Prognozowanie za pomocą rozwiązania AutoML (obliczenia klasyczne)
Użyj rozwiązania AutoML, aby automatycznie znaleźć najlepszy algorytm prognozowania i konfigurację hiperparametrów w celu przewidywania wartości na podstawie danych szeregów czasowych.
Prognozowanie szeregów czasowych jest dostępne tylko dla środowiska Databricks Runtime 10.0 ML lub nowszego.
Konfigurowanie eksperymentu prognozowania za pomocą interfejsu użytkownika
Problem z prognozowaniem można skonfigurować przy użyciu interfejsu użytkownika rozwiązania AutoML, wykonując następujące kroki:
- Na pasku bocznym wybierz pozycję Eksperymenty.
- Na karcie Prognozowanie wybierz pozycję Rozpocznij szkolenie.
Domyślnie interfejs użytkownika prognozowania jest ustawiony na prognozowanie bezserwerowe. Aby uzyskać dostęp do prognozowania przy użyciu własnych zasobów obliczeniowych, wybierz przywrócić stare doświadczenie.
Konfigurowanie eksperymentu automatycznego uczenia maszynowego
Zostanie wyświetlona strona Konfigurowanie eksperymentu automatycznego uczenia maszynowego. Na tej stronie skonfigurujesz proces automatycznego uczenia maszynowego, określając zestaw danych, typ problemu, docelową lub etykietę kolumny do przewidywania, metryki używanej do oceny i oceniania przebiegów eksperymentu oraz zatrzymywania warunków.
W polu Obliczenia wybierz klaster z uruchomionym środowiskiem Databricks Runtime 10.0 ML lub nowszym.
W obszarze Zestaw danych kliknij przycisk Przeglądaj. Przejdź do tabeli, której chcesz użyć, a następnie kliknij pozycję Wybierz. Zostanie wyświetlony schemat tabeli.
Kliknij pole Cel przewidywania. Zostanie wyświetlone menu rozwijane z listą kolumn wyświetlanych w schemacie. Wybierz kolumnę, którą model ma przewidywać.
Kliknij pole Kolumna czasowa. Zostanie wyświetlona lista rozwijana z kolumnami zestawu danych, które są typu
timestamplubdate. Wybierz kolumnę zawierającą okresy dla szeregu czasowego.W przypadku prognozowania z wieloma seriami wybierz kolumny identyfikujące poszczególne szeregi czasowe z listy rozwijanej Identyfikatory szeregów czasowych. Rozwiązanie AutoML grupuje dane według tych kolumn jako różne szeregi czasowe i trenuje model dla każdej serii niezależnie. Jeśli to pole pozostanie puste, rozwiązanie AutoML zakłada, że zestaw danych zawiera pojedynczą serię czasową.
W polach Horyzont prognozy i częstotliwość określ liczbę okresów w przyszłości, dla których rozwiązanie AutoML powinno obliczyć prognozowane wartości. W polu po lewej stronie wprowadź liczbę całkowitą okresów do prognozowania. W prawym polu wybierz jednostki.
Uwaga
Aby użyć funkcji Auto-ARIMA, szereg czasowy musi mieć regularną częstotliwość, w której interwał między dwoma punktami musi być taki sam w ciągu szeregu czasowego. Częstotliwość musi być zgodna z jednostką częstotliwości określoną w wywołaniu interfejsu API lub w interfejsie użytkownika rozwiązania AutoML. Rozwiązanie AutoML obsługuje brakujące kroki czasu, wypełniając te wartości poprzednimi wartościami.
W środowisku Databricks Runtime 11.3 LTS ML i nowszym można zapisać wyniki przewidywania. W tym celu określ bazę danych w polu Wyjściowa baza danych . Kliknij przycisk Przeglądaj i wybierz bazę danych w oknie dialogowym. Rozwiązanie AutoML zapisuje wyniki przewidywania w tabeli w tej bazie danych.
W polu Nazwa eksperymentu jest wyświetlana nazwa domyślna. Aby ją zmienić, wpisz nową nazwę w polu.
Możesz również wykonać następujące czynności:
- Określ dodatkowe opcje konfiguracji.
- Użyj istniejących tabel funkcji w magazynie funkcji, aby rozszerzyć oryginalny wejściowy zestaw danych.
Konfiguracje zaawansowane
Otwórz sekcję Konfiguracja zaawansowana (opcjonalnie), aby uzyskać dostęp do tych parametrów.
- Metryka oceny to podstawowa metryka używana do oceniania przebiegów.
