Poprawianie jakości potoku danych RAG
W tym artykule omówiono sposób eksperymentowania z wyborami potoków danych z praktycznego punktu widzenia w implementowaniu zmian potoku danych.
Kluczowe składniki potoku danych
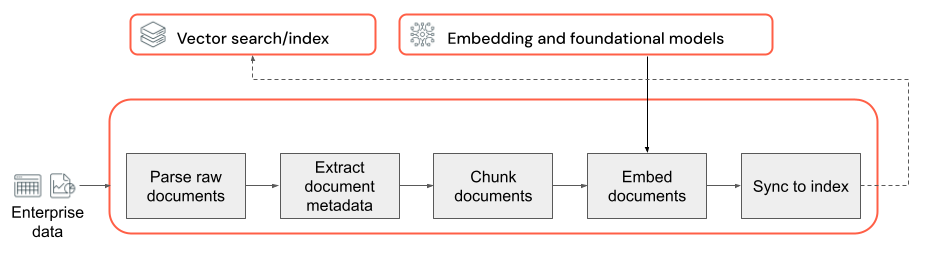
Podstawą każdej aplikacji RAG z danymi bez struktury jest potok danych. Ten potok jest odpowiedzialny za przygotowanie danych bez struktury w formacie, który może być skutecznie wykorzystywany przez aplikację RAG. Chociaż ten potok danych może stać się arbitralnie złożony, poniżej przedstawiono kluczowe składniki, o których należy pomyśleć podczas pierwszego kompilowania aplikacji RAG:
- Kompozycja korpusu: wybieranie odpowiednich źródeł danych i zawartości na podstawie konkretnego przypadku użycia.
- Analizowanie: wyodrębnianie odpowiednich informacji z danych pierwotnych przy użyciu odpowiednich technik analizowania.
- Fragmentowanie: dzielenie analizowanych danych na mniejsze fragmenty, którymi można zarządzać w celu wydajnego pobierania.
- Osadzanie: konwertowanie fragmentowanych danych tekstowych na reprezentację wektorów liczbowych, która przechwytuje jego znaczenie semantyczne.
Kompozycja korpusu
Bez odpowiedniego korpusu danych aplikacja RAG nie może pobrać informacji wymaganych do udzielenia odpowiedzi na zapytanie użytkownika. Odpowiednie dane są całkowicie zależne od konkretnych wymagań i celów aplikacji, co ma kluczowe znaczenie, aby poświęcić czas, aby zrozumieć niuanse dostępnych danych (zobacz sekcję dotyczącą zbierania wymagań, aby uzyskać wskazówki na ten temat).
Na przykład podczas tworzenia bota obsługi klienta możesz rozważyć uwzględnienie następujących kwestii:
- Dokumenty bazy wiedzy
- Często zadawane pytania (FAQ)
- Podręczniki i specyfikacje produktu
- Przewodniki rozwiązywania problemów
Skontaktuj się z ekspertami z dziedziny i uczestnikami projektu od samego początku dowolnego projektu, aby pomóc zidentyfikować i ograniczyć odpowiednią zawartość, która może poprawić jakość i pokrycie Twoich korpusów danych. Mogą one udostępniać szczegółowe informacje na temat typów zapytań, które mogą przesyłać użytkownicy, i pomóc w określaniu priorytetów najważniejszych informacji do uwzględnienia.
Analiza
Po zidentyfikowaniu źródeł danych dla aplikacji RAG następnym krokiem jest wyodrębnienie wymaganych informacji z danych pierwotnych. Ten proces, znany jako analizowanie, obejmuje przekształcenie danych bez struktury w format, który może być skutecznie wykorzystywany przez aplikację RAG.
Określone techniki analizowania i używane narzędzia zależą od typu danych, z którymi pracujesz. Na przykład:
- Dokumenty tekstowe (PDF, Dokumenty programu Word): gotowe biblioteki, takie jak bez struktury i PyPDF2 , mogą obsługiwać różne formaty plików i udostępniać opcje dostosowywania procesu analizowania.
