania notesu zawierającego widżety, domyślnie określony notes jest uruchamiany z wartościami domyślnymi widżetu. Można również przekazywać wartości do widgetów; zobacz Użycie widgetów usługi Databricks z %run.
Użyj dbutils.notebook.run, aby uruchomić nowe zadanie
Uruchom notes i zwróć jego wartość zakończenia. Metoda uruchamia efemeryczne zadanie, które jest uruchamiane natychmiast.
Metody dostępne w interfejsie dbutils.notebook API to run i exit. Zarówno parametry, jak i wartości zwracane muszą być ciągami.
run(path: String, timeout_seconds: int, arguments: Map): String
Parametr timeout_seconds kontroluje limit czasu przebiegu (0 oznacza brak limitu czasu). Wywołanie metody run zgłasza wyjątek, jeśli nie zostanie zakończone w określonym czasie. Jeśli usługa Azure Databricks nie działa przez ponad 10 minut, uruchomienie notesu kończy się niepowodzeniem niezależnie od timeout_seconds.
Parametr arguments ustawia wartości widżetu notesu docelowego. W szczególności jeśli uruchomiony notes ma widżet o nazwie Ai przekazujesz parę ("A": "B") klucz-wartość jako część parametru run() argumentów do wywołania, pobieranie wartości widżetu A zwróci wartość "B". Instrukcje dotyczące tworzenia widżetów i pracy z nimi można znaleźć w artykule Dotyczącym widżetów usługi Databricks.
Uwaga
- Parametr
argumentsakceptuje tylko znaki łacińskie (zestaw znaków ASCII). Użycie znaków innych niż ASCII zwraca błąd. - Zadania utworzone przy użyciu interfejsu
dbutils.notebookAPI muszą zostać ukończone w ciągu 30 dni lub mniej.
run Zwyczaj
Python
dbutils.notebook.run("notebook-name", 60, {"argument": "data", "argument2": "data2", ...})
Scala
dbutils.notebook.run("notebook-name", 60, Map("argument" -> "data", "argument2" -> "data2", ...))
Przekazywanie danych ustrukturyzowanych między notatnikami
W tej sekcji pokazano, jak przekazywać dane ustrukturyzowane między notesami.
Python
# Example 1 - returning data through temporary views.
# You can only return one string using dbutils.notebook.exit(), but since called notebooks reside in the same JVM, you can
# return a name referencing data stored in a temporary view.
## In callee notebook
spark.range(5).toDF("value").createOrReplaceGlobalTempView("my_data")
dbutils.notebook.exit("my_data")
## In caller notebook
returned_table = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
global_temp_db = spark.conf.get("spark.sql.globalTempDatabase")
display(table(global_temp_db + "." + returned_table))
# Example 2 - returning data through DBFS.
# For larger datasets, you can write the results to DBFS and then return the DBFS path of the stored data.
## In callee notebook
dbutils.fs.rm("/tmp/results/my_data", recurse=True)
spark.range(5).toDF("value").write.format("parquet").save("dbfs:/tmp/results/my_data")
dbutils.notebook.exit("dbfs:/tmp/results/my_data")
## In caller notebook
returned_table = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
display(spark.read.format("parquet").load(returned_table))
# Example 3 - returning JSON data.
# To return multiple values, you can use standard JSON libraries to serialize and deserialize results.
## In callee notebook
import json
dbutils.notebook.exit(json.dumps({
"status": "OK",
"table": "my_data"
}))
## In caller notebook
import json
result = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
print(json.loads(result))
Scala
// Example 1 - returning data through temporary views.
// You can only return one string using dbutils.notebook.exit(), but since called notebooks reside in the same JVM, you can
// return a name referencing data stored in a temporary view.
/** In callee notebook */
sc.parallelize(1 to 5).toDF().createOrReplaceGlobalTempView("my_data")
dbutils.notebook.exit("my_data")
/** In caller notebook */
val returned_table = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
val global_temp_db = spark.conf.get("spark.sql.globalTempDatabase")
display(table(global_temp_db + "." + returned_table))
// Example 2 - returning data through DBFS.
// For larger datasets, you can write the results to DBFS and then return the DBFS path of the stored data.
/** In callee notebook */
dbutils.fs.rm("/tmp/results/my_data", recurse=true)
sc.parallelize(1 to 5).toDF().write.format("parquet").save("dbfs:/tmp/results/my_data")
dbutils.notebook.exit("dbfs:/tmp/results/my_data")
/** In caller notebook */
val returned_table = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
display(sqlContext.read.format("parquet").load(returned_table))
// Example 3 - returning JSON data.
// To return multiple values, use standard JSON libraries to serialize and deserialize results.
/** In callee notebook */
// Import jackson json libraries
import com.fasterxml.jackson.module.scala.DefaultScalaModule
import com.fasterxml.jackson.module.scala.experimental.ScalaObjectMapper
import com.fasterxml.jackson.databind.ObjectMapper
// Create a json serializer
val jsonMapper = new ObjectMapper with ScalaObjectMapper
jsonMapper.registerModule(DefaultScalaModule)
// Exit with json
dbutils.notebook.exit(jsonMapper.writeValueAsString(Map("status" -> "OK", "table" -> "my_data")))
/** In caller notebook */
// Import jackson json libraries
import com.fasterxml.jackson.module.scala.DefaultScalaModule
import com.fasterxml.jackson.module.scala.experimental.ScalaObjectMapper
import com.fasterxml.jackson.databind.ObjectMapper
// Create a json serializer
val jsonMapper = new ObjectMapper with ScalaObjectMapper
jsonMapper.registerModule(DefaultScalaModule)
val result = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
println(jsonMapper.readValue[Map[String, String]](result))
Obsługa błędów
W tej sekcji pokazano, jak obsługiwać błędy.
Python
# Errors throw a WorkflowException.
def run_with_retry(notebook, timeout, args = {}, max_retries = 3):
num_retries = 0
while True:
try:
return dbutils.notebook.run(notebook, timeout, args)
except Exception as e:
if num_retries > max_retries:
raise e
else:
print("Retrying error", e)
num_retries += 1
run_with_retry("LOCATION_OF_CALLEE_NOTEBOOK", 60, max_retries = 5)
Scala
// Errors throw a WorkflowException.
import com.databricks.WorkflowException
// Since dbutils.notebook.run() is just a function call, you can retry failures using standard Scala try-catch
// control flow. Here, we show an example of retrying a notebook a number of times.
def runRetry(notebook: String, timeout: Int, args: Map[String, String] = Map.empty, maxTries: Int = 3): String = {
var numTries = 0
while (true) {
try {
return dbutils.notebook.run(notebook, timeout, args)
} catch {
case e: WorkflowException if numTries < maxTries =>
println("Error, retrying: " + e)
}
numTries += 1
}
"" // not reached
}
runRetry("LOCATION_OF_CALLEE_NOTEBOOK", timeout = 60, maxTries = 5)
Współbieżne uruchamianie wielu notesów
Jednocześnie można uruchamiać wiele notesów przy użyciu standardowych konstrukcji Języka Scala i Python, takich jak Threads (Scala, Python) i Futures (Scala, Python). W przykładowych notesach pokazano, jak używać tych konstrukcji.
- Pobierz następujące cztery zeszyty. Notesy są napisane w języku Scala.
- Zaimportuj notesy do jednego folderu w obszarze roboczym.
- Uruchom notes Uruchom współbieżnie.
Uruchamianie notesu współbieżnego
Pobierz notatnik
Uruchamianie w notesie równoległym
Pobierz notatnik
Notes testowania
Pobierz notatnik
Notes Testing-2
Pobierz notatnik