Wymagane działania klienta
Wstępne zdarzenie
W przypadku usług platformy Azure
- Zapoznaj się z usługą Azure Service Health w witrynie Azure Portal. Ta strona będzie działać jako "jednorazowy sklep" podczas incydentu.
- Rozważ użycie alertów usługi Service Health, które można skonfigurować do automatycznego generowania powiadomień w przypadku wystąpienia zdarzeń platformy Azure.
W przypadku usługi Power BI
- Zapoznaj się z usługą Service Health w Centrum administracyjne platformy Microsoft 365. Ta strona będzie działać jako "jednorazowy sklep" podczas incydentu.
- Rozważ użycie aplikacji mobilnej Administracja Microsoft 365, aby otrzymywać powiadomienia o alertach o zdarzeniu usługi automatycznej.
Podczas zdarzenia
W przypadku usług platformy Azure
- Usługa Azure Service Health w portalu zarządzania platformy Azure udostępni najnowsze aktualizacje.
- Jeśli występują problemy z uzyskiwaniem dostępu do usługi Service Health, zapoznaj się ze stroną Stan platformy Azure.
- Jeśli kiedykolwiek występują problemy z uzyskiwaniem dostępu do strony Stan, przejdź do pozycji @AzureSupport X (dawniej Twitter).
- Jeśli wpływ/problemy nie są zgodne ze zdarzeniem (lub utrwały się po zaradczem), skontaktuj się z pomocą techniczną , aby zgłosić bilet pomocy technicznej usługi.
W przypadku usługi Power BI
- Strona Kondycja usługi w ramach Centrum administracyjne platformy Microsoft 365 udostępni najnowsze aktualizacje
- Jeśli występują problemy z uzyskiwaniem dostępu do usługi Service Health, zapoznaj się ze stroną stanu platformy Microsoft 365
- Jeśli wpływ/problemy nie są zgodne ze zdarzeniem (lub jeśli problemy będą nadal występować po rozwiązaniu problemu), należy zgłosić bilet pomocy technicznej usługi.
Po odzyskiwaniu przez firmę Microsoft
Aby uzyskać szczegółowe informacje, zobacz poniższe sekcje.
Po zdarzeniu
Dla usług platformy Azure
- Firma Microsoft opublikuje pir w witrynie Azure Portal — usługa Service Health do przeglądu.
W przypadku usługi Power BI
- Firma Microsoft opublikuje pir w Administracja Microsoft 365 — usługa Service Health do przeglądu.
Czekaj na proces firmy Microsoft
Proces "Czekaj na firmę Microsoft" po prostu czeka na odzyskanie wszystkich składników i usług w dotkniętym regionie podstawowym. Po odzyskaniu zweryfikuj powiązanie platformy danych z udostępnionymi lub innymi usługami przedsiębiorstwa, datą zestawu danych, a następnie wykonaj procesy przesyłania systemu do bieżącej daty.
Po zakończeniu tego procesu można ukończyć walidację ekspertów w dziedzinie zagadnień technicznych i biznesowych (SME), co umożliwi zatwierdzenie uczestników projektu w celu odzyskania usługi.
Ponowne wdrażanie w przypadku awarii
W przypadku strategii "Ponowne wdrażanie w przypadku awarii" można opisać następujący ogólny przepływ procesów.
Odzyskiwanie usług udostępnionych i systemów źródłowych przedsiębiorstwa firmy Contoso

- Ten krok jest wymaganiem wstępnym dla odzyskiwania platformy danych.
- Ten krok zostanie wykonany przez różne grupy pomocy technicznej operacyjnej firmy Contoso odpowiedzialne za usługi udostępnione przedsiębiorstwa i operacyjne systemy źródłowe.
Odzyskiwanie usług platformy Azure usług platformy Azure odnosi się do aplikacji i usług, które udostępniają ofertę w chmurze platformy Azure, są dostępne w regionie pomocniczym do wdrożenia.

Usługi platformy Azure odnoszą się do aplikacji i usług, które udostępniają ofertę w chmurze platformy Azure, są dostępne w regionie pomocniczym do wdrożenia.
- Ten krok jest wymaganiem wstępnym dla odzyskiwania platformy danych.
