Kopiowanie danych z usługi Azure Data Lake Storage Gen1 do generacji 2 za pomocą usługi Azure Data Factory
DOTYCZY: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Napiwek
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
Usługa Azure Data Lake Storage Gen2 to zestaw funkcji przeznaczonych do analizy danych big data wbudowanych w usługę Azure Blob Storage. Można ją wykorzystać do połączenia interfejsem z danymi przy użyciu zarówno paradygmatów systemu plików, jak i magazynu obiektów.
Jeśli obecnie używasz usługi Azure Data Lake Storage Gen1, możesz ocenić usługę Azure Data Lake Storage Gen2, kopiując dane z usługi Data Lake Storage Gen1 do generacji 2 przy użyciu usługi Azure Data Factory.
Azure Data Factory to w pełni zarządzana usługa integracji danych w chmurze. Za pomocą usługi można wypełnić je danymi z bogatego zestawu lokalnych i opartych na chmurze magazynów danych oraz zaoszczędzić czas podczas tworzenia rozwiązań analitycznych. Aby uzyskać listę obsługiwanych łączników, zobacz tabelę Obsługiwanych magazynów danych.
Usługa Azure Data Factory oferuje skalowane w poziomie rozwiązanie do przenoszenia danych zarządzanych. Ze względu na architekturę skalowaną w poziomie usługi Data Factory może pozyskiwać dane przy wysokiej przepływności. Aby uzyskać więcej informacji, zobacz działanie Kopiuj wydajność.
W tym artykule pokazano, jak za pomocą narzędzia do kopiowania danych usługi Data Factory skopiować dane z usługi Azure Data Lake Storage Gen1 do usługi Azure Data Lake Storage Gen2. Możesz wykonać podobne kroki, aby skopiować dane z innych typów magazynów danych.
Wymagania wstępne
- Subskrypcja platformy Azure. Jeśli nie masz subskrypcji platformy Azure, przed rozpoczęciem utwórz bezpłatne konto.
- Konto usługi Azure Data Lake Storage Gen1 z danymi.
- Konto usługi Azure Storage z włączoną usługą Data Lake Storage Gen2. Jeśli nie masz konta magazynu, utwórz konto.
Tworzenie fabryki danych
Jeśli fabryka danych nie została jeszcze utworzona, wykonaj kroki opisane w przewodniku Szybki start: Tworzenie fabryki danych przy użyciu witryny Azure Portal i programu Azure Data Factory Studio , aby je utworzyć. Po utworzeniu przejdź do fabryki danych w witrynie Azure Portal.

Wybierz pozycję Otwórz na kafelku Otwórz usługę Azure Data Factory Studio, aby uruchomić aplikację Integracja danych na osobnej karcie.
Ładowanie danych do usługi Azure Data Lake Storage Gen2
Na stronie głównej wybierz kafelek Pozyskiwanie , aby uruchomić narzędzie do kopiowania danych.
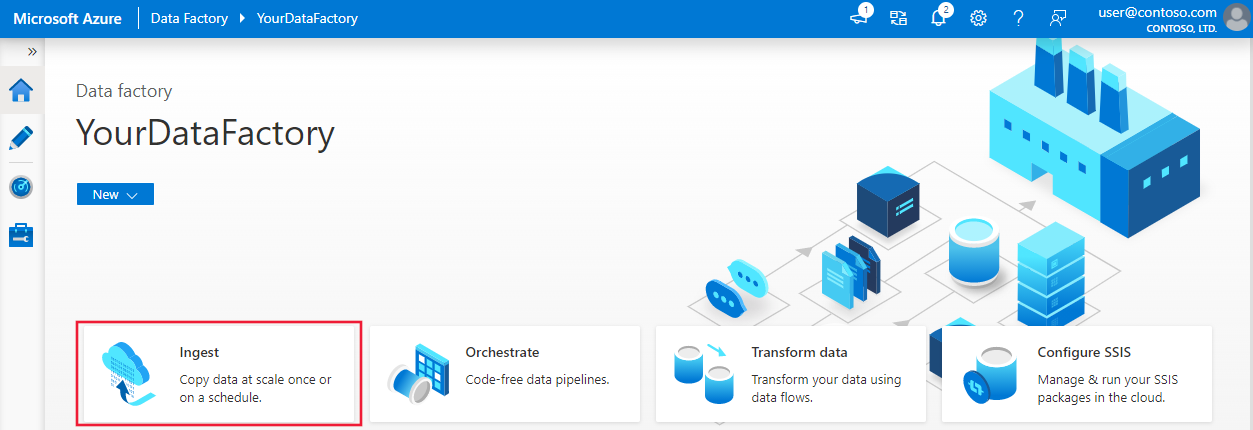
Na stronie Właściwości wybierz pozycję Wbudowane zadanie kopiowania w obszarze Typ zadania, a następnie wybierz pozycję Uruchom raz w obszarze Harmonogram zadań lub harmonogram zadań, a następnie wybierz przycisk Dalej.
Na stronie Źródłowy magazyn danych wybierz pozycję + Nowe połączenie.
Z galerii łączników wybierz pozycję Azure Data Lake Storage Gen1, a następnie przycisk Kontynuuj.
