Opis i kroki przetwarzania potoku danych RAG
W tym artykule dowiesz się więcej na temat przygotowywania danych bez struktury do użycia w aplikacjach RAG. Dane bez struktury odnoszą się do danych bez określonej struktury lub organizacji, takich jak dokumenty PDF, które mogą zawierać tekst i obrazy, lub zawartość multimedialną, taką jak audio lub wideo.
Dane bez struktury nie mają wstępnie zdefiniowanego modelu danych lub schematu, co uniemożliwia wykonywanie zapytań na podstawie samej struktury i metadanych. W związku z tym dane bez struktury wymagają technik, które mogą zrozumieć i wyodrębnić znaczenie semantyczne z nieprzetworzonego tekstu, obrazów, dźwięku lub innej zawartości.
Podczas przygotowywania danych potok danych aplikacji RAG pobiera nieprzetworzone dane bez struktury i przekształca je w dyskretne fragmenty, które mogą być odpytywane w oparciu o ich znaczenie dla zapytania użytkownika. Poniżej przedstawiono kluczowe kroki przetwarzania wstępnego przetwarzania danych. Każdy krok ma różne pokrętła, które można dostroić — aby dowiedzieć się więcej na temat tych pokręteł, zapoznaj się z tematem Poprawianie jakości aplikacji RAG.
Przygotowywanie danych bez struktury do pobierania
W pozostałej części tej sekcji opisano proces przygotowywania danych bez struktury do pobierania przy użyciu wyszukiwania semantycznego. Wyszukiwanie semantyczne rozumie kontekstowe znaczenie i intencję zapytania użytkownika w celu udostępnienia bardziej odpowiednich wyników wyszukiwania.
Wyszukiwanie semantyczne to jedno z kilku podejść, które można wykonać podczas implementowania składnika pobierania aplikacji RAG na danych bez struktury. Te dokumenty obejmują alternatywne strategie pobierania w sekcji pokrętła pobierania.
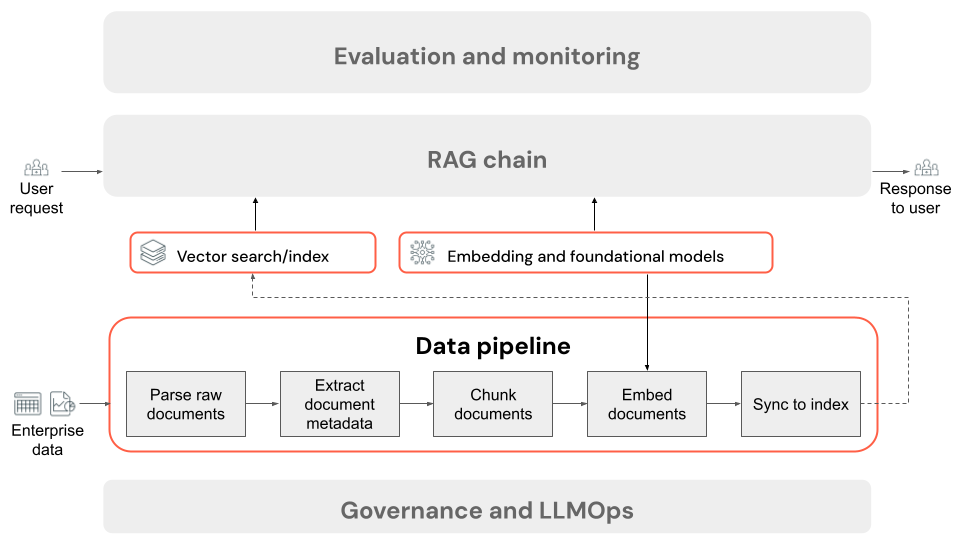
Kroki potoku danych aplikacji RAG
Poniżej przedstawiono typowe kroki potoku danych w aplikacji RAG przy użyciu danych bez struktury:
- Analizowanie nieprzetworzonych dokumentów: początkowy krok obejmuje przekształcanie danych pierwotnych w format użyteczny. Może to obejmować wyodrębnianie tekstu, tabel i obrazów z kolekcji plików PDF lub stosowanie technik optycznego rozpoznawania znaków (OCR) w celu wyodrębnienia tekstu z obrazów.
- Wyodrębnianie metadanych dokumentu (opcjonalnie):w niektórych przypadkach wyodrębnianie i używanie metadanych dokumentu, takich jak tytuły dokumentów, numery stron, adresy URL lub inne informacje, mogą pomóc w bardziej precyzyjnym kroku pobierania prawidłowych danych.
- Dokumenty fragmentów: aby upewnić się, że przeanalizowane dokumenty mogą mieścić się w modelu osadzania i oknie kontekstowym llM, dzielimy przeanalizowane dokumenty na mniejsze, dyskretne fragmenty. Pobieranie tych skoncentrowanych fragmentów, a nie całych dokumentów, zapewnia bardziej ukierunkowany kontekst LLM, z którego mają być generowane odpowiedzi.
- Osadzanie fragmentów: w aplikacji RAG korzystającej z wyszukiwania semantycznego specjalny typ modelu językowego nazywany modelem osadzania przekształca każdy fragment z poprzedniego kroku w wektory liczbowe lub listy liczb, które hermetyzują znaczenie każdego fragmentu zawartości. Co najważniejsze, te wektory reprezentują semantyczne znaczenie tekstu, a nie tylko słowa kluczowe na poziomie powierzchni. Umożliwia to wyszukiwanie na podstawie znaczenia, a nie dopasowania tekstu literału.
- Fragmenty indeksu w bazie danych wektorów: ostatnim krokiem jest załadowanie reprezentacji wektorowych fragmentów wraz z tekstem fragmentu do bazy danych wektorów. Baza danych wektorów to wyspecjalizowany typ bazy danych przeznaczony do wydajnego przechowywania i wyszukiwania danych wektorowych, takich jak osadzanie. Aby zachować wydajność przy dużej liczbie fragmentów, bazy danych wektorów często zawierają indeks wektorowy, który używa różnych algorytmów do organizowania i mapowania osadzania wektorów w sposób, który optymalizuje wydajność wyszukiwania. W czasie wykonywania zapytania żądanie użytkownika jest osadzone w wektorze, a baza danych korzysta z indeksu wektorowego, aby znaleźć najbardziej podobne wektory fragmentów, zwracając odpowiadające oryginalne fragmenty tekstu.
Proces przetwarzania podobieństwa może być kosztowny obliczeniowo. Indeksy wektorowe, takie jak wyszukiwanie wektorów usługi Databricks, przyspieszają ten proces, zapewniając mechanizm efektywnego organizowania i nawigowania po osadzaniu, często za pomocą zaawansowanych metod przybliżenia. Umożliwia to szybkie klasyfikowanie najbardziej odpowiednich wyników bez porównywania każdego osadzania z zapytaniem użytkownika indywidualnie.
Każdy krok w potoku danych obejmuje decyzje inżynieryjne wpływające na jakość aplikacji RAG. Na przykład wybranie odpowiedniego rozmiaru fragmentu w kroku 3 gwarantuje, że funkcja LLM odbiera określone, ale kontekstowe informacje, wybierając odpowiedni model osadzania w kroku 4, określa dokładność fragmentów zwracanych podczas pobierania.
Ten proces przygotowywania danych jest określany jako przygotowywanie danych w trybie offline, tak jak ma to miejsce przed odpowiedzią systemu na zapytania, w przeciwieństwie do kroków online wyzwalanych podczas przesyłania zapytania przez użytkownika.
Poprzednie: <: Podstawy RAG