- Ten krok zostałby ukończony przez firmę Microsoft i innych partnerów platformy jako usługi (PaaS)/oprogramowania jako usługi (SaaS).
Odzyskiwanie podstawy platformy danych
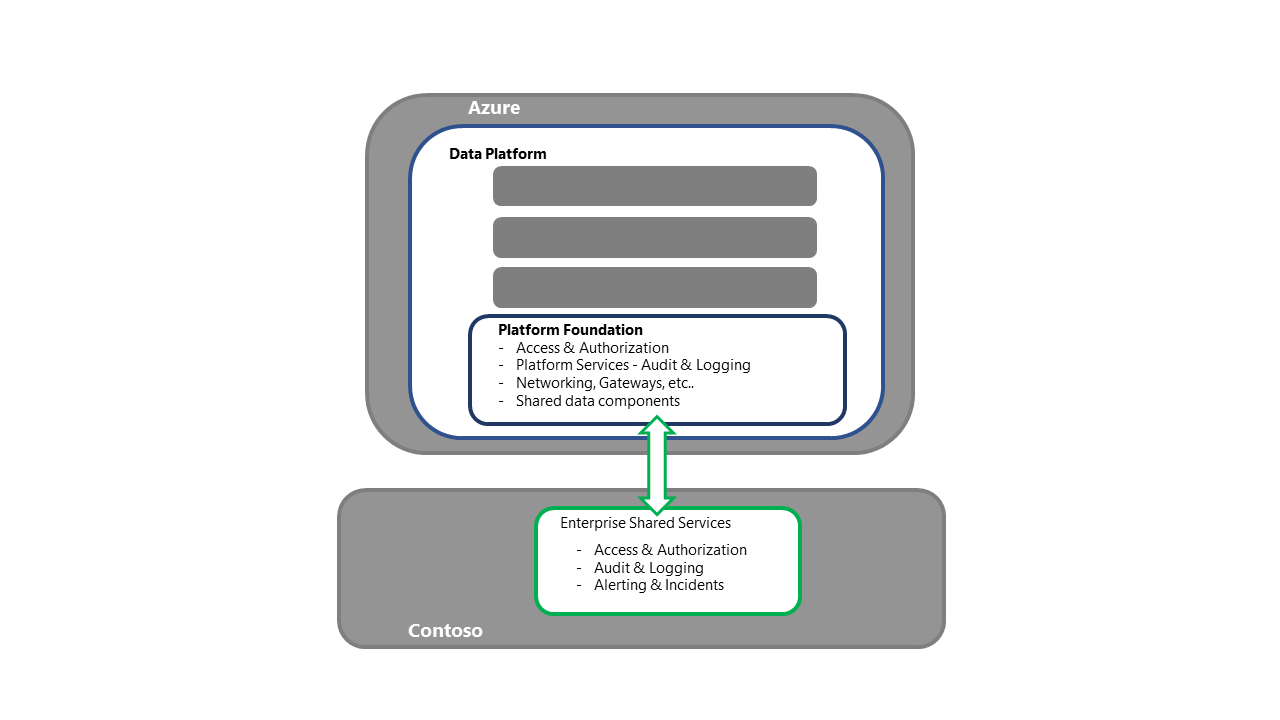
- Ten krok jest punktem wejścia dla działań odzyskiwania platformy.
- W przypadku strategii ponownego wdrażania każdy wymagany składnik/usługa zostanie pozyskany i wdrożony w regionie pomocniczym.
- Ten proces powinien również obejmować działania, takie jak powiązanie z usługami udostępnionymi przedsiębiorstwa, zapewnienie łączności z dostępem/uwierzytelnianiem oraz weryfikowanie działania odciążania dziennika, a jednocześnie zapewnienie łączności zarówno z procesami nadrzędnymi, jak i podrzędnym.
- Dane/przetwarzanie należy potwierdzić. Na przykład weryfikacja znacznika czasu odzyskanej platformy.
- Jeśli istnieją pytania dotyczące integralności danych, decyzja może zostać podjęta, aby wycofać się na czas przed wykonaniem nowego przetwarzania w celu zapewnienia aktualności platformy.