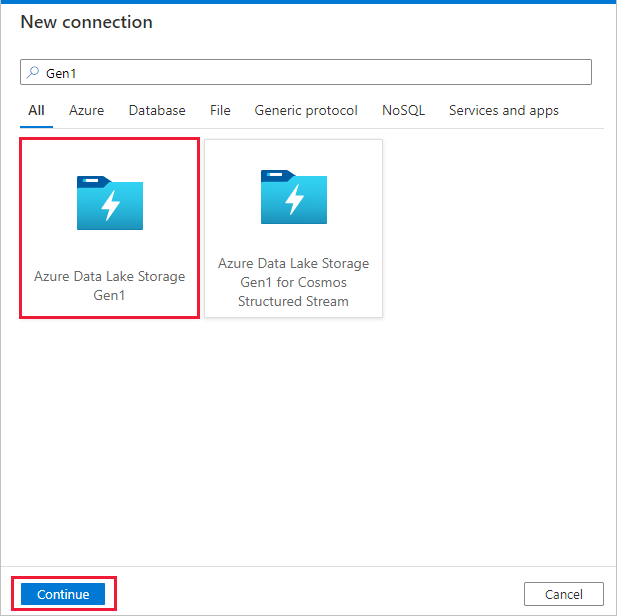
Na stronie Nowe połączenie (Azure Data Lake Storage Gen1) wykonaj następujące kroki:
- Wybierz nazwę konta usługi Data Lake Storage Gen1 i określ lub zweryfikuj dzierżawę.
- Wybierz pozycję Testuj połączenie , aby zweryfikować ustawienia. Następnie wybierz Utwórz.
Ważne
W tym przewodniku użyjesz tożsamości zarządzanej dla zasobów platformy Azure do uwierzytelniania usługi Azure Data Lake Storage Gen1. Aby udzielić tożsamości zarządzanej odpowiednich uprawnień w usłudze Azure Data Lake Storage Gen1, postępuj zgodnie z tymi instrukcjami.
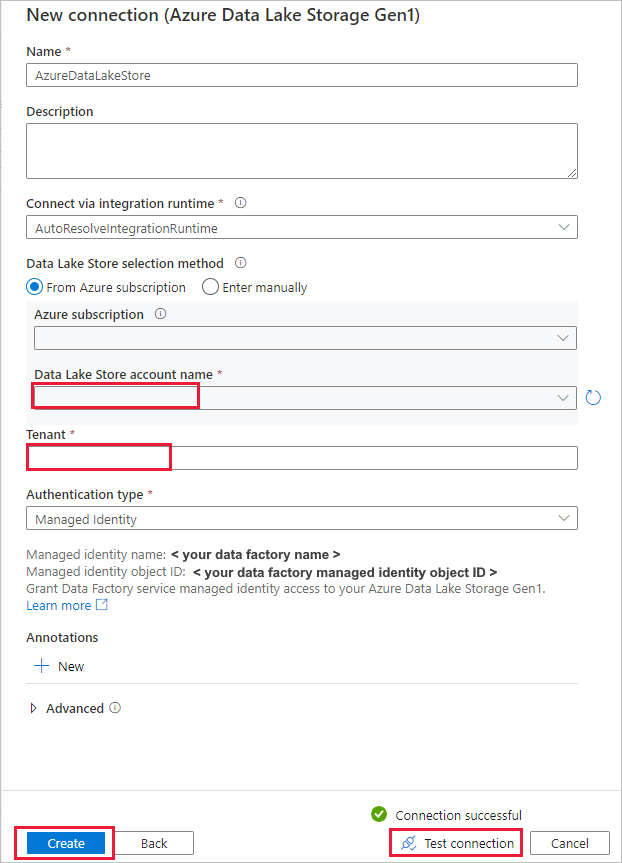
Na stronie Źródłowy magazyn danych wykonaj następujące kroki.
- Wybierz nowo utworzone połączenie w sekcji Połączenie .
- W obszarze Plik lub folder przejdź do folderu i pliku, który chcesz skopiować. Wybierz folder lub plik, a następnie wybierz przycisk OK.
- Określ zachowanie kopiowania, wybierając opcje Rekursywnie i Kopiowanie binarne. Wybierz Dalej.
