Wprowadzenie: importowanie i wizualizowanie danych CSV z notesu
W tym artykule przedstawiono sposób użycia notesu usługi Azure Databricks do importowania danych z pliku CSV zawierającego dane nazwy dziecka z health.data.ny.gov do woluminu wykazu aparatu Unity przy użyciu języków Python, Scala i R. Dowiesz się również, jak modyfikować nazwę kolumny, wizualizować dane i zapisywać je w tabeli.
Wymagania
Aby wykonać zadania opisane w tym artykule, musisz spełnić następujące wymagania:
- Obszar roboczy musi mieć włączony katalog aparatu Unity. Aby uzyskać informacje na temat rozpoczynania pracy z wykazem aparatu Unity, zobacz Konfigurowanie wykazu aparatu Unity i zarządzanie nim.
- Musisz mieć
WRITE VOLUMEuprawnienia do woluminu,USE SCHEMAuprawnienia w schemacie nadrzędnym iUSE CATALOGuprawnienia w katalogu nadrzędnym. - Musisz mieć uprawnienia do używania istniejącego zasobu obliczeniowego lub utworzenia nowego zasobu obliczeniowego. Przejrzyj Rozpoczynanie pracy z usługą Azure Databricks lub skontaktuj się z administratorem usługi Databricks.
Napiwek
Aby zapoznać się z ukończonym notesem dla tego artykułu, zobacz Importowanie i wizualizowanie notesów danych.
Krok 1. Tworzenie nowego notesu
Aby utworzyć notes w obszarze roboczym, kliknij pozycję ![]() Nowy na pasku bocznym, a następnie kliknij przycisk Notes. W obszarze roboczym zostanie otwarty pusty notes.
Nowy na pasku bocznym, a następnie kliknij przycisk Notes. W obszarze roboczym zostanie otwarty pusty notes.
Aby dowiedzieć się więcej na temat tworzenia notesów i zarządzania nimi, zobacz Zarządzanie notesami.
Krok 2. Definiowanie zmiennych
W tym kroku zdefiniujesz zmienne do użycia w przykładowym notesie utworzonym w tym artykule.
Skopiuj i wklej następujący kod do nowej pustej komórki notesu. Zastąp
<catalog-name>wartości ,<schema-name>i<volume-name>nazwami wykazu, schematu i woluminu dla woluminu wykazu aparatu Unity. Opcjonalnie zastąptable_namewartość wybraną nazwą tabeli. Dane nazwy dziecka zostaną zapisane w tej tabeli w dalszej części tego artykułu.Naciśnij
Shift+Enter, aby uruchomić komórkę i utworzyć nową pustą komórkę.Python
catalog = "<catalog_name>" schema = "<schema_name>" volume = "<volume_name>" download_url = "https://health.data.ny.gov/api/views/jxy9-yhdk/rows.csv" file_name = "baby_names.csv" table_name = "baby_names" path_volume = "/Volumes/" + catalog + "/" + schema + "/" + volume path_table = catalog + "." + schema print(path_table) # Show the complete path print(path_volume) # Show the complete pathScala
val catalog = "<catalog_name>" val schema = "<schema_name>" val volume = "<volume_name>" val downloadUrl = "https://health.data.ny.gov/api/views/jxy9-yhdk/rows.csv" val fileName = "baby_names.csv" val tableName = "baby_names" val pathVolume = s"/Volumes/${catalog}/${schema}/${volume}" val pathTable = s"${catalog}.${schema}" print(pathVolume) // Show the complete path print(pathTable) // Show the complete pathR
catalog <- "<catalog_name>" schema <- "<schema_name>" volume <- "<volume_name>" download_url <- "https://health.data.ny.gov/api/views/jxy9-yhdk/rows.csv" file_name <- "baby_names.csv" table_name <- "baby_names" path_volume <- paste("/Volumes/", catalog, "/", schema, "/", volume, sep = "") path_table <- paste(catalog, ".", schema, sep = "") print(path_volume) # Show the complete path print(path_table) # Show the complete path
Krok 3. Importowanie pliku CSV
W tym kroku zaimportujesz plik CSV zawierający dane nazwy dziecka z health.data.ny.gov do woluminu wykazu aparatu Unity.
