Zarządzanie zasadami sieci na potrzeby kontroli ruchu wychodzącego bezserwerowego
Ważne
Ta funkcja jest dostępna w publicznej wersji zapoznawczej.
W tym dokumencie wyjaśniono, jak skonfigurować zasady sieci i zarządzać nimi w celu kontrolowania wychodzących połączeń sieciowych z obciążeń bezserwerowych w usłudze Azure Databricks.
Uprawnienia do zarządzania zasadami sieciowymi są ograniczone do administratora konta. Zobacz Wprowadzenie do administrowania usługą Azure Databricks.
Uzyskiwanie dostępu do zasad sieci
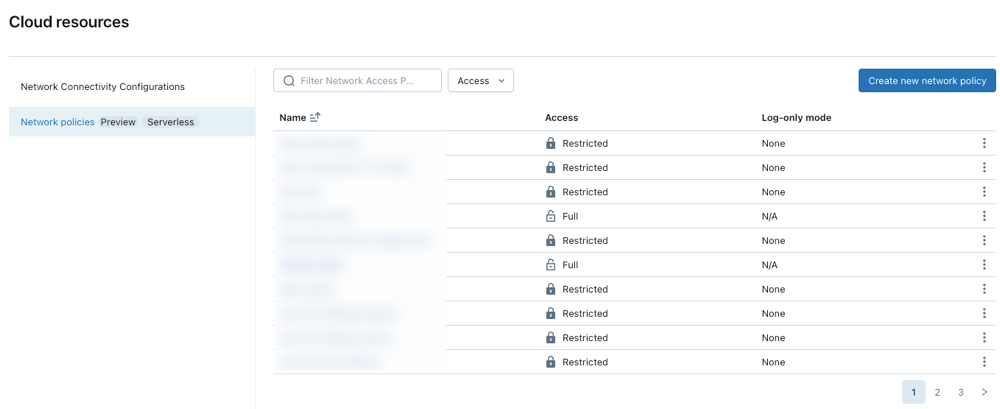
Aby utworzyć, wyświetlić i zaktualizować zasady sieciowe na koncie:
- W konsoli konta kliknij pozycję Zasoby w chmurze.
- Kliknij kartę Sieć .
Tworzenie nowych zasad sieciowych
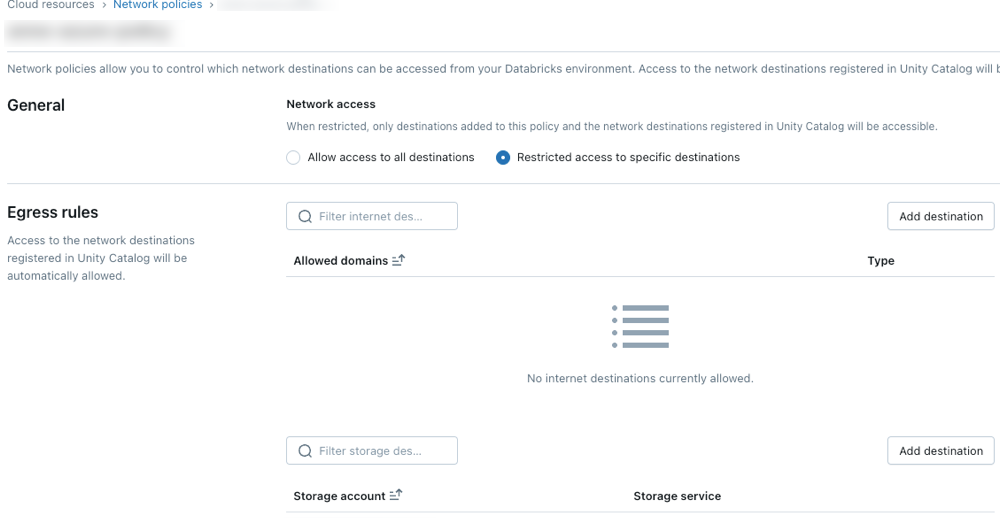
Kliknij Utwórz nowe zasady sieciowe.