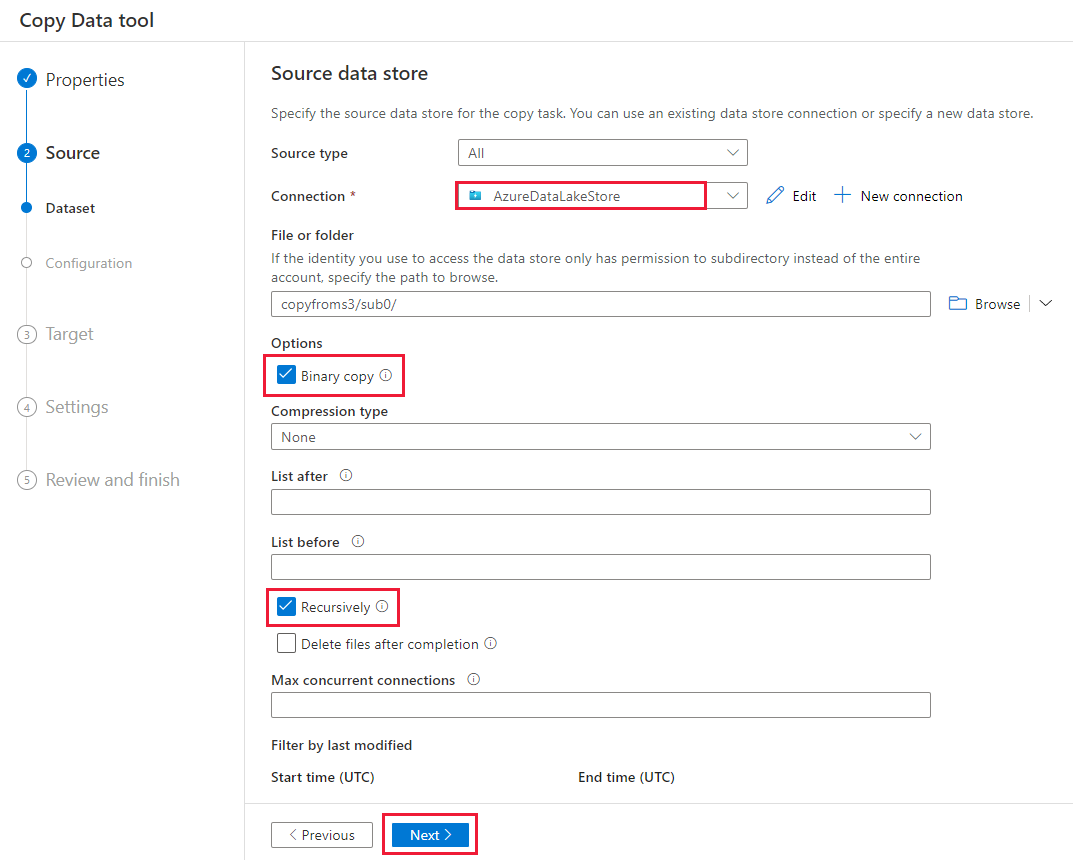
Na stronie Docelowy magazyn danych wybierz pozycję + Nowe połączenie z usługą>Azure Data Lake Storage Gen2>Kontynuuj.
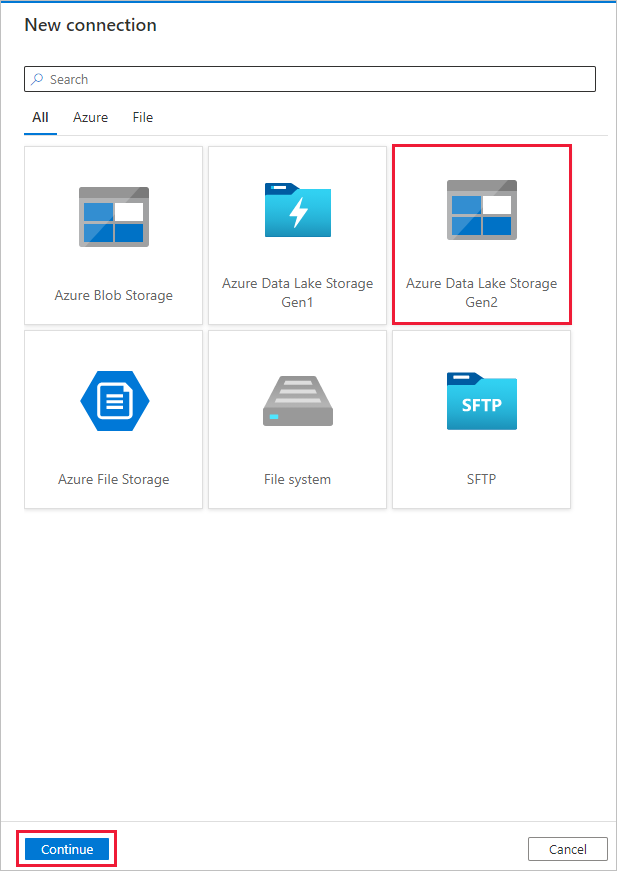
Na stronie Nowe połączenie (Azure Data Lake Storage Gen2) wykonaj następujące kroki:
- Wybierz swoje konto obsługujące usługę Data Lake Storage Gen2 z listy rozwijanej Nazwa konta magazynu.
- Wybierz Utwór, aby utworzyć łącznik.
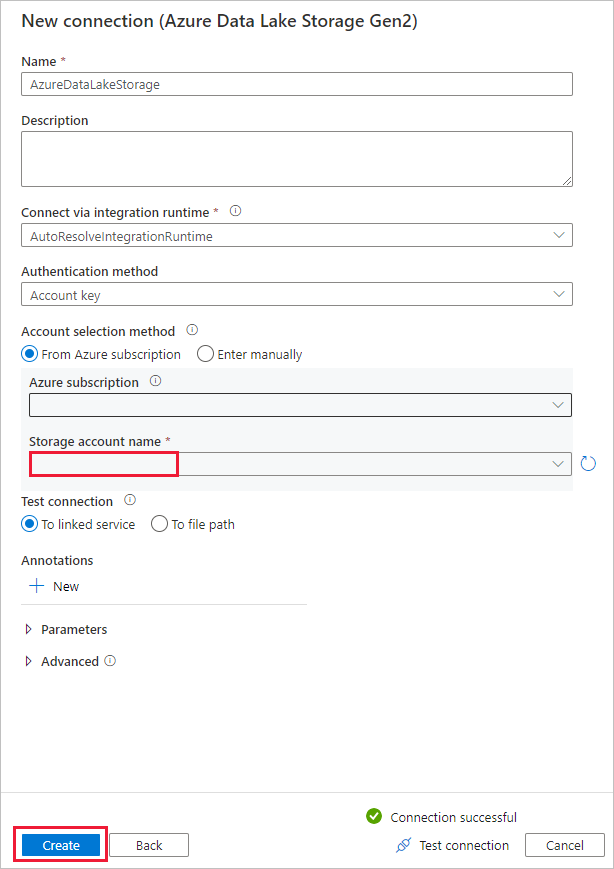
Na stronie Docelowy magazyn danych wykonaj następujące kroki.
