Łańcuch RAG do wnioskowania
W tym artykule opisano proces, który występuje, gdy użytkownik przesyła żądanie do aplikacji RAG w ustawieniu online. Po przetworzeniu danych przez potok danych jest odpowiedni do użycia w aplikacji RAG. Seria lub łańcuch kroków wywoływanych w czasie wnioskowania jest często określany jako łańcuch RAG.
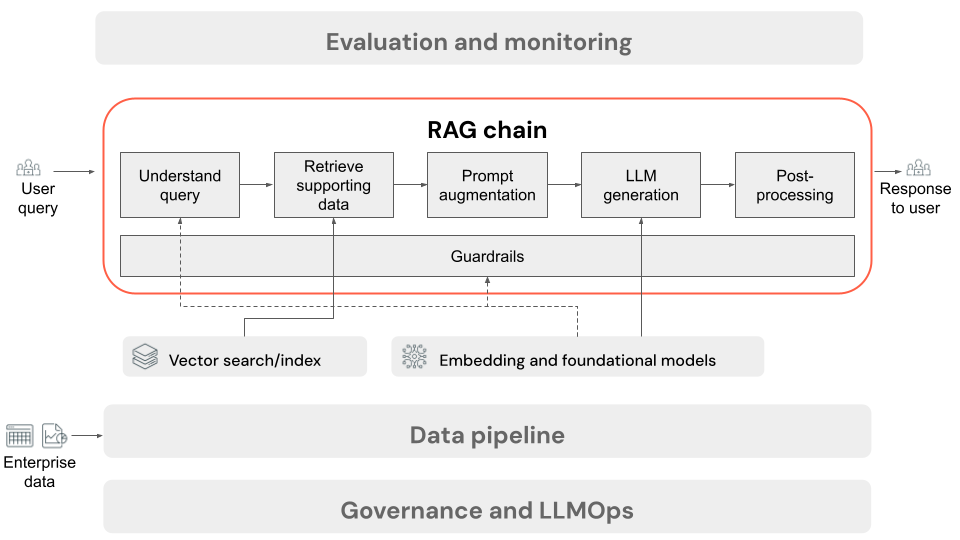
- (Opcjonalnie) Wstępne przetwarzanie zapytań użytkownika: w niektórych przypadkach zapytanie użytkownika jest wstępnie przetworzone, aby ułatwić wykonywanie zapytań względem bazy danych wektorów. Może to obejmować formatowanie zapytania w szablonie, użycie innego modelu do ponownego zapisania żądania lub wyodrębnienie słów kluczowych w celu pomocy w pobieraniu. Dane wyjściowe tego kroku to zapytanie pobierania, które będzie używane w kolejnym kroku pobierania.
- Pobieranie: aby pobrać informacje pomocnicze z bazy danych wektorów, zapytanie pobierania jest tłumaczone na osadzanie przy użyciu tego samego modelu osadzania, który został użyty do osadzania fragmentów dokumentu podczas przygotowywania danych. Te osadzania umożliwiają porównanie podobieństwa semantycznego między zapytaniem pobierania a fragmentami tekstu bez struktury przy użyciu miar, takich jak podobieństwo cosinus. Następnie fragmenty są pobierane z bazy danych wektorów i klasyfikowane na podstawie tego, jak podobne są do osadzonego żądania. Zwracane są pierwsze (najbardziej podobne) wyniki.
- Monitowanie rozszerzone: monit, który zostanie wysłany do usługi LLM, jest tworzony przez rozszerzenie zapytania użytkownika przy użyciu pobranego kontekstu, w szablonie, który instruuje model, jak używać każdego składnika, często z dodatkowymi instrukcjami dotyczącymi kontrolowania formatu odpowiedzi. Proces iteracji w odpowiednim szablonie monitu, który ma być używany, jest określany jako monit inżynieryjny.
- Generowanie llM: LLM przyjmuje rozszerzony monit, który obejmuje zapytanie użytkownika i pobiera dane pomocnicze jako dane wejściowe. Następnie generuje odpowiedź uziemiona w kontekście dodatkowym.
- (Opcjonalnie) Przetwarzanie końcowe: odpowiedź LLM może być przetwarzana dalej, aby zastosować dodatkową logikę biznesową, dodać cytaty lub w inny sposób uściślić wygenerowany tekst na podstawie wstępnie zdefiniowanych reguł lub ograniczeń.
Podobnie jak w przypadku potoku danych aplikacji RAG, istnieje wiele konsekwencji decyzji inżynieryjnych, które mogą mieć wpływ na jakość łańcucha RAG. Na przykład określenie liczby fragmentów do pobrania w kroku 2 i połączenia ich z zapytaniem użytkownika w kroku 3 może znacząco wpłynąć na zdolność modelu do generowania odpowiedzi dotyczących jakości.
W całym łańcuchu można zastosować różne zabezpieczenia w celu zapewnienia zgodności z zasadami przedsiębiorstwa. Może to obejmować filtrowanie odpowiednich żądań, sprawdzanie uprawnień użytkownika przed uzyskaniem dostępu do źródeł danych i stosowanie technik con tryb namiotu ration do wygenerowanych odpowiedzi.