Zdobyte doświadczenia
- Upewnij się, że wszystkie zaangażowane strony rozumieją różnicę między wysoką dostępnością i odzyskiwaniem po awarii (DR): typowe pułapki polegają na myleniu dwóch pojęć i niezgodności powiązanych z nimi rozwiązań.
- Porozmawiaj z uczestnikami projektu biznesowego na temat ich oczekiwań dotyczących następujących aspektów, aby zdefiniować cele punktu odzyskiwania (RPO) i cele czasu odzyskiwania (RTO):
- Ile przestojów mogą tolerować, mając na uwadze, że zwykle im szybsze odzyskiwanie, tym wyższy koszt.
- Typ zdarzeń, z których mają być chronione, wspominając o powiązanym prawdopodobieństwie takiego zdarzenia. Na przykład prawdopodobieństwo awarii serwera jest wyższe niż klęska żywiołowa, która ma wpływ na wszystkie centra danych w całym regionie.
- Jaki wpływ na system jest niedostępny w swojej firmie?
- Budżet wydatków operacyjnych (OPEX) na rozwiązanie w przyszłości.
- Zastanów się, jakie opcje usługi obniżonej wydajności mogą zaakceptować użytkownicy końcowi. Mogą to być:
- Nadal masz dostęp do pulpitów nawigacyjnych wizualizacji, nawet bez najbardziej aktualnych danych, które są, jeśli potoki pozyskiwania nie działają, użytkownicy końcowi nadal mają dostęp do swoich danych.
- Mając dostęp do odczytu, ale bez dostępu do zapisu.
- Docelowe metryki celu czasu odzyskiwania i celu punktu odzyskiwania po awarii mogą definiować strategię odzyskiwania po awarii, którą chcesz zaimplementować:
- Aktywne/aktywne.
- Aktywne/pasywne.
- Aktywne/ponowne wdrażanie w przypadku awarii.
- Weź pod uwagę własny cel poziomu usług złożonych (SLO), aby uwzględnić tolerowane przestoje.
- Upewnij się, że rozumiesz wszystkie składniki, które mogą mieć wpływ na dostępność systemów, takie jak:
- Zarządzanie tożsamością.
- Topologia sieci.
- Zarządzanie wpisami tajnymi/kluczami.
- Źródła danych.
- Harmonogram automatyzacji/zadań.
- Potoki repozytorium źródłowego i wdrażania (GitHub, Azure DevOps).
- Wczesne wykrywanie awarii jest również sposobem znacznego zmniejszenia wartości celu czasu odzyskiwania i celu punktu odzyskiwania. Poniżej przedstawiono kilka aspektów, które należy uwzględnić:
- Zdefiniuj awarię i sposób mapowania jej na definicję awarii firmy Microsoft. Definicja firmy Microsoft jest dostępna na stronie umowy dotyczącej poziomu usług (SLA) platformy Azure na poziomie produktu lub usługi.
- Wydajny system monitorowania i zgłaszania alertów z odpowiedzialnymi zespołami w celu przeglądu tych metryk i alertów w odpowiednim czasie pomaga osiągnąć ten cel.
- Jeśli chodzi o projekt subskrypcji, dodatkowa infrastruktura odzyskiwania po awarii może być przechowywana w oryginalnej subskrypcji. Usługi typu platforma jako usługa (PaaS), takie jak Azure Data Lake Storage Gen2 lub Azure Data Factory, zwykle mają natywne funkcje, które umożliwiają przechodzenie w tryb failover do wystąpień pomocniczych w innych regionach podczas pozostawania w pierwotnej subskrypcji. Niektórzy klienci mogą rozważyć posiadanie dedykowanej grupy zasobów dla zasobów używanych tylko w scenariuszach odzyskiwania po awarii na potrzeby kosztów.
- Należy zauważyć, że limity subskrypcji mogą działać jako ograniczenie dla tego podejścia.
- Inne ograniczenia mogą obejmować złożoność projektu i mechanizmy kontroli zarządzania, aby upewnić się, że grupy zasobów odzyskiwania po awarii nie są używane dla przepływów pracy typu "business-as-usual" (BAU).