- Wybierz nowo utworzone połączenie w bloku Połączenie .
- W obszarze Ścieżka folderu wprowadź wartość copyfromadlsgen1 jako nazwę folderu wyjściowego, a następnie wybierz przycisk Dalej. Usługa Data Factory tworzy odpowiedni system plików i podfoldery usługi Azure Data Lake Storage Gen2 podczas kopiowania, jeśli nie istnieją.
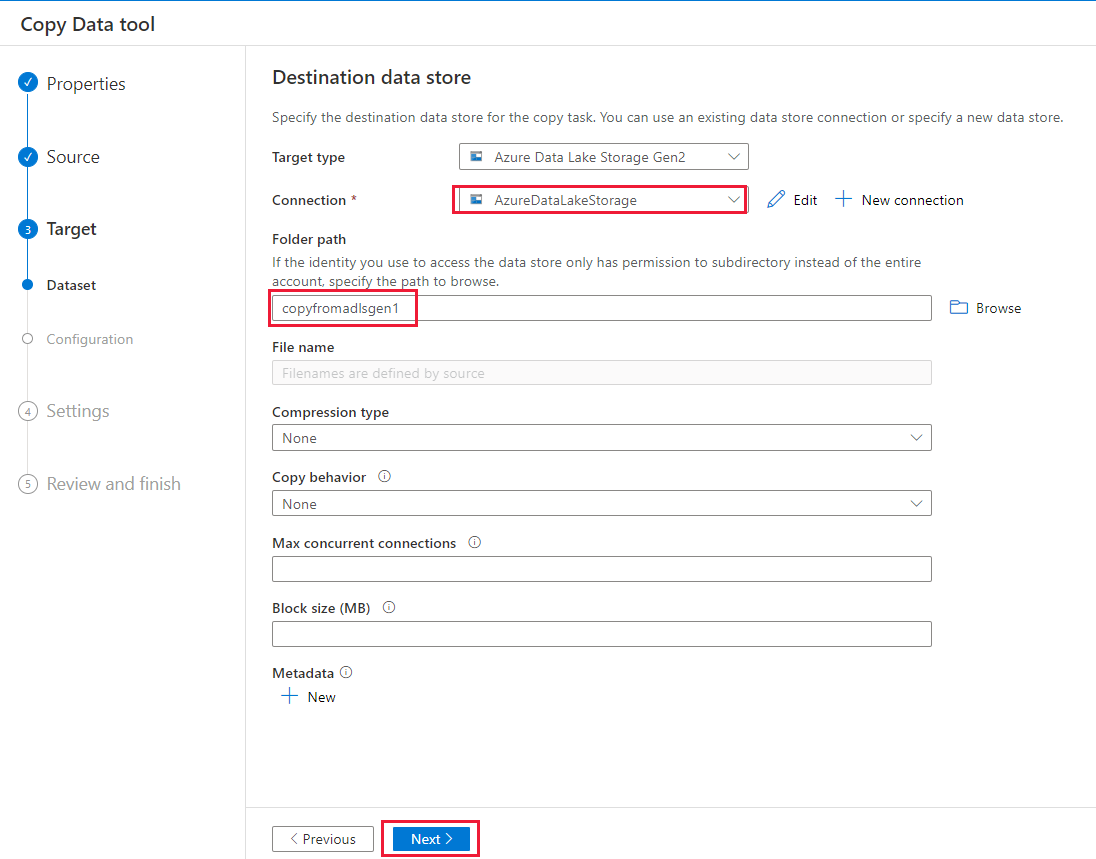
Na stronie Ustawienia określ wartość CopyFromADLSGen1ToGen2 w polu Nazwa zadania, a następnie wybierz przycisk Dalej, aby użyć ustawień domyślnych.
Na stronie Podsumowanie przejrzyj ustawienia, a następnie wybierz pozycję Dalej.