- Kolejność priorytetu procesów (na podstawie wpływu biznesowego) pomoże w organizowaniu odzyskiwania.
- Ten krok powinien zostać zamknięty przez weryfikację techniczną, chyba że użytkownicy biznesowi bezpośrednio wchodzą w interakcje z usługami. Jeśli istnieje bezpośredni dostęp, konieczne będzie sprawdzenie poprawności biznesowej.
- Po zakończeniu walidacji następuje przekazanie poszczególnym zespołom rozwiązań w celu rozpoczęcia własnego procesu odzyskiwania po awarii.
- Przekazanie powinno obejmować potwierdzenie bieżącego znacznika czasu danych i procesów.
- Jeśli zostaną wykonane podstawowe procesy danych przedsiębiorstwa, poszczególne rozwiązania powinny zostać poinformowane o tym — na przykład przepływy przychodzące/wychodzące.
Odzyskiwanie poszczególnych rozwiązań hostowanych przez platformę
- Każde rozwiązanie powinno mieć własny element Runbook odzyskiwania po awarii. Elementy Runbook powinny zawierać co najmniej nominowanych uczestników projektu biznesowego, którzy będą testować i potwierdzić, że odzyskiwanie usługi zostało ukończone.
- W zależności od rywalizacji lub priorytetu zasobów kluczowe rozwiązania/obciążenia mogą być priorytetowe dla innych — podstawowe procesy przedsiębiorstwa w laboratoriach ad hoc, na przykład.
- Po zakończeniu kroków weryfikacji nastąpi przekazanie do rozwiązań podrzędnych w celu rozpoczęcia procesu odzyskiwania po awarii.
Przekazywanie do systemów podrzędnych, zależnych
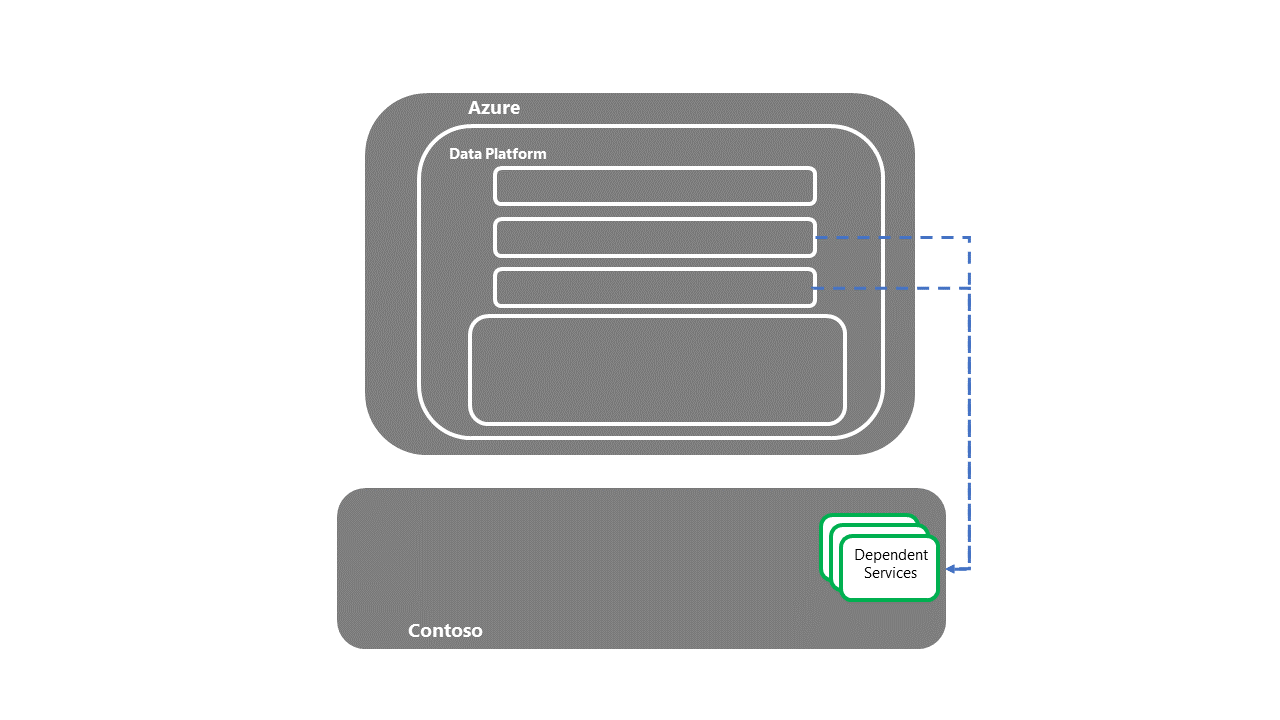
- Po odzyskaniu usług zależnych proces odzyskiwania po awarii E2E zostanie ukończony.