- Projektowanie przepływu pracy odzyskiwania po awarii w oparciu o krytyczność i zależności rozwiązania. Na przykład nie próbuj ponownie skompilować wystąpienia usług Azure Analysis Services przed uruchomieniem magazynu danych, ponieważ wyzwala błąd. W dalszej części procesu pozostaw laboratoria deweloperskie, najpierw odzyskaj podstawowe rozwiązania dla przedsiębiorstw.
- Spróbuj zidentyfikować zadania odzyskiwania, które mogą być równoległe w różnych rozwiązaniach, zmniejszając łączną wartość czasu odzyskiwania.
- Jeśli usługa Azure Data Factory jest używana w ramach rozwiązania, nie zapomnij uwzględnić własnych środowisk Integration Runtime w zakresie. Usługa Azure Site Recovery jest idealna dla tych maszyn.
- Operacje ręczne powinny być jak najwięcej zautomatyzowane, aby uniknąć błędów ludzkich, zwłaszcza w przypadku pod presją. Zaleca się:
- Wdrażanie aprowizacji zasobów za pomocą szablonów Bicep, szablonów usługi ARM lub skryptów programu PowerShell.
- Wdrażanie przechowywania wersji kodu źródłowego i konfiguracji zasobów.
- Użyj potoków wydań ciągłej integracji/ciągłego wdrażania, a nie operacji kliknięć.
- Zgodnie z planem przejścia w tryb failover należy rozważyć procedury powrotu do wystąpień podstawowych.
- Zdefiniuj jasne wskaźniki i metryki, aby sprawdzić, czy przejście w tryb failover powiodło się, a rozwiązania są uruchomione lub czy sytuacja wraca do normy (znana również jako podstawowa funkcjonalność).
- Zdecyduj, czy umowy dotyczące poziomu usług (SLA) powinny pozostać takie same po przejściu w tryb failover lub jeśli zezwalasz na obniżoną wydajność usługi.
- Ta decyzja będzie znacznie zależeć od obsługiwanego procesu usługi biznesowej. Na przykład przejście w tryb failover dla systemu rezerwacji pomieszczeń będzie wyglądać znacznie inaczej niż podstawowy system operacyjny.
- Definicja celu punktu odzyskiwania/celu punktu odzyskiwania powinna być oparta na konkretnych scenariuszach użytkownika, a nie na poziomie infrastruktury. Zapewni to większą szczegółowość procesów i składników, które powinny zostać odzyskane jako pierwsze, jeśli wystąpi awaria lub awaria.
- Upewnij się, że kontrole pojemności są uwzględniane w regionie docelowym przed przejściem do trybu failover: jeśli wystąpi poważna awaria, należy pamiętać, że wielu klientów spróbuje przejść w tryb failover do tego samego sparowanego regionu w tym samym czasie, co może spowodować opóźnienia lub rywalizację o aprowizowanie zasobów.
- Jeśli te zagrożenia są niedopuszczalne, należy rozważyć strategię aktywne/aktywne/pasywne odzyskiwanie po awarii.
- Należy utworzyć i zachować plan odzyskiwania po awarii, aby udokumentować proces odzyskiwania i właścicieli akcji. Należy również wziąć pod uwagę, że ludzie mogą być na urlopie, więc pamiętaj, aby dołączyć kontakty pomocnicze.
- Regularne próby odzyskiwania po awarii powinny być wykonywane w celu zweryfikowania przepływu pracy planu odzyskiwania po awarii, że spełnia on wymagania celu punktu odzyskiwania/celu punktu odzyskiwania oraz do trenowania odpowiedzialnych zespołów.
- Kopie zapasowe danych i konfiguracji powinny być również regularnie testowane, aby upewnić się, że są one "odpowiednie do celu", aby obsługiwać wszelkie działania odzyskiwania.
- Wczesna współpraca z zespołami odpowiedzialnymi za sieć, tożsamość i aprowizowanie zasobów umożliwi umowę dotyczącą najbardziej optymalnego rozwiązania:
- Jak przekierowywać użytkowników i ruch z lokacji głównej do lokacji dodatkowej. Można ocenić koncepcje, takie jak przekierowanie DNS lub użycie określonych narzędzi, takich jak usługa Azure Traffic Manager .
