Poprawianie jakości łańcucha RAG
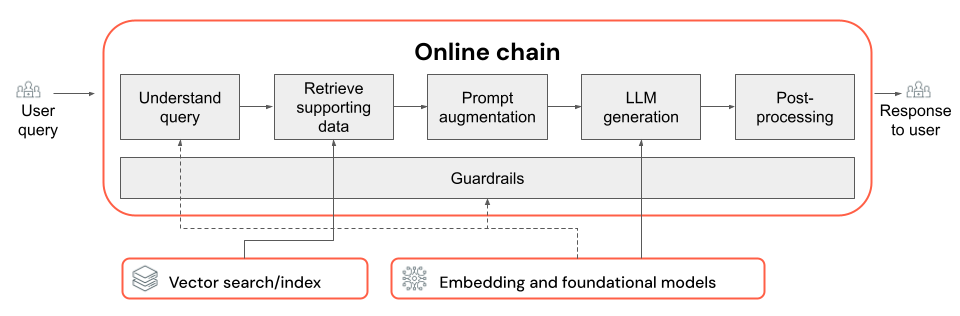
W tym artykule opisano, jak można poprawić jakość aplikacji RAG przy użyciu składników łańcucha RAG.
Łańcuch RAG pobiera zapytanie użytkownika jako dane wejściowe, pobiera odpowiednie informacje, biorąc pod uwagę to zapytanie i generuje odpowiednią odpowiedź uziemiona na pobranych danych. Chociaż dokładne kroki w łańcuchu RAG mogą się znacznie różnić w zależności od przypadku użycia i wymagań, poniżej przedstawiono kluczowe składniki, które należy wziąć pod uwagę podczas tworzenia łańcucha RAG:
- Zrozumienie zapytań: Analizowanie i przekształcanie zapytań użytkowników w celu lepszego reprezentowania intencji i wyodrębniania odpowiednich informacji, takich jak filtry lub słowa kluczowe, w celu ulepszenia procesu pobierania.
- Pobieranie: znajdowanie najbardziej odpowiednich fragmentów informacji przy użyciu zapytania pobierania. W przypadku danych bez struktury zwykle wiąże się to z jedną lub kombinacją wyszukiwania semantycznego lub opartego na słowach kluczowych.
- Monitowanie o rozszerzenie: łączenie zapytania użytkownika z pobranymi informacjami i instrukcjami w celu poprowadzenia usługi LLM w celu generowania odpowiedzi o wysokiej jakości.
- LLM: wybieranie najbardziej odpowiedniego modelu (i parametrów modelu) dla aplikacji w celu optymalizacji/równoważenia wydajności, opóźnień i kosztów.
- Po przetworzeniu i zabezpieczeniach: Stosowanie dodatkowych kroków przetwarzania i środków bezpieczeństwa w celu zapewnienia, że odpowiedzi generowane przez llM są na temat, faktycznie spójne i zgodne z określonymi wytycznymi lub ograniczeniami.
Iteracyjne implementowanie i ocenianie poprawek jakości pokazuje, jak iterować składniki łańcucha.
Opis zapytań
Korzystanie z zapytania użytkownika bezpośrednio jako zapytania pobierania może działać w przypadku niektórych zapytań. Jednak zazwyczaj korzystne jest ponowne sformatowanie zapytania przed wykonaniem kroku pobierania. Zrozumienie zapytań obejmuje krok (lub serię kroków) na początku łańcucha w celu analizowania i przekształcania zapytań użytkowników w celu lepszego reprezentowania intencji, wyodrębniania odpowiednich informacji i ostatecznie pomocy w kolejnym procesie pobierania. Metody przekształcania zapytania użytkownika w celu ulepszenia pobierania obejmują:
Ponowne zapisywanie zapytań: ponowne zapisywanie zapytań obejmuje tłumaczenie zapytania użytkownika na co najmniej jedno zapytanie, które lepiej reprezentuje oryginalną intencję. Celem jest ponowne sformatowanie zapytania w sposób, który zwiększa prawdopodobieństwo znalezienia najbardziej odpowiednich dokumentów przez krok pobierania. Może to być szczególnie przydatne w przypadku złożonych lub niejednoznacznych zapytań, które mogą nie być bezpośrednio zgodne z terminologią używaną w dokumentach pobierania.