Wybierz tryb dostępu do sieci:
- pełny dostęp: nieograniczony wychodzący dostęp do Internetu. Jeśli wybierzesz opcję Pełny dostęp, dostęp wychodzący do Internetu pozostanie nieograniczony.
- ograniczony dostęp: dostęp wychodzący jest ograniczony do określonych miejsc docelowych. Aby uzyskać więcej informacji, zobacz Omówienie zasad sieciowych.
Konfigurowanie zasad sieci
W poniższych krokach opisano opcjonalne ustawienia trybu dostępu z ograniczeniami.
Zasady ruchu wychodzącego
Miejsca docelowe skonfigurowane za pośrednictwem lokalizacji lub połączeń Unity Catalog są automatycznie dozwolone przez politykę.
Aby przyznać dostęp obliczeniowy bez serwera do jeszcze innych domen, kliknij Dodaj miejsce docelowe powyżej listy dozwolone domeny.
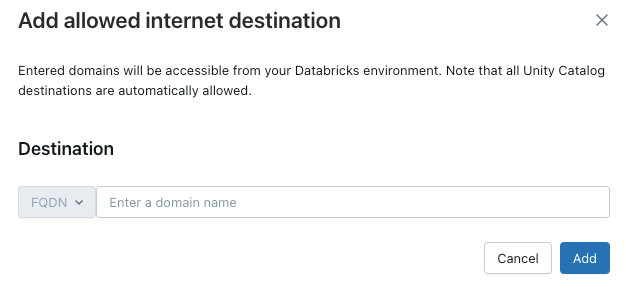
Filtr FQDN umożliwia dostęp do wszystkich domen, które współużytkujące ten sam adres IP. Obsługa modelu aprowizowana w punktach końcowych uniemożliwia dostęp do Internetu, gdy dostęp do sieci jest ustawiony na ograniczony. Jednak szczegółowa kontrolka z filtrowaniem nazw FQDN nie jest obsługiwana.
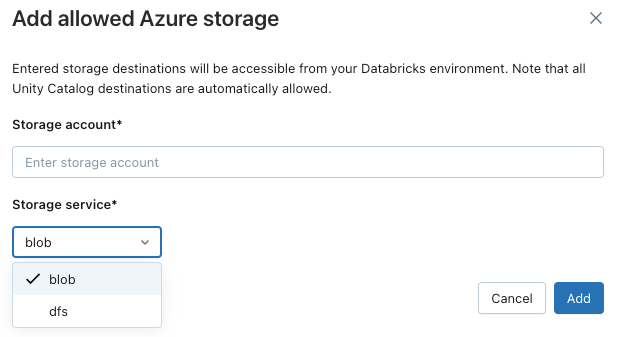
Aby zezwolić obszarowi roboczemu na dostęp do dodatkowych kont usługi Azure Storage, kliknij przycisk Dodaj miejsce docelowe nad listą Dozwolone konta magazynu.
Uwaga
Maksymalna liczba obsługiwanych miejsc docelowych to 2000. Obejmuje to wszystkie lokalizacje i połączenia Unity Catalog dostępne w obszarze roboczym, a także miejsca docelowe jawnie dodane do zasad.
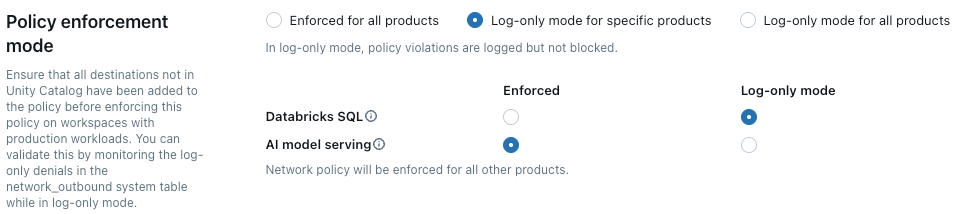
Wymuszanie zasad
Tryb tylko do rejestrowania umożliwia testowanie konfiguracji zasad i monitorowanie połączeń wychodzących bez zakłócania dostępu do zasobów. Po włączeniu trybu tylko dziennika żądania naruszające zasady są rejestrowane, ale nie są blokowane. Dostępne są następujące opcje:
Databricks SQL: Magazyny Databricks SQL działają w trybie wyłącznie do logowania.
modelu sztucznej inteligencji obsługującego: punkty końcowe obsługujące model działają w trybie tylko do logowania.