- Jak zapewnić dostęp i prawa do lokacji dodatkowej w odpowiednim czasie i w bezpieczny sposób.
- Podczas awarii skuteczna komunikacja między wieloma zaangażowanymi stronami jest kluczem do skutecznego i szybkiego wykonania planu. Zespoły mogą obejmować:
- Decydentów.
- Zespół reagowania na zdarzenia.
- Dotyczy to użytkowników wewnętrznych i zespołów.
- Zespoły zewnętrzne.
- Orkiestracja różnych zasobów w odpowiednim czasie zapewni wydajność wykonywania planu odzyskiwania po awarii.
Kwestie wymagające rozważenia
Antywzorzecy
- Skopiuj/wklej tę serię artykułów Ta seria artykułów ma na celu zapewnienie klientom wskazówek dotyczących następnego poziomu szczegółów dla procesu odzyskiwania po awarii specyficznego dla platformy Azure. W związku z tym jest ona oparta na ogólnym adresie IP i architekturze referencyjnej firmy Microsoft, a nie na implementacji platformy Azure specyficznej dla jednego klienta.
Chociaż podane szczegóły pomogą w uzyskaniu solidnego podstawowego zrozumienia, klienci muszą zastosować własny kontekst, implementację i wymagania przed uzyskaniem strategii i procesu odzyskiwania po awarii "odpowiedniego do celu".
Traktowanie odzyskiwania po awarii jako procesu technologicznego Interesariusze biznesowi odgrywają kluczową rolę w zdefiniowaniu wymagań dotyczących odzyskiwania po awarii i wykonaniu kroków weryfikacji biznesowych wymaganych do potwierdzenia odzyskiwania usługi. Zapewnienie, że uczestnicy projektu biznesowego są zaangażowani we wszystkie działania związane z odzyskiwaniem po awarii, zapewni proces odzyskiwania po awarii", który jest "odpowiedni do celu", reprezentuje wartość biznesową i jest wykonywalny.
Plany odzyskiwania po awarii "Ustawianie i zapominanie" na platformie Azure stale ewoluują, podobnie jak korzystanie z różnych składników i usług przez poszczególnych klientów. Proces odzyskiwania po awarii "dopasowany do celu" musi ewoluować wraz z nimi. Za pośrednictwem procesu cyklu projektowania oprogramowania (SDLC) lub okresowych przeglądów klienci powinni regularnie przeglądać swój plan odzyskiwania po awarii. Celem jest zapewnienie ważności planu odzyskiwania usługi i uwzględnienie wszelkich różnic między składnikami, usługami lub rozwiązaniami.
Oceny oparte na papierze , podczas gdy kompleksowa symulacja zdarzenia odzyskiwania po awarii będzie trudna w przypadku nowoczesnego systemu danych, należy dążyć do jak największego zbliżenia się do pełnej symulacji między składnikami, których dotyczy problem. Regularnie zaplanowane ćwiczenia zbudują "pamięć mięśni" wymaganą przez organizację, aby móc wykonać plan odzyskiwania po awarii z ufnością.