Przykłady:
- Parafrasowanie historii konwersacji w czacie wieloeciowym
- Poprawianie błędów pisowni w zapytaniu użytkownika
- Zastępowanie wyrazów lub fraz w zapytaniu użytkownika synonimami w celu przechwycenia szerszego zakresu odpowiednich dokumentów
Ważne
Ponowne zapisywanie zapytań należy wykonać w połączeniu ze zmianami w składniku pobierania
Wyodrębnianie filtrów: w niektórych przypadkach zapytania użytkowników mogą zawierać określone filtry lub kryteria, których można użyć do zawężenia wyników wyszukiwania. Wyodrębnianie filtrów obejmuje identyfikowanie i wyodrębnianie tych filtrów z zapytania oraz przekazywanie ich do kroku pobierania jako dodatkowych parametrów. Może to pomóc poprawić istotność pobranych dokumentów, koncentrując się na określonych podzestawach dostępnych danych.
Przykłady:
- Wyodrębnianie określonych okresów wymienionych w zapytaniu, takich jak "artykuły z ostatnich 6 miesięcy" lub "raporty z 2023 r.".
- Identyfikowanie wzmianki o określonych produktach, usługach lub kategoriach w zapytaniu, takich jak "Usługi profesjonalne usługi Databricks" lub "laptopy".
- Wyodrębnianie jednostek geograficznych z zapytania, takich jak nazwy miast lub kody kraju.
Uwaga
Wyodrębnianie filtrów należy wykonać w połączeniu ze zmianami zarówno w potoku danych wyodrębniania metadanych, jak i składnikami łańcucha pobierania. Krok wyodrębniania metadanych powinien zapewnić dostępność odpowiednich pól metadanych dla każdego dokumentu/fragmentu, a krok pobierania powinien zostać zaimplementowany w celu akceptowania i stosowania wyodrębnionych filtrów.
Oprócz ponownego zapisywania i wyodrębniania filtrów zapytań należy pamiętać o tym, czy używać jednego wywołania LLM, czy wielu wywołań. Podczas korzystania z jednego wywołania z starannie spreparowany monit może być wydajny, istnieją przypadki, w których podział procesu zrozumienia zapytania na wiele wywołań LLM może prowadzić do lepszych wyników. W ten sposób jest to ogólnie odpowiednia reguła kciuka, gdy próbujesz zaimplementować szereg złożonych kroków logiki w jednym wierszu polecenia.
Na przykład można użyć jednego wywołania LLM do sklasyfikowania intencji zapytania, innego w celu wyodrębnienia odpowiednich jednostek, a trzeci do ponownego zapisania zapytania na podstawie wyodrębnionych informacji. Mimo że takie podejście może spowodować pewne opóźnienie do ogólnego procesu, może zapewnić bardziej szczegółową kontrolę i potencjalnie poprawić jakość pobranych dokumentów.
Opis zapytań wieloetapowych dla bota pomocy technicznej
Oto, jak składnik rozumienia zapytań wieloetapowych może szukać bota pomocy technicznej klienta:
- Klasyfikacja intencji: użyj usługi LLM, aby sklasyfikować zapytanie użytkownika w wstępnie zdefiniowane kategorie, takie jak "informacje o produkcie", "rozwiązywanie problemów" lub "zarządzanie kontami".
- Wyodrębnianie jednostek: na podstawie zidentyfikowanej intencji użyj innego wywołania LLM, aby wyodrębnić odpowiednie jednostki z zapytania, takie jak nazwy produktów, zgłoszone błędy lub numery kont.
- Ponowne zapisywanie zapytań: Użyj wyodrębnionej intencji i jednostek, aby ponownie zapisać oryginalne zapytanie w bardziej szczegółowy i docelowy format, na przykład "My RAG chain is fail to deploy on Model Serving, widzę następujący błąd...".