Skopiuj i wklej następujący kod do nowej pustej komórki notesu. Ten kod kopiuje
rows.csvplik z health.data.ny.gov do woluminu wykazu aparatu Unity przy użyciu polecenia dbutuils usługi Databricks .Naciśnij ,
Shift+Enteraby uruchomić komórkę, a następnie przejdź do następnej komórki.Python
dbutils.fs.cp(f"{download_url}", f"{path_volume}" + "/" + f"{file_name}")Scala
dbutils.fs.cp(downloadUrl, s"${pathVolume}/${fileName}")R
dbutils.fs.cp(download_url, paste(path_volume, "/", file_name, sep = ""))
Krok 4. Ładowanie danych CSV do ramki danych
W tym kroku utworzysz ramkę danych o nazwie df z pliku CSV, który został wcześniej załadowany do woluminu wykazu aparatu Unity przy użyciu metody spark.read.csv .
Skopiuj i wklej następujący kod do nowej pustej komórki notesu. Ten kod ładuje dane baby name do ramki
dfdanych z pliku CSV.Naciśnij ,
Shift+Enteraby uruchomić komórkę, a następnie przejdź do następnej komórki.Python
df = spark.read.csv(f"{path_volume}/{file_name}", header=True, inferSchema=True, sep=",")Scala
val df = spark.read .option("header", "true") .option("inferSchema", "true") .option("delimiter", ",") .csv(s"${pathVolume}/${fileName}")R
# Load the SparkR package that is already preinstalled on the cluster. library(SparkR) df <- read.df(paste(path_volume, "/", file_name, sep=""), source="csv", header = TRUE, inferSchema = TRUE, delimiter = ",")
Dane można załadować z wielu obsługiwanych formatów plików.
Krok 5. Wizualizowanie danych z notesu
W tym kroku użyjesz display() metody , aby wyświetlić zawartość ramki danych w tabeli w notesie, a następnie zwizualizować dane na wykresie w chmurze wyrazów w notesie.
Skopiuj i wklej następujący kod do nowej pustej komórki notesu, a następnie kliknij pozycję Uruchom komórkę , aby wyświetlić dane w tabeli.
Python
display(df)Scala
display(df)R
display(df)Przejrzyj wyniki w tabeli.
Obok karty Tabela kliknij+, a następnie kliknij pozycję Wizualizacja.
W edytorze wizualizacji kliknij pozycję Typ wizualizacji i sprawdź, czy wybrano chmurę programu Word.
W kolumnie Wyrazy sprawdź, czy
First Namejest zaznaczone.W obszarze Limit częstotliwości kliknij pozycję
35.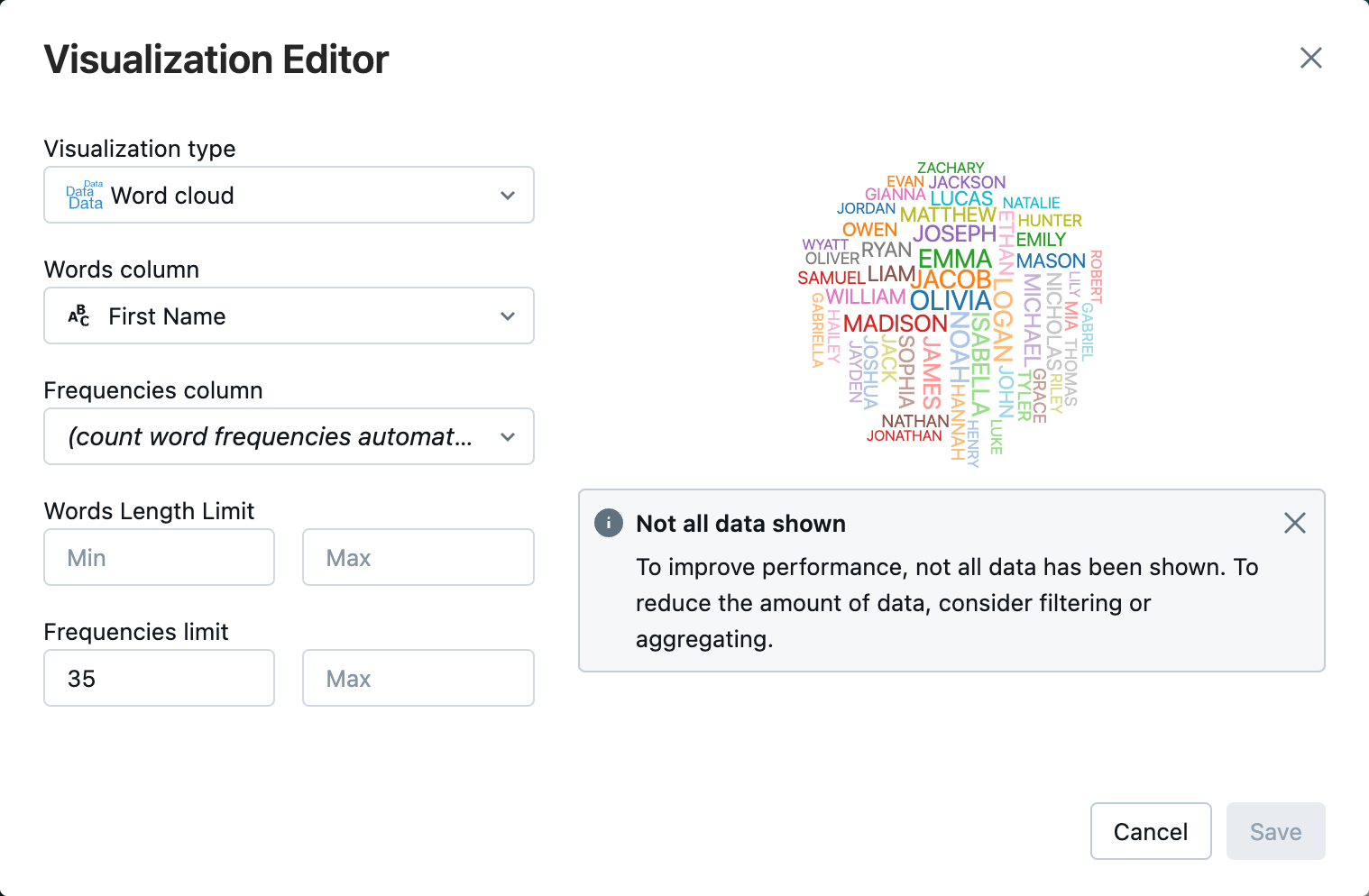
Kliknij przycisk Zapisz.
Krok 6. Zapisywanie ramki danych w tabeli
Ważne