Poleganie na firmie Microsoft w celu wykonania tego wszystkiego w ramach usług platformy Microsoft Azure, istnieje wyraźny podział odpowiedzialności, zakotwiczony przez używaną warstwę usług w chmurze:
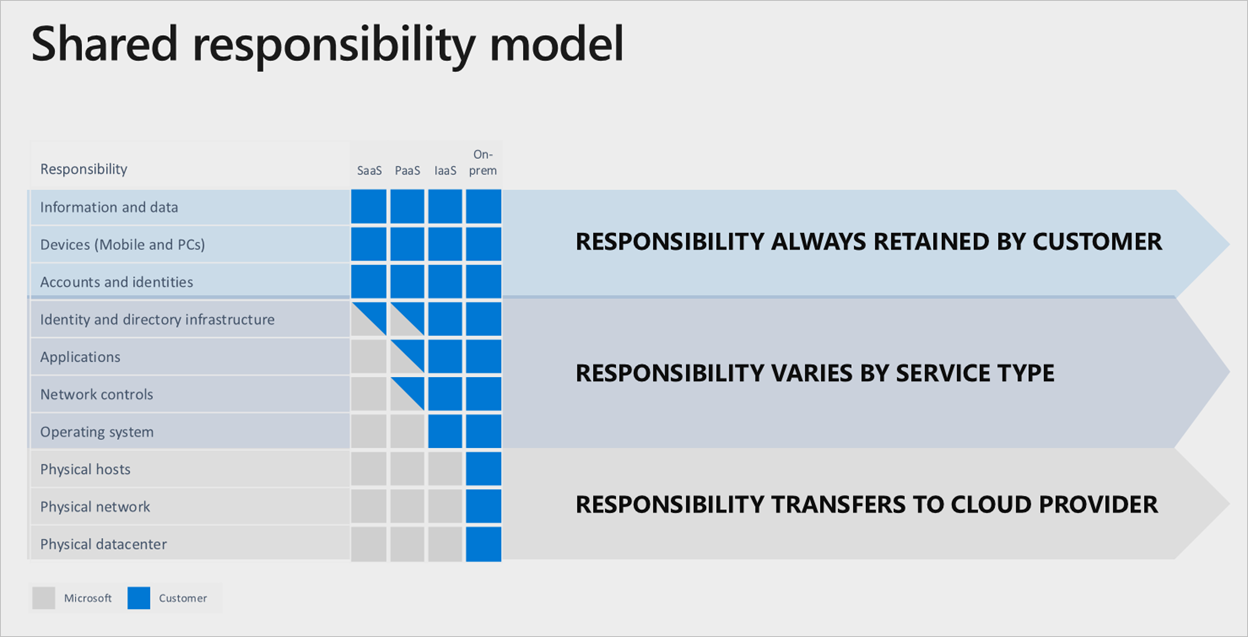 nawet jeśli jest używany pełny stos oprogramowania jako usługi (SaaS), klient będzie nadal ponosić odpowiedzialność za zapewnienie, że konta, tożsamości i dane są poprawne/aktualne, wraz z urządzeniami używanymi do interakcji z usługami platformy Azure.
nawet jeśli jest używany pełny stos oprogramowania jako usługi (SaaS), klient będzie nadal ponosić odpowiedzialność za zapewnienie, że konta, tożsamości i dane są poprawne/aktualne, wraz z urządzeniami używanymi do interakcji z usługami platformy Azure.
Zakres i strategia zdarzeń
Zakres zdarzeń awarii
Różne zdarzenia będą miały inny zakres wpływu i w związku z tym inną odpowiedź. Na poniższym diagramie przedstawiono to w przypadku zdarzenia awarii: 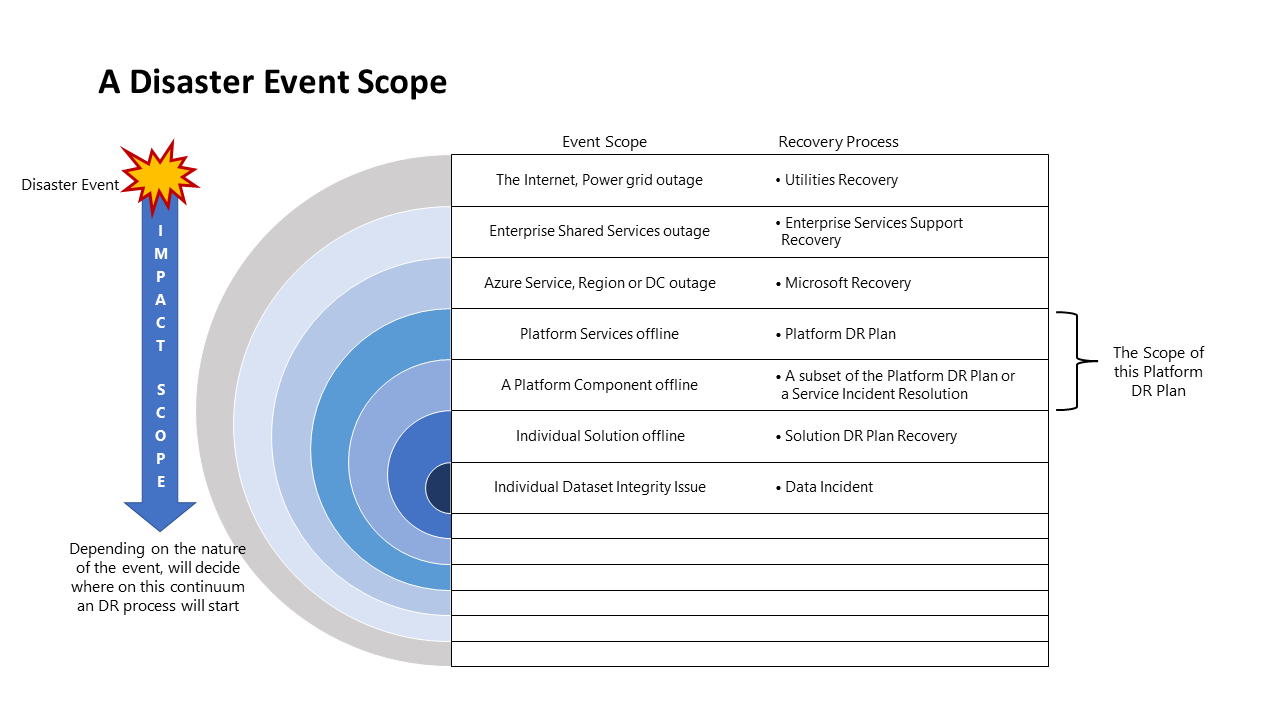
Opcje strategii awarii
Istnieją cztery ogólne opcje strategii odzyskiwania po awarii:
- Poczekaj na firmę Microsoft — jak sugeruje nazwa, rozwiązanie jest w trybie offline do momentu ukończenia odzyskiwania usług w danym regionie przez firmę Microsoft. Po odzyskaniu rozwiązanie jest weryfikowane przez klienta, a następnie jest aktualizowane na potrzeby odzyskiwania usługi.