Pobieranie
Składnik pobierania łańcucha RAG jest odpowiedzialny za znalezienie najbardziej odpowiednich fragmentów informacji podanych w zapytaniu pobierania. W kontekście danych bez struktury pobieranie zwykle obejmuje jedną lub kombinację wyszukiwania semantycznego, wyszukiwania opartego na słowach kluczowych i filtrowania metadanych. Wybór strategii pobierania zależy od konkretnych wymagań aplikacji, charakteru danych i typów zapytań, które mają być obsługiwane. Porównajmy następujące opcje:
- Wyszukiwanie semantyczne: wyszukiwanie semantyczne używa modelu osadzania w celu przekonwertowania każdego fragmentu tekstu na reprezentację wektorową, która przechwytuje jego znaczenie semantyczne. Porównując wektorowa reprezentację zapytania pobierania z reprezentacją wektorów fragmentów, wyszukiwanie semantyczne może pobierać koncepcyjnie podobne dokumenty, nawet jeśli nie zawierają dokładnych słów kluczowych z zapytania.
- Wyszukiwanie oparte na słowach kluczowych: wyszukiwanie oparte na słowach kluczowych określa istotność dokumentów, analizując częstotliwość i rozkład udostępnionych wyrazów między zapytaniem pobierania a indeksowanym dokumentem. Im częściej te same słowa pojawiają się zarówno w zapytaniu, jak i w dokumencie, tym większa jest ocena istotności przypisana do tego dokumentu.
- Wyszukiwanie hybrydowe: wyszukiwanie hybrydowe łączy mocne strony wyszukiwania semantycznego i opartego na słowach kluczowych, stosując proces pobierania dwuetapowego. Najpierw wykonuje wyszukiwanie semantyczne w celu pobrania zestawu koncepcyjnie odpowiednich dokumentów. Następnie stosuje wyszukiwanie oparte na słowach kluczowych na podstawie tego ograniczonego zestawu w celu dalszego uściślenia wyników na podstawie dokładnych dopasowań słów kluczowych. Na koniec łączy wyniki z obu kroków, aby sklasyfikować dokumenty.
Porównanie strategii pobierania
W poniższej tabeli przedstawiono porównanie każdej z tych strategii pobierania względem siebie:
| Wyszukiwanie semantyczne | Wyszukiwanie wg słów kluczowych | Wyszukiwanie hybrydowe | |
|---|---|---|---|
| Proste wyjaśnienie | Jeśli te same pojęcia pojawiają się w zapytaniu i potencjalnym dokumencie, są one istotne. | Jeśli te same słowa pojawiają się w zapytaniu i potencjalnym dokumencie, są one istotne. Więcej słów z zapytania w dokumencie, tym bardziej istotne jest to, że dokument. | Uruchamia zarówno wyszukiwanie semantyczne, jak i wyszukiwanie słów kluczowych, a następnie łączy wyniki. |
| Przykładowy przypadek użycia | Obsługa klienta, w której zapytania użytkowników różnią się od słów w podręcznikach produktu. Przykład: "jak mogę włączyć mój telefon?" a sekcja ręczna jest nazywana "przełączaniem zasilania". | Obsługa klienta, w której zapytania zawierają określone, nieopisowe terminy techniczne. Przykład: "co robi model HD7-8D?" | Zapytania obsługi klienta, które połączyły zarówno semantyczne, jak i techniczne terminy. Przykład: "jak mogę włączyć moją usługę HD7-8D?" |
| Podejścia techniczne | Używa osadzania do reprezentowania tekstu w ciągłej przestrzeni wektorowej, umożliwiając wyszukiwanie semantyczne. | Opiera się na dyskretnych metodach opartych na tokenach, takich jak bag-of-words, TF-IDF, BM25 na potrzeby dopasowywania słów kluczowych. | Użyj podejścia do ponownego klasyfikowania, aby połączyć wyniki, takie jak wzajemne łączenie rangi lub model ponownego klasyfikowania. |
| Mocnych | Pobieranie kontekstowo podobnych informacji do zapytania, nawet jeśli dokładne wyrazy nie są używane. | Scenariusze wymagające dokładnych dopasowań słów kluczowych, idealne dla konkretnych zapytań ukierunkowanych na terminy, takich jak nazwy produktów. | Łączy najlepsze z obu podejść. |
Sposoby ulepszania procesu pobierania
Oprócz tych podstawowych strategii pobierania istnieje kilka technik, które można zastosować w celu dalszego ulepszania procesu pobierania:
- Rozszerzanie zapytań: rozszerzenie zapytania może pomóc w przechwyceniu szerszego zakresu odpowiednich dokumentów przy użyciu wielu odmian zapytania pobierania. Można to osiągnąć przez przeprowadzenie poszczególnych wyszukiwań dla każdego rozszerzonego zapytania lub użycie łączenia wszystkich rozszerzonych zapytań wyszukiwania w jednym zapytaniu pobierania.