Wszystkie produkty: Wszystkie usługi Azure Databricks działają w trybie wyłącznie do logowania, zastępując wszystkie inne opcje.
Aktualizowanie zasad domyślnych
Każde konto usługi Azure Databricks zawiera domyślne zasady. Domyślne zasady są skojarzone ze wszystkimi obszarami roboczymi bez jawnego przypisania zasad sieciowych, w tym nowo utworzonych obszarów roboczych. Te zasady można modyfikować, ale nie można ich usunąć. Domyślne zasady są stosowane tylko do obszarów roboczych z co najmniej warstwą Premium.
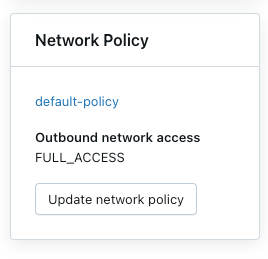
Kojarzenie zasad sieciowych z obszarami roboczymi
Jeśli zasady domyślne zostały zaktualizowane przy użyciu dodatkowych konfiguracji, są one automatycznie stosowane do obszarów roboczych, które nie mają istniejących zasad sieciowych. Twoja przestrzeń robocza musi być w warstwie Premium.
Aby skojarzyć obszar roboczy z innymi zasadami, wykonaj następujące czynności:
- Wybieranie obszaru roboczego.
- W zasadach sieciowychkliknij Aktualizuj zasady sieciowe.
- Wybierz odpowiednie zasady sieciowe z listy.
Stosowanie zmian zasad sieciowych
Większość aktualizacji konfiguracji sieci jest automatycznie propagowana do bezserwerowego środowiska obliczeniowego w ciągu dziesięciu minut. Obejmuje to:
- Dodawanie nowej lokalizacji zewnętrznej lub połączenia wykazu aparatu Unity.
- Dołączanie obszaru roboczego do innego magazynu metadanych.
- Zmiana dozwolonych miejsc docelowych magazynu lub Internetu.
Uwaga
Należy ponownie uruchomić obliczenia, jeśli zmodyfikujesz ustawienie trybu dostępu do Internetu lub trybu tylko do rejestrowania.
Ponowne uruchamianie lub ponowne wdrażanie obciążeń bezserwerowych
Należy zaktualizować tylko podczas przełączania trybu dostępu do Internetu lub aktualizowania trybu tylko dziennika.
Aby określić odpowiednią procedurę ponownego uruchamiania, zapoznaj się z następującą listą według produktu:
- Obsługa uczenia maszynowego w usłudze Databricks: ponowne wdrażanie punktu końcowego obsługującego uczenie maszynowe. Zobacz Tworzenie niestandardowych punktów końcowych obsługujących model
- Delta Live Tables: Zatrzymaj, a następnie uruchom ponownie uruchomiony potok Delta Live Tables. Zobacz Run an update on a Delta Live Tables pipeline (Uruchamianie aktualizacji potoku tabel na żywo funkcji Delta).
- Serverless SQL Warehouse: Zatrzymaj oraz uruchom ponownie Serverless SQL Warehouse. Zobacz Zarządzanie usługą SQL Warehouse.
- Przepływy pracy: zmiany zasad sieciowych są automatycznie stosowane po wyzwoleniu nowego uruchomienia zadania lub ponownym uruchomieniu istniejącego zadania.
-
Notesy:
- Jeśli notes nie współdziała z platformą Spark, możesz zakończyć działanie i dołączyć nowy klaster bezserwerowy, aby odświeżyć konfigurację sieci zastosowaną do notesu.