- W środowisku Databricks Runtime 10.4 LTS ML i nowszym można wykluczyć struktury szkoleniowe z uwagi. Domyślnie rozwiązanie AutoML trenuje modele przy użyciu struktur wymienionych w obszarze Algorytmy automatycznego uczenia maszynowego.
- Możesz edytować warunki zatrzymywania. Domyślne warunki zatrzymywania to:
- W przypadku eksperymentów prognozowania zatrzymaj się po 120 minutach.
- W środowisku Databricks Runtime 10.4 LTS ML i poniżej w przypadku eksperymentów klasyfikacji i regresji zatrzymaj się po 60 minutach lub po ukończeniu 200 prób, w zależności od tego, co nastąpi wcześniej. W przypadku środowiska Databricks Runtime 11.0 ML i nowszych liczba prób nie jest używana jako stan zatrzymania.
- W środowisku Databricks Runtime 10.4 LTS ML i nowszym w przypadku eksperymentów klasyfikacji i regresji rozwiązanie AutoML obejmuje wczesne zatrzymywanie; zatrzymuje trenowanie i dostrajanie modeli, jeśli metryka walidacji nie jest już ulepszana.
- W środowisku Databricks Runtime 10.4 LTS ML i nowszym można wybrać element ,
time columnaby podzielić dane na potrzeby trenowania, walidacji i testowania w kolejności chronologicznej (dotyczy tylko klasyfikacji i regresji). - Usługa Databricks nie zaleca wypełniania pola Katalog danych. Spowoduje to wyzwolenie domyślnego zachowania bezpiecznego przechowywania zestawu danych jako artefaktu MLflow. Można określić ścieżkę systemu plików DBFS, ale w tym przypadku zestaw danych nie dziedziczy uprawnień dostępu eksperymentu automatycznego uczenia maszynowego.
Uruchamianie eksperymentu i monitorowanie wyników
Aby rozpocząć eksperyment automl, kliknij przycisk Uruchom rozwiązanie AutoML. Eksperyment rozpoczyna się od uruchomienia, a zostanie wyświetlona strona trenowania zautomatyzowanego uczenia maszynowego. Aby odświeżyć tabelę przebiegów, kliknij pozycję  .
.
Wyświetlanie postępu eksperymentu
Z poziomu tej strony można:
- Zatrzymaj eksperyment w dowolnym momencie.
- Otwórz notes eksploracji danych.
- Monitorowanie przebiegów.
- Przejdź do strony uruchamiania dla dowolnego przebiegu.
W przypadku środowiska Databricks Runtime 10.1 ML lub nowszego rozwiązanie AutoML wyświetla ostrzeżenia dotyczące potencjalnych problemów z zestawem danych, takich jak nieobsługiwane typy kolumn lub kolumny o wysokiej kardynalności.
Uwaga
Usługa Databricks najlepiej wskazuje potencjalne błędy lub problemy. Jednak może to nie być kompleksowe i może nie przechwytywać problemów lub błędów, które mogą być wyszukiwane.
Aby wyświetlić wszelkie ostrzeżenia dotyczące zestawu danych, kliknij kartę Ostrzeżenia na stronie trenowania lub na stronie eksperymentu po zakończeniu eksperymentu.
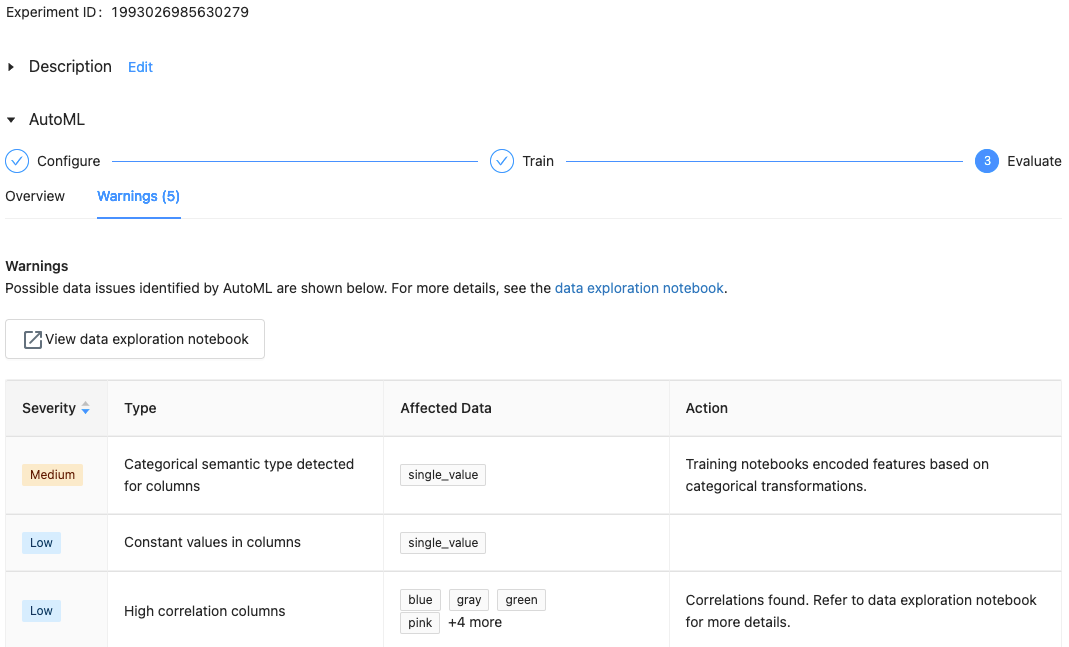
Wyświetlanie wyników
Po zakończeniu eksperymentu można wykonać następujące czynności:
- Zarejestruj i wdróż jeden z modeli za pomocą biblioteki MLflow.
