Prognozowanie (bezserwerowe) przy użyciu rozwiązania AutoML
W tym artykule pokazano, jak uruchomić bezserwerowy eksperyment prognozowania przy użyciu interfejsu użytkownika do trenowania modelu Mosaic AI.
Trenowanie modelu mozaiki sztucznej inteligencji — prognozowanie upraszcza prognozowanie danych szeregów czasowych przez automatyczne wybranie najlepszego algorytmu i hiperparametrów, a wszystko to przy jednoczesnym uruchomieniu w pełni zarządzanych zasobów obliczeniowych.
Aby zrozumieć różnicę między prognozowanie bezserwerowe i klasyczne prognozowanie obliczeń, zobacz Prognozowanie bezserwerowe a klasyczne prognozowanie obliczeń.
Wymagania
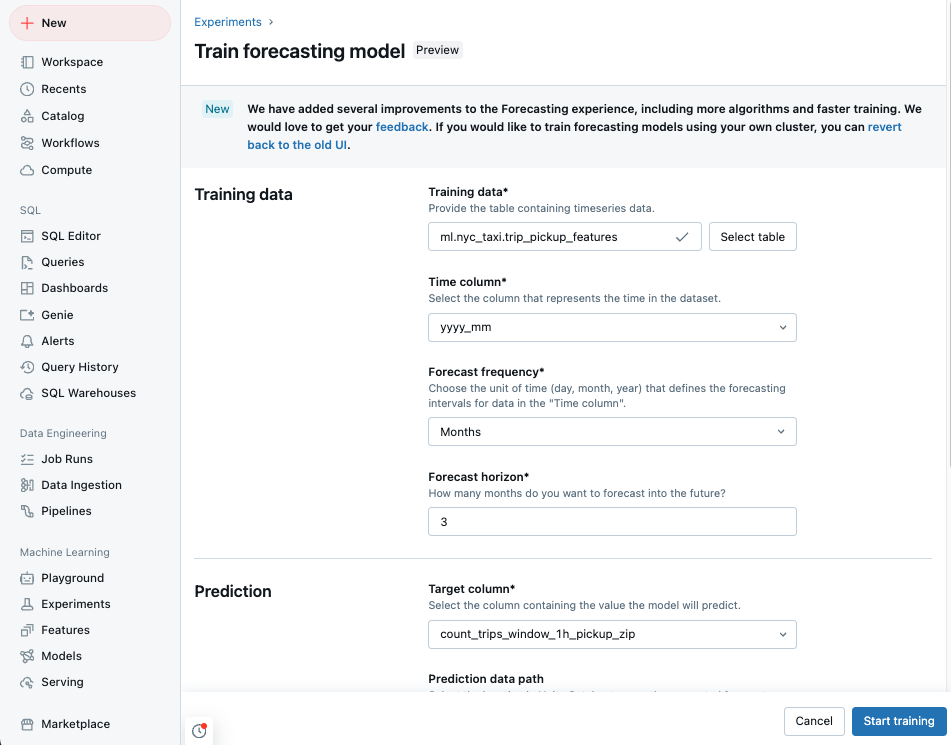
Dane szkoleniowe z szeregami czasowymi column, zapisane jako Catalogtablew Unity.
Jeśli obszar roboczy ma włączoną usługę Secure Egress Gateway (SEG), do dozwolonych domen należy dodać
pypi.orglist. Zobacz Zarządzanie politykami sieciowymi w celu bezserwerowej kontroli ruchu wychodzącego.
Tworzenie eksperymentu prognozowania za pomocą interfejsu użytkownika
Przejdź do strony docelowej usługi Azure Databricks i kliknij pozycję Eksperymenty na pasku bocznym.
Na kafelku prognozowania
Rozpocznij szkolenie .danych trenowania z aparatu Unity, do którego można uzyskać dostęp. -
czas column: Selectcolumn zawierające okresy szeregów czasowych.
columns musi być typu
timestamplubdate. - częstotliwość prognozowania: Select jednostkę czasu reprezentującą częstotliwość danych wejściowych. Na przykład minuty, godziny, dni, miesiące. Określa stopień szczegółowości szeregów czasowych.
- horyzont prognozy: określ liczbę jednostek wybranej częstotliwości do prognozowania w przyszłości. Wraz z częstotliwością prognozy definiuje to zarówno jednostki czasu, jak i liczbę jednostek czasu, które mają być prognozowane.