- Jeśli notes współdziała z platformą Spark, zasób bezserwerowy odświeża się i automatycznie wykrywa zmianę. Przełączenie trybu dostępu i trybu tylko do dziennika może potrwać do 24 godzin, a zastosowanie innych zmian może potrwać do 10 minut.
Weryfikowanie wymuszania zasad sieciowych
Możesz sprawdzić, czy zasady sieciowe są prawidłowo wymuszane, próbując uzyskać dostęp do ograniczonych zasobów z różnych obciążeń bezserwerowych. Proces weryfikacji różni się w zależności od produktu bezserwerowego.
Weryfikowanie przy użyciu tabel delta live
- Tworzenie notesu języka Python. Możesz użyć przykładowego notesu udostępnionego w samouczku języka Python w witrynie Delta Live Tables.
- Utwórz potok delty tabel na żywo:
- Kliknij pozycję Pipelinesw obszarze Data Engineeringna pasku bocznym obszaru roboczego.
- Kliknij pozycję Utwórz potok.
- Skonfiguruj potok przy użyciu następujących ustawień:
- Tryb potoku: bezserwerowy
- Kod źródłowy: wybierz utworzony notes.
- Opcje magazynu: Wykaz aparatu Unity. Wybierz żądany wykaz i schemat.
- Kliknij pozycję Utwórz.
- Uruchom potok Delta Live Tables.
- Na stronie potoku kliknij przycisk Start.
- Poczekaj na zakończenie potoku.
- Weryfikowanie wyników
- Zaufane miejsce docelowe: potok powinien zostać uruchomiony pomyślnie i zapisać dane w miejscu docelowym.
- Niezaufane miejsce docelowe: potok powinien zakończyć się niepowodzeniem z błędami wskazującymi, że dostęp do sieci jest zablokowany.
Weryfikowanie przy użyciu usługi Databricks SQL
- Utwórz usługę SQL Warehouse. Aby uzyskać instrukcje, zobacz Tworzenie usługi SQL Warehouse.
- Uruchom zapytanie testowe w edytorze SQL, które próbuje uzyskać dostęp do zasobu kontrolowanego przez zasady sieciowe.
- Sprawdź wyniki:
- Zaufane miejsce docelowe: zapytanie powinno zakończyć się powodzeniem.
- Niezaufane miejsce docelowe: zapytanie powinno zakończyć się niepowodzeniem z powodu błędu dostępu do sieci.
Weryfikowanie przy użyciu obsługi modelu
Tworzenie modelu testowego
- W notesie języka Python utwórz model, który próbuje uzyskać dostęp do publicznego zasobu internetowego, na przykład pobranie pliku lub utworzenie żądania interfejsu API.
- Uruchom ten notes, aby wygenerować model w obszarze roboczym testowym. Na przykład:
import mlflow import mlflow.pyfunc import mlflow.sklearn import requests class DummyModel(mlflow.pyfunc.PythonModel): def load_context(self, context): pass def predict(self, _, model_input): first_row = model_input.iloc[0] try: response = requests.get(first_row['host']) except requests.exceptions.RequestException as e: # Return the error details as text return f"Error: An error occurred - {e}" return [response.status_code] with mlflow.start_run(run_name='internet-access-model'): wrappedModel = DummyModel() mlflow.pyfunc.log_model(artifact_path="internet_access_ml_model", python_model=wrappedModel, registered_model_name="internet-http-access")Tworzenie punktu końcowego obsługującego
- W obszarze nawigacyjnym obszaru roboczego wybierz pozycję Machine Learning.
- Kliknij kartę Obsługa.
- Kliknij pozycję Utwórz punkt końcowy obsługujący.
- Skonfiguruj punkt końcowy przy użyciu następujących ustawień:
- Nazwa punktu końcowego obsługi: podaj opisową nazwę.
- Szczegóły jednostki: wybierz pozycję Model rejestru.
- Model: wybierz model utworzony w poprzednim kroku.
- Kliknij przycisk Potwierdź.
- Poczekaj, aż punkt końcowy obsługujący osiągnie stan Gotowe .