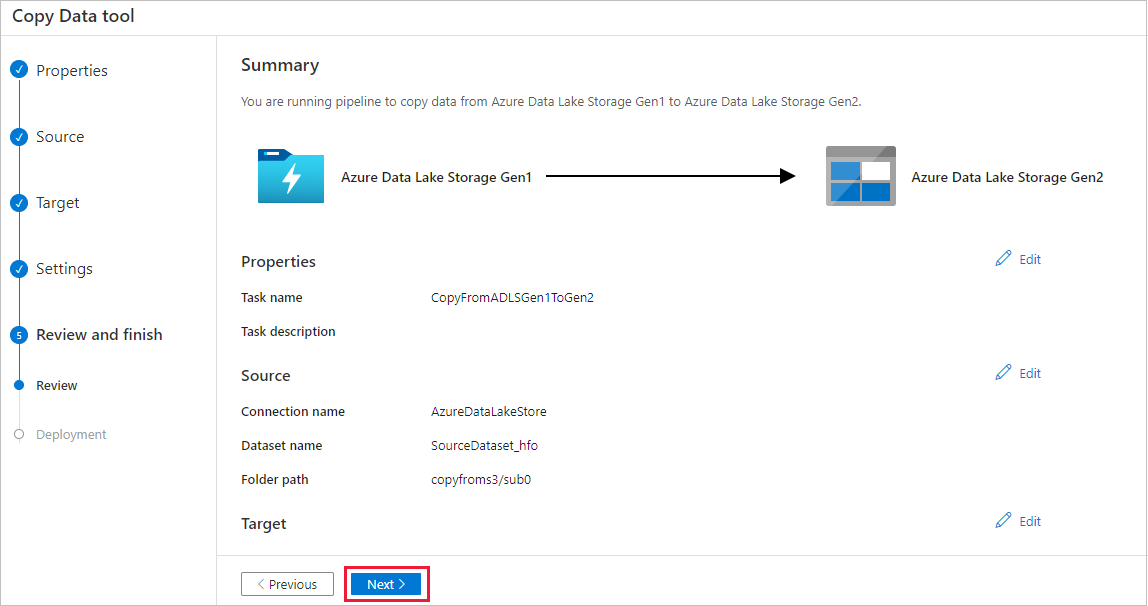
Na stronie Wdrażanie wybierz pozycję Monitor, aby monitorować potok.
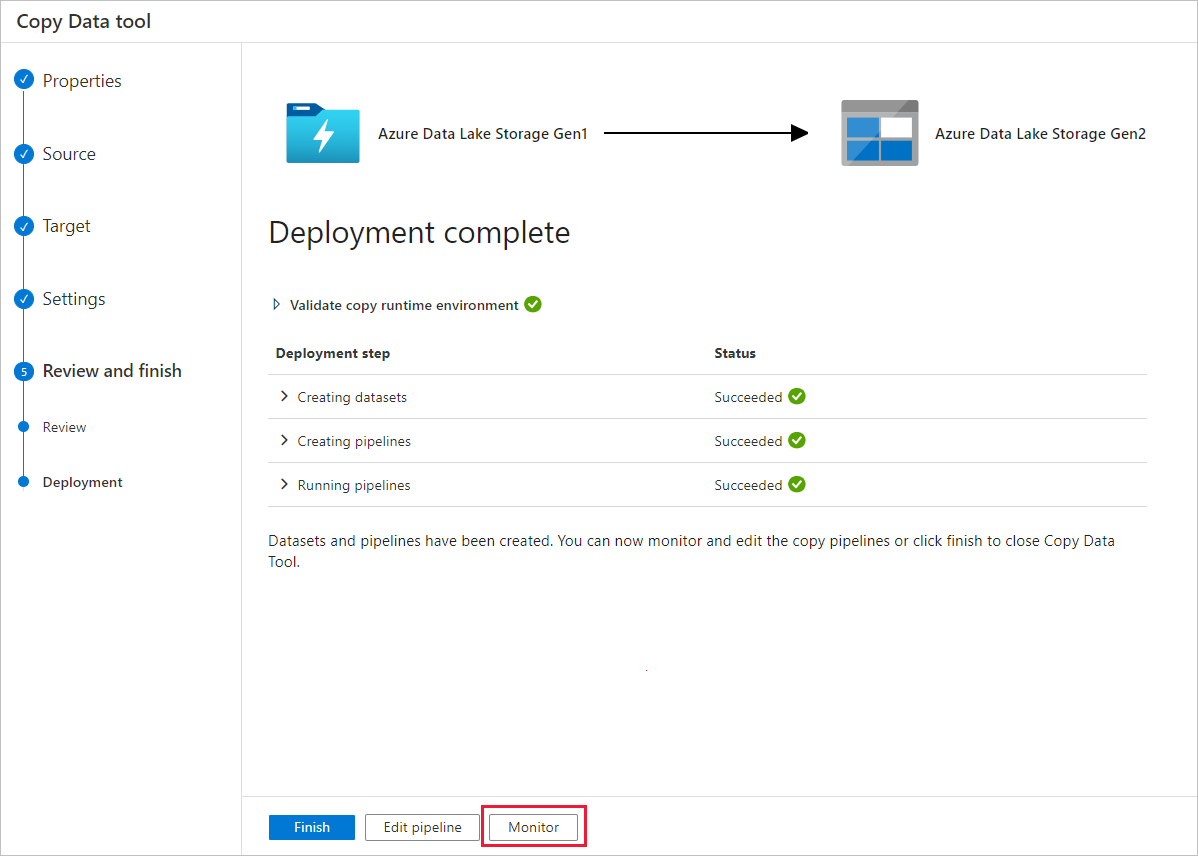
Zwróć uwagę, że karta Monitor po lewej stronie jest automatycznie wybrana. Kolumna Nazwa potoku zawiera linki do wyświetlania szczegółów przebiegu działania i ponownego uruchamiania potoku.