- Ponowne wdrażanie w przypadku awarii — rozwiązanie jest ponownie wdrażane ręcznie w dostępnym regionie od podstaw, po awarii.
- Ciepły zapasowy (aktywny/pasywny) — pomocnicze rozwiązanie hostowane jest tworzone w regionie alternatywnym, a składniki są wdrażane w celu zagwarantowania minimalnej pojemności, ale składniki nie odbierają ruchu produkcyjnego. Usługi pomocnicze w regionie alternatywnym mogą być "wyłączone" lub działać na niższym poziomie wydajności do czasu wystąpienia zdarzenia odzyskiwania po awarii.
- Hot Spare (aktywny/aktywny) — rozwiązanie jest hostowane w konfiguracji aktywne/aktywne w wielu regionach. Pomocnicze rozwiązanie hostowane odbiera, przetwarza i obsługuje dane w ramach większego systemu.
Wpływ strategii odzyskiwania po awarii
Chociaż koszt operacyjny przypisywany wyższym poziomom odporności usług często dominuje kluczowa decyzja projektowa (KDD) dla strategii odzyskiwania po awarii. Istnieją inne ważne zagadnienia.
Uwaga
Optymalizacja kosztów jest jednym z pięciu filarów doskonałości architektury z platformą Azure Well-Architected Framework. Jego celem jest zmniejszenie niepotrzebnych wydatków i zwiększenie wydajności operacyjnej.
Scenariusz odzyskiwania po awarii dla tego przykładu to kompletna regionalna awaria platformy Azure, która ma bezpośredni wpływ na region podstawowy hostujący platformę danych Contoso.