- Dokumenty HTML: biblioteki analizy HTML, takie jak BeautifulSoup , mogą służyć do wyodrębniania odpowiedniej zawartości ze stron internetowych. Za ich pomocą można nawigować po strukturze HTML, wybierać określone elementy i wyodrębniać żądany tekst lub atrybuty.
- Obrazy i zeskanowane dokumenty: techniki optycznego rozpoznawania znaków (OCR) są zwykle wymagane do wyodrębnienia tekstu z obrazów. Popularne biblioteki OCR to Tesseract, Amazon Textract, Azure AI Vision OCR i Google Cloud Vision API.
Najlepsze rozwiązania dotyczące analizowania danych
Podczas analizowania danych należy wziąć pod uwagę następujące najlepsze rozwiązania:
- Czyszczenie danych: wstępnie przetwarza wyodrębniony tekst, aby usunąć wszelkie nieistotne lub hałaśliwe informacje, takie jak nagłówki, stopki lub znaki specjalne. Bądź świadomy zmniejszenia ilości niepotrzebnych lub źle sformułowanych informacji, które łańcuch RAG musi przetworzyć.
- Obsługa błędów i wyjątków: zaimplementuj mechanizmy obsługi błędów i rejestrowania, aby zidentyfikować i rozwiązać wszelkie problemy napotkane podczas procesu analizowania. Ułatwia to szybkie identyfikowanie i rozwiązywanie problemów. Często wskazuje to na nadrzędne problemy z jakością danych źródłowych.
- Dostosowywanie logiki analizowania: w zależności od struktury i formatu danych może być konieczne dostosowanie logiki analizowania w celu wyodrębnienia najbardziej odpowiednich informacji. Chociaż może to wymagać dodatkowego nakładu pracy z góry, zainwestuj czas, aby to zrobić, jeśli jest to wymagane — często uniemożliwia to wiele problemów z jakością podrzędną.
- Ocenianie jakości analizowania: Regularnie oceniaj jakość analizowanych danych, ręcznie przeglądając próbkę danych wyjściowych. Może to pomóc w zidentyfikowaniu wszelkich problemów lub obszarów poprawy w procesie analizowania.
Segmentu
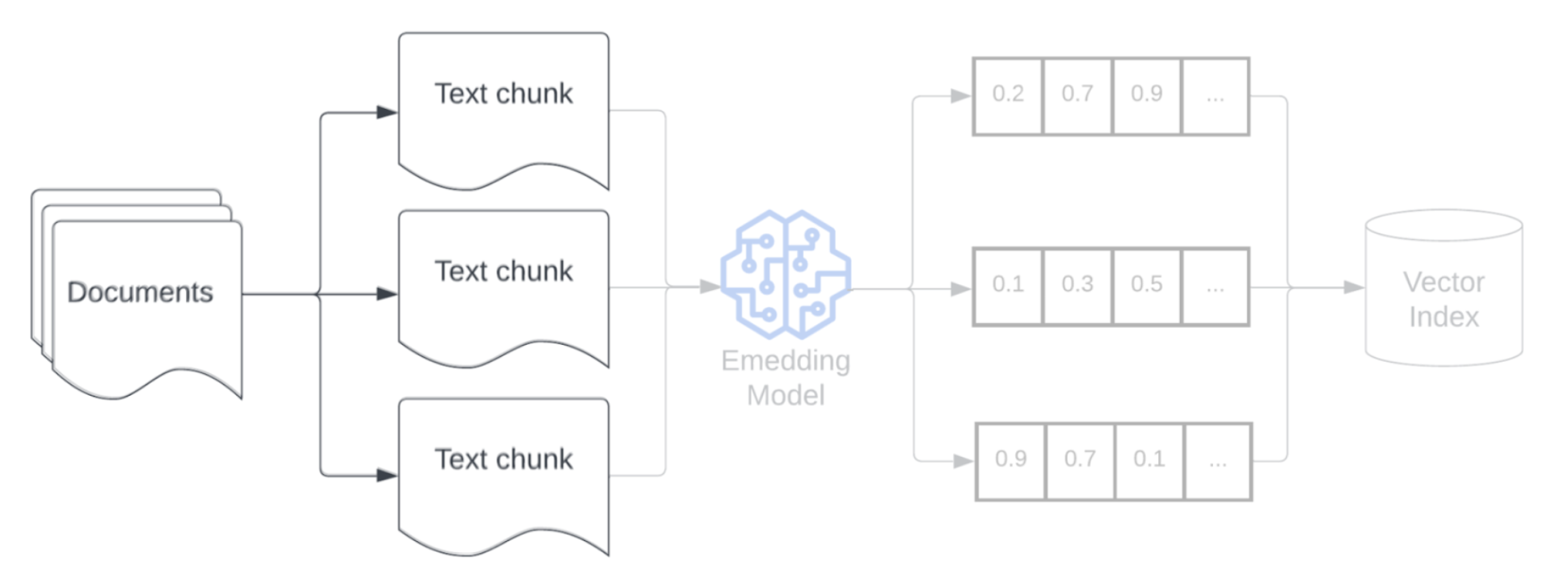