Uwaga
Rozszerzanie zapytań należy wykonać w połączeniu ze zmianami w składniku rozumienia zapytań (łańcuch RAG). Wiele odmian zapytania pobierania jest zwykle generowanych w tym kroku.
- Ponowne klasyfikowanie: po pobraniu początkowego zestawu fragmentów zastosuj dodatkowe kryteria klasyfikacji (na przykład sortuj według czasu) lub model ponownego sortowania, aby ponownie uporządkować wyniki. Ponowne klasyfikowanie może pomóc w określaniu priorytetów najbardziej odpowiednich fragmentów, biorąc pod uwagę określone zapytanie pobierania. Ponowne korbowanie za pomocą modeli cross-encoder, takich jak mxbai-rerank i ColBERTv2 może przynieść wzrost wydajności pobierania.
- Filtrowanie metadanych: użyj filtrów metadanych wyodrębnionych z kroku zrozumienia zapytania, aby zawęzić przestrzeń wyszukiwania na podstawie określonych kryteriów. Filtry metadanych mogą zawierać atrybuty, takie jak typ dokumentu, data utworzenia, autor lub tagi specyficzne dla domeny. Łącząc filtry metadanych z wyszukiwaniem semantycznym lub opartym na słowach kluczowych, można utworzyć bardziej ukierunkowane i wydajne pobieranie.
Uwaga
Filtrowanie metadanych należy wykonać w połączeniu ze zmianami składników analizy zapytań (łańcuch RAG) i wyodrębniania metadanych (potoku danych).
Monitowanie o rozszerzenie
Monitowanie rozszerzone to krok, w którym zapytanie użytkownika jest łączone z pobranymi informacjami i instrukcjami w szablonie monitu, aby pokierować modelem języka w kierunku generowania odpowiedzi o wysokiej jakości. Iterowanie na tym szablonie w celu zoptymalizowania monitu dostarczonego do inżynierii monitu LLM (AKA prompt engineering) jest wymagane, aby upewnić się, że model jest kierowany do tworzenia dokładnych, uziemionych i spójnych odpowiedzi.
Istnieją wszystkie przewodniki dotyczące monitowania inżynieryjnego, ale poniżej przedstawiono kilka zagadnień, które należy wziąć pod uwagę podczas iteracji w szablonie monitu:
- Przykłady
- Dołącz przykłady dobrze sformułowanych zapytań i odpowiadających im idealnych odpowiedzi w ramach samego szablonu monitu (uczenie kilku strzałów). Ułatwia to modelowi zrozumienie żądanego formatu, stylu i zawartości odpowiedzi.
- Jednym z przydatnych sposobów wymyślenia dobrych przykładów jest zidentyfikowanie typów zapytań, z których ma się zmagać łańcuch. Utwórz odpowiedzi ze standardem złotym dla tych zapytań i dołącz je jako przykłady w wierszu polecenia.
- Upewnij się, że podane przykłady są reprezentatywne dla zapytań użytkowników, które przewidujesz w czasie wnioskowania. Staraj się obejmować zróżnicowany zakres oczekiwanych zapytań, aby ułatwić uogólnianie modelu.
- Parametryzowanie szablonu monitu
- Zaprojektuj szablon monitu, aby był elastyczny, parametryzując go w celu uwzględnienia dodatkowych informacji poza pobranymi danymi i zapytaniem użytkownika. Mogą to być zmienne, takie jak bieżąca data, kontekst użytkownika lub inne istotne metadane.
- Wstrzykiwanie tych zmiennych do monitu w czasie wnioskowania może włączyć bardziej spersonalizowane lub kontekstowe odpowiedzi.
- Rozważ monitowanie o łańcuch myśli
- W przypadku złożonych zapytań, w których bezpośrednie odpowiedzi nie są łatwo widoczne, należy rozważyć monitowanie łańcucha myśli (CoT). Ta strategia inżynieryjna monitu dzieli skomplikowane pytania na prostsze, sekwencyjne kroki, prowadząc llM przez logiczny proces rozumowania.
