Wymaganie wstępne: Zbieranie wymagań
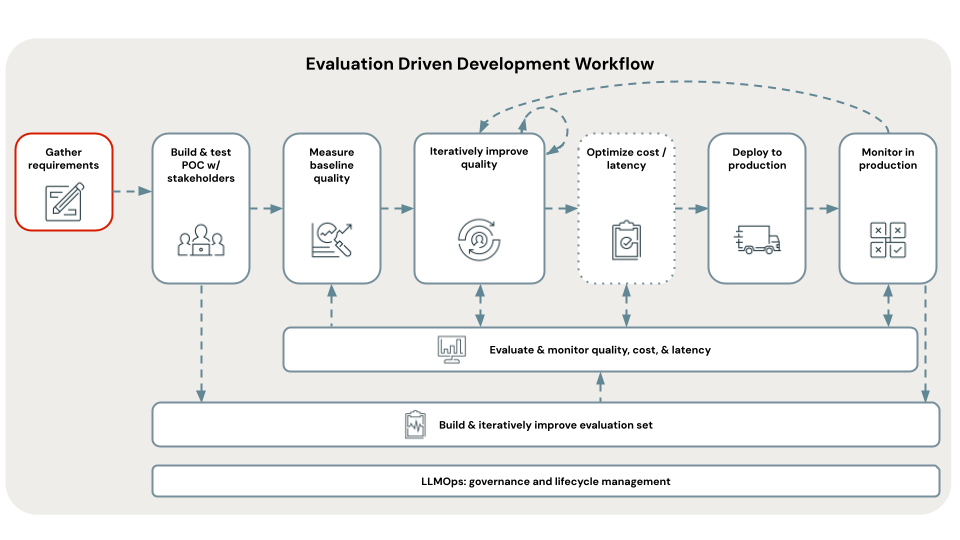
Definiowanie jasnych i kompleksowych wymagań przypadków użycia jest kluczowym pierwszym krokiem w tworzeniu pomyślnej aplikacji RAG. Te wymagania służą dwóm podstawowym celom. Po pierwsze, pomagają określić, czy RAG jest najbardziej odpowiednim podejściem dla danego przypadku użycia. Jeśli funkcja RAG jest rzeczywiście dobrym rozwiązaniem, te wymagania zawierają wskazówki dotyczące projektowania, wdrażania i podejmowania decyzji dotyczących oceny. Inwestowanie czasu na początku projektu w celu zebrania szczegółowych wymagań może zapobiec znaczącym wyzwaniom i porażkom w dalszej części procesu opracowywania oraz zapewnić, że wynikowe rozwiązanie spełnia potrzeby użytkowników końcowych i uczestników projektu. Dobrze zdefiniowane wymagania stanowią podstawę kolejnych etapów cyklu projektowania, które omówimy.
Zobacz repozytorium GitHub, aby zapoznać się z przykładowym kodem w tej sekcji. Możesz również użyć kodu repozytorium jako szablonu, za pomocą którego można tworzyć własne aplikacje sztucznej inteligencji.
Czy przypadek użycia jest dobrym rozwiązaniem dla RAG?
Pierwszą rzeczą, którą należy ustalić, jest to, czy RAG jest nawet właściwym podejściem do twojego przypadku użycia. Biorąc pod uwagę szum wokół RAG, kuszące jest, aby zobaczyć go jako możliwe rozwiązanie dowolnego problemu. Istnieją jednak niuanse, kiedy RAG jest odpowiedni, a nie.
RAG jest dobrym rozwiązaniem, gdy:
- Wnioskowanie o pobranych informacjach (zarówno bez struktury, jak i ze strukturą), które nie mieszczą się całkowicie w oknie kontekstowym llM
- Synchronizowanie informacji z wielu źródeł (na przykład generowanie podsumowania kluczowych punktów z różnych artykułów w temacie)
- Pobieranie dynamiczne na podstawie zapytania użytkownika jest niezbędne (na przykład w przypadku zapytania użytkownika określ źródło danych do pobrania)
- Przypadek użycia wymaga wygenerowania nowej zawartości na podstawie pobranych informacji (na przykład odpowiadanie na pytania, dostarczanie wyjaśnień, oferowanie rekomendacji)
Rag może nie być najlepszym rozwiązaniem, gdy:
- Zadanie nie wymaga pobierania specyficznego dla zapytania. Na przykład generowanie podsumowań transkrypcji wywołań; nawet jeśli poszczególne transkrypcje są dostarczane jako kontekst w wierszu polecenia LLM, pobrane informacje pozostają takie same dla każdego podsumowania.
- Cały zestaw informacji do pobrania może mieścić się w oknie kontekstowym llM
- Wymagane są bardzo małe opóźnienia odpowiedzi (na przykład gdy odpowiedzi są wymagane w milisekundach)
- Proste odpowiedzi oparte na regułach lub szablonach są wystarczające (na przykład czatbot pomocy technicznej klienta, który udostępnia wstępnie zdefiniowane odpowiedzi na podstawie słów kluczowych)
Wymagania dotyczące odnajdywania
Po ustaleniu, że rag jest dobrym rozwiązaniem dla twojego przypadku użycia, należy wziąć pod uwagę następujące pytania, aby uchwycić konkretne wymagania. Wymagania są priorytetowe w następujący sposób:
🟢 P0: Przed rozpoczęciem weryfikacji koncepcji należy zdefiniować to wymaganie.