Po przeanalizowaniu danych pierwotnych w bardziej ustrukturyzowanym formacie następnym krokiem jest podzielenie ich na mniejsze, możliwe do zarządzania jednostki nazywane fragmentami. Segmentowanie dużych dokumentów na mniejsze, semantycznie skoncentrowane fragmenty zapewnia, że pobrane dane mieszczą się w kontekście LLM, jednocześnie minimalizując włączenie rozpraszających lub nieistotnych informacji. Opcje dokonane na fragmentowaniu będą mieć bezpośredni wpływ na to, jakie pobrane dane są udostępniane przez moduł LLM, dzięki czemu jest to jedna z pierwszych warstw optymalizacji w aplikacji RAG.
Podczas fragmentowania danych należy wziąć pod uwagę następujące czynniki:
- Strategia fragmentowania: metoda używana do dzielenia oryginalnego tekstu na fragmenty. Może to obejmować podstawowe techniki, takie jak dzielenie według zdań, akapitów lub określonej liczby znaków/tokenów, za pomocą bardziej zaawansowanych strategii dzielenia specyficznych dla dokumentu.
- Rozmiar fragmentu: mniejsze fragmenty mogą skupić się na konkretnych szczegółach, ale tracą niektóre informacje otaczające. Większe fragmenty mogą przechwytywać więcej kontekstu, ale mogą również zawierać nieistotne informacje.
- Nakładanie się między fragmentami: aby upewnić się, że ważne informacje nie zostaną utracone podczas dzielenia danych na fragmenty, rozważ uwzględnienie niektórych nakładających się między sąsiadujących fragmentów. Nakładanie się może zapewnić ciągłość i zachowywanie kontekstu między fragmentami.
- Spójność semantyczna: Jeśli to możliwe, należy utworzyć fragmenty, które są semantycznie spójne, co oznacza, że zawierają powiązane informacje i mogą stać na własną rękę jako zrozumiała jednostka tekstu. Można to osiągnąć, biorąc pod uwagę strukturę oryginalnych danych, takich jak akapity, sekcje lub granice tematów.
- Metadane: uwzględnienie odpowiednich metadanych w poszczególnych fragmentach, takich jak nazwa dokumentu źródłowego, nagłówek sekcji lub nazwy produktów, może poprawić proces pobierania. Te dodatkowe informacje w fragmentach mogą pomóc w dopasowaniu zapytań pobierania do fragmentów.