Uwaga
Chociaż teoretycznie jest możliwe całkowite zautomatyzowanie procesu odzyskiwania po awarii E2E, jest mało prawdopodobne, biorąc pod uwagę ryzyko wystąpienia zdarzenia w porównaniu z kosztem działań SDLC wymaganych do pokrycia procesu E2E.
Powrót do regionu podstawowego Fallback to proces przenoszenia usługi platformy danych i jej danych z powrotem do regionu podstawowego, gdy będzie dostępny dla usługi BAU.
W zależności od charakteru systemów źródłowych i różnych procesów danych rezerwowe platformy danych mogą być wykonywane niezależnie od innych części środowiska danych.
Klienci powinni przejrzeć zależności własnej platformy danych (zarówno nadrzędne, jak i podrzędne), aby podjąć odpowiednią decyzję. W poniższej sekcji przyjęto założenie, że niezależne odzyskiwanie platformy danych.
- Gdy wszystkie wymagane składniki/usługi staną się dostępne w regionie podstawowym, klienci ukończyliby test weryfikacyjny kompilacji w celu zweryfikowania odzyskiwania firmy Microsoft.
- Konfiguracja składnika/usługi zostanie zweryfikowana. Różnice zostaną rozwiązane za pomocą ponownego wdrożenia z kontroli źródła.
- Data systemowa w regionie podstawowym zostanie ustanowiona między składnikami stanowymi. Różnica między ustaloną datą a sygnaturą czasową w regionie pomocniczym powinna zostać rozwiązana przez ponowne ekscesję lub odtworzenie procesów pozyskiwania danych od tego momentu.
- Po zatwierdzeniu zarówno zainteresowanych stron biznesowych, jak i technicznych zostanie wybrane okno rezerwowe. W idealnym przypadku powinno się to zdarzyć podczas uśpić działanie systemu i przetwarzanie.
- Podczas powrotu region podstawowy zostanie przeniesiony do synchronizacji z regionem pomocniczym, zanim system został przełączony.
- Po okresie przebiegu równoległego region pomocniczy zostanie przełączony w tryb offline z systemu.
- Składniki w regionie pomocniczym zostaną usunięte lub usunięte, w zależności od wybranej strategii odzyskiwania po awarii.
Ciepły proces zapasowy
W przypadku strategii "Warm Spare" przepływ procesów wysokiego poziomu jest ściśle dopasowany do strategii "Ponowne wdrażanie w przypadku awarii", co jest kluczową różnicą, że składniki zostały już pozyskane w regionie pomocniczym. Ta strategia eliminuje ryzyko rywalizacji o zasoby od innych organizacji, które chcą ukończyć własne odzyskiwanie po awarii w tym regionie.
Gorący proces zapasowy
Strategia "Hot Spare" oznacza, że usługi platformy, w tym PaaS i systemy IaaS (Infrastruktura jako usługa) będą utrzymywać się pomimo awarii, ponieważ systemy pomocnicze działają razem z systemami podstawowymi. Podobnie jak w przypadku strategii "Warm Spare", ta strategia eliminuje ryzyko rywalizacji o zasoby od innych organizacji, które chcą ukończyć własne odzyskiwanie po awarii w tym regionie.
Klienci hot Spare będą monitorować odzyskiwanie składników/usług firmy Microsoft w regionie podstawowym. Po zakończeniu klienci zweryfikują systemy regionów podstawowych i zakończą powrót do regionu podstawowego. Ten proces będzie podobny do procesu trybu failover odzyskiwania po awarii, który polega na sprawdzeniu dostępnej bazy kodu i danych, ponownego wdrożenia zgodnie z potrzebami.