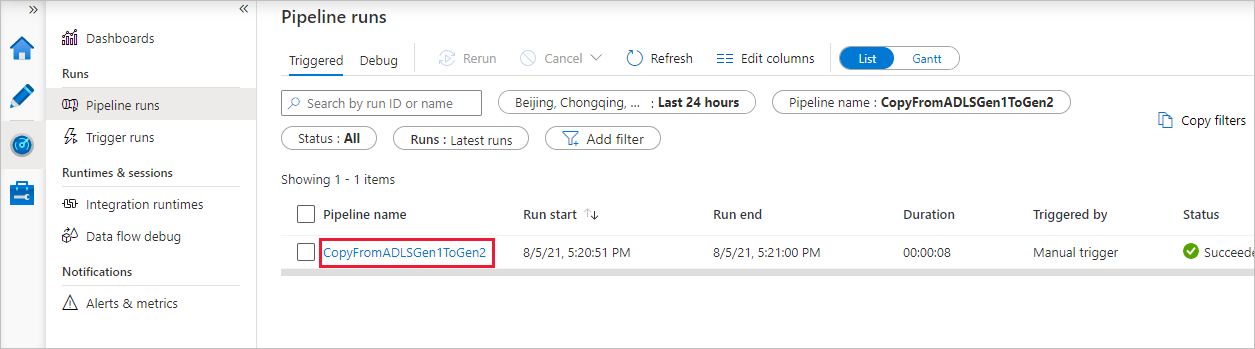
Aby wyświetlić uruchomienia działań skojarzone z uruchomieniem potoku, wybierz link w kolumnie Nazwa potoku. W potoku jest tylko jedno działanie (działanie kopiowania), dlatego na liście jest wyświetlana tylko jedna pozycja. Aby wrócić do widoku przebiegów potoku, wybierz link Wszystkie uruchomienia potoku w menu linku do stron nadrzędnych u góry. Wybierz pozycję Odśwież, aby odświeżyć listę.
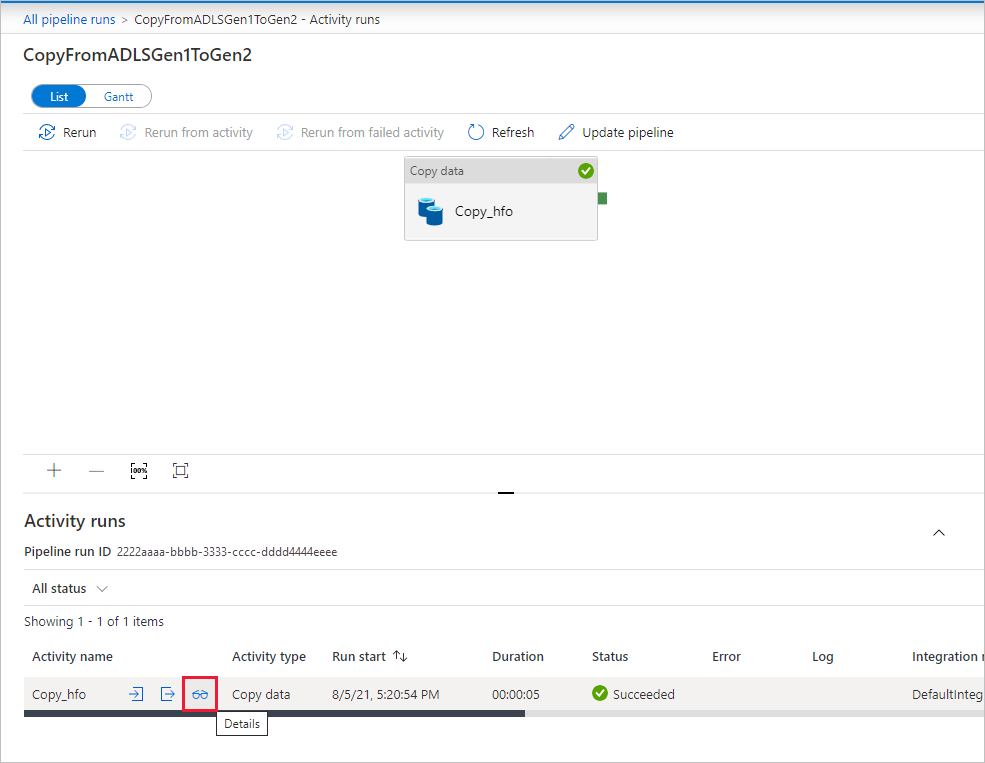
Aby monitorować szczegóły wykonywania dla każdego działania kopiowania, wybierz link Szczegóły (obraz okularów) w kolumnie Nazwa działania w widoku monitorowania aktywności. Możesz monitorować szczegóły, takie jak ilość danych skopiowanych ze źródła do ujścia, przepływność danych, kroki wykonywania z odpowiednim czasem trwania i używane konfiguracje.