Strategie fragmentowania danych
Znalezienie właściwej metody fragmentowania jest zarówno iteracyjne, jak i zależne od kontekstu. Nie ma żadnego podejścia uniwersalnego; optymalny rozmiar i metoda fragmentu zależą od konkretnego przypadku użycia i charakteru przetwarzanych danych. Ogólnie rzecz biorąc, strategie fragmentowania można postrzegać jako następujące:
- Fragmentowanie o stałym rozmiarze: podziel tekst na fragmenty wstępnie określonego rozmiaru, na przykład stałą liczbę znaków lub tokenów (na przykład LangChain CharacterTextSplitter). Podczas dzielenia przez dowolną liczbę znaków/tokenów można szybko i łatwo skonfigurować, zwykle nie powoduje to spójnych fragmentów spójnych semantycznie spójnych.
- Fragmentowanie oparte na akapitach: użyj naturalnych granic akapitu w tekście, aby zdefiniować fragmenty. Ta metoda może pomóc w zachowaniu spójności semantycznej fragmentów, ponieważ akapity często zawierają powiązane informacje (na przykład LangChain RecursiveCharacterTextSplitter).
- Fragmentowanie specyficzne dla formatu: formaty, takie jak markdown lub HTML, mają w sobie nieodłączną strukturę, która może służyć do definiowania granic fragmentów (na przykład nagłówków markdown). Do tego celu można używać narzędzi takich jak Podziały oparte na sekcjach nagłówków Języka LangChain w / lub HTML.