- Monitując model o "przemyślenie problemu krok po kroku", zachęcamy go do udostępnienia bardziej szczegółowych i dobrze przemyślanych odpowiedzi, które mogą być szczególnie skuteczne w przypadku obsługi zapytań wieloetapowych lub otwartych.
- Monity mogą nie być przenoszone między modelami
- Zdaj sobie sprawę, że monity często nie są bezproblemowo przesyłane między różnymi modelami językowymi. Każdy model ma własne unikatowe cechy, w których monit, który działa dobrze dla jednego modelu, może nie być tak skuteczny dla innego.
- Poeksperymentuj z różnymi formatami i długościami monitów, zapoznaj się z przewodnikami online (takimi jak Książka kucharka OpenAI, książka kucharka antropotyczna) i przygotuj się do dostosowywania i uściślinia monitów podczas przełączania się między modelami.
LLM
Składnik generowania łańcucha RAG pobiera rozszerzony szablon monitu z poprzedniego kroku i przekazuje go do modułu LLM. Podczas wybierania i optymalizowania modułu LLM dla składnika generowania łańcucha RAG należy wziąć pod uwagę następujące czynniki, które mają równie zastosowanie do innych kroków obejmujących wywołania LLM:
- Eksperymentuj z różnymi modelami gotowymi.
- Każdy model ma własne unikatowe właściwości, mocne i słabe strony. Niektóre modele mogą lepiej zrozumieć niektóre domeny lub lepiej wykonywać określone zadania.
- Jak wspomniano wcześniej, należy pamiętać, że wybór modelu może również mieć wpływ na proces inżynierii monitu, ponieważ różne modele mogą reagować inaczej na te same monity.
- Jeśli w łańcuchu istnieje wiele kroków wymagających usługi LLM, takich jak wywołania do zrozumienia zapytań oprócz kroku generowania, rozważ użycie różnych modeli dla różnych kroków. Droższe modele ogólnego przeznaczenia mogą być zbyt kosztowne dla zadań, takich jak określanie intencji zapytania użytkownika.
- Uruchom małe i skalowane w górę zgodnie z potrzebami.
- Chociaż może to być kuszące, aby natychmiast dotrzeć do najbardziej zaawansowanych i zdolnych modeli (np. GPT-4, Claude), często bardziej wydajne jest rozpoczęcie od mniejszych, bardziej lekkich modeli.
- W wielu przypadkach mniejsze alternatywy typu open source, takie jak Llama 3 lub DBRX, mogą zapewnić zadowalające wyniki przy niższych kosztach i krótszych czasach wnioskowania. Modele te mogą być szczególnie skuteczne w przypadku zadań, które nie wymagają bardzo złożonej rozumowania ani rozległej wiedzy na temat świata.
- Podczas opracowywania i uściślenia łańcucha RAG stale oceniasz wydajność i ograniczenia wybranego modelu. Jeśli okaże się, że model zmaga się z pewnymi typami zapytań lub nie dostarcza wystarczająco szczegółowych lub dokładnych odpowiedzi, rozważ skalowanie w górę do bardziej zdolnego modelu.
- Monitoruj wpływ zmieniających się modeli na kluczowe metryki, takie jak jakość odpowiedzi, opóźnienie i koszty, aby upewnić się, że masz właściwą równowagę dla wymagań konkretnego przypadku użycia.
- Optymalizowanie parametrów modelu
- Poeksperymentuj z różnymi ustawieniami parametrów, aby znaleźć optymalną równowagę między jakością odpowiedzi, różnorodnością i spójnością. Na przykład dostosowanie temperatury może kontrolować losowość wygenerowanego tekstu, a max_tokens może ograniczyć długość odpowiedzi.
- Należy pamiętać, że optymalne ustawienia parametrów mogą się różnić w zależności od określonego zadania, monitu i żądanego stylu danych wyjściowych. Iteracyjne testowanie i uściślinie tych ustawień na podstawie oceny wygenerowanych odpowiedzi.
- Dostrajanie specyficzne dla zadania
- W miarę uściślinia wydajności rozważ precyzyjne dostrajanie mniejszych modeli dla określonych podzadania w łańcuchu RAG, takich jak interpretacja zapytań.