- Wybierz pozycję Wyświetl notes, aby uzyskać najlepszy model , aby przejrzeć i edytować notes, który utworzył najlepszy model.
- Wybierz pozycję Wyświetl notes eksploracji danych, aby otworzyć notes eksploracji danych.
- Wyszukiwanie, filtrowanie i sortowanie przebiegów w tabeli przebiegów.
- Zobacz szczegóły dotyczące dowolnego przebiegu:
- Wygenerowany notes zawierający kod źródłowy dla przebiegu w wersji próbnej można znaleźć, klikając w przebiegu platformy MLflow. Notes jest zapisywany w sekcji Artefakty na stronie uruchamiania. Możesz pobrać ten notes i zaimportować go do obszaru roboczego, jeśli pobieranie artefaktów jest włączone przez administratorów obszaru roboczego.
- Aby wyświetlić wyniki przebiegu, kliknij kolumnę Modele lub kolumnę Godzina rozpoczęcia. Zostanie wyświetlona strona uruchamiania zawierająca informacje o przebiegu próbnym (takim jak parametry, metryki i tagi) oraz artefakty utworzone przez przebieg, w tym model. Ta strona zawiera również fragmenty kodu, których można użyć do przewidywania modelu.
Aby powrócić do tego eksperymentu automatycznego uczenia maszynowego później, znajdź go w tabeli na stronie Eksperymenty. Wyniki każdego eksperymentu zautomatyzowanego uczenia maszynowego, w tym notesów eksploracji i trenowania danych, są przechowywane w databricks_automlfolderze głównym użytkownika, który przeprowadził eksperyment.
Rejestrowanie i wdrażanie modelu
Model można zarejestrować i wdrożyć za pomocą interfejsu użytkownika rozwiązania AutoML:
- Wybierz link w kolumnie Modele dla modelu do zarejestrowania. Po zakończeniu przebiegu górny wiersz jest najlepszym modelem (na podstawie metryki podstawowej).
- Wybierz
 , aby zarejestrować model w rejestrze modeli.
, aby zarejestrować model w rejestrze modeli. - Wybierz pozycję
 Modele na pasku bocznym, aby przejść do rejestru modeli.
Modele na pasku bocznym, aby przejść do rejestru modeli. - Wybierz nazwę modelu w tabeli modelu.
- Na stronie zarejestrowanego modelu można udostępnić model z obsługą modelu.
Brak modułu o nazwie "pandas.core.indexes.numeric"
Podczas obsługi modelu utworzonego przy użyciu rozwiązania AutoML z obsługą modelu może wystąpić błąd: No module named 'pandas.core.indexes.numeric.
Jest to spowodowane niezgodną pandas wersją między rozwiązaniem AutoML a modelem obsługującym środowisko punktu końcowego. Ten błąd można rozwiązać, uruchamiając skrypt add-pandas-dependency.py. Skrypt edytuje element requirements.txt i conda.yaml dla zarejestrowanego modelu, aby zawierał odpowiednią pandas wersję zależności: pandas==1.5.3
- Zmodyfikuj skrypt, aby uwzględnić
run_idprzebieg MLflow, w którym zarejestrowano model. - Ponowne zarejestrowanie modelu w rejestrze modeli MLflow.
- Spróbuj użyć nowej wersji modelu MLflow.