Wykonaj zapytanie dotyczące punktu końcowego.
- Użyj opcji Punkt końcowy zapytania na stronie obsługującego punkt końcowy, aby wysłać żądanie testowe.
{"dataframe_records": [{"host": "https://www.google.com"}]}Sprawdź wynik:
- Włączony dostęp do Internetu: zapytanie powinno zakończyć się powodzeniem.
- Ograniczony dostęp do Internetu: zapytanie powinno zakończyć się niepowodzeniem z powodu błędu dostępu do sieci.
Aktualizowanie zasad sieciowych
Zasady sieciowe można zaktualizować w dowolnym momencie po jego utworzeniu. Aby zaktualizować zasady sieciowe:
- Na stronie szczegółów zasad sieciowych w konsoli kont zmodyfikuj zasady:
- Zmień tryb dostępu do sieci.
- Włącz lub wyłącz tryb tylko logowania dla określonych usług.
- Dodawanie lub usuwanie nazw FQDN lub miejsc docelowych magazynu.
- Kliknij Aktualizuj.
- Zapoznaj się z Zastosowanie zmian zasad sieciowych, aby upewnić się, że aktualizacje zostały zastosowane do istniejących obciążeń.
Sprawdzanie dzienników odmowy
Dzienniki odmowy są przechowywane w tabeli w wykazie system.access.outbound_network aparatu Unity. Te dzienniki śledzą, kiedy żądania sieci wychodzące są odrzucane. Aby uzyskać dostęp do dzienników odmowy, upewnij się, że schemat dostępu jest włączony w magazynie metadanych wykazu aparatu Unity. Zobacz Włączanie schematów tabeli systemowej.
Użyj zapytania SQL, takiego jak poniższe, aby wyświetlić zdarzenia odmowy. Jeśli dzienniki tylko do dziennika są włączone, zapytanie zwraca zarówno dzienniki odmowy, jak i dzienniki tylko do dziennika, które można odróżnić przy użyciu kolumny access_type . Dzienniki odmowy mają wartość DROP, a dzienniki tylko rejestrowania mają LOG_ONLY_DENIAL.
Poniższy przykład pobiera dzienniki z ostatnich 2 godzin:
select * from system.access.outbound_network
where event_time >= current_timestamp() - interval 2 hour
sort by event_time desc
Odmowy nie są rejestrowane w tabeli systemu logowania ruchu wychodzącego podczas nawiązywania połączenia z zewnętrznymi modelami generacyjnymi sztucznej inteligencji przy użyciu bramy Mosaic AI. Zobacz Mozaikowa brama sztucznej inteligencji.
Uwaga
Może wystąpić pewne opóźnienie między czasem dostępu a wyświetleniem dzienników odmowy.
Ograniczenia
konfiguracja: ta funkcja jest konfigurowana tylko za pomocą konsoli konta. Obsługa interfejsu API nie jest jeszcze dostępna.
Rozmiar przekazywania artefaktu: w przypadku korzystania z wewnętrznego systemu plików usługi Databricks MLflow w formacie
dbfs:/databricks/mlflow-tracking/<experiment_id>/<run_id>/artifacts/<artifactPath>przekazywanie artefaktów jest ograniczone do 5 GB dla interfejsów APIlog_artifact,log_artifactsilog_model.obsługiwane połączenia Unity Catalog: Obsługiwane są następujące typy połączeń: MySQL, PostgreSQL, Snowflake, Redshift, Azure Synapse, SQL Server, Salesforce, BigQuery, Netsuite, Workday RaaS, Hive MetaStore i Salesforce Data Cloud.
Model obsługujący: kontrolka ruchu wychodzącego nie ma zastosowania podczas kompilowania obrazów do obsługi modelu.
dostęp do usługi Azure Storage: obsługiwany jest tylko sterownik systemu plików usługi Azure Blob dla usługi Azure Data Lake Storage. Dostęp przy użyciu sterownika usługi Azure Blob Storage lub sterownika WASB nie jest obsługiwany.