W tym scenariuszu awarii względny wpływ na cztery strategie odzyskiwania po awarii wysokiego poziomu to: 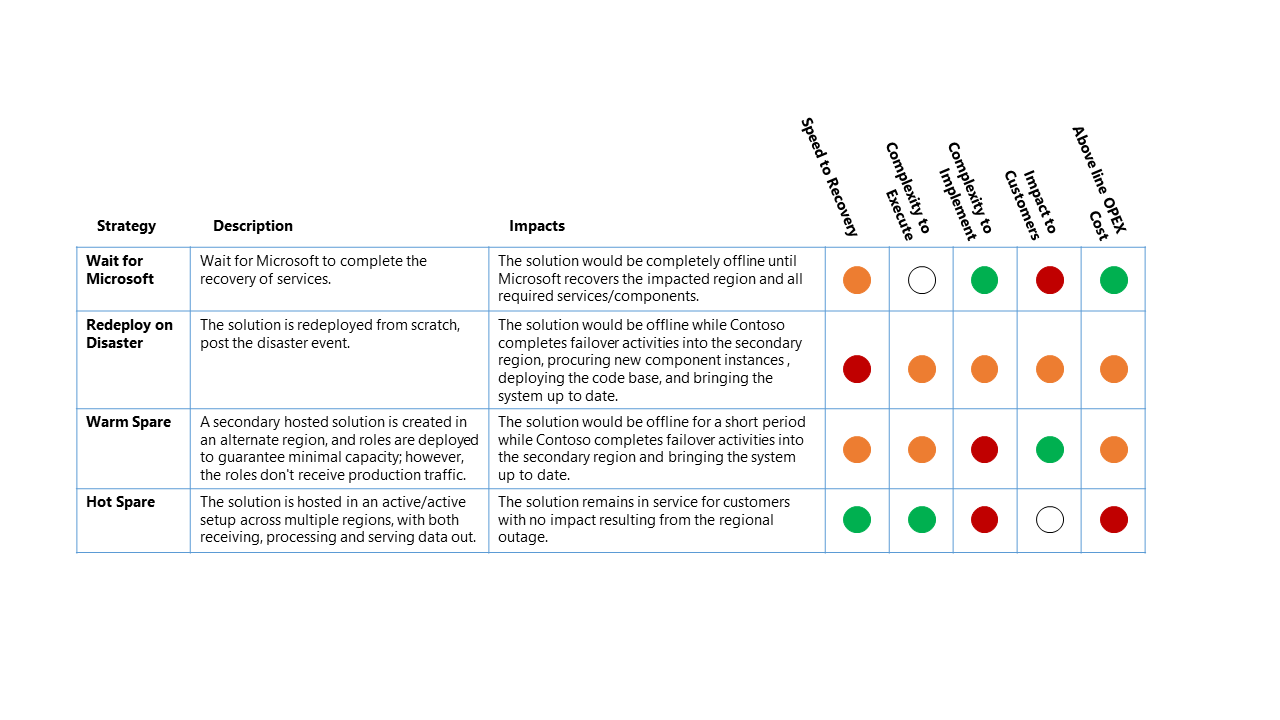
Klucz klasyfikacji
- Cel czasu odzyskiwania (RTO): oczekiwany czas od zdarzenia awarii do odzyskiwania usługi platformy.
- Złożoność do wykonania: złożoność wykonywania działań odzyskiwania przez organizację.
- Złożoność implementacji: złożoność implementacji strategii odzyskiwania po awarii w organizacji.
- Wpływ na klientów: bezpośredni wpływ na klientów usługi platformy danych ze strategii odzyskiwania po awarii.
- Powyżej wiersza koszt OPEX: dodatkowy koszt oczekiwany od wdrożenia tej strategii, takiej jak zwiększone miesięczne rozliczenia dla platformy Azure dla dodatkowych składników i dodatkowych zasobów wymaganych do obsługi.
Uwaga
Powyższa tabela powinna być odczytywana jako porównanie opcji — strategia, która ma zielony wskaźnik, jest lepsza dla tej klasyfikacji niż inna strategia ze wskaźnikiem żółtym lub czerwonym.
Następne kroki
Po zapoznaniu się z zaleceniami dotyczącymi scenariusza możesz dowiedzieć się, jak wdrożyć ten scenariusz