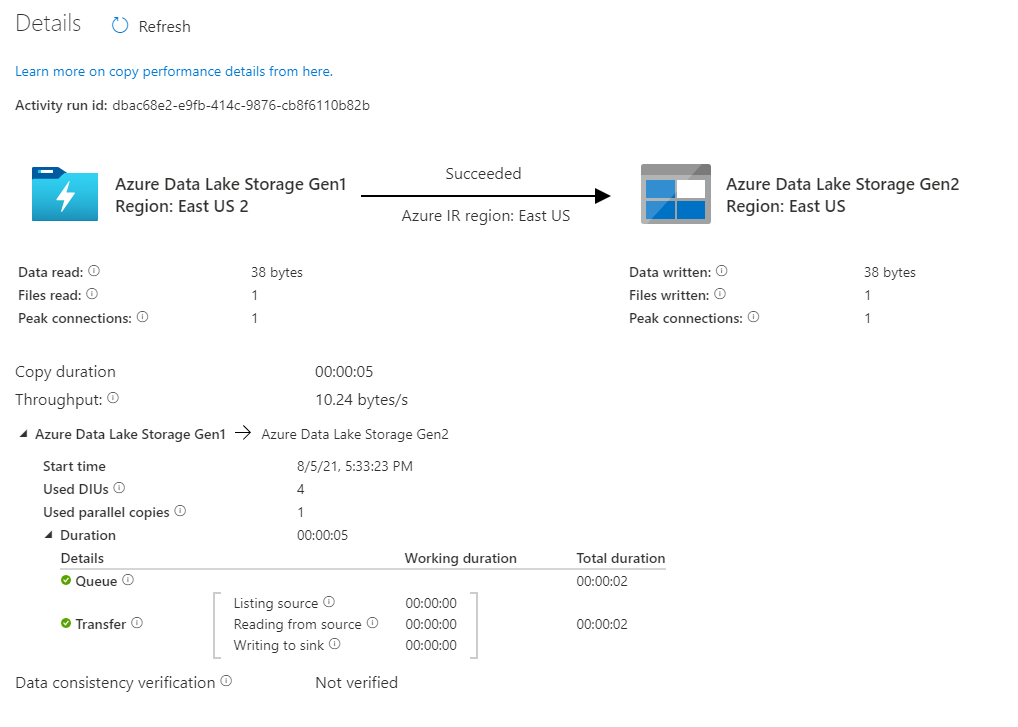
Sprawdź, czy dane są kopiowane na konto usługi Azure Data Lake Storage Gen2.
Najlepsze rozwiązania
Aby ocenić uaktualnienie z usługi Azure Data Lake Storage Gen1 do usługi Azure Data Lake Storage Gen2, zobacz Uaktualnianie rozwiązań analizy danych big data z usługi Azure Data Lake Storage Gen1 do usługi Azure Data Lake Storage Gen2. W poniższych sekcjach przedstawiono najlepsze rozwiązania dotyczące używania usługi Data Factory do uaktualnienia danych z usługi Data Lake Storage Gen1 do usługi Data Lake Storage Gen2.
Początkowa migracja danych migawek
Wydajność
Usługa ADF oferuje architekturę bezserwerową, która umożliwia równoległość na różnych poziomach, co umożliwia deweloperom tworzenie potoków w celu pełnego wykorzystania przepustowości sieci, a także liczby operacji we/wy na sekundę magazynu i przepustowości w celu zmaksymalizowania przepływności przenoszenia danych dla środowiska.
Klienci pomyślnie zmigrowali petabajty danych składających się z setek milionów plików z usługi Data Lake Storage Gen1 do 2. generacji, przy stałej przepływności 2 GB/s i wyższych.
Możesz osiągnąć większą szybkość przenoszenia danych, stosując różne poziomy równoległości:
- Jedno działanie kopiowania może korzystać ze skalowalnych zasobów obliczeniowych: w przypadku korzystania z środowiska Azure Integration Runtime można określić maksymalnie 256 jednostek integracji danych (DIU) dla każdego działania kopiowania w sposób bezserwerowy. W przypadku korzystania z własnego środowiska Integration Runtime można ręcznie skalować maszynę w górę lub skalować w poziomie do wielu maszyn (maksymalnie 4 węzły). a jedno działanie kopiowania podzieli plik na partycje we wszystkich węzłach.
- Jedno działanie kopiowania odczytuje dane i zapisuje je w magazynie danych przy użyciu wielu wątków.
- Przepływ sterowania usługi ADF może uruchamiać wiele działań kopiowania równolegle, na przykład za pomocą pętli For Each.
Partycje danych
Jeśli łączny rozmiar danych w usłudze Data Lake Storage Gen1 jest mniejszy niż 10 TB, a liczba plików jest mniejsza niż 1 milion, możesz skopiować wszystkie dane w jednym uruchomieniu działania kopiowania. Jeśli masz większą ilość danych do skopiowania lub chcesz elastycznie zarządzać migracją danych w partiach i dokonać ich ukończenia w określonym przedziale czasu, podziel dane na partycje. Partycjonowanie zmniejsza również ryzyko wystąpienia nieoczekiwanego problemu.
Sposobem partycjonowania plików jest użycie zakresu nazw listAfter/listBefore we właściwości działania kopiowania. Każde działanie kopiowania można skonfigurować pod kątem kopiowania jednej partycji jednocześnie, dzięki czemu wiele działań kopiowania może kopiować dane z pojedynczego konta usługi Data Lake Storage Gen1 współbieżnie.
Rate limiting (Ograniczanie szybkości)
Najlepszym rozwiązaniem jest przeprowadzenie weryfikacji koncepcji wydajności przy użyciu reprezentatywnego przykładowego zestawu danych, dzięki czemu można określić odpowiedni rozmiar partycji.