Uwaga
Należy zwrócić szczególną uwagę na to, aby zapewnić spójność wszystkich metadanych systemu między dwoma regionami.
- Po zakończeniu powrotu do podstawowego moduły równoważenia obciążenia systemu można zaktualizować, aby przywrócić topologię systemu w regionie podstawowym. Jeśli jest dostępna, można użyć podejścia do wydania kanarowego w celu przyrostowego przełączenia regionu podstawowego dla systemu.
Struktura planu odzyskiwania po awarii
Skuteczny plan odzyskiwania po awarii zawiera szczegółowy przewodnik po odzyskiwaniu usługi, który można wykonać za pomocą zasobu technicznego platformy Azure. W związku z tym poniżej wymieniono proponowaną strukturę MVP dla planu odzyskiwania po awarii.
- Wymagania dotyczące procesu
- Wszelkie szczegółowe informacje dotyczące procesu odzyskiwania po awarii klienta, takie jak poprawna autoryzacja wymagana do uruchomienia odzyskiwania po awarii i podejmowanie kluczowych decyzji dotyczących odzyskiwania w razie potrzeby (w tym "definicja gotowego"), pomoc techniczna dotycząca obsługi biletów odzyskiwania po awarii i szczegóły pokoju wojennego.
- Potwierdzenie zasobu, w tym potencjalnego klienta odzyskiwania po awarii i kopii zapasowej funkcji wykonawczej. Wszystkie zasoby powinny być udokumentowane przy użyciu kontaktów podstawowych i pomocniczych, ścieżek eskalacji i opuszczania kalendarzy. W krytycznych sytuacjach odzyskiwania po awarii należy rozważyć systemy dyżurów.
- Laptop, power packi lub zasilanie kopii zapasowej, łączność sieciowa i szczegóły telefonu komórkowego dla funkcji wykonawczej odzyskiwania po awarii, kopii zapasowej odzyskiwania po awarii i wszelkich punktów eskalacji.
- Proces, który ma zostać spełniony, jeśli którykolwiek z wymagań dotyczących procesu nie zostanie spełniony.
- Lista kontaktów
- Kierownictwo dr i grupy wsparcia.
- MŚP biznesowe, które zakończą cykl testowania/przeglądu na potrzeby odzyskiwania technicznego.
- Właściciele firm, których dotyczy problem, w tym osoby zatwierdzające odzyskiwanie usługi.
- Dotyczy to właścicieli technicznych, w tym osób zatwierdzających odzyskiwanie techniczne.
- Obsługa MŚP we wszystkich obszarach, których dotyczy problem, w tym kluczowych rozwiązań hostowanych przez platformę.
- Systemy podrzędne, których dotyczy problem — obsługa operacyjna.
- Nadrzędne systemy źródłowe — obsługa operacyjna.
- Kontakty usług udostępnionych przedsiębiorstwa. Na przykład obsługa dostępu i uwierzytelniania, monitorowanie zabezpieczeń i obsługa bramy
- Wszyscy zewnętrzni lub zewnętrzni dostawcy, w tym kontakty pomocy technicznej dla dostawców usług w chmurze.
- Projekt architektury
- Opisz szczegóły scenariusza end-end (E2E) i dołącz całą skojarzoną dokumentację pomocy technicznej.
- Zależności
- Wyświetl listę wszystkich relacji i zależności składników.
- Wymagania wstępne odzyskiwania po awarii
- Potwierdzenie, że nadrzędne systemy źródłowe są dostępne zgodnie z wymaganiami.
- Podwyższony poziom dostępu między stosem został przyznany zasobom funkcji wykonawczej odzyskiwania po awarii.
- Usługi platformy Azure są dostępne zgodnie z wymaganiami.
- Proces, który należy wykonać, jeśli którykolwiek z wymagań wstępnych nie został spełniony.
- Odzyskiwanie techniczne — instrukcje krok po kroku
- Uruchom kolejność.
- Opis kroku.
- Krok wymagania wstępne.
- Szczegółowe kroki procesu dla każdej akcji dyskretnej, w tym adresów URL.
- Instrukcje weryfikacji, w tym wymagane dowody.