🟡 P1: Należy zdefiniować przed przejściem do środowiska produkcyjnego, ale może iteracyjne uściślić podczas weryfikacji koncepcji.
⚪ P2: Nicea, aby mieć wymóg.
Nie jest to wyczerpująca lista pytań. Jednak powinno to stanowić solidną podstawę do przechwytywania kluczowych wymagań dotyczących rozwiązania RAG.
Środowisko użytkownika
Definiowanie sposobu interakcji użytkowników z systemem RAG i oczekiwanego rodzaju odpowiedzi
🟢 [P0] Jak będzie wyglądać typowe żądanie łańcucha RAG? Poproś uczestników projektu o przykłady potencjalnych zapytań użytkowników.
🟢 [P0] Jakiego rodzaju odpowiedzi będą oczekiwać użytkownicy (krótkie odpowiedzi, długie wyjaśnienia, kombinacja lub coś innego)?
🟡 [P1] Jak użytkownicy będą korzystać z systemu? Za pośrednictwem interfejsu czatu, paska wyszukiwania lub innej modalności?
🟡 [P1] ton kapelusza lub styl powinny zostać wygenerowane odpowiedzi? (formalne, konwersacyjne, techniczne?)
🟡 [P1] Jak aplikacja powinna obsługiwać niejednoznaczne, niekompletne lub nieistotne zapytania? Czy w takich przypadkach należy przekazać jakąkolwiek formę opinii lub wskazówek?
⚪ [P2] Czy istnieją określone wymagania dotyczące formatowania lub prezentacji dla wygenerowanych danych wyjściowych? Czy dane wyjściowe powinny zawierać wszelkie metadane oprócz odpowiedzi łańcucha?
Data
Określ charakter, źródła i jakość danych, które będą używane w rozwiązaniu RAG.
🟢 [P0] Jakie źródła mają być używane?
Dla każdego źródła danych:
- 🟢 [P0] Czy dane są ustrukturyzowane czy nieustrukturyzowane?
- 🟢 [P0] Jaki jest format źródłowy danych pobierania (np. pliki PDF, dokumentacja z obrazami/tabelami, ustrukturyzowane odpowiedzi interfejsu API)?
- 🟢 [P0] Gdzie znajdują się te dane?
- 🟢 [P0] Ile danych jest dostępnych?
- 🟡 [P1] Jak często są aktualizowane dane? Jak należy obsługiwać te aktualizacje?
- 🟡 [P1] Czy istnieją znane problemy z jakością danych lub niespójności dla każdego źródła danych?
Rozważ utworzenie tabeli spisu, aby skonsolidować te informacje, na przykład:
| Źródło danych | Źródło | Typy plików | Rozmiar | Częstotliwość aktualizacji |
|---|---|---|---|---|
| Źródło danych 1 | Wolumin wykazu aparatu Unity | JSON | 10 GB | Codziennie |
| Źródło danych 2 | Publiczny interfejs API | XML | NA (INTERFEJS API) | W czasie rzeczywistym |
| Źródło danych 3 | SharePoint | PDF, .docx | 500 MB | Co miesiąc |
Ograniczenia wydajności
Przechwyć wymagania dotyczące wydajności i zasobów aplikacji RAG.
🟡 [P1] Jakie jest maksymalne dopuszczalne opóźnienie generowania odpowiedzi?
🟡 [P1] Jaki jest maksymalny dopuszczalny czas pierwszego tokenu?
🟡 [P1] Jeśli dane wyjściowe są przesyłane strumieniowo, czy dopuszczalne jest większe całkowite opóźnienie?
🟡 [P1] Czy istnieją ograniczenia kosztów dotyczące zasobów obliczeniowych dostępnych do wnioskowania?
🟡 [P1] Jakie są oczekiwane wzorce użycia i szczytowe obciążenia?
🟡 [P1] Ilu równoczesnych użytkowników lub żądań powinno być w stanie obsłużyć system? Usługa Databricks natywnie obsługuje takie wymagania dotyczące skalowalności, dzięki możliwości automatycznego skalowania za pomocą funkcji obsługi modelu.
Ocena
Ustal, w jaki sposób rozwiązanie RAG będzie oceniane i ulepszane w czasie.
🟢 [P0] Jaki jest cel biznesowy/kluczowy wskaźnik wydajności, na który chcesz mieć wpływ? Jaka jest wartość punktu odniesienia i jaki jest cel?
🟢 [P0] Którzy użytkownicy lub uczestnicy projektu przekażą wstępne i bieżące opinie?
🟢 [P0] Jakich metryk należy użyć do oceny jakości wygenerowanych odpowiedzi? Ocena agenta mozaiki sztucznej inteligencji udostępnia zalecany zestaw metryk do użycia.