- Trenowanie wyspecjalizowanych modeli dla poszczególnych zadań za pomocą łańcucha RAG może potencjalnie poprawić ogólną wydajność, zmniejszyć opóźnienia i niższe koszty wnioskowania w porównaniu z użyciem jednego dużego modelu dla wszystkich zadań.
- Dalsze wstępne szkolenie
- Jeśli aplikacja RAG zajmuje się wyspecjalizowaną domeną lub wymaga wiedzy, która nie jest dobrze reprezentowana w wstępnie wytrenowanym module LLM, rozważ wykonanie ciągłego wstępnego trenowania (CPT) na danych specyficznych dla domeny.
- Dalsze wstępne szkolenie może poprawić zrozumienie konkretnej terminologii lub pojęć specyficznych dla danej domeny. Z kolei może to zmniejszyć potrzebę szerokiej inżynierii monitów lub kilku strzałów przykłady.
Po przetworzeniu i zabezpieczeniach
Po wygenerowaniu odpowiedzi w usłudze LLM często konieczne jest zastosowanie technik przetwarzania końcowego lub barier zabezpieczających w celu zapewnienia, że dane wyjściowe spełniają wymagania dotyczące żądanego formatu, stylu i zawartości. Ten ostatni krok (lub wiele kroków) w łańcuchu może pomóc zachować spójność i jakość wygenerowanych odpowiedzi. Jeśli implementujesz zabezpieczenia po przetwarzaniu i zabezpieczeniach, rozważ następujące kwestie:
- Wymuszanie formatu danych wyjściowych
- W zależności od przypadku użycia mogą być wymagane wygenerowane odpowiedzi zgodne z określonym formatem, takim jak szablon ustrukturyzowany lub określony typ pliku (np. JSON, HTML, Markdown itd.).
- Jeśli wymagane jest ustrukturyzowane dane wyjściowe, biblioteki, takie jak Instruktor lub Konspekt, zapewniają dobre punkty wyjścia do zaimplementowania tego rodzaju kroku weryfikacji.
- Podczas opracowywania należy zająć trochę czasu, aby upewnić się, że krok przetwarzania końcowego jest wystarczająco elastyczny, aby obsługiwać zmiany w wygenerowanych odpowiedziach przy zachowaniu wymaganego formatu.
- Utrzymywanie spójności stylu
- Jeśli aplikacja RAG ma określone wytyczne dotyczące stylu lub wymagania dotyczące tonu (np. formalne i przypadkowe, zwięzłe a szczegółowe), krok przetwarzania końcowego może zarówno sprawdzać, jak i wymuszać te atrybuty stylu w wygenerowanych odpowiedziach.
- Filtry zawartości i bariery zabezpieczające
- W zależności od charakteru aplikacji RAG i potencjalnego ryzyka związanego z wygenerowaną zawartością może być ważne zaimplementowanie filtrów zawartości lub barier bezpieczeństwa, aby zapobiec wystąpieniu nieodpowiednich, obraźliwych lub szkodliwych informacji.
- Rozważ użycie modeli, takich jak Llama Guard lub interfejsy API specjalnie zaprojektowane pod kątem kon tryb namiotu ration i bezpieczeństwa, takich jak interfejs API moderowania openAI, w celu zaimplementowania barier bezpieczeństwa.
- Obsługa halucynacji
- Obrona przed halucynacjami można również zaimplementować jako krok przetwarzania końcowego. Może to obejmować krzyżowe odwoływanie się do wygenerowanych danych wyjściowych z pobranymi dokumentami lub użycie dodatkowych modułów LLM w celu zweryfikowania faktycznej dokładności odpowiedzi.
- Opracowywanie mechanizmów rezerwowych do obsługi przypadków, w których wygenerowana odpowiedź nie spełnia wymagań dotyczących dokładności faktów, takich jak generowanie alternatywnych odpowiedzi lub dostarczanie odpowiedzialności użytkownikowi.
- Obsługa błędów
- W przypadku wszystkich kroków przetwarzania końcowego zaimplementuj mechanizmy, aby bezpiecznie poradzić sobie z przypadkami, w których krok napotka problem lub nie wygeneruje zadowalającej odpowiedzi. Może to obejmować wygenerowanie domyślnej odpowiedzi lub eskalację problemu do operatora ludzkiego w celu ręcznego przeglądu.