- Oczekiwany czas ukończenia każdego kroku, w tym awaryjne.
- Proces, który należy wykonać, jeśli krok zakończy się niepowodzeniem.
- Punkty eskalacji w przypadku awarii lub obsługi MŚP.
- Odzyskiwanie techniczne — wymagania wstępne
- Potwierdź bieżący znacznik czasu daty systemu między kluczowymi składnikami.
- Potwierdź adresy URL systemu odzyskiwania po awarii i adresy IP.
- Przygotuj się do procesu przeglądu uczestników projektu biznesowego, w tym potwierdzenia dostępu do systemów i przedsiębiorstw MŚP kończących walidację i zatwierdzenie.
- Przegląd i zatwierdzenie uczestników projektu biznesowego
- Szczegóły kontaktu z zasobami biznesowymi.
- Kroki weryfikacji biznesowej zgodnie z powyższym odzyskiwaniem technicznym.
- Ślad dowodowy wymagany od osoby zatwierdzającej firmy podpisuje odzyskiwanie.
- Wymagania wstępne odzyskiwania
- Przekazanie do obsługi operacyjnej w celu wykonania procesów danych w celu zapewnienia aktualności systemu.
- Przekazywanie procesów i rozwiązań podrzędnych — potwierdzanie daty i szczegółów połączenia systemu odzyskiwania po awarii.
- Potwierdź proces odzyskiwania zakończony przez potencjalnego klienta odzyskiwania po awarii — potwierdzanie śladu dowodu i ukończony element Runbook.
- Powiadamianie zespołów ds. zabezpieczeń o podwyższonym poziomie uprawnień dostępu można usunąć z zespołu odzyskiwania po awarii.
Objaśnienie
- Zaleca się uwzględnienie zrzutów ekranu systemu każdego procesu kroku. Te zrzuty ekranu pomogą rozwiązać problem zależności od mŚP systemu w celu wykonania zadań.
- Aby zapewnić szybkie rozwijanie usług w chmurze, plan odzyskiwania po awarii powinien być regularnie ponownie sprawdzany, testowany i wykonywany przez zasoby z bieżącą wiedzą na temat platformy Azure i jej usług.
- Kroki odzyskiwania technicznego powinny odzwierciedlać priorytet składnika i rozwiązania w organizacji. Na przykład podstawowe przepływy danych przedsiębiorstwa są odzyskiwane przed laboratoriami analizy danych ad hoc.
- Kroki odzyskiwania technicznego powinny być wykonywane zgodnie z kolejnością przepływów pracy (zazwyczaj od lewej do prawej), po odzyskaniu składników podstawowych lub usługi, takich jak Key Vault. Ta strategia zapewni dostępność zależności nadrzędnych, a składniki można odpowiednio przetestować.
- Po zakończeniu planu krok po kroku należy uzyskać całkowity czas działań z awaryjnego działania. Jeśli ta suma jest ponad uzgodnionym celem czasu odzyskiwania (RTO), dostępnych jest kilka opcji:
- Automatyzowanie wybranych procesów odzyskiwania (jeśli to możliwe).
- Poszukaj możliwości równoległego uruchamiania wybranych kroków odzyskiwania (tam, gdzie to możliwe). Jednak zauważając, że ta strategia może wymagać dodatkowych zasobów funkcji wykonawczej odzyskiwania po awarii.
- Podnieś poziom kluczowych składników do wyższych poziomów warstw usług, takich jak PaaS, gdzie firma Microsoft ponosi większą odpowiedzialność za działania odzyskiwania usług.
- Rozszerzanie celu czasu odzyskiwania z udziałem uczestników projektu.
Testowanie odzyskiwania po awarii
Charakter usługi w chmurze platformy Azure powoduje ograniczenia dla wszystkich scenariuszy testowania odzyskiwania po awarii. W związku z tym wskazówki dotyczą tworzenia subskrypcji odzyskiwania po awarii ze składnikami platformy danych, ponieważ będą one dostępne w regionie pomocniczym.
Z tego punktu odniesienia element runbook planu odzyskiwania po awarii można selektywnie wykonywać, zwracając szczególną uwagę na usługi i składniki, które można wdrożyć i zweryfikować. Ten proces będzie wymagał wyselekcjonowanych zestawów danych testowych, umożliwiając potwierdzenie kontroli weryfikacji technicznej i biznesowej zgodnie z planem.