Notatka
Aby użyć algorytmu auto-ARIMA
, szereg czasowy musi mieć regularną częstotliwość, interwał między dwoma punktami musi być taki sam w ciągu szeregu czasowego. Rozwiązanie AutoML obsługuje brakujące kroki czasu, wypełniając te values przy użyciu poprzedniej wartości. -
czas column: Selectcolumn zawierające okresy szeregów czasowych.
columns musi być typu
Select celu przewidywania column, które mają być przewidywane przez model.
Opcjonalnie określ ścieżkę danych predykcji Unity Catalogtable do przechowywania prognoz wyjściowych.
Select rejestracja modelu Unity Catalog lokalizacja i nazwa.
Opcjonalnie setopcje zaawansowane:
- nazwa eksperymentu: podaj nazwę eksperymentu MLflow.
- identifier columns szeregi czasowe — w przypadku prognozowania wielu serii selectcolumn(s) które identyfikują indywidualne szeregi czasowe. Usługa Databricks grupuje dane według tych columns jako różne szeregi czasowe i trenuje model dla każdej serii niezależnie.
- podstawowa metryka: wybierz podstawową metrykę używaną do oceny i select najlepszego modelu.
- struktura szkoleniowa: Wybierz struktury do eksploracji AutoML.
- Split column: Selectcolumn zawierające podział danych niestandardowych. Values musi być "szkolenie", "walidacja", "test"
- waga column: określ column do ważenia serii czasowej. Wszystkie próbki dla danej serii czasowej muszą mieć taką samą wagę. Waga musi znajdować się w zakresie [0, 10000].
- region wakacyjny: Select region wakacyjny, który ma być używany jako kowariata przy trenowaniu modelu.
- limit czasu: Set maksymalny czas trwania eksperymentu automatycznego uczenia maszynowego.
Uruchamianie eksperymentu i monitorowanie wyników
Aby rozpocząć eksperyment zautomatyzowanego uczenia maszynowego, kliknij przycisk Rozpocznij szkolenie. Na stronie szkoleniowej eksperymentu można wykonać następujące czynności:
- Zatrzymaj eksperyment w dowolnym momencie.
- Monitorowanie uruchomień.
- Przejdź do strony uruchomienia dla dowolnej sesji.
Wyświetlanie wyników lub używanie najlepszego modelu
Po zakończeniu trenowania wyniki przewidywania są przechowywane w określonym Delta table, a najlepszy model jest zarejestrowany w Unity Catalog.
Na stronie Eksperymenty wybierz jedną z następujących następnych czynności:
- Select Wyświetl przewidywania, aby zobaczyć wyniki prognozowania table.
- Select Notatnik wnioskowania wsadowego, aby otworzyć automatycznie generowany notatnik do wnioskowania wsadowego przy użyciu najlepszego modelu.
- Select Tworzenie punktu końcowego obsługującego w celu wdrożenia najlepszego modelu w punkcie końcowym obsługującym model.
prognozowanie bezserwerowe a prognozowanie przy użyciu klasycznych obliczeń
Poniższe table podsumowuje różnice między prognozowaniem bezserwerowym a prognozowaniem przy użyciu klasycznej obliczeniowej
| Funkcja | Prognozowanie bezserwerowe | Klasyczne prognozowanie zasobów obliczeniowych |
|---|---|---|
| Infrastruktura obliczeniowa | Usługa Azure Databricks zarządza konfiguracją obliczeniową i automatycznie optymalizuje pod kątem kosztów i wydajności. | Obliczenia skonfigurowane przez użytkownika |
| Rządzenie | Modele i artefakty zarejestrowane w usłudze Unity Catalog | Magazyn plików obszaru roboczego skonfigurowany przez użytkownika |
| Wybór algorytmu | modele statystyczne oraz algorytm sieci neuronowej uczenia głębokiego DeepAR | modele statystyczne |
| Integracja magazynu funkcji | Niewspierane | Obsługiwane |
| Notesy generowane automatycznie | Notatnik wnioskowania wsadowego | Kod źródłowy dla wszystkich wersji próbnych |
| Wdrażanie obsługi modelu jednym kliknięciem | Obsługiwane | Nieobsługiwane |
| Niestandardowe podziały trenowania/walidacji/testowania | Obsługiwane | Niewspierane |
| Własne wagi dla poszczególnych szeregów czasowych | Obsługiwane | Niewspierane |