- Fragmentowanie semantyczne: techniki, takie jak modelowanie tematów, można zastosować do identyfikowania semantycznie spójnych sekcji w tekście. Te podejścia analizują zawartość lub strukturę każdego dokumentu, aby określić najbardziej odpowiednie granice fragmentów na podstawie zmian w temacie. Chociaż bardziej zaangażowane niż bardziej podstawowe podejścia, fragmentowanie semantyczne może pomóc w tworzeniu fragmentów, które są bardziej dopasowane do naturalnych podziałów semantycznych w tekście (zobacz LangChain SemanticChunker na przykład tego).
Przykład: poprawianie rozmiaru fragmentu
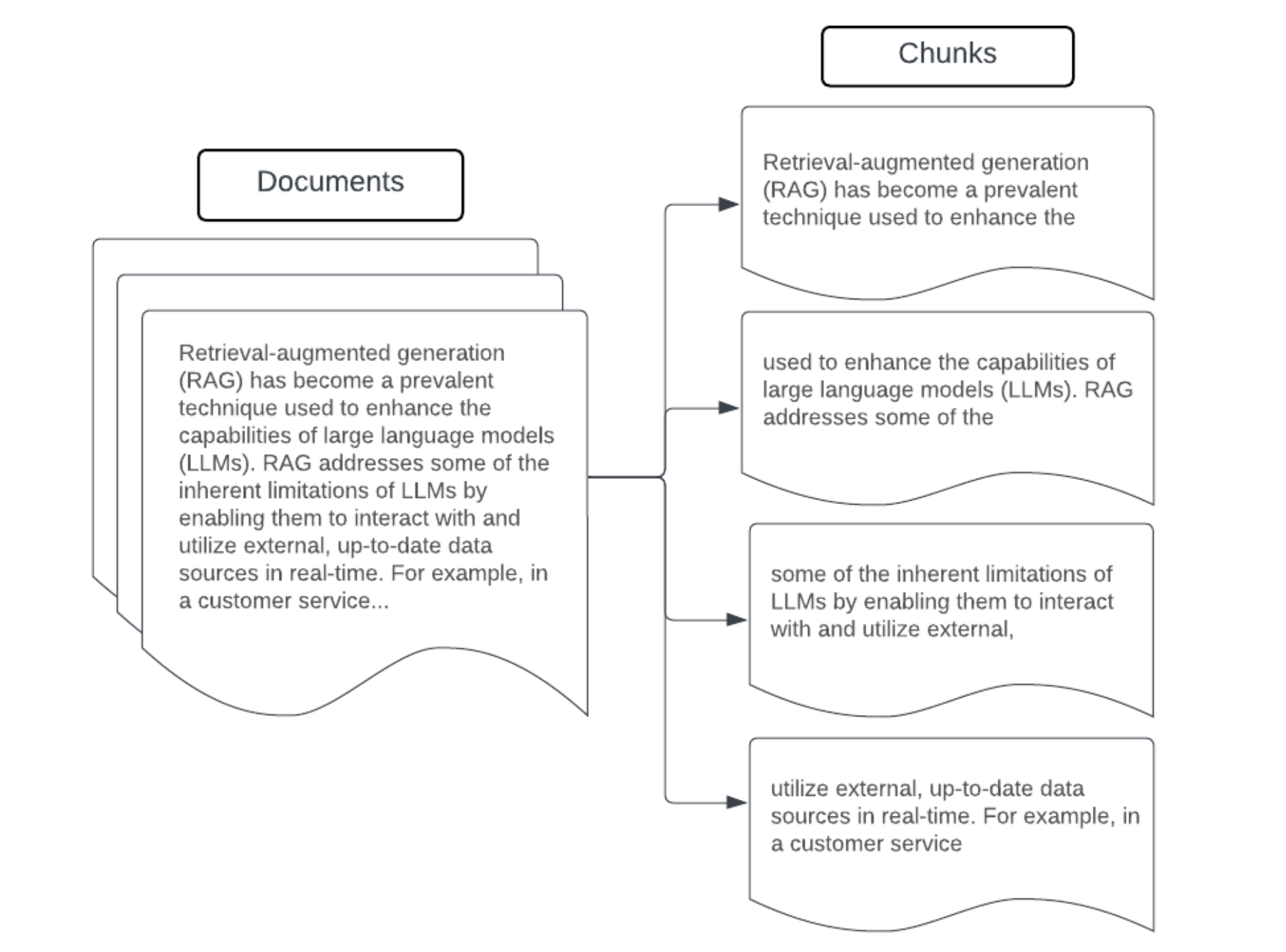
Przykład fragmentowania o stałym rozmiarze przy użyciu elementu RecursiveCharacterTextSplitter języka LangChain z parametrami chunk_size=100 i chunk_overlap=20.
Funkcja ChunkViz zapewnia interaktywny sposób wizualizacji, w jaki sposób różne rozmiary fragmentów i fragmenty nakładają się na siebie wartości z podziałami znaków Langchain wpływa na wynikowe fragmenty.
Model osadzania
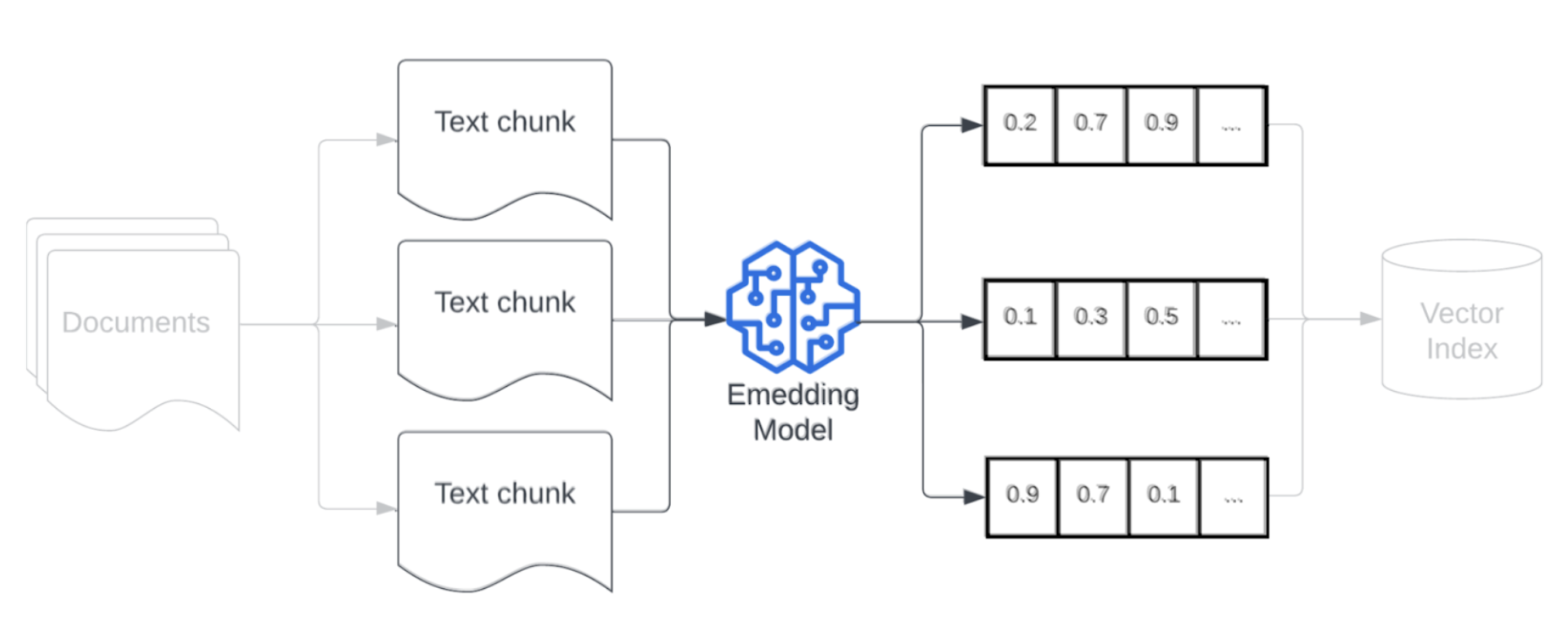
Po fragmentowaniu danych następnym krokiem jest przekonwertowanie fragmentów tekstu na reprezentację wektorową przy użyciu modelu osadzania. Model osadzania służy do konwertowania każdego fragmentu tekstu na reprezentację wektorową, która przechwytuje jego znaczenie semantyczne. Reprezentując fragmenty jako gęste wektory, osadzanie umożliwia szybkie i dokładne pobieranie najbardziej odpowiednich fragmentów na podstawie ich semantycznej podobieństwa do zapytania pobierania. W czasie zapytania zapytanie zostanie przekształcone przy użyciu tego samego modelu osadzania, który został użyty do osadzania fragmentów w potoku danych.