Plan odzyskiwania po awarii powinien być regularnie testowany, aby nie tylko zapewnić aktualność, ale także zbudować "pamięć mięśni" dla zespołów wykonujących działania w trybie failover i odzyskiwania.
- Kopie zapasowe danych i konfiguracji powinny być również regularnie testowane, aby upewnić się, że są one "odpowiednie do celu", aby obsługiwać wszelkie działania odzyskiwania.
Kluczowym obszarem, na który należy skoncentrować się podczas testu odzyskiwania po awarii, jest zapewnienie, że kroki preskrypcyjne są nadal poprawne, a szacowane czasy są nadal istotne.
- Jeśli instrukcje odzwierciedlają ekrany portalu, a nie kod, instrukcje powinny być weryfikowane co najmniej co 12 miesięcy ze względu na cykl zmian w chmurze.
Chociaż aspiracją jest posiadanie w pełni zautomatyzowanego procesu odzyskiwania po awarii, pełna automatyzacja może być mało prawdopodobna ze względu na rzadkość zdarzenia. W związku z tym zaleca się ustanowienie punktu odniesienia odzyskiwania za pomocą infrastruktury Desired State Configuration (DSC) jako kodu (IaC) używanego do dostarczania platformy, a następnie podnieść poziom wydajności, gdy nowe projekty bazują na linii bazowej.
- W miarę rozszerzania składników i usług należy wymusić NFR, wymagając refaktoryzacji potoku wdrażania produkcyjnego w celu zapewnienia pokrycia odzyskiwania po awarii.
Jeśli chronometraż elementu Runbook przekracza cel czasu odzyskiwania, istnieje kilka opcji:
- Rozszerzanie celu czasu odzyskiwania z udziałem uczestników projektu.
- Obniż czas wymagany dla działań odzyskiwania za pośrednictwem automatyzacji, równoległego uruchamiania zadań lub migracji do wyższych warstw serwera w chmurze.
Azure Chaos Studio
Azure Chaos Studio to zarządzana usługa zwiększająca odporność przez wprowadzanie błędów do aplikacji platformy Azure. Program Chaos Studio umożliwia organizowanie iniekcji błędów w zasobach platformy Azure w bezpieczny i kontrolowany sposób przy użyciu eksperymentów. Zapoznaj się z dokumentacją produktu, aby uzyskać opis typów obecnie obsługiwanych błędów.
Bieżąca iteracja programu Chaos Studio obejmuje tylko podzestaw składników i usług platformy Azure. Do czasu dodania większej liczby bibliotek błędów program Chaos Studio jest zalecanym podejściem do testowania odporności izolowanej, a nie pełnego testowania odzyskiwania po awarii systemu.
Więcej informacji na temat programu Chaos Studio można znaleźć w dokumentacji usługi Azure Chaos Studio.
Azure Site Recovery
W przypadku składników IaaS usługa Azure Site Recovery będzie chronić większość obciążeń uruchomionych na obsługiwanej maszynie wirtualnej lub serwerze fizycznym
Istnieją silne wskazówki dotyczące:
- Wykonywanie próbnego odzyskiwania po awarii maszyny wirtualnej platformy Azure
- Wykonywanie trybu failover odzyskiwania po awarii do regionu pomocniczego
- Wykonywanie powrotu odzyskiwania po awarii do regionu podstawowego
- Włączanie automatyzacji planu odzyskiwania po awarii
Powiązane zasoby
- Tworzenie architektury pod kątem odporności i dostępności
- Ciągłość działania i odzyskiwanie po awarii
- Tworzenie kopii zapasowych i odzyskiwanie po awarii dla aplikacji platformy Azure
- Odporność na platformie Azure
- Podsumowanie umów dotyczących poziomu usług (SLA)
- Pięć najlepszych rozwiązań w celu przewidywania awarii
Następne kroki
Teraz, gdy wiesz już, jak wdrożyć scenariusz, możesz przeczytać podsumowanie serii odzyskiwania po awarii dla platformy danych azure.