🟡 [P1] Jaki jest zestaw pytań, które aplikacja RAG musi być dobra, aby przejść do środowiska produkcyjnego?
🟡 [P1] Czy [zestaw oceny] istnieje? Czy można uzyskać zestaw ewaluacyjnych zapytań użytkownika wraz z odpowiedziami na podstawowe informacje i (opcjonalnie) prawidłowymi dokumentami pomocniczymi, które powinny zostać pobrane?
🟡 [P1] W jaki sposób opinia użytkowników zostanie zebrana i włączona do systemu?
Zabezpieczenia
Zidentyfikuj wszelkie zagadnienia dotyczące zabezpieczeń i prywatności.
🟢 [P0] Czy istnieją poufne/poufne dane, które muszą być obsługiwane z troską?
🟡 [P1] Czy w rozwiązaniu należy zaimplementować mechanizmy kontroli dostępu (na przykład dany użytkownik może pobierać tylko z ograniczonego zestawu dokumentów)?
Wdrożenie
Zrozumienie sposobu, w jaki rozwiązanie RAG zostanie zintegrowane, wdrożone i utrzymane.
🟡 Jak rozwiązanie RAG powinno być zintegrowane z istniejącymi systemami i przepływami pracy?
🟡 Jak należy wdrożyć, skalować i wersjonować model? W tym samouczku opisano sposób obsługi kompleksowego cyklu życia w usłudze Databricks przy użyciu biblioteki MLflow, katalogu aparatu Unity, zestawu SDK agenta i obsługi modelu.
Przykład
Rozważmy na przykład zastosowanie tych pytań do tej przykładowej aplikacji RAG używanej przez zespół pomocy technicznej klienta usługi Databricks:
| Obszar | Kwestie wymagające rozważenia | Wymagania |
|---|---|---|
| Środowisko użytkownika | - Modalność interakcji. — Typowe przykłady zapytań użytkowników. — Oczekiwany format odpowiedzi i styl. - Obsługa niejednoznacznych lub nieistotnych zapytań. |
- Interfejs czatu zintegrowany z usługą Slack. — Przykładowe zapytania: "Jak mogę skrócić czas uruchamiania klastra?" "Jakiego rodzaju plan pomocy technicznej mam?" - Jasne, techniczne odpowiedzi z fragmentami kodu i linki do odpowiedniej dokumentacji tam, gdzie jest to konieczne. — Podaj kontekstowe sugestie i eskaluj je do inżynierów pomocy technicznej, gdy jest to konieczne. |
| Data | - Liczba i typ źródeł danych. - Format danych i lokalizacja. — Rozmiar danych i częstotliwość aktualizacji. - Jakość i spójność danych. |
- Trzy źródła danych. — Dokumentacja firmy (HTML, PDF). - Rozwiązano bilety pomocy technicznej (JSON). - Wpisy na forum społeczności (tabela delta). — Dane przechowywane w wykazie aparatu Unity i aktualizowane co tydzień. - Całkowity rozmiar danych: 5 GB. - Spójna struktura danych i jakość utrzymywana przez dedykowane zespoły docs i pomocy technicznej. |
| Wydajność | - Maksymalne dopuszczalne opóźnienie. - Ograniczenia kosztów. — Oczekiwane użycie i współbieżność. |
— Wymaganie dotyczące maksymalnego opóźnienia. - Ograniczenia kosztów. — Oczekiwane obciążenie szczytowe. |
| Ocena | — Dostępność zestawu danych oceny. - Metryki jakości. — Zbieranie opinii użytkowników. |
— Eksperci z poszczególnych obszarów produktów pomagają przeglądać dane wyjściowe i dostosowywać niepoprawne odpowiedzi, aby utworzyć zestaw danych oceny. - Wskaźniki KPI biznesowe. - Zwiększenie współczynnika rozwiązywania biletów pomocy technicznej. - Zmniejszenie czasu spędzonego przez użytkownika na bilet pomocy technicznej. - Metryki jakości. - Oceniana przez LLM poprawność i istotność odpowiedzi. - Sędziowie LLM pobierają precyzję. - Upvote lub downvote użytkownika. - Zbieranie opinii. - Slack będzie instrumentowany, aby zapewnić kciuki w górę / w dół. |
| Zabezpieczenia | - Obsługa danych poufnych. - Wymagania dotyczące kontroli dostępu. |
— Żadne poufne dane klientów nie powinny znajdować się w źródle pobierania. — Uwierzytelnianie użytkowników za pośrednictwem logowania jednokrotnego społeczności usługi Databricks. |
| Wdrożenie | - Integracja z istniejącymi systemami. — Wdrażanie i przechowywanie wersji. |
— Integracja z systemem biletów pomocy technicznej. — Łańcuch wdrożony jako punkt końcowy obsługujący model usługi Databricks. |
Następny krok
Wprowadzenie do kroku 1. Sklonuj repozytorium kodu i utwórz obliczenia.
< Poprzedni: Programowanie oparte na ocenie
Dalej: Krok 1. Klonowanie repozytorium i tworzenie zasobów obliczeniowych >