Poprawianie jakości aplikacji RAG
Ten artykuł zawiera omówienie sposobu uściślinia poszczególnych składników w celu zwiększenia jakości aplikacji rozszerzonej generacji (RAG).
Istnieją niezliczone "pokrętła", które można dostroić w każdym momencie zarówno w potoku danych offline, jak i w łańcuchu RAG online. Chociaż istnieje niezliczona liczba innych, artykuł koncentruje się na najważniejszych pokrętłach, które mają największy wpływ na jakość aplikacji RAG. Usługa Databricks zaleca rozpoczęcie od tych pokrętł.
Dwa typy zagadnień dotyczących jakości
Z punktu widzenia koncepcyjnego warto wyświetlić pokrętła jakości RAG za pomocą obiektywu dwóch kluczowych typów problemów z jakością:
Jakość pobierania: czy pobierasz najbardziej istotne informacje dla danego zapytania pobierania?
Trudno jest wygenerować wysokiej jakości dane wyjściowe RAG, jeśli kontekst podany w usłudze LLM nie zawiera ważnych informacji lub zawiera zbędne informacje.
Jakość generowania: biorąc pod uwagę pobrane informacje i oryginalne zapytanie użytkownika, czy llM generuje najdokładniejsze, spójne i przydatne odpowiedzi możliwe?
W tym miejscu problemy mogą manifestować się jako halucynacje, niespójne dane wyjściowe lub brak bezpośredniego rozwiązywania problemów z zapytaniem użytkownika.
Aplikacje RAG mają dwa składniki, które można iterować, aby sprostać wyzwaniom związanym z jakością: potokiem danych i łańcuchem. Kuszące jest założenie, że istnieje wyraźny podział między problemami z pobieraniem (wystarczy zaktualizować pipeline danych) a problemami z generowaniem (zaktualizuj łańcuch RAG). Jednak rzeczywistość jest bardziej zniuansowana. Na jakość pobierania może mieć wpływ zarówno potok danych (na przykład strategia analizowania/fragmentowania, strategia metadanych, model osadzania) i łańcuch RAG (na przykład transformacja zapytania użytkownika, liczba pobranych fragmentów, ponowne klasyfikowanie). Podobnie jakość generowania będzie mieć niezmienny wpływ na słabe pobieranie (na przykład nieistotne lub brakujące informacje wpływające na dane wyjściowe modelu).
Nakłada się to na podkreślenie potrzeby holistycznego podejścia do poprawy jakości RAG. Zrozumienie, które składniki mają ulec zmianie zarówno w potoku danych, jak i w łańcuchu RAG, oraz o tym, jak te zmiany wpływają na ogólne rozwiązanie, można wprowadzić ukierunkowane aktualizacje w celu poprawy jakości danych wyjściowych RAG.
Zagadnienia dotyczące jakości potoku danych
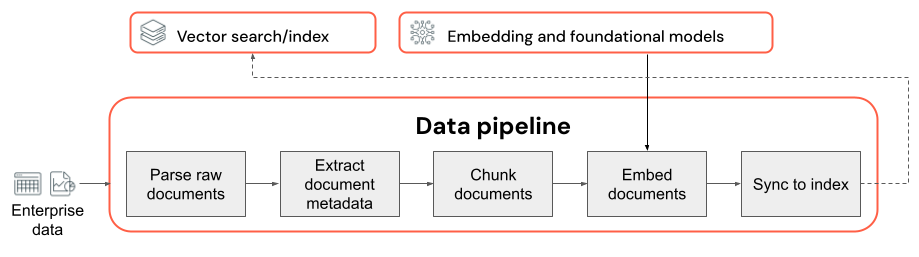
Kluczowe zagadnienia dotyczące potoku danych:
- Kompozycja danych wejściowych.
- Sposób wyodrębniania i przekształcania danych pierwotnych w format użyteczny (na przykład analizowanie dokumentu PDF).
- Sposób dzielenia dokumentów na mniejsze fragmenty i sposób formatowania tych fragmentów (na przykład strategii fragmentowania i rozmiaru fragmentów).
- Metadane (takie jak tytuł sekcji lub tytuł dokumentu) wyodrębnione z każdego dokumentu i/lub fragmentu. Sposób dołączania tych metadanych (lub nieuwzględniania) w poszczególnych fragmentach.
- Model osadzania używany do konwertowania tekstu na reprezentacje wektorowe na potrzeby wyszukiwania podobieństwa.
Łańcuch RAG
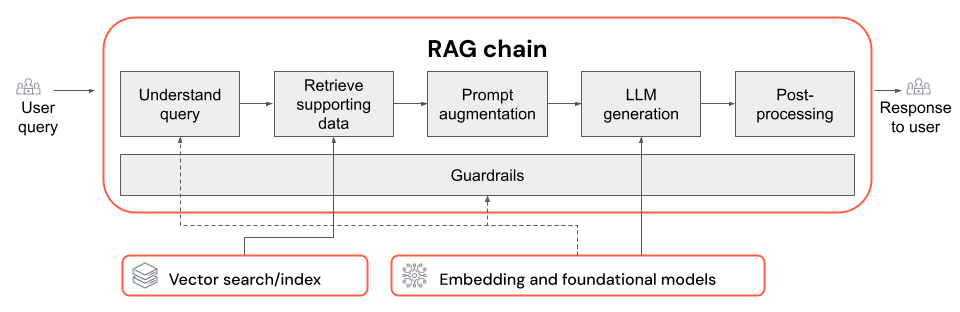
- Wybór funkcji LLM i jego parametrów (na przykład temperatury i maksymalne tokeny).
- Parametry pobierania (na przykład liczba pobranych fragmentów lub dokumentów).
- Metoda pobierania (na przykład słowo kluczowe a wyszukiwanie hybrydowe a semantyczne, ponowne zapisywanie zapytania użytkownika, przekształcanie zapytania użytkownika w filtry lub ponowne klasyfikowanie).
- Sposób formatowania monitu przy użyciu pobranego kontekstu w celu poprowadzenia funkcji LLM w kierunku danych wyjściowych dotyczących jakości.