Podczas wybierania modelu osadzania należy wziąć pod uwagę następujące czynniki:
- Wybór modelu: każdy model osadzania ma swoje niuanse, a dostępne testy porównawcze mogą nie przechwytywać określonych cech danych. Poeksperymentuj z różnymi modelami osadzania poza półką, nawet te, które mogą być niższe w rankingu standardowym, takim jak MTEB. Oto kilka przykładów, które należy wziąć pod uwagę:
- Maksymalna liczba tokenów: należy pamiętać o maksymalnym limicie tokenów dla wybranego modelu osadzania. Jeśli przekażesz fragmenty, które przekraczają ten limit, zostaną obcięte, potencjalnie tracąc ważne informacje. Na przykład bge-large-en-v1.5 ma maksymalny limit tokenu wynoszący 512.
- Rozmiar modelu: Większe modele osadzania zwykle oferują lepszą wydajność, ale wymagają większej ilości zasobów obliczeniowych. Zrównoważ wydajność i wydajność na podstawie konkretnego przypadku użycia i dostępnych zasobów.
- Dostrajanie: jeśli aplikacja RAG zajmuje się językiem specyficznym dla domeny (np. wewnętrznymi akronimami firmy lub terminologią), rozważ dostosowanie modelu osadzania na danych specyficznych dla domeny. Może to pomóc modelowi lepiej uchwycić niuanse i terminologię danej domeny, a często może prowadzić do poprawy wydajności pobierania.