Zacznij od pojedynczej partycji i pojedynczego działania kopiowania z domyślnym ustawieniem jednostki DIU. Kopia równoległa jest zawsze sugerowana jako pusta (wartość domyślna). Jeśli przepływność kopiowania nie jest odpowiednia, zidentyfikuj i rozwiąż wąskie gardła wydajności, wykonując kroki dostrajania wydajności.
Stopniowo zwiększaj ustawienie jednostek DIU do momentu osiągnięcia limitu przepustowości sieci lub limitu liczby operacji we/wy na sekundę/przepustowości magazynów danych lub osiągnięto maksymalną liczbę 256 jednostek DIU dozwolonych w ramach pojedynczego działania kopiowania.
Jeśli zmaksymalizowano wydajność pojedynczego działania kopiowania, ale nie osiągnęło jeszcze górnej przepływności środowiska, możesz uruchomić wiele działań kopiowania równolegle.
Jeśli podczas monitorowania aktywności kopiowania zostanie wyświetlona znaczna liczba błędów ograniczania przepustowości, oznacza to, że osiągnięto limit pojemności konta magazynu. Usługa ADF spróbuje automatycznie pokonać każdy błąd ograniczania przepustowości, aby upewnić się, że nie zostaną utracone żadne dane, ale zbyt wiele ponownych prób może również obniżyć przepływność kopiowania. W takim przypadku zachęcamy do zmniejszenia liczby działań kopiowania uruchomionych jednocześnie, aby uniknąć znacznych ilości błędów ograniczania przepustowości. Jeśli używasz działania kopiowania pojedynczego do kopiowania danych, zachęcamy do zmniejszenia liczby jednostek DIU.
Migracja danych różnicowych
Możesz użyć kilku metod ładowania tylko nowych lub zaktualizowanych plików z usługi Data Lake Storage Gen1:
- Załaduj nowe lub zaktualizowane pliki według czasu podzielonego na partycje folderu lub nazwy pliku. Przykładem jest /2019/05/13/*.
- Załaduj nowe lub zaktualizowane pliki według daty ostatniej modyfikacji. Jeśli kopiujesz duże ilości plików, najpierw wykonaj partycje, aby uniknąć niskiej przepływności kopiowania wyników z pojedynczego działania kopiowania skanującego całe konto usługi Data Lake Storage Gen1 w celu zidentyfikowania nowych plików.
- Zidentyfikuj nowe lub zaktualizowane pliki za pomocą dowolnego narzędzia lub rozwiązania innej firmy. Następnie przekaż nazwę pliku lub folderu do potoku usługi Data Factory za pomocą parametru lub tabeli lub pliku.
Właściwa częstotliwość ładowania przyrostowego zależy od całkowitej liczby plików w usłudze Azure Data Lake Storage Gen1 oraz woluminu nowych lub zaktualizowanych plików, które mają być ładowane za każdym razem.
Bezpieczeństwo sieci
Domyślnie usługa ADF transferuje dane z usługi Azure Data Lake Storage Gen1 do generacji 2 przy użyciu szyfrowanego połączenia za pośrednictwem protokołu HTTPS. Protokół HTTPS zapewnia szyfrowanie danych podczas przesyłania i uniemożliwia podsłuchiwanie i ataki typu man-in-the-middle.
Alternatywnie, jeśli nie chcesz, aby dane zostały przesłane za pośrednictwem publicznego Internetu, można osiągnąć większe bezpieczeństwo, przesyłając dane za pośrednictwem sieci prywatnej.
Zachowywanie list ACL
Jeśli chcesz replikować listy ACL wraz z plikami danych podczas uaktualniania z usługi Data Lake Storage Gen1 do usługi Data Lake Storage Gen2, zobacz Zachowywanie list ACL z usługi Data Lake Storage Gen1.
Odporność
W ramach jednego uruchomienia działania kopiowania usługa ADF ma wbudowany mechanizm ponawiania prób, dzięki czemu może obsługiwać określony poziom przejściowych błędów w magazynach danych lub w sieci bazowej. Jeśli migrujesz więcej niż 10 TB danych, zachęcamy do partycjonowania danych w celu zmniejszenia ryzyka wystąpienia nieoczekiwanych problemów.
Można również włączyć odporność na uszkodzenia w działaniu kopiowania, aby pominąć wstępnie zdefiniowane błędy. Weryfikację spójności danych w działaniu kopiowania można również włączyć, aby przeprowadzić dodatkową weryfikację, aby upewnić się, że dane nie tylko zostały pomyślnie skopiowane ze źródła do magazynu docelowego, ale także zweryfikowane, aby były spójne między magazynem źródłowym i docelowym.
Uprawnienia
W usłudze Data Factory łącznik usługi Data Lake Storage Gen1 obsługuje jednostkę usługi i tożsamość zarządzaną na potrzeby uwierzytelniania zasobów platformy Azure. Łącznik usługi Data Lake Storage Gen2 obsługuje klucz konta, jednostkę usługi i tożsamość zarządzaną na potrzeby uwierzytelniania zasobów platformy Azure. Aby usługa Data Factory mogła nawigować i kopiować wszystkie pliki lub listy kontroli dostępu (ACL), musisz przyznać kontom wystarczające uprawnienia dostępu do wszystkich plików, odczytu lub zapisu oraz ustawiać listy ACL, jeśli wybierzesz opcję. Należy przyznać konto roli administratora lub właściciela w okresie migracji i usunąć podniesione uprawnienia po zakończeniu migracji.