Aby zapisać ramkę danych w wykazie aparatu Unity, musisz mieć CREATE uprawnienia do tabeli w wykazie i schemacie. Aby uzyskać informacje na temat uprawnień w wykazie aparatu Unity, zobacz Uprawnienia i zabezpieczane obiekty w wykazie aparatu Unity i Zarządzanie uprawnieniami w wykazie aparatu Unity.
Skopiuj i wklej następujący kod do pustej komórki notesu. Ten kod zastępuje spację w nazwie kolumny. Znaki specjalne, takie jak spacje, nie są dozwolone w nazwach kolumn. Ten kod używa metody Apache Spark
withColumnRenamed().Python
df = df.withColumnRenamed("First Name", "First_Name") df.printSchemaScala
val dfRenamedColumn = df.withColumnRenamed("First Name", "First_Name") // when modifying a DataFrame in Scala, you must assign it to a new variable dfRenamedColumn.printSchema()R
df <- withColumnRenamed(df, "First Name", "First_Name") printSchema(df)Skopiuj i wklej następujący kod do pustej komórki notesu. Ten kod zapisuje zawartość ramki danych w tabeli w wykazie aparatu Unity przy użyciu zmiennej nazwy tabeli zdefiniowanej na początku tego artykułu.
Python
df.write.mode("overwrite").saveAsTable(f"{path_table}" + "." + f"{table_name}")Scala
dfRenamedColumn.write.mode("overwrite").saveAsTable(s"${pathTable}.${tableName}")R
saveAsTable(df, paste(path_table, ".", table_name), mode = "overwrite")Aby sprawdzić, czy tabela została zapisana, kliknij pozycję Wykaz na lewym pasku bocznym, aby otworzyć interfejs użytkownika Eksploratora wykazu. Otwórz katalog, a następnie schemat, aby sprawdzić, czy tabela jest wyświetlana.
Kliknij tabelę, aby wyświetlić schemat tabeli na karcie Przegląd .
Kliknij pozycję Przykładowe dane , aby wyświetlić 100 wierszy danych z tabeli.
Importowanie i wizualizowanie notesów danych
Aby wykonać kroki opisane w tym artykule, użyj jednego z poniższych notesów. Zastąp <catalog-name>wartości , <schema-name>i <volume-name> nazwami wykazu, schematu i woluminu dla woluminu wykazu aparatu Unity. Opcjonalnie zastąp table_name wartość wybraną nazwą tabeli.
Python
Importowanie danych z pliku CSV przy użyciu języka Python
Scala
Importowanie danych z woluminów CSV przy użyciu języka Scala
R
Importowanie danych z pliku CSV przy użyciu języka R
Następne kroki
- Aby dowiedzieć się więcej o dodawaniu dodatkowych danych do istniejącej tabeli z pliku CSV, zobacz Wprowadzenie: pozyskiwanie i wstawianie dodatkowych danych.
- Aby dowiedzieć się więcej o czyszczeniu i ulepszaniu danych, zobacz Wprowadzenie: ulepszanie i